Übersicht
Dieser Artikel beschreibt zwei verschiedene verfügbare Ansätze, um doppelte Zeilen aus SQL-Tabelle(n) zu entfernen, was im Laufe der Zeit oft schwierig wird, wenn die Daten wachsen, wenn dies nicht rechtzeitig erfolgt.
Das Vorhandensein doppelter Zeilen ist ein häufiges Problem, mit dem SQL-Entwickler und -Tester von Zeit zu Zeit konfrontiert werden. Diese doppelten Zeilen fallen jedoch in eine Reihe verschiedener Kategorien, die wir in diesem Artikel besprechen werden.
Dieser Artikel konzentriert sich auf ein bestimmtes Szenario, wenn Daten, die in eine Datenbanktabelle eingefügt werden, zur Einführung von doppelten Datensätzen führen, und dann werden wir uns die Methoden zum Entfernen von Duplikaten genauer ansehen und schließlich die Duplikate mit diesen Methoden entfernen.
Beispieldaten vorbereiten
Bevor wir mit der Erforschung der verschiedenen verfügbaren Optionen zum Entfernen von Duplikaten beginnen, lohnt es sich an dieser Stelle, eine Beispieldatenbank einzurichten, die uns helfen wird, die Situationen zu verstehen, in denen doppelte Daten in das System gelangen, und die zu verwendenden Ansätze, um sie zu beseitigen .
Beispieldatenbank einrichten (UniversityV2)
Beginnen Sie damit, eine sehr einfache Datenbank zu erstellen, die nur aus einem Student besteht Tabelle am Anfang.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Schülertabelle füllen
Fügen wir der Student-Tabelle nur zwei Datensätze hinzu:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Datencheck
Sehen Sie sich die Tabelle an, die im Moment zwei unterschiedliche Datensätze enthält:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
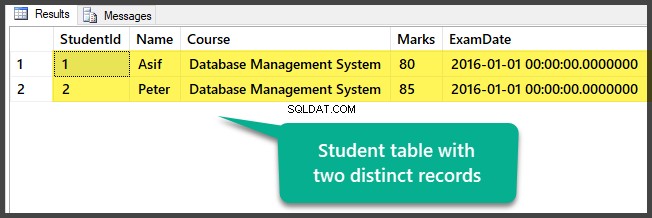
Sie haben die Beispieldaten erfolgreich vorbereitet, indem Sie eine Datenbank mit einer Tabelle und zwei unterschiedlichen (unterschiedlichen) Datensätzen eingerichtet haben.
Wir werden nun einige mögliche Szenarien diskutieren, in denen Duplikate eingeführt und gelöscht wurden, angefangen bei einfachen bis hin zu etwas komplexen Situationen.
Fall 01:Hinzufügen und Entfernen von Duplikaten
Jetzt werden wir doppelte Zeilen in der Student-Tabelle einführen.
Voraussetzungen
In diesem Fall wird gesagt, dass eine Tabelle doppelte Datensätze enthält, wenn der Name eines Schülers angegeben ist , Kurs , Markierungen und Prüfungsdatum in mehr als einem Datensatz übereinstimmen, auch wenn die Studenten-ID ist anders.
Wir gehen also davon aus, dass keine zwei Studenten den gleichen Namen, Kurs, Noten und Prüfungsdatum haben können.
Hinzufügen doppelter Daten für Student Asif
Lassen Sie uns absichtlich einen doppelten Datensatz für Student:Asif einfügen an den Schüler Tabelle wie folgt:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Doppelte Schülerdaten anzeigen
Zeigen Sie den Schüler an Tabelle, um doppelte Datensätze zu sehen:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
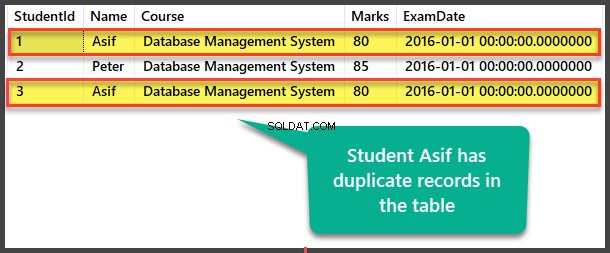
Duplikate durch selbstreferenzierende Methode finden
Was ist, wenn es Tausende von Datensätzen in dieser Tabelle gibt, dann wird das Anzeigen der Tabelle nicht viel helfen.
