Lassen Sie uns unsere SQL-Reise beginnen, um die Aggregation von Daten in SQL und Arten von Aggregationen, einschließlich einfacher und gleitender Aggregationen, zu verstehen.
Bevor wir zu den Aggregationen springen, lohnt es sich, interessante Fakten zu berücksichtigen, die von einigen Entwicklern oft übersehen werden, wenn es um SQL im Allgemeinen und die Aggregation im Besonderen geht.
In diesem Artikel bezieht sich SQL auf T-SQL, das die Microsoft-Version von SQL ist und über mehr Funktionen als das Standard-SQL verfügt.
Mathematik hinter SQL
Es ist sehr wichtig zu verstehen, dass T-SQL auf einigen soliden mathematischen Konzepten basiert, obwohl es keine starre mathematische Sprache ist.
Laut dem Buch „Microsoft_SQL_Server_2008_T_SQL_Fundamentals“ von Itzik Ben-Gan dient SQL dazu, Daten in einem relationalen Datenbankverwaltungssystem (RDBMS) abzufragen und zu verwalten.
Das relationale Datenbankverwaltungssystem selbst basiert auf zwei soliden mathematischen Zweigen:
- Mengentheorie
- Prädikatenlogik
Mengentheorie
Die Mengenlehre ist, wie der Name schon sagt, ein Zweig der Mathematik über Mengen, die auch als Sammlungen bestimmter verschiedener Objekte bezeichnet werden können.
Kurz gesagt, in der Mengenlehre denken wir an Dinge oder Objekte als Ganzes, genauso wie wir an einen einzelnen Gegenstand denken.
Zum Beispiel ist ein Buch ein Satz aller definitiv unterschiedlichen Bücher, also nehmen wir ein Buch als Ganzes, was ausreicht, um Details aller darin enthaltenen Bücher zu erhalten.
Prädikatenlogik
Die Prädikatenlogik ist eine boolesche Logik, die abhängig von der Bedingung oder den Werten der Variablen wahr oder falsch zurückgibt.
Die Prädikatenlogik kann verwendet werden, um Integritätsregeln durchzusetzen (der Preis muss größer als 0,00 sein) oder um Daten zu filtern (wobei der Preis größer als 10,00 ist). Im Kontext von T-SQL haben wir jedoch drei logische Werte wie folgt:
- Richtig
- Falsch
- Unbekannt (Null)
Dies lässt sich wie folgt veranschaulichen:
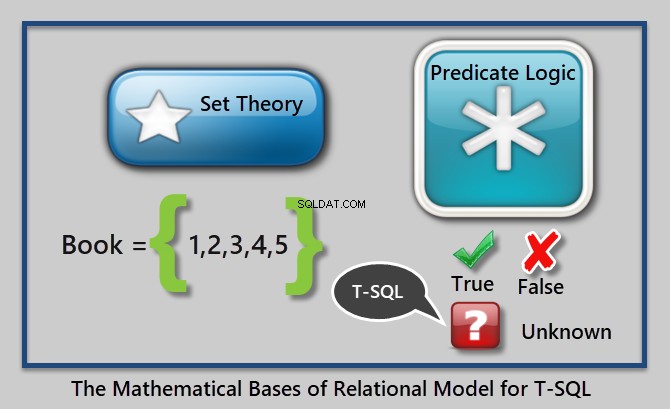
Ein Beispiel für ein Prädikat ist „Wo der Buchpreis größer als 10,00 ist“.
Das ist genug über Mathematik, aber denken Sie bitte daran, dass ich später in diesem Artikel darauf verweisen werde.
Warum das Aggregieren von Daten in SQL einfach ist
Beim Aggregieren von Daten in SQL in seiner einfachsten Form geht es darum, die Summen auf einen Schlag zu erfahren.
Wenn wir beispielsweise eine Kundentabelle haben, die eine Liste aller Kunden zusammen mit ihren Details enthält, können uns die aggregierten Daten der Kundentabelle die Gesamtzahl unserer Kunden geben.
Wie bereits erwähnt, stellen wir uns eine Menge als ein einzelnes Element vor, also wenden wir einfach eine Aggregatfunktion auf die Tabelle an, um die Summen zu erhalten.
Da SQL ursprünglich eine mengenbasierte Sprache ist (wie bereits erwähnt), ist es im Vergleich zu anderen Sprachen relativ einfacher, Aggregatfunktionen darauf anzuwenden.
Wenn wir beispielsweise eine Produkttabelle haben, die Datensätze aller Produkte in der Datenbank enthält, können wir die Zählfunktion sofort auf eine Produkttabelle anwenden, um die Gesamtzahl der Produkte zu erhalten, anstatt sie einzeln in einer Schleife zu zählen.
