SQL Server 2005 fügte die Möglichkeit hinzu, Nichtschlüsselspalten in einen nicht gruppierten Index aufzunehmen. In SQL Server 2000 und früher waren für einen nicht gruppierten Index alle für einen Index definierten Spalten Schlüsselspalten, was bedeutete, dass sie Teil jeder Ebene des Index waren, von der Wurzel bis zur Blattebene. Wenn eine Spalte als eingeschlossene Spalte definiert ist, ist sie nur Teil der Blattebene. Books Online weist auf die folgenden Vorteile der enthaltenen Spalten hin:
- Das können Datentypen sein, die nicht als Indexschlüsselspalten erlaubt sind.
- Sie werden von der Datenbank-Engine bei der Berechnung der Anzahl der Indexschlüsselspalten oder der Indexschlüsselgröße nicht berücksichtigt.
Beispielsweise kann eine varchar(max)-Spalte nicht Teil eines Indexschlüssels sein, aber sie kann eine eingeschlossene Spalte sein. Außerdem wird diese varchar(max)-Spalte nicht auf die 900-Byte- (oder 16-Spalten-)Grenze angerechnet, die für den Indexschlüssel gilt.
Die Dokumentation erwähnt auch den folgenden Leistungsvorteil:
Ein Index mit Nichtschlüsselspalten kann die Abfrageleistung erheblich verbessern, wenn alle Spalten in der Abfrage entweder als Schlüssel- oder Nichtschlüsselspalten in den Index aufgenommen werden. Leistungssteigerungen werden erzielt, weil der Abfrageoptimierer alle Spaltenwerte im Index finden kann; Auf Tabellen- oder Clustered-Index-Daten wird nicht zugegriffen, was zu weniger Festplatten-E/A-Vorgängen führt.Wir können daraus schließen, dass wir unabhängig davon, ob es sich bei den Indexspalten um Schlüsselspalten oder Nichtschlüsselspalten handelt, eine Verbesserung der Leistung im Vergleich dazu erzielen, wenn nicht alle Spalten Teil des Index sind. Aber gibt es einen Leistungsunterschied zwischen den beiden Varianten?
Die Einrichtung
Ich habe eine Kopie der AdventuresWork2012-Datenbank installiert und die Indizes für die Sales.SalesOrderHeader-Tabelle mit Kimberly Tripps Version von sp_helpindex überprüft:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Standardindizes für Sales.SalesOrderHeader
Wir beginnen mit einer einfachen Abfrage zum Testen, die Daten aus mehreren Spalten abruft:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Wenn wir dies mit SQL Sentry Plan Explorer für die AdventureWorks2012-Datenbank ausführen und den Plan und die Tabellen-I/O-Ausgabe überprüfen, sehen wir, dass wir einen Clustered-Index-Scan mit 689 logischen Lesevorgängen erhalten:
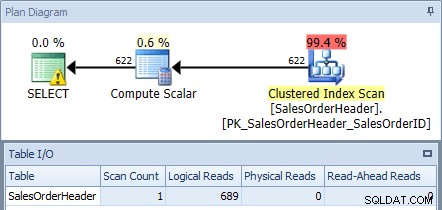
Ausführungsplan aus der ursprünglichen Abfrage
(In Management Studio können Sie die E/A-Metriken mit SET STATISTICS IO ON; anzeigen .)
Das SELECT hat ein Warnsymbol, weil der Optimierer einen Index für diese Abfrage empfiehlt:
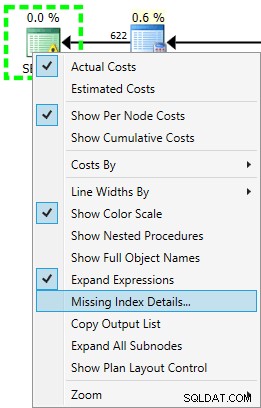
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Zuerst erstellen wir den vom Optimierer empfohlenen Index (mit dem Namen NCI1_included) sowie die Variante mit allen Spalten als Schlüsselspalten (mit dem Namen NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Wenn wir die ursprüngliche Abfrage erneut ausführen und sie einmal mit NCI1 und einmal mit NCI1_included andeuten, sehen wir einen ähnlichen Plan wie das Original, aber dieses Mal gibt es eine Indexsuche für jeden nicht gruppierten Index mit entsprechenden Werten für Tabelle I/ O, und ähnliche Kosten (beide etwa 0,006):
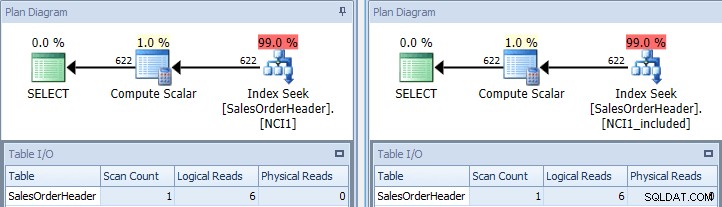
Ursprüngliche Abfrage mit Indexsuchen – Taste links, Include ein rechts
(Die Scan-Zählung ist immer noch 1, da die Indexsuche tatsächlich ein getarnter Bereichs-Scan ist.)