Bei der selbstreferenzierenden Methode nehmen wir zwei Verweise auf dieselbe Tabelle und verbinden sie mithilfe einer spaltenweisen Zuordnung mit Ausnahme der ID, die kleiner oder größer als die andere gemacht wird.
Schauen wir uns die selbstreferenzierende Methode an, um Duplikate zu finden, die so aussieht:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Die Ausgabe des obigen Skripts zeigt uns nur die doppelten Datensätze:

Finden von Duplikaten durch selbstreferenzierende Methode-2
Eine andere Möglichkeit, Duplikate mithilfe von Selbstreferenzen zu finden, ist die Verwendung von INNER JOIN wie folgt:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Entfernen von Duplikaten durch selbstreferenzierende Methode
Wir können die Duplikate mit der gleichen Methode entfernen, mit der wir Duplikate gefunden haben, mit Ausnahme der Verwendung von DELETE in Übereinstimmung mit seiner Syntax wie folgt:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Datenprüfung nach Entfernung von Duplikaten
Lassen Sie uns schnell die Aufzeichnungen überprüfen, nachdem wir die Duplikate entfernt haben:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
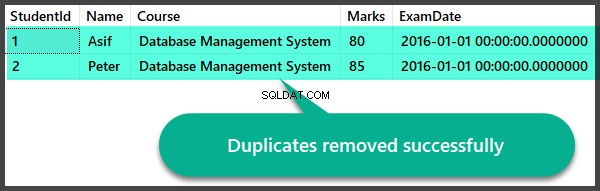
Duplikate erstellen View and RemoveDuplicates Stored Procedure
Jetzt, da wir wissen, dass unsere Skripte doppelte Zeilen in SQL erfolgreich finden und löschen können, ist es besser, sie zur einfacheren Verwendung in Ansicht und gespeicherte Prozedur umzuwandeln:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
Hinzufügen und Anzeigen mehrerer doppelter Datensätze
Lassen Sie uns nun vier weitere Datensätze zu Student hinzufügen Tabelle und alle Datensätze sind Duplikate, so dass sie denselben Namen, denselben Kurs, dieselben Noten und dasselbe Prüfungsdatum haben:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
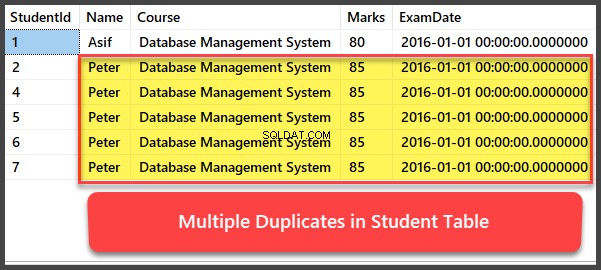
Entfernen von Duplikaten mit der UspRemoveDuplicates-Prozedur
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
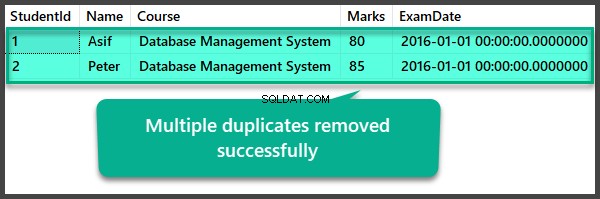
Datenprüfung nach Entfernung mehrerer Duplikate
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Fall 02:Hinzufügen und Entfernen von Duplikaten mit denselben IDs
Bisher haben wir doppelte Datensätze mit unterschiedlichen IDs identifiziert, aber was ist, wenn die IDs identisch sind?
Denken Sie beispielsweise an das Szenario, in dem kürzlich eine Tabelle aus einer Text- oder Excel-Datei ohne Primärschlüssel importiert wurde.
Voraussetzungen
In diesem Fall hat eine Tabelle doppelte Datensätze, wenn alle Spaltenwerte genau gleich sind, einschließlich einiger ID-Spalten, und der Primärschlüssel fehlt, was die Eingabe der doppelten Datensätze erleichtert.