Datenaggregationsrezept
Um Daten in SQL zu aggregieren, benötigen wir mindestens die folgenden Dinge:
- Daten (Tabelle) mit sinnvoll aggregierten Spalten
- Eine auf die Daten anzuwendende Aggregatfunktion
Probedaten vorbereiten (Tabelle)
Nehmen wir ein Beispiel einer einfachen Bestelltabelle, die drei Dinge (Spalten) enthält:
- Bestellnummer (OrderId)
- Datum, an dem die Bestellung aufgegeben wurde (OrderDate)
- Betrag der Bestellung (TotalAmount)
Lassen Sie uns die AggregateSample-Datenbank erstellen, um fortzufahren:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Erstellen Sie nun die Bestelltabelle in der Beispieldatenbank wie folgt:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Beispieldaten auffüllen
Füllen Sie die Tabelle, indem Sie eine Zeile hinzufügen:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Sehen wir uns jetzt die Tabelle an:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
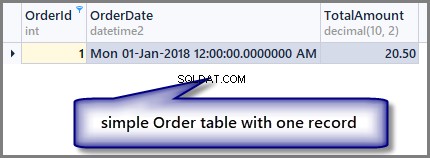
Bitte beachten Sie, dass ich in diesem Artikel dbForge Studio für SQL Server verwende, daher kann sich nur das Aussehen der Ausgabe unterscheiden, wenn Sie den gleichen Code in SSMS (SQL Server Management Studio) ausführen, es gibt keinen Unterschied, was Skripte und deren Ergebnisse betrifft.
Grundlegende Aggregatfunktionen
Die grundlegenden Aggregatfunktionen, die auf die Tabelle angewendet werden können, lauten wie folgt:
- Summe
- Zählen
- Minute
- maximal
- Durchschnitt
Aggregierende Einzeldatensatztabelle
Nun ist die interessante Frage:„Können wir Daten (Datensätze) in einer Tabelle aggregieren (summieren oder zählen), wenn sie wie in unserem Fall nur eine Zeile hat?“ Die Antwort ist „Ja“, wir können, obwohl es nicht viel Sinn macht, aber es kann uns helfen zu verstehen, wie Daten für die Aggregation vorbereitet werden.
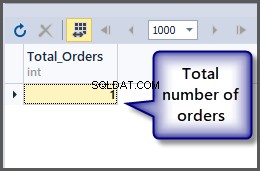
Um die Gesamtzahl der Bestellungen zu erhalten, verwenden wir die Funktion count() mit der Tabelle, wie bereits erwähnt, wir können einfach die Aggregatfunktion auf die Tabelle anwenden, da SQL eine mengenbasierte Sprache ist und Operationen auf eine Menge angewendet werden können direkt.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
Was ist nun mit der Bestellung mit Mindest-, Höchst- und Durchschnittsbetrag für einen einzelnen Datensatz:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
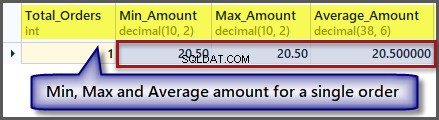
Wie wir aus der Ausgabe ersehen können, sind der minimale, maximale und durchschnittliche Betrag gleich, wenn wir einen einzelnen Datensatz haben, also ist die Anwendung einer Aggregatfunktion auf einen einzelnen Datensatz möglich, aber es liefert uns die gleichen Ergebnisse.
Wir benötigen mindestens mehr als einen Datensatz, um die aggregierten Daten zu verstehen.
Tabelle zum Aggregieren mehrerer Datensätze
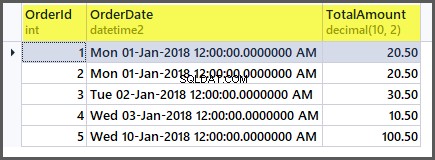
Fügen wir nun wie folgt vier weitere Datensätze hinzu:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
Die Tabelle sieht nun wie folgt aus:
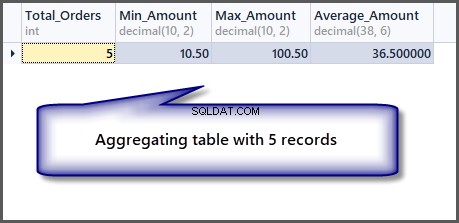
Wenn wir jetzt die Aggregatfunktionen auf die Tabelle anwenden, erhalten wir gute Ergebnisse:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
Aggregierte Daten gruppieren
Wir können die aggregierten Daten nach jeder Spalte oder Spaltengruppe gruppieren, um Aggregate basierend auf dieser Spalte zu erhalten.