Nun, die AdventureWorks2012-Datenbank ist in Bezug auf die Größe nicht repräsentativ für eine Produktionsdatenbank, und wenn wir uns die Anzahl der Seiten in jedem Index ansehen, sehen wir, dass sie genau gleich sind:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
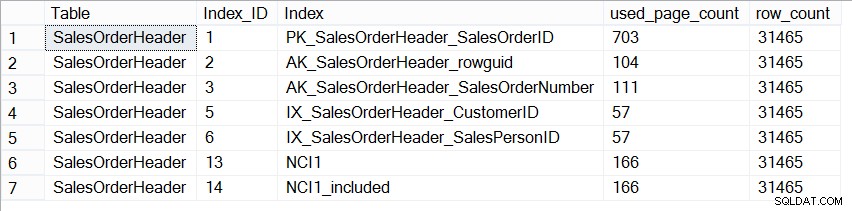
Größe der Indizes auf Sales.SalesOrderHeader
Wenn es um die Leistung geht, ist es ideal (und macht mehr Spaß), mit einem größeren Datensatz zu testen.
Test 2
Ich habe eine Kopie der AdventureWorks2012-Datenbank mit einer SalesOrderHeader-Tabelle mit über 200 Millionen Zeilen (Skript HIER). Lassen Sie uns also dieselben nicht gruppierten Indizes in dieser Datenbank erstellen und die Abfragen erneut ausführen:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
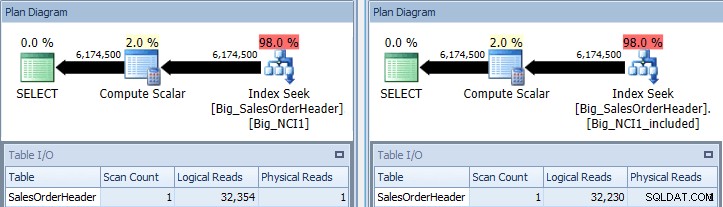
Originalabfrage mit Indexsuchen gegen Big_NCI1 (l) und Big_NCI1_Included ( r)
Jetzt bekommen wir einige Daten. Die Abfrage gibt über 6 Millionen Zeilen zurück, und das Suchen jedes Index erfordert etwas mehr als 32.000 Lesevorgänge, und die geschätzten Kosten sind für beide Abfragen gleich (31.233). Noch keine Leistungsunterschiede, und wenn wir die Größe der Indizes überprüfen, sehen wir, dass der Index mit den enthaltenen Spalten 5.578 Seiten weniger hat:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Größe der Indizes auf Sales.Big_SalesOrderHeader
Wenn wir uns weiter damit beschäftigen und dm_dm_index_physical_stats überprüfen, können wir sehen, dass es Unterschiede in den Zwischenstufen des Index gibt:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
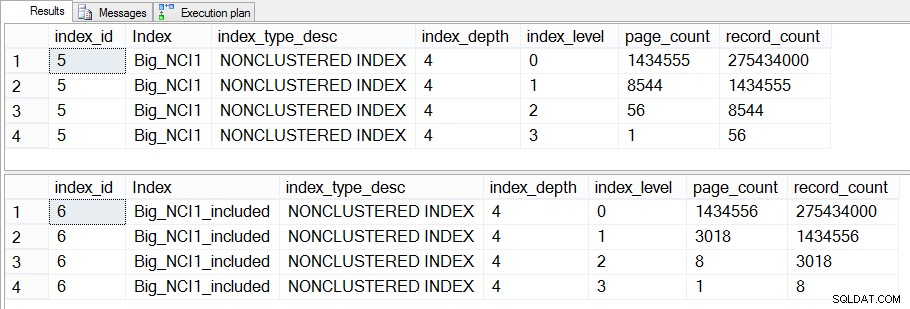
Größe der Indizes (stufenspezifisch) auf Sales.Big_SalesOrderHeader
Der Unterschied zwischen den mittleren Ebenen der beiden Indizes beträgt 43 MB, was vielleicht nicht signifikant ist, aber ich würde wahrscheinlich trotzdem dazu neigen, den Index mit eingeschlossenen Spalten zu erstellen, um Platz zu sparen – sowohl auf der Festplatte als auch im Speicher. Aus Abfrageperspektive sehen wir immer noch keine große Leistungsänderung zwischen dem Index mit allen Spalten im Schlüssel und dem Index mit den enthaltenen Spalten.
Test 3
Für diesen Test ändern wir die Abfrage und fügen einen Filter für [SubTotal] >= 100 hinzu zur WHERE-Klausel:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
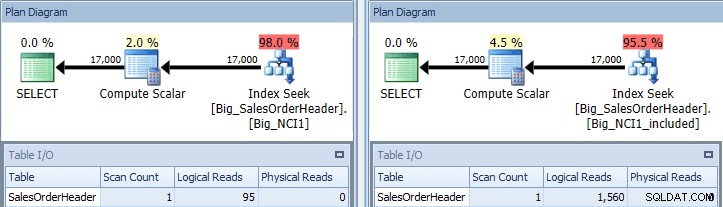
Ausführungsplan der Abfrage mit SubTotal-Prädikat für beide Indizes
Jetzt sehen wir einen Unterschied bei E/A (95 Lesevorgänge gegenüber 1.560), Kosten (0,848 gegenüber 1,55) und einen subtilen, aber bemerkenswerten Unterschied im Abfrageplan. Wenn Sie den Index mit allen Spalten im Schlüssel verwenden, ist das Suchprädikat die CustomerID und die SubTotal:
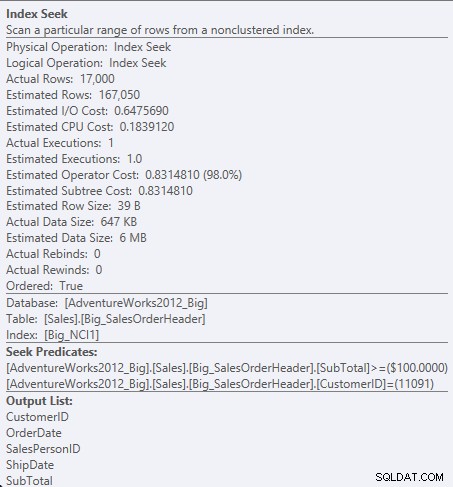
Prädikat gegen NCI1 suchen
Da SubTotal die zweite Spalte im Indexschlüssel ist, werden die Daten geordnet und die SubTotal befindet sich in den Zwischenebenen des Index. Die Engine kann direkt nach dem ersten Datensatz mit einer Kunden-ID von 11091 und einer Zwischensumme größer oder gleich 100 suchen und dann den Index durchlesen, bis keine Datensätze mehr für die Kunden-ID 11091 vorhanden sind.
Für den Index mit den enthaltenen Spalten existiert die Teilsumme nur auf der Blattebene des Index, also ist CustomerID das Suchprädikat und Teilsumme ist ein Restprädikat (im Screenshot nur als Prädikat aufgeführt):
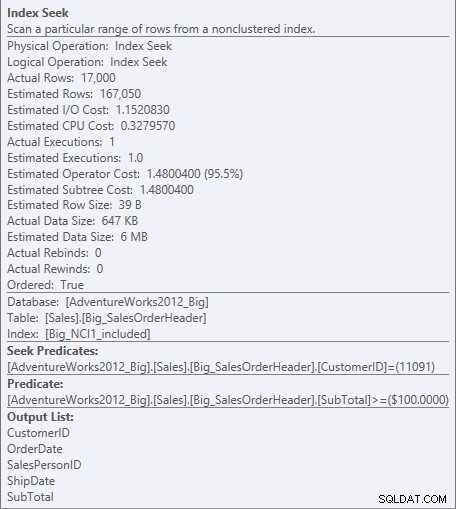
Suchprädikat und Restprädikat gegen NCI1_included
Die Engine kann direkt nach dem ersten Datensatz suchen, bei dem CustomerID 11091 ist, aber dann muss sie alle betrachten Datensatz für CustomerID 11091, um zu sehen, ob die Zwischensumme 100 oder höher ist, da die Daten nach CustomerID und SalesOrderID (Clustering-Schlüssel) geordnet sind.
