Dieser Artikel zeigt, wie SQL Server Dichteinformationen aus mehreren Einzelspaltenstatistiken kombiniert, um eine Kardinalitätsschätzung für eine Aggregation über mehrere Spalten zu erstellen. Die Details sind für sich hoffentlich interessant. Sie bieten auch einen Einblick in einige der allgemeinen Ansätze und Algorithmen, die vom Kardinalitätsschätzer verwendet werden.
Betrachten Sie die folgende AdventureWorks-Beispieldatenbankabfrage, die die Anzahl der Produktinventarartikel in jedem Lagerplatz in jedem Regal im Lager auflistet:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Der geschätzte Ausführungsplan zeigt 1.069 Zeilen, die aus der Tabelle gelesen werden, sortiert in Shelf und Bin Reihenfolge, dann mit einem Stream Aggregate-Operator aggregiert:
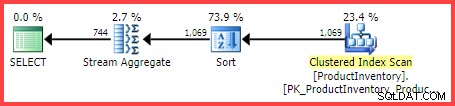
Geschätzter Ausführungsplan
Die Frage ist, wie kam der Abfrageoptimierer von SQL Server zu der endgültigen Schätzung von 744 Zeilen?
Verfügbare Statistiken
Beim Kompilieren der obigen Abfrage erstellt der Abfrageoptimierer einspaltige Statistiken im Shelf und Bin Spalten, falls noch keine geeigneten Statistiken vorhanden sind. Diese Statistiken geben unter anderem Auskunft über die Anzahl der eindeutigen Spaltenwerte (im Dichtevektor):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Die Ergebnisse sind in der folgenden Tabelle zusammengefasst (die dritte Spalte wird aus der Dichte berechnet):
| Spalte | Dichte | 1 / Dichte |
|---|---|---|
| Regal | 0,04761905 | 21 |
| Bin | 0,01612903 | 62 |
Informationen zu Regal- und Behälterdichtevektoren
Wie die Dokumentation feststellt, ist der Kehrwert der Dichte die Anzahl der unterschiedlichen Werte in der Spalte. Aus den oben gezeigten Statistikinformationen weiß SQL Server, dass es 21 unterschiedliche Shelf gab Werte und 62 verschiedene Bin Werte in der Tabelle, als die Statistiken erfasst wurden.
Die Aufgabe, die Anzahl der Zeilen zu schätzen, die von einem GROUP BY erzeugt werden -Klausel ist trivial, wenn nur eine einzige Spalte betroffen ist (unter der Annahme, dass keine anderen Prädikate verwendet werden). Zum Beispiel ist es leicht zu sehen, dass GROUP BY Shelf wird 21 Zeilen erzeugen; GROUP BY Bin ergibt 62.
Es ist jedoch nicht sofort klar, wie SQL Server die Anzahl unterschiedlicher (Shelf, Bin) schätzen kann Kombinationen für unser GROUP BY Shelf, Bin Anfrage. Um die Frage etwas anders zu stellen:Wie viele einzigartige Regal- und Behälterkombinationen gibt es bei 21 Regalen und 62 Behältern? Abgesehen von physikalischen Aspekten und anderem menschlichen Wissen über den Problembereich könnte die Antwort irgendwo zwischen max(21, 62) =62 und (21 * 62) =1.302 liegen. Ohne weitere Informationen gibt es keine offensichtliche Möglichkeit, eine Schätzung in diesem Bereich vorzunehmen.
Für unsere Beispielabfrage schätzt SQL Server jedoch 744.312 Zeilen (gerundet auf 744 in der Plan-Explorer-Ansicht), aber auf welcher Grundlage?
Erweitertes Kardinalitätsschätzungsereignis
Die dokumentierte Möglichkeit, sich den Prozess der Kardinalitätsschätzung anzusehen, ist die Verwendung des erweiterten Ereignisses query_optimizer_estimate_cardinality (obwohl es sich im "Debug"-Kanal befindet). Während eine Sitzung ausgeführt wird, die dieses Ereignis erfasst, erhalten Ausführungsplanoperatoren eine zusätzliche Eigenschaft StatsCollectionId die individuelle Betreiberschätzungen mit den Berechnungen verknüpft, die sie hervorgebracht haben. Für unsere Beispielabfrage ist die Statistiksammlungs-ID 2 mit der Kardinalitätsschätzung für die Gruppe nach Aggregatoperator verknüpft.
Die relevante Ausgabe des erweiterten Ereignisses für unsere Testabfrage lautet:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Da gibt es sicher einige nützliche Informationen.
Wir können sehen, dass die Planblatt-Berechnungsklasse für unterschiedliche Werte (CDVCPlanLeaf ) wurde verwendet, wobei Einzelspaltenstatistiken auf Shelf verwendet wurden und Bin als Eingänge. Das Statistik-Erfassungselement gleicht dieses Fragment mit der im Ausführungsplan angezeigten ID (2) ab, die die Kardinalitätsschätzung von 744,31 zeigt , sowie weitere Informationen zu den verwendeten Statistikobjekt-IDs.
Leider gibt es in der Ereignisausgabe nichts, was genau sagt, wie der Rechner zu der endgültigen Zahl gekommen ist, was uns wirklich interessiert.
Eindeutige Zählungen kombinieren
Bei einem weniger dokumentierten Weg können wir einen geschätzten Plan für die Abfrage mit Ablaufverfolgungsflags 2363 anfordern und 3604 aktiviert:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Dadurch werden Debuginformationen an die Registerkarte „Meldungen“ in SQL Server Management Studio zurückgegeben. Der interessante Teil ist unten wiedergegeben:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Dies zeigt im Wesentlichen die gleichen Informationen wie das erweiterte Ereignis in einem (wohl) einfacher zu konsumierenden Format:
- Der relationale Eingabeoperator zum Berechnen einer Kardinalitätsschätzung für (
LogOp_GbAgg– logische Gruppe nach Aggregat) - Der verwendete Rechner (
CDVCPlanLeaf) und Eingabestatistiken - Die sich ergebenden Details der Statistikerfassung
Die interessante neue Information ist der Teil über die Verwendung der Umgebungskardinalität, um unterschiedliche Zählungen zu kombinieren .
Dies zeigt deutlich, dass die Werte 21, 62 und 1069 verwendet wurden, aber (frustrierend) immer noch nicht genau, welche Berechnungen durchgeführt wurden, um zu 744.312 zu gelangen Ergebnis.
Zum Debugger!
Durch das Anhängen eines Debuggers und die Verwendung öffentlicher Symbole können wir den beim Kompilieren der Beispielabfrage verfolgten Codepfad im Detail untersuchen.
Der folgende Schnappschuss zeigt den oberen Teil der Aufrufliste an einem repräsentativen Punkt im Prozess:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Hier gibt es ein paar interessante Details. Von unten nach oben sehen wir, dass die Kardinalität mithilfe des aktualisierten CE (CCardFrameworkSQL12 ) verfügbar in SQL Server 2014 und höher (das ursprüngliche CE ist CCardFrameworkSQL7 ), für die Gruppierung nach aggregiertem logischen Operator (CLogOp_GbAgg ).
Die Berechnung der unterschiedlichen Kardinalität beinhaltet das Kombinieren (Munging) mehrerer Eingaben, wobei Sampling ohne Ersatz verwendet wird.
Der Verweis auf H und ein (natürlicher) Logarithmus in der zweiten Methode von oben zeigt die Verwendung der Shannon-Entropie in der Berechnung:
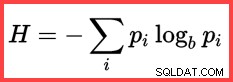
Shannon-Entropie
Entropie kann verwendet werden, um die Informationskorrelation (gegenseitige Informationen) zwischen zwei Statistiken abzuschätzen:
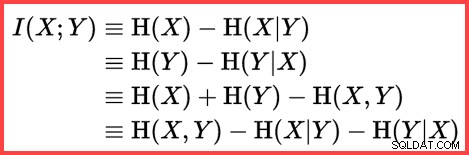
Gegenseitige Informationen
Wenn wir all dies zusammenfassen, können wir ein T-SQL-Berechnungsskript erstellen, das der Art und Weise entspricht, wie SQL Server Sampling ohne Ersatz, Shannon-Entropie und gegenseitige Informationen verwendet um die endgültige Kardinalitätsschätzung zu erstellen.
Wir beginnen mit den Eingabezahlen (Umgebungskardinalität und die Anzahl unterschiedlicher Werte in jeder Spalte):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; Die Häufigkeit jeder Spalte ist die durchschnittliche Anzahl von Zeilen pro eindeutigem Wert:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Beim SWR (Sampling without Replacement) wird einfach die durchschnittliche Zeilenanzahl pro eindeutigem Wert (Häufigkeit) von der Gesamtzeilenanzahl subtrahiert:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Berechnen Sie die Entropien (N log N) und gegenseitige Informationen:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Nachdem wir nun geschätzt haben, wie korreliert die beiden Statistiken sind, können wir die endgültige Schätzung berechnen:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Das Ergebnis der Berechnung ist 744,311823994677, also 744,312 auf drei Dezimalstellen gerundet.
Der Einfachheit halber ist hier der gesamte Code in einem Block:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Abschließende Gedanken
Die endgültige Schätzung ist in diesem Fall unvollkommen – die Beispielabfrage gibt tatsächlich 441 zurück Zeilen.
Um eine bessere Schätzung zu erhalten, könnten wir dem Optimierer bessere Informationen über die Dichte des Bin liefern und Shelf Spalten mit einer mehrspaltigen Statistik. Zum Beispiel:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Mit dieser Statistik (entweder wie angegeben oder als Nebeneffekt des Hinzufügens eines ähnlichen mehrspaltigen Index) ist die Kardinalitätsschätzung für die Beispielabfrage genau richtig. Es ist jedoch selten, eine so einfache Aggregation zu berechnen. Mit zusätzlichen Prädikaten ist die mehrspaltige Statistik möglicherweise weniger effektiv. Dennoch ist es wichtig, daran zu denken, dass die zusätzlichen Dichteinformationen, die von mehrspaltigen Statistiken bereitgestellt werden, für Aggregationen (sowie Gleichheitsvergleiche) nützlich sein können.
Ohne eine mehrspaltige Statistik kann eine aggregierte Abfrage mit zusätzlichen Prädikaten möglicherweise dennoch die in diesem Artikel gezeigte grundlegende Logik verwenden. Anstatt die Formel beispielsweise auf die Tabellenkardinalität anzuwenden, kann sie Schritt für Schritt auf Eingabehistogramme angewendet werden.
Zugehöriger Inhalt:Kardinalitätsschätzung für ein Prädikat auf einem COUNT-Ausdruck