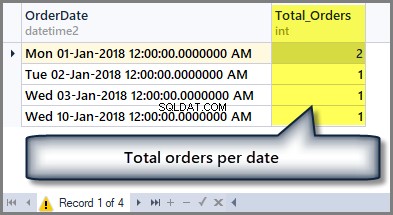
Zum Beispiel, wenn wir die Gesamtzahl der Bestellungen pro Datum wissen möchten Wir müssen die Tabelle mit der Group by-Klausel wie folgt nach Datum gruppieren:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
Die Ausgabe sieht wie folgt aus:
Wenn wir also die Summe aller Bestellsummen sehen möchten, Wir können die Summenfunktion einfach ohne Gruppierung wie folgt auf die Spalte Gesamtbetrag anwenden:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
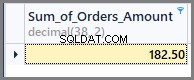
Um die Summe der Bestellungen pro Datum zu erhalten, fügen wir einfach group by date wie folgt zur obigen SQL-Anweisung hinzu:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
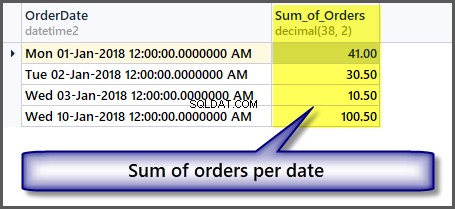
Ermitteln von Summen ohne Gruppieren von Daten
Wir können sofort Summen wie Gesamtbestellungen, maximale Bestellmenge, Mindestbestellmenge, Summe der Bestellmengen, durchschnittliche Bestellmenge erhalten, ohne dass sie gruppiert werden müssen, wenn die Aggregation für alle Tische gedacht ist.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
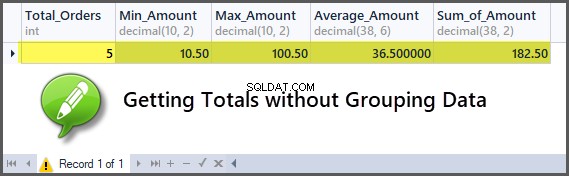
Hinzufügen von Kunden zu den Bestellungen
Lassen Sie uns etwas Spaß hinzufügen, indem Sie Kunden in unsere Tabelle hinzufügen. Wir können dies tun, indem wir eine weitere Kundentabelle erstellen und die Kunden-ID an die Auftragstabelle übergeben. Um es jedoch einfach zu halten und den Data-Warehouse-Stil nachzuahmen (bei dem Tabellen denormalisiert sind), füge ich die Kundennamenspalte wie folgt in die Auftragstabelle ein :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
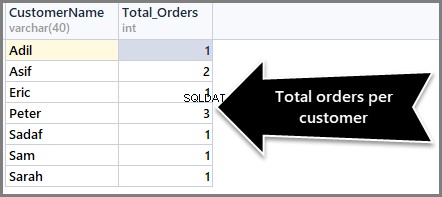
Gesamtbestellungen pro Kunde erhalten
Können Sie jetzt erraten, wie Sie die Gesamtbestellungen pro Kunde erhalten? Sie müssen nach Kunde (CustomerName) gruppieren und die Aggregatfunktion count() wie folgt auf alle Datensätze anwenden:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
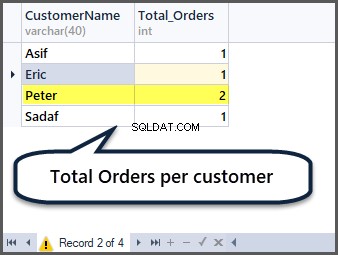
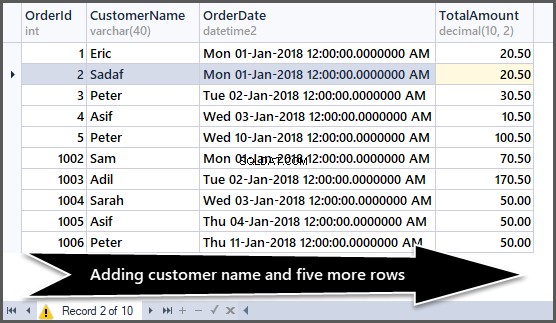
Hinzufügen von fünf weiteren Datensätzen zur Bestelltabelle
Jetzt fügen wir fünf weitere Zeilen zur einfachen Bestelltabelle wie folgt hinzu:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Sehen Sie sich jetzt die Daten an:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
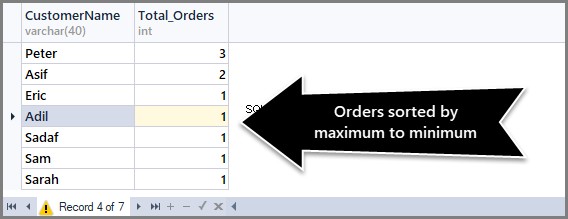
Erhalten der Gesamtbestellungen pro Kunde sortiert nach Höchst- bis Mindestbestellungen
Wenn Sie an den Gesamtbestellungen pro Kunde interessiert sind, sortiert nach maximalen bis minimalen Bestellungen, ist es keine schlechte Idee, dies wie folgt in kleinere Schritte aufzuteilen:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
Um die Anzahl der Bestellungen vom Maximum zum Minimum zu sortieren, müssen wir die Klausel Order By DESC (absteigende Reihenfolge) mit count() am Ende wie folgt verwenden:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
Erhalten der Gesamtbestellungen pro Datum, sortiert nach der letzten Bestellung zuerst
Mit der obigen Methode können wir nun die Gesamtbestellungen pro Datum ermitteln, sortiert nach der neuesten Bestellung zuerst, wie folgt:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
Die CAST-Funktion hilft uns, nur den Datumsteil zu erhalten. Die Ausgabe sieht wie folgt aus:
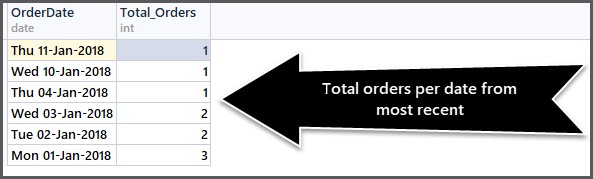
Sie können so viele Kombinationen wie möglich verwenden, solange sie sinnvoll sind.
Laufende Aggregationen
Nachdem wir nun mit der Anwendung von Aggregatfunktionen auf unsere Daten vertraut sind, wollen wir uns der fortgeschrittenen Form von Aggregationen zuwenden, und eine solche Aggregation ist die laufende Aggregation.
Laufende Aggregationen sind die Aggregationen, die auf eine Teilmenge von Daten und nicht auf den gesamten Datensatz angewendet werden, was uns hilft, kleine Fenster für die Daten zu erstellen.
Bisher haben wir gesehen, dass alle Aggregatfunktionen auf alle Zeilen der Tabelle angewendet werden, die nach einer Spalte wie Bestelldatum oder Kundenname gruppiert werden können, aber bei laufenden Aggregationen haben wir die Freiheit, die Aggregatfunktionen anzuwenden, ohne das Ganze zu gruppieren Datensatz.
Dies bedeutet natürlich, dass wir die Aggregatfunktion anwenden können, ohne die Group By-Klausel zu verwenden, was etwas seltsam für SQL-Anfänger ist (oder manche Entwickler übersehen dies manchmal), die mit den Windowing-Funktionen und dem Ausführen von Aggregationen nicht vertraut sind.
Windows auf Daten
Wie bereits erwähnt, wird die laufende Aggregation auf eine Teilmenge des Datensatzes oder (mit anderen Worten) auf kleine Datenfenster angewendet.
Stellen Sie sich Fenster als Satz(e) innerhalb eines Satzes oder als Tabelle(n) innerhalb einer Tabelle vor. Ein gutes Beispiel für das Fenstern von Daten in unserem Fall ist, dass wir die Bestelltabelle haben, die Bestellungen enthält, die an verschiedenen Daten aufgegeben wurden. Wenn also jedes Datum ein separates Fenster ist, können wir Aggregatfunktionen auf die gleiche Weise auf jedes Fenster anwenden, wie wir es angewendet haben die Tabelle.
Wenn wir die Bestelltabelle (SimpleOrder) nach Bestelldatum (OrderDate) wie folgt sortieren:
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows auf Daten, die zum Ausführen von Aggregationen bereit sind, finden Sie unten:

Wir können diese Fenster oder Teilmengen auch als sechs datumsbasierte Mini-Tabellen und Aggregate auf jede dieser Mini-Tabellen anwenden.
Verwendung von Partition By innerhalb der OVER()-Klausel
Laufende Aggregationen können angewendet werden, indem die Tabelle mit „Partition by“ innerhalb der OVER()-Klausel partitioniert wird.
Wenn wir beispielsweise die Bestelltabelle nach Daten partitionieren möchten, z. B. wenn jedes Datum eine Untertