Bevor wir uns mit dem Leistungsproblem der weitergeleiteten Datensätze befassen und es lösen, müssen wir die Struktur der SQL Server-Tabellen überprüfen.
Übersicht über die Tabellenstruktur
In SQL Server sind die 8-KB-Seiten die grundlegende Einheit der Datenspeicherung . Jede Seite beginnt mit einem 96-Byte-Header, der die Systeminformationen zu dieser Seite speichert. Dann werden die Tabellenzeilen seriell nach dem Header auf den Datenseiten gespeichert. Am Ende der Seite wird die Zeilen-Offset-Tabelle, die einen Eintrag für jede Zeile enthält, entgegengesetzt zur Reihenfolge der Zeilen in der Seite gespeichert. Dieser Zeilen-Offset-Eintrag zeigt, wie weit das erste Byte dieser Zeile vom Anfang der Seite entfernt ist.
SQL Server bietet uns zwei Arten von Tabellen, basierend auf der Struktur dieser Tabelle. Die Clustered Die Tabelle speichert und sortiert die Daten auf den Datenseiten basierend auf der vordefinierten Schlüsselspalte oder den Spaltenwerten des Clustered-Index. Darüber hinaus werden die Datenseiten innerhalb der Clustered-Tabelle sortiert und in einer verknüpften Liste basierend auf den Clustered-Index-Schlüsselwerten miteinander verknüpft. Der B-Baum Die Struktur des Clustered-Index bietet eine schnelle Datenzugriffsmethode basierend auf den Schlüsselwerten des Clustered-Index. Wenn eine neue Zeile eingefügt oder ein vorhandener Schlüsselwert in der gruppierten Tabelle aktualisiert wird, speichert SQL Server den neuen Wert an der richtigen logischen Position, die der eingefügten Zeilengröße entspricht, ohne die Sortierkriterien zu verletzen. Wenn der eingefügte oder aktualisierte Wert größer ist als der verfügbare Platz auf der Datenseite, wird die Seite in zwei Seiten geteilt, um den neuen Wert aufzunehmen.
Der zweite Tabellentyp ist der Heap Tabelle, in der die Daten innerhalb der Datenseiten nicht in beliebiger Reihenfolge sortiert und die Seiten nicht miteinander verknüpft sind, da für diese Tabelle kein Clustered-Index definiert ist, um Sortierkriterien durchzusetzen. Das Verfolgen der Seiten, die nicht nach Sortierkriterien sortiert oder in der Heap-Tabelle miteinander verknüpft sind, ist keine leichte Aufgabe. Um den Nachverfolgungsprozess der Seitenzuordnung innerhalb der Heap-Tabelle zu vereinfachen, verwendet SQL Server die Indexzuordnungskarte (IAM), die einzige logische Verbindung zwischen den Datenseiten in der Heap-Tabelle, indem für jede Datenseite in der Tabelle oder dem Index in der IAM-Tabelle ein Eintrag beibehalten wird. Um Daten aus der Heap-Tabelle abzurufen, scannt die SQL Server-Engine das IAM, um den Extent zu finden, der 8 Seiten bildet, die die angeforderten Daten speichern.
Problem mit weitergeleiteten Datensätzen
Wenn eine neue Zeile in die Heap-Tabelle eingefügt wird, scannt die SQL Server-Engine den freien Speicherplatz der Seite (PFS)-Seiten, um den Zuordnungsstatus und die Speicherplatznutzung auf jeder Datenseite zu verfolgen, um die erste verfügbare Position in den Datenseiten zu finden, die der eingefügten Zeilengröße entspricht. Dann wird die Zeile zur ausgewählten Seite hinzugefügt. Wenn der eingefügte Wert größer ist als der verfügbare Platz in den Datenseiten, wird eine neue Seite zu dieser Tabelle hinzugefügt, um den neuen Wert einfügen zu können.
Wenn andererseits die vorhandenen Daten in der Heap-Tabelle geändert werden, wir beispielsweise eine Zeichenfolge mit variabler Länge mit einer größeren Datengröße aktualisiert haben und der aktuelle Platz nicht zu den neuen Daten passt, werden die Daten auf einen anderen physischen verschoben Standort und den Weitergeleiteten Datensatz wird am ursprünglichen Datenspeicherort in die Heap-Tabelle eingefügt, um auf den neuen Speicherort dieser Daten zu verweisen und den Speicherort der Verfolgungsdaten zu vereinfachen. Der neue Datenort enthält auch einen Zeiger, der auf den Weiterleitungszeiger zeigt, um ihn im Fall des Verschiebens der Daten von dem neuen Ort aktuell zu halten und die lange Weiterleitungszeigerkette zu verhindern oder zu löschen. Dies kann dazu führen, dass auch der Weiterleitungseintrag entfernt wird.
Obwohl die Umleitungsmethode für weitergeleitete Datensätze den Bedarf an ressourcenintensiven Tabellen- und Non-Clustered-Indizes-Wiederherstellungsvorgängen zum Aktualisieren der Datenadressen bei jeder Änderung des Speicherorts der Daten reduziert, verdoppelt sie auch die Anzahl der Lesevorgänge, die zum Abrufen der Daten erforderlich sind. SQL Server besucht zuerst den alten Speicherort, wo er den weitergeleiteten Datensatz findet, der ihn an den neuen Datenspeicherort umleitet. Dann liest es die angeforderten Daten und führt die Leseoperation zweimal aus. Darüber hinaus führt das Problem der weitergeleiteten Datensätze dazu, dass die gelesenen sequentiellen Daten in zufällige gelesene Daten geändert werden, was sich im Laufe der Zeit negativ auf die Leistung des Datenabrufvorgangs auswirkt.
Lassen Sie uns den folgenden ForwardRecordDemo Heap erstellen Tabelle mit der CREATE TABLE T-SQL-Anweisung unten:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Füllen Sie diese Tabelle dann zu Testzwecken mit 3K-Datensätzen, indem Sie die folgende INSERT INTO T-SQL-Anweisung verwenden:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identifizieren des Problems mit weitergeleiteten Datensätzen
Die Informationen über den Tabellentyp und die Anzahl der verbrauchten Seiten beim Speichern der Tabellendaten sowie der Prozentsatz der Indexfragmentierung und die Anzahl der weitergeleiteten Datensätze für eine bestimmte Tabelle können durch Abfragen von sys.dm_db_index_physical_stats systemdynamische Verwaltungsfunktion und durch Übergabe an DETAILED Modus, um die Anzahl der Weiterleitungsdatensätze zurückzugeben. Verwenden Sie dazu das folgende T-SQL-Skript:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Wie Sie dem Abfrageergebnis entnehmen können, ist die vorherige Tabelle die Heap-Tabelle, auf der kein Clustered-Index erstellt wurde, um die Daten auf den Seiten zu sortieren und die Seiten miteinander zu verknüpfen. Die in die Tabelle eingefügten 3K-Zeilen werden 15 zugewiesen Datenseiten, ohne weitergeleitete Datensätze und ohne Fragmentierungsprozentsatz, wie im Ergebnis unten gezeigt:

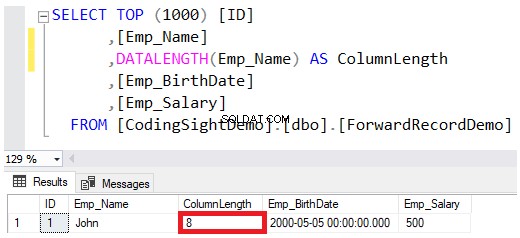
Wenn Sie den Datentyp einer Spalte als VARCHAR oder NVARCHAR definieren, ist der in der Datentypdefinition angegebene Wert die maximal zulässige Größe für diese Zeichenfolge, ohne dass dieser Betrag beim Speichern der Werte in den Datenseiten vollständig reserviert wird. Zum Beispiel der John Der in diese Tabelle eingefügte Mitarbeitername reserviert nur 8 Bytes der maximal 100 Bytes für diese Spalte, wobei zu berücksichtigen ist, dass das Speichern der NVARCHAR-Zeichenfolge die für die VARCHAR-Spalte erforderlichen Bytes verdoppelt, wie in DATALENGTH Funktionsergebnis unten:
