Als SQL Server-DBAs haben wir gehört, dass Indexstrukturen die Leistung einer bestimmten Abfrage (oder eines Satzes von Abfragen) erheblich verbessern können. Dennoch gibt es bestimmte Details, die viele DBAs übersehen, wie die folgenden:
- Indexstrukturen können fragmentiert werden, was potenziell zu Leistungseinbußen führen kann.
- Sobald eine Indexstruktur für eine Datenbanktabelle bereitgestellt wurde, aktualisiert SQL Server sie bei jedem Schreibvorgang für diese Tabelle. Dies geschieht, wenn die indexkonformen Spalten betroffen sind.
- In SQL Server gibt es Metadaten, die verwendet werden können, um zu wissen, wann die Statistiken für eine bestimmte Indexstruktur (wenn überhaupt) zum letzten Mal aktualisiert wurden. Unzureichende oder veraltete Statistiken können die Leistung bestimmter Abfragen beeinträchtigen.
- In SQL Server gibt es Metadaten, die verwendet werden können, um festzustellen, wie viel eine Indexstruktur entweder durch Lesevorgänge verbraucht oder durch Schreibvorgänge von SQL Server selbst aktualisiert wurde. Diese Informationen können nützlich sein, um zu wissen, ob es Indizes gibt, deren Schreibvolumen das Lesevolumen bei weitem übersteigt. Es kann sich möglicherweise um eine Indexstruktur handeln, deren Aufbewahrung nicht so nützlich ist.*
*Es ist sehr wichtig, daran zu denken, dass die Systemansicht, die diese bestimmten Metadaten enthält, jedes Mal gelöscht wird, wenn die SQL Server-Instanz neu gestartet wird, sodass es sich nicht um Informationen aus ihrer Konzeption handelt.
Aufgrund der Bedeutung dieser Details habe ich eine gespeicherte Prozedur erstellt, um Informationen zu Indexstrukturen in seiner Umgebung zu verfolgen und so proaktiv wie möglich zu handeln.
Erste Überlegungen
- Stellen Sie sicher, dass das Konto, das diese gespeicherte Prozedur ausführt, über ausreichende Berechtigungen verfügt. Sie könnten wahrscheinlich mit den Systemadministratoren beginnen und dann so granular wie möglich vorgehen, um sicherzustellen, dass der Benutzer die Mindestberechtigungen hat, die erforderlich sind, damit der SP ordnungsgemäß funktioniert.
- Die Datenbankobjekte (Datenbanktabelle und gespeicherte Prozedur) werden innerhalb der Datenbank erstellt, die zum Zeitpunkt der Ausführung des Skripts ausgewählt wurde, wählen Sie also sorgfältig aus.
- Das Skript ist so aufgebaut, dass es mehrmals ausgeführt werden kann, ohne dass ein Fehler ausgegeben wird. Für die gespeicherte Prozedur habe ich die CREATE OR ALTER PROCEDURE-Anweisung verwendet, die seit SQL Server 2016 SP1 verfügbar ist.
- Sie können den Namen der erstellten Datenbankobjekte gerne ändern, wenn Sie eine andere Namenskonvention verwenden möchten.
- Wenn Sie sich dafür entscheiden, von der gespeicherten Prozedur zurückgegebene Daten beizubehalten, wird die Zieltabelle zuerst abgeschnitten, sodass nur die neueste Ergebnismenge gespeichert wird. Sie können die notwendigen Anpassungen vornehmen, wenn Sie möchten, dass sich dies aus irgendeinem Grund anders verhält (vielleicht um historische Informationen beizubehalten?).
Wie verwende ich die gespeicherte Prozedur?
- Kopieren Sie den T-SQL-Code und fügen Sie ihn ein (verfügbar in diesem Artikel).
- Der SP erwartet 2 Parameter:
- @persistData:„Y“, wenn der DBA die Ausgabe in einer Zieltabelle speichern möchte, und „N“, wenn der DBA die Ausgabe nur direkt sehen möchte.
