Datenreplikation bedeutet das Kopieren von Daten von einem Ort zum anderen und wird normalerweise zwischen Benutzern verschiedener Datenbanken durchgeführt, die denselben Informationsstand teilen müssen. Die Replikation kann auch andere Datenquellen und -ziele umfassen und hinsichtlich Transformation und Zeitaufwand komplexer werden.
Dies ist der erste von zwei Artikeln, die die Datenbankreplikation in der IRI Workbench-GUI behandeln. IRI Workbench ist die kostenlose IDE, die auf Eclipse™ basiert und alle IRI-Produkte unterstützt, einschließlich IRI NextForm (für die Daten- und Datenbankmigration) und IRI Voracity (eine umfassende Datenverwaltungsplattform, die NextForm et al. enthält). IRI Workbench erstellt und führt Datenreplikationsjobs durch Assistenten, Skripte und Arbeitsablaufdiagramme aus.
Hier sind einige Möglichkeiten, wie Replikationen auftreten:
- Daten in einer Datenbank werden in eine andere Datenbank auf demselben oder einem anderen Server kopiert.
- Daten aus zwei oder mehr Datenbanken werden in einer einzigen Datenbank kombiniert.
- Benutzer erhalten vollständige Anfangskopien der Datenbank und dann regelmäßige Updates, wenn sich Daten ändern.
- Daten werden selektiv aus einer Datenbank extrahiert und in eine externe Datei repliziert.
Die Datenreplikation ermöglicht es Ihnen, nur einen Teil der Datenbank zu replizieren; d. h. ausgewählte Tabellen, Spalten und/oder Zeilen. Das Replizieren aller Tabellen ist Teil der Datenbankspiegelung. Änderungen an Schemata, Einschränkungen, Verfahren und Zugriffsberechtigungen sind jedoch nicht so einfach zu replizieren und können separate Prozesse beinhalten.
Einfaches Beispiel in IRI Workbench
Für dieses erste Datenreplikationsbeispiel verwenden wir einen Auftragserstellungsassistenten aus dem NextForm-Menü in der Symbolleiste der IRI Workbench. Wir werden Daten aus einer Oracle-Tabelle sowohl in eine MySQL-Tabelle als auch in eine modifizierte Flatfile kopieren. Dieser zweite Artikel demonstriert die Replikation von nur aktualisierten Daten in einer Tabelle durch Auswerten von Timestamp-Spaltenwerten.
Das NextForm-Menü enthält drei Job-Erstellungsassistenten:
- Neuer Reformat-Job
- Neuer Single-Source-Migrationsjob
- Neuer Job für die Migration mehrerer Tabellen
Wir verwenden den Assistenten für neue Neuformatierungsaufträge, um diese Replikation durchzuführen. Für einen komplexeren Job würden wir einen anderen NextForm-Wizard oder einen ETL-Job-Wizard im Voracity-Menü verwenden (oder manuell einen neuen Workflow erstellen).
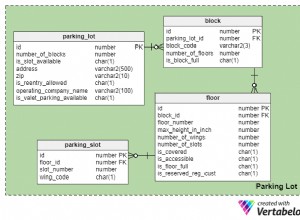
Hier ist die Struktur der Quell- und Zieltabellen:

Schritt 1:Geben Sie den Namen und die Auftragsoptionen an
Wählen Sie im Menü „NextForm“ in der oberen Symbolleiste den Assistenten „Job neu formatieren“ aus. Geben Sie für dieses Beispiel den Jobdateinamen datareplication ein . NextForm fügt die Erweiterung .ncl hinzu. Sie können auch relevante Informationen zu diesem Job hinzufügen, die als Kommentare im Skript erscheinen.
Belassen Sie in der Optionsfeldliste die Standardauswahl von Skript erstellen da dies ein eigenständiger Job ist und nicht Teil eines größeren Flow- oder Batch-Projekts.

Schritt 2:Identifizieren Sie die Quelle
Klicken Sie auf dem nächsten Bildschirm, Datenquellen, auf Datenquelle hinzufügen . Die Quelle in diesem Beispiel ist eine mit ODBC verbundene Datenbank, wählen Sie also ODBC, aus und klicken Sie dann auf Durchsuchen um den Datenquellennamen (DSN) und die Tabelle auszuwählen.

Schritt 3:Geben Sie die Quellmetadaten an
Damit die IRI-Software die Daten in ihrer Engine verschieben und bearbeiten kann (in diesem Fall in NextForm replizieren), benötigen Sie Metadaten für die Quelle und die Ziele, die im Jobskript definiert sind, im Format der Datendefinitionsdatei (DDF) von IRI.
Sie können die DDFs für jede Quelle (oder jedes Ziel) automatisch in IRI Workbench erstellen. Diese Funktionalität ist hier eingebettet, wo Sie entweder Metadaten entdecken auswählen können oder Vorhandene Metadaten hinzufügen . In diesem Fall werden wir vorhandene Metadaten hinzufügen, die auf andere Weise erstellt wurden. Diese Auswahl und ihre Ergebnisse werden im folgenden Dialog angezeigt:

Klicken Sie auf Quellfeld-Layout um das Layout der Daten zu sehen.