Test 4
Wir werden eine weitere Variante unserer Abfrage ausprobieren und dieses Mal ORDER BY:
hinzufügenSELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
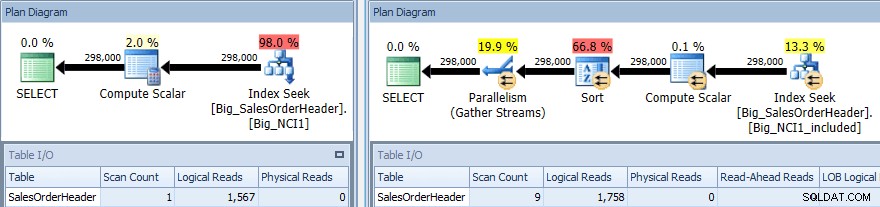
Ausführungsplan der Abfrage mit SORT für beide Indizes
Wieder haben wir eine Änderung der E/A (wenn auch sehr geringfügig), eine Änderung der Kosten (1,5 gegenüber 9,3) und eine viel größere Änderung der Planform; Wir sehen auch eine größere Anzahl von Scans (1 vs. 9). Die Abfrage erfordert, dass die Daten nach SubTotal sortiert werden; Wenn die Zwischensumme Teil des Indexschlüssels ist, wird sie sortiert, sodass die Datensätze für die Kunden-ID 11091 bereits in der angeforderten Reihenfolge vorliegen, wenn sie abgerufen werden.
Wenn SubTotal als eingeschlossene Spalte vorhanden ist, müssen die Datensätze für CustomerID 11091 sortiert werden, bevor sie an den Benutzer zurückgegeben werden können, daher fügt der Optimierer einen Sort-Operator in die Abfrage ein. Infolgedessen fordert (und erhält) die Abfrage, die den Index Big_NCI1_included verwendet, auch eine Speicherzuteilung von 29.312 KB, was bemerkenswert ist (und in den Eigenschaften des Plans gefunden wird).
Zusammenfassung
Die ursprüngliche Frage, die wir beantworten wollten, war, ob wir einen Leistungsunterschied sehen würden, wenn eine Abfrage den Index mit allen Spalten im Schlüssel verwendet, im Vergleich zu dem Index mit den meisten Spalten, die in der Blattebene enthalten sind. In unserer ersten Testreihe gab es keinen Unterschied, aber in unserem dritten und vierten Test schon. Letztlich kommt es auf die Abfrage an. Wir haben uns nur zwei Varianten angesehen – die eine hatte ein zusätzliches Prädikat, die andere ein ORDER BY – es gibt noch viele weitere.
Was Entwickler und DBAs verstehen müssen, ist, dass das Einschließen von Spalten in einen Index einige große Vorteile bietet, aber sie werden nicht immer die gleiche Leistung erbringen wie Indizes, die alle Spalten im Schlüssel enthalten. Es kann verlockend sein, Spalten, die nicht Teil von Prädikaten und Joins sind, aus dem Schlüssel zu verschieben und sie einfach einzuschließen, um die Gesamtgröße des Index zu verringern. In einigen Fällen erfordert dies jedoch mehr Ressourcen für die Abfrageausführung und kann die Leistung beeinträchtigen. Die Verschlechterung kann unbedeutend sein; es kann nicht sein ... Sie werden es nicht wissen, bis Sie es testen. Daher ist es beim Entwerfen eines Index wichtig, über die Spalten nach der führenden nachzudenken – und zu verstehen, ob sie Teil des Schlüssels sein müssen (z Säulen.
Wie es bei der Indizierung in SQL Server üblich ist, müssen Sie Ihre Abfragen mit Ihren Indizes testen, um die beste Strategie zu ermitteln. Es bleibt eine Kunst und eine Wissenschaft – zu versuchen, die minimale Anzahl von Indizes zu finden, um so viele Anfragen wie möglich zu erfüllen.