- @db:„all“, um die Informationen für alle Datenbanken (System und Benutzer) abzurufen, „user“, um auf Benutzerdatenbanken abzuzielen, „system“, um nur auf Systemdatenbanken (außer tempdb) abzuzielen, und schließlich der tatsächliche Name von eine bestimmte Datenbank.
Dargestellte Felder und ihre Bedeutung
- dbName: der Name der Datenbank, in der sich das Indexobjekt befindet.
- schemaName: der Name des Schemas, in dem sich das Indexobjekt befindet.
- Tabellenname: der Name der Tabelle, in der sich das Indexobjekt befindet.
- Indexname: der Name der Indexstruktur.
- Typ: die Art des Index (z. B. Clustered, Non-Clustered).
- allocation_unit_type: gibt den Datentyp an, auf den verwiesen wird (z. B. In-Row-Daten, Lob-Daten).
- Fragmentierung: der Grad der Fragmentierung (in %), den die Indexstruktur derzeit aufweist.
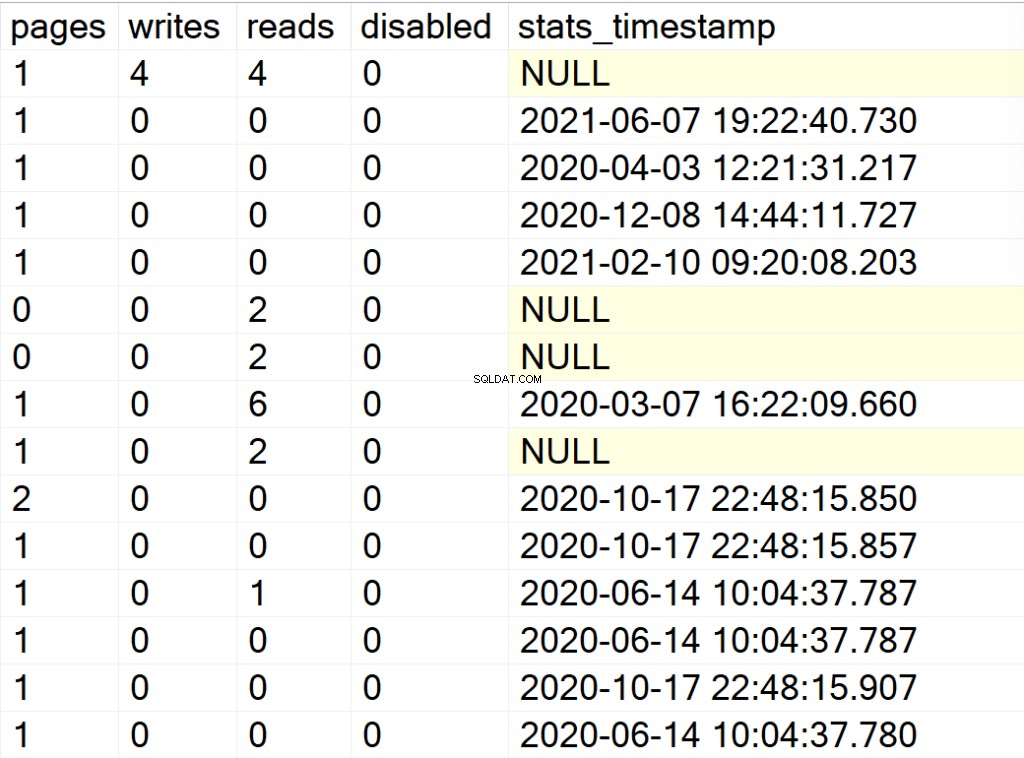
- Seiten: die Anzahl der 8-KB-Seiten, die die Indexstruktur bilden.
- schreibt: die Anzahl der Schreibvorgänge, die die Indexstruktur seit dem letzten Neustart der SQL Server-Instanz erfahren hat.
- liest: die Anzahl der Lesevorgänge, die die Indexstruktur seit dem letzten Neustart der SQL Server-Instanz durchlaufen hat.