Klicken Sie auf OK um das Quellfeld-Layout zu schließen. Klicken Sie dann auf Weiter auf der Seite "Datenquellen", um die Seite "Datenziel" zu öffnen.
Schritt 4:Ziel(e) definieren
Wir senden die replizierten Oracle-Daten an zwei Ziele:eine MySQL-Tabelle, die wir customers_out nennen , und eine Datei namens personout.csv .
Zieltabelle hinzufügen
Klicken Sie auf Datenziel hinzufügen . Wählen Sie ODBC aus und klicken Sie auf Durchsuchen . Wählen Sie dann den Datenquellennamen (DSN) Oracle aus und die Tabelle CUSTOMERS_REP . Klicken Sie auf OK um den Dialog zu schließen.
Markieren Sie auf der Seite „Datenziele“ den Tabellennamen und klicken Sie auf Vorhandene Metadaten hinzufügen . Wählen Sie kunden.ddf aus (die zuvor erstellt wurde) und klicken Sie auf OK .
Wir möchten die Anzahl der Datensätze in dieser Datei auf 100 begrenzen. Klicken Sie auf Zieloptionen bearbeiten um den Editor zu öffnen, und im Outcollect Geben Sie im Feld 100 ein , und klicken Sie auf OK .
Zieldatei hinzufügen
Klicken Sie erneut auf Datenziel hinzufügen . Wählen Sie Datei aus und geben Sie personout.csv ein , und klicken Sie auf OK . Wir möchten die Anzahl der Datensätze in der Datei auf nicht mehr als 50 begrenzen, und wir müssen auch das Format in CSV ändern. Klicken Sie für beides auf Zieloptionen bearbeiten um den Editor zu öffnen. Ändern Sie das Format Feld in CSV , und im Outcollect Geben Sie 50 ein , und klicken Sie auf OK .

Fügen Sie der Zieldatei eine Zeichenfolgenfunktion hinzu
Wir werden auch eine Zeichenfolgenfunktion hinzufügen, um nur die letzten vier Ziffern des SSN-Felds anzuzeigen. Klicken Sie dazu auf Zielfeldlayout und klicken Sie auf die Registerkarte personout.csv.
Wählen Sie das Feld SSN aus, klicken Sie mit der rechten Maustaste und wählen Sie Regel anwenden > Regel erstellen . Wählen Sie auf der Auswahlseite des Assistenten für neue Feldregeln die Option Funktionen zur Zeichenfolgenbearbeitung aus . Wählen Sie auf der nächsten Seite – String-Manipulationsfunktionen – sub_string aus . Im Versatz Geben Sie 6 für die Anzahl der Zeichen links vom Feld und in die Länge ein Geben Sie im Feld 4 als Länge der Teilzeichenfolge ein und klicken Sie dann auf Fertig stellen .

Einschließen-Filter hinzufügen
Um die CSV-Datei weiter zu modifizieren, fügen wir einen Filter hinzu, um die Daten so einzuschränken, dass sie nur die Datensätze von CA enthalten. Klicken Sie auf Datensatzfilter um den Filter zu erstellen. Wählen Sie Einschließen aus für die Filteraktion und wählen Sie Neue Bedingung aus für den Typ. Öffnen Sie den Ausdrucksgenerator, indem Sie auf das Funktionssymbol klicken.  Wählen Sie im Expression Builder die Kategorie Relational Operators und das Element EQ . Im Ausdruck Geben Sie oben im Feld STATE EQ „CA“ mit den Werkzeugen in der Symbolleiste ein und klicken Sie auf Fertig stellen .
Wählen Sie im Expression Builder die Kategorie Relational Operators und das Element EQ . Im Ausdruck Geben Sie oben im Feld STATE EQ „CA“ mit den Werkzeugen in der Symbolleiste ein und klicken Sie auf Fertig stellen .

Zurück auf der Seite „Datenziele“ beschließen wir, die Felder „Nachname“ und „Vorname“ nach dem Feld „PLZ“ neu zu positionieren. Wählen Sie NACHNAME aus und klicken Sie auf Nach unten bis sich das Feld ganz unten in der Liste befindet, und wählen Sie dann FIRSTNAME aus und tun Sie dasselbe.
Wenn wir beide Ziele hinzugefügt haben, werden die Felder und Änderungen auf der Seite „Datenziele“ angezeigt.

Klicken Sie auf Fertig stellen um das Erstellen des Skripts abzuschließen, das unten in der farbcodierten, syntaxbewussten Editoransicht von IRI Workbench gezeigt wird:

Ergebnisse
Führen Sie das Auftragsskript aus, indem Sie mit der rechten Maustaste auf das Skript klicken und Ausführen als> auswählen IRI-Job . Die Zieldaten werden in den unten geöffneten Registerkarten angezeigt:

Wenn Sie Fragen zum Replizieren von Daten in NextForm oder Voracity haben, wenden Sie sich an Ihren IRI-Vertreter.
- Klicken Sie im Datenquellen-Explorer mit der rechten Maustaste auf die Tabelle und wählen Sie IRI aus > DDF generieren . Dadurch wird das DDF für die Tabelle im aktiven Projektordner erstellt und zur Laufzeit von der Datenmanipulations-Engine von IRI referenziert.