Beim Ausführen einer Abfrage versucht der SQL Server-Optimierer natürlich für eine angemessene Zeit, den besten Abfrageplan basierend auf vorhandenen Indizes und verfügbaren neuesten Statistiken zu finden, wenn dieser Plan nicht bereits im Server-Cache gespeichert ist. Wenn nein, wird die Abfrage gemäß diesem Plan ausgeführt und der Plan im Server-Cache gespeichert. Wenn der Plan für diese Abfrage bereits erstellt wurde, wird die Abfrage gemäß dem vorhandenen Plan ausgeführt.
Wir interessieren uns für folgendes Problem:
Wenn der Server beim Kompilieren eines Abfrageplans beim Sortieren möglicher Indizes nicht den besten Index findet, wird der fehlende Index im Abfrageplan markiert, und der Server führt Statistiken über solche Indizes:wie oft der Server diesen Index verwenden würde und wie viel diese Abfrage kosten würde.
In diesem Artikel werden wir diese fehlenden Indizes analysieren – wie man damit umgeht.
Betrachten wir dies an einem bestimmten Beispiel. Erstellen Sie ein paar Tabellen in unserer Datenbank auf einem lokalen und Testserver:
[expand title =”Code”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expandieren]
Die Struktur ist einfach und besteht aus zwei Tabellen. Die erste Tabelle heißt Bestellungen mit Feldern wie Kennung, Verkaufsdatum und Verkäufer. Die zweite sind Bestelldetails, in denen einige Waren mit Preis und Menge angegeben sind.
Sehen Sie sich eine einfache Abfrage und ihren Plan an:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
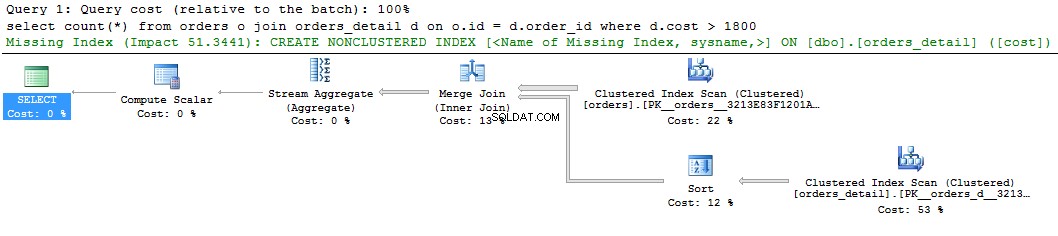
Auf der grafischen Darstellung des Abfrageplans sehen wir einen grünen Hinweis auf den fehlenden Index. Wenn Sie mit der rechten Maustaste darauf klicken und „Fehlende Indexdetails ..“ auswählen, wird der Text des vorgeschlagenen Index angezeigt. Das Einzige, was Sie tun müssen, ist, die Kommentare im Text zu entfernen und dem Index einen Namen zu geben. Das Skript ist zur Ausführung bereit.
Wir werden den Index, den wir aus dem von SSMS bereitgestellten Hinweis erhalten haben, nicht erstellen. Stattdessen werden wir sehen, ob dieser Index von dynamischen Ansichten empfohlen wird, die mit fehlenden Indizes verknüpft sind. Die Ansichten sind wie folgt:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
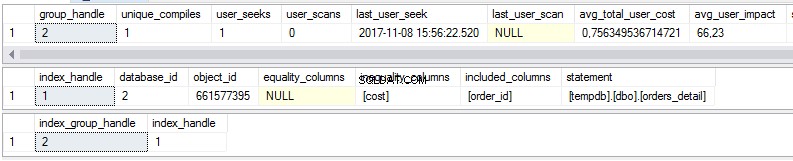
Wie wir sehen können, gibt es in der ersten Ansicht einige Statistiken zu fehlenden Indizes:
- Wie oft würde eine Suche durchgeführt, wenn der vorgeschlagene Index vorhanden wäre?
- Wie oft würde ein Scan durchgeführt werden, wenn der vorgeschlagene Index vorhanden wäre?
- Letztes Datum und letzte Zeit, zu der wir den Index verwendet haben
- Die aktuellen tatsächlichen Kosten des Abfrageplans ohne den vorgeschlagenen Index.
Die zweite Ansicht ist der Indexkörper:
- Datenbank
- Objekt/Tabelle
- Sortierte Spalten
- Spalten hinzugefügt, um die Indexabdeckung zu erhöhen
Die dritte Ansicht ist die Kombination aus der ersten und zweiten Ansicht.
Dementsprechend ist es nicht schwierig, ein Skript zu erhalten, das ein Skript zum Erstellen fehlender Indizes aus diesen dynamischen Ansichten generiert. Das Skript lautet wie folgt:
[expand title="Code"]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expandieren]
Für die Indexeffizienz werden die fehlenden Indizes ausgegeben. Die perfekte Lösung ist, wenn diese Ergebnismenge nichts zurückgibt. In unserem Beispiel gibt die Ergebnismenge mindestens einen Index zurück:

Wenn keine Zeit ist und Sie keine Lust haben, sich mit den Client-Bugs zu beschäftigen, habe ich die Abfrage ausgeführt, die erste Spalte kopiert und auf dem Server ausgeführt. Danach hat alles gut funktioniert.
Ich empfehle, die Informationen auf diesen Indizes bewusst zu behandeln. Wenn das System beispielsweise die folgenden Indizes empfiehlt:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
Und diese Indizes werden für die Suche verwendet, es ist ziemlich offensichtlich, dass es logischer ist, diese Indizes durch einen zu ersetzen, der alle drei vorgeschlagenen abdeckt:
create index ix_1 on tbl1 (a,b) include (c,d)
Daher überprüfen wir die fehlenden Indizes, bevor wir sie auf dem Produktionsserver bereitstellen. Obwohl…. Auch hier habe ich beispielsweise die verlorenen Indizes auf dem TFS-Server bereitgestellt und so die Gesamtleistung erhöht. Die Durchführung dieser Optimierung hat nur minimale Zeit in Anspruch genommen. Beim Wechsel von TFS 2015 zu TFS 2017 hatte ich jedoch das Problem, dass es aufgrund dieser neuen Indizes kein Update gab. Trotzdem können sie leicht durch die Maske gefunden werden
select * from sys.indexes where name like 'ix[_]2017%'
Nützliches Tool:
dbForge Index Manager – praktisches SSMS-Add-in zum Analysieren des Status von SQL-Indizes und Beheben von Problemen mit der Indexfragmentierung.