- deaktiviert: 1, wenn die Indexstruktur derzeit deaktiviert ist, oder 0, wenn die Struktur aktiviert ist.
- stats_timestamp: der Zeitstempelwert, wann die Statistiken für die bestimmte Indexstruktur zuletzt aktualisiert wurden (NULL, wenn nie).
- data_collection_timestamp: nur sichtbar, wenn 'Y' an den @persistData-Parameter übergeben wird, und es wird verwendet, um zu wissen, wann der SP ausgeführt und die Informationen erfolgreich in der DBA_Indexes-Tabelle gespeichert wurden.
Ausführungstests
Ich werde einige Ausführungen der gespeicherten Prozedur demonstrieren, damit Sie sich ein Bild davon machen können, was Sie davon erwarten können:
*Sie finden den vollständigen T-SQL-Code des Skripts am Ende dieses Artikels, führen Sie es also unbedingt aus, bevor Sie mit dem folgenden Abschnitt fortfahren.
*Die Ergebnismenge wird zu breit sein, um gut in einen Screenshot zu passen, daher werde ich alle erforderlichen Screenshots teilen, um die vollständigen Informationen zu präsentieren.
/* Alle Indexinformationen für alle System- und Benutzerdatenbanken anzeigen */
EXEC GetIndexData @persistData = 'N',@db = 'all'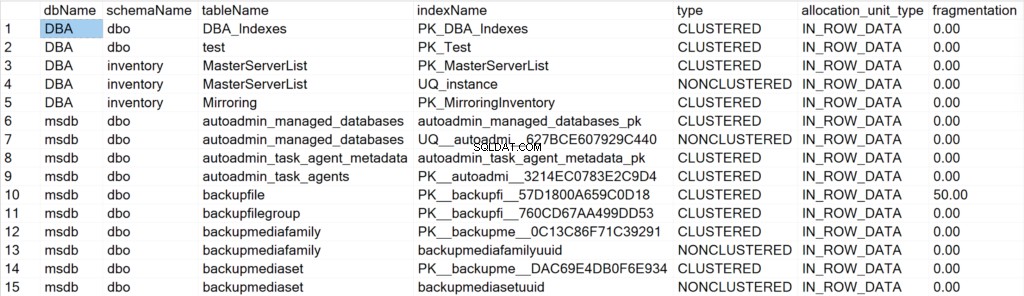