Kurstabelle ohne Primärschlüssel erstellen
Um das Szenario zu reproduzieren, bei dem doppelte Datensätze ohne Primärschlüssel in eine Tabelle fallen, erstellen wir zunächst einen neuen Kurs Tabelle ohne Primärschlüssel in der University2-Datenbank wie folgt:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Kurstabelle ausfüllen
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
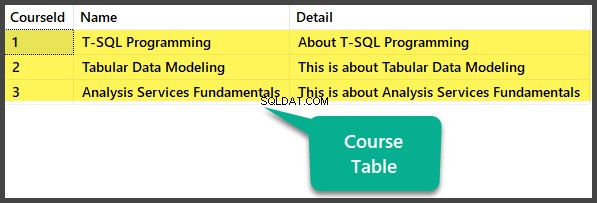
Datencheck
Sehen Sie sich den Kurs an Tabelle:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Hinzufügen doppelter Daten in der Kurstabelle
Fügen Sie nun Duplikate in den Kurs ein Tabelle:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Doppelte Kursdaten anzeigen
Wählen Sie alle Spalten aus, um die Tabelle anzuzeigen:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

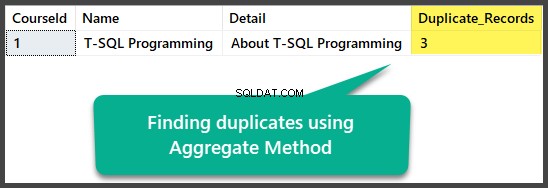
Duplikate nach aggregierter Methode finden
Wir können exakte Duplikate finden, indem wir die aggregierte Methode verwenden, indem wir alle Spalten mit insgesamt mehr als einer gruppieren, nachdem wir alle Spalten ausgewählt und alle Zeilen mit der aggregierten count(*)-Funktion gezählt haben:
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Dies kann wie folgt angewendet werden:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Duplikate nach aggregierter Methode entfernen
Lassen Sie uns die Duplikate mit der Aggregate-Methode wie folgt entfernen:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Datencheck
VERWENDEN Sie UniversityV2
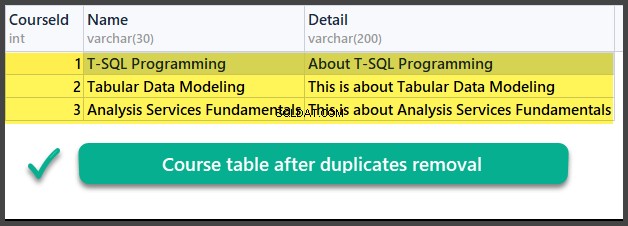
Wir haben also erfolgreich gelernt, wie man Duplikate aus einer Datenbanktabelle mit zwei verschiedenen Methoden basierend auf zwei verschiedenen Szenarien entfernt.
Dinge zu tun
Sie können eine Datenbanktabelle jetzt einfach identifizieren und von doppelten Werten befreien.
1. Versuchen Sie, UspRemoveDuplicatesByAggregate zu erstellen gespeicherte Prozedur basierend auf der oben genannten Methode und entfernen Duplikate durch Aufrufen der gespeicherten Prozedur
2. Versuchen Sie, die oben erstellte gespeicherte Prozedur (UspRemoveDuplicatesByAggregates) zu ändern, und implementieren Sie die in diesem Artikel erwähnten Bereinigungstipps.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Können Sie sicher sein, dass die UspRemoveDuplicatesByAggregate gespeicherte Prozedur so oft wie möglich ausgeführt werden kann, selbst nach dem Entfernen der Duplikate, um zu zeigen, dass die Prozedur überhaupt konsistent bleibt?
4. Bitte lesen Sie meinen vorherigen Artikel Testgesteuerte Datenbankentwicklung (TDDD) – Teil 1 und versuchen Sie, Duplikate in die SQLDevBlog-Datenbanktabellen einzufügen, und versuchen Sie danach, die Duplikate mit beiden in diesem Tipp erwähnten Methoden zu entfernen.
5. Bitte versuchen Sie, eine andere Beispieldatenbank EmployeesSample zu erstellen beziehen Sie sich auf meinen vorherigen Artikel Art of Isolating Dependencies and Data in Database Unit Testing und fügen Sie Duplikate in die Tabellen ein und versuchen Sie, sie mit beiden Methoden zu entfernen, die Sie aus diesem Tipp gelernt haben.
Nützliches Tool:
dbForge Data Compare for SQL Server – leistungsstarkes SQL-Vergleichstool, das mit großen Datenmengen arbeiten kann.