Wenn Sie den Wert der Spalte Emp_Name aktualisieren möchten, um den vollständigen Namen des Mitarbeiters von John aufzunehmen, verwenden Sie die folgende UPDATE-Anweisung:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
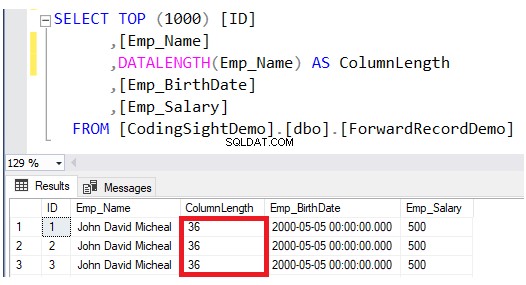
Überprüfen Sie die Länge der aktualisierten Spalte mit DATALENGTH Funktion. Sie werden sehen, dass die Länge der Emp_Name-Spalte in den aktualisierten Zeilen um 28 erweitert wurde Byte pro Spalte, was ungefähr 3,5 entspricht zusätzliche Datenseiten zu dieser Tabelle, wie im Ergebnis unten gezeigt:
Überprüfen Sie dann die Anzahl der weitergeleiteten Datensätze nach dem Aktualisierungsvorgang, indem Sie die dynamische Verwaltungsfunktion des Systems sys.dm_db_index_physical_stats abfragen. Verwenden Sie dazu das folgende T-SQL-Skript:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Wie Sie sehen können, werden beim Aktualisieren der Emp_Name-Spalte bei 1K-Datensätzen mit größeren Zeichenfolgenwerten, ohne einen neuen Datensatz hinzuzufügen, die zusätzlichen 5 zugewiesen Seiten zu dieser Tabelle, anstatt 3,5 Seiten wie zuvor erwartet. Dies geschieht aufgrund der Generierung von 484 weitergeleiteten Datensätze, um auf die neuen Speicherorte der verschobenen Daten zu verweisen. Dies kann dazu führen, dass die Tabelle 33 % beträgt fragmentiert, wie unten deutlich gezeigt:

Wenn Sie es schaffen, den Wert der Emp_Name-Spalte so zu aktualisieren, dass er den vollständigen Namen des Zaid-Mitarbeiters enthält, verwenden Sie die folgende UPDATE-Anweisung:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
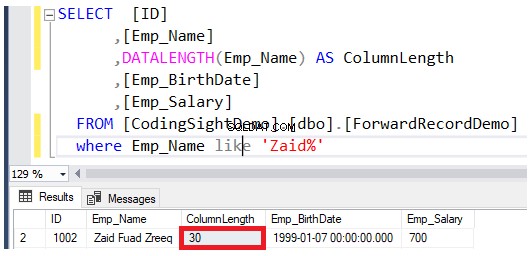
Überprüfen Sie die Länge der aktualisierten Spalte mit DATALENGTH Funktion. Sie werden sehen, dass die Länge der Emp_Name-Spalte in den aktualisierten Zeilen um 22 erweitert wurde Bytes pro Spalte, was ungefähr 2,7 entspricht zusätzliche Datenseiten zu dieser Tabelle hinzugefügt, wie im Ergebnis unten gezeigt:
Überprüfen Sie die Anzahl der weitergeleiteten Datensätze nach dem Ausführen des Aktualisierungsvorgangs. Sie können dies tun, indem Sie die dynamische Verwaltungsfunktion des Systems sys.dm_db_index_physical_stats mit demselben T-SQL-Skript unten abfragen:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Das Ergebnis zeigt Ihnen, dass das Aktualisieren der Emp_Name-Spalte in den anderen 1K-Datensätzen mit größeren Zeichenfolgenwerten ohne Einfügen einer neuen Zeile weitere 4 zuweist Seiten zu dieser Tabelle, anstatt wie erwartet 2,7 Seiten. Dies geschieht, weil zusätzliche 417 generiert werden weitergeleitete Aufzeichnungen, um auf die neuen Speicherorte der verschobenen Daten hinzuweisen und dieselben 33 % beizubehalten Fragmentierungsprozentsatz, wie unten gezeigt:

Behebung des Problems mit weitergeleiteten Datensätzen
Der einfachste Weg, das Problem mit weitergeleiteten Datensätzen zu beheben, besteht darin, die maximale Länge der Zeichenfolge zu schätzen, die in der Spalte gespeichert wird, und sie unter Verwendung der festen Länge zuzuweisen Datentyp für diese Spalte, anstatt den Datentyp mit variabler Länge zu verwenden. Der optimale dauerhafte Weg, um das Problem mit weitergeleiteten Datensätzen zu beheben, ist das Hinzufügen des Clustered Index zu diesem Tisch. Auf diese Weise wird die Tabelle vollständig in eine Clustered-Tabelle konvertiert, die basierend auf den Schlüsselwerten des Clustered-Index sortiert ist. Es steuert die Reihenfolge der vorhandenen Daten, der neu eingefügten und aktualisierten Daten, die nicht in den aktuell verfügbaren Platz auf der Datenseite passen, wie zuvor in der Einleitung dieses Artikels beschrieben.
Wenn das Hinzufügen des Clustered-Index zu dieser Tabelle für bestimmte Anforderungen, wie z. B. die Staging-Tabellen oder die ETL-Tabellen, keine Option ist, können Sie das Problem der weitergeleiteten Datensätze vorübergehend lösen, indem Sie die weitergeleiteten Datensätze überwachen und die Heap-Tabelle neu erstellen, um sie zu entfernen aktualisieren Sie auch alle Non-Clustered-Indizes in dieser Heap-Tabelle. Die Funktionalität zum Neuerstellen der Heap-Tabelle wurde in SQL Server 2008 mithilfe von ALTER TABLE…REBUILD eingeführt T-SQL-Befehl.
Um die Leistungsauswirkung der weitergeleiteten Datensätze auf die Datenabrufabfragen zu sehen, lassen Sie uns die SELECT-Abfrage ausführen, die die Suche basierend auf den Emp_Name-Spaltenwerten durchführt. Aktivieren Sie jedoch vor dem Ausführen der Abfrage die TIME- und IO-Statistiken:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Als Ergebnis sehen Sie diese 925 logische Lesevorgänge werden ausgeführt, um die angeforderten Daten innerhalb von 84 ms abzurufen wie unten gezeigt:

Um die Heap-Tabelle neu aufzubauen, um alle weitergeleiteten Datensätze zu entfernen, verwenden Sie den Befehl ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Führen Sie dieselbe SELECT-Anweisung erneut aus:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Die TIME- und IO-Statistiken zeigen Ihnen, dass nur 21 logische Leseoperationen im Vergleich zum 925 logische Lesevorgänge mit den darin enthaltenen weitergeleiteten Datensätzen werden ausgeführt, um die angeforderten Daten innerhalb von 79 ms abzurufen :

Um die Anzahl der weitergeleiteten Datensätze nach dem Neuaufbau der Heap-Tabelle zu überprüfen, führen Sie die dynamische Systemverwaltungsfunktion sys.dm_db_index_physical_stats aus und verwenden Sie dasselbe T-SQL-Skript unten:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Sie werden das nur 21 sehen Seiten, mit den vorherigen 3 Seiten, die für die weitergeleiteten Datensätze verbraucht werden, werden dieser Tabelle zugewiesen, um die Daten zu speichern, was dem geschätzten Ergebnis ähnelt, das wir während der Dateneinfügungs- und -aktualisierungsoperationen erhalten haben (15 + 3,5 + 2,7). Nach dem Neuaufbau der Heap-Tabelle werden nun alle weitergeleiteten Datensätze entfernt. Als Ergebnis haben wir eine Tabelle ohne Fragmentierung:

Das Problem der weitergeleiteten Datensätze ist ein wichtiges Leistungsproblem, das Datenbankadministratoren bei der Planung berücksichtigen sollten Wartung der Heap-Tabelle. Die vorherigen Ergebnisse werden aus unserer Testtabelle abgerufen, die nur 3K-Datensätze enthält. Sie können sich die Anzahl der Seiten vorstellen, die durch die weitergeleiteten Datensätze und die E/A-Leistungsverschlechterung aufgrund des Lesens einer großen Anzahl weitergeleiteter Datensätze beim Lesen aus riesigen Tabellen verschwendet werden!
Referenzen:
- Seiten- und Extents-Architekturleitfaden
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Das Wissen um "weitergeleitete Datensätze" kann bei der Diagnose schwer zu findender Leistungsprobleme helfen