/* Alle Indexinformationen für alle Systemdatenbanken anzeigen */
EXEC GetIndexData @persistData = 'N',@db = 'system'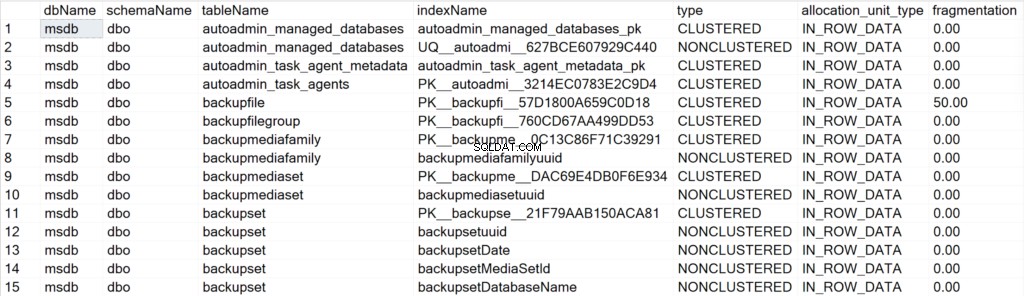
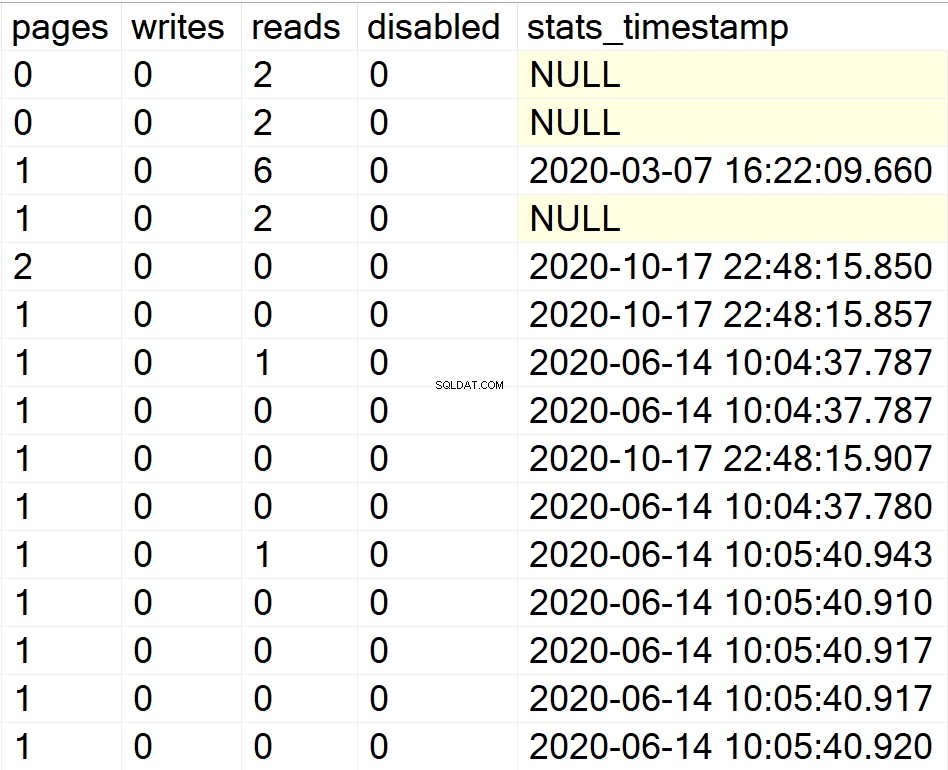
/* Alle Indexinformationen für alle Benutzerdatenbanken anzeigen */
EXEC GetIndexData @persistData = 'N',@db = 'user'
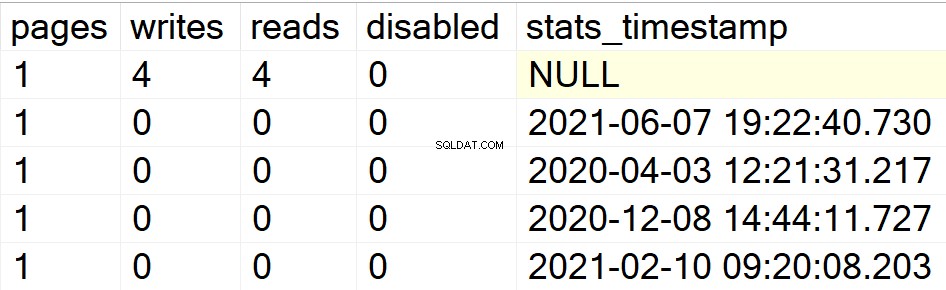
/* Alle Indexinformationen für bestimmte Benutzerdatenbanken anzeigen */
In meinen vorherigen Beispielen wurde nur die Datenbank DBA als meine einzige Benutzerdatenbank mit darin enthaltenen Indizes angezeigt. Lassen Sie mich daher eine Indexstruktur in einer anderen Datenbank erstellen, die ich in derselben Instanz herumliegen habe, damit Sie sehen können, ob der SP seine Sache macht oder nicht.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Alle bisher vorgestellten Beispiele demonstrieren die Ausgabe, die Sie erhalten, wenn Sie keine Daten beibehalten möchten, für die verschiedenen Kombinationen von Optionen für den @db-Parameter. Die Ausgabe ist leer, wenn Sie entweder eine ungültige Option angeben oder die Zieldatenbank nicht vorhanden ist. Aber was ist, wenn der DBA Daten in einer Datenbanktabelle persistieren möchte? Finden wir es heraus.
*Ich werde den SP nur für einen Fall ausführen, da die restlichen Optionen für den @db-Parameter oben ziemlich genau gezeigt wurden und das Ergebnis das gleiche ist, aber in einer Datenbanktabelle gespeichert wird.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
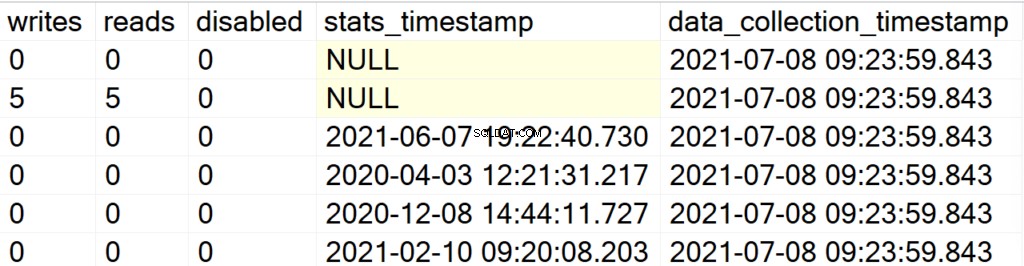
Jetzt, nachdem Sie die gespeicherte Prozedur ausgeführt haben, erhalten Sie keine Ausgabe. Um die Ergebnismenge abzufragen, müssen Sie eine SELECT-Anweisung für die Tabelle DBA_Indexes absetzen. Die Hauptattraktion hier ist, dass Sie den erhaltenen Ergebnissatz für die Nachanalyse abfragen können, und das Hinzufügen des Felds data_collection_timestamp, das Sie darüber informiert, wie aktuell/alt die Daten sind, die Sie sich ansehen.
Nebenabfragen
Um dem DBA einen Mehrwert zu bieten, habe ich einige Abfragen vorbereitet, die Ihnen helfen können, nützliche Informationen aus den Daten zu erhalten, die in der Tabelle gespeichert sind.
*Abfrage, um insgesamt sehr fragmentierte Indizes zu finden.
*Wählen Sie die Anzahl von %, die Sie für passend halten.
*Die 1500 Seiten basieren auf einem Artikel, den ich gelesen habe, basierend auf der Empfehlung von Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Abfrage, um deaktivierte Indizes in Ihrer Umgebung zu finden.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Abfrage, um Indizes (meistens nicht gruppiert) zu finden, die nicht so oft von Abfragen verwendet werden, zumindest nicht seit dem letzten Neustart der SQL Server-Instanz.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Abfrage, um Statistiken zu finden, die entweder nie aktualisiert wurden oder alt sind.
*Du bestimmst, was in deiner Umgebung alt ist, also achte darauf, die Anzahl der Tage entsprechend anzupassen.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Hier ist der vollständige Code der Stored Procedure:
*Ganz am Anfang des Skripts sehen Sie den Standardwert, den die gespeicherte Prozedur annimmt, wenn für jeden Parameter kein Wert übergeben wird.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOSchlussfolgerung
- Sie können diesen SP in jeder von Ihnen unterstützten SQL Server-Instanz bereitstellen und einen Warnmechanismus für Ihren gesamten Stack unterstützter Instanzen implementieren.
- Wenn Sie einen Agentenjob implementieren, der diese Informationen relativ häufig abfragt, bleiben Sie auf dem Laufenden und kümmern sich um die Indexstrukturen in Ihren unterstützten Umgebungen.
- Stellen Sie sicher, dass Sie diesen Mechanismus ordnungsgemäß in einer Sandbox-Umgebung testen, und stellen Sie sicher, dass Sie Zeiträume mit geringer Aktivität wählen, wenn Sie eine Produktionsbereitstellung planen.
Probleme mit der Indexfragmentierung können knifflig und stressig sein. Um sie zu finden und zu beheben, können Sie verschiedene Tools verwenden, wie den dbForge Index Manager, der hier heruntergeladen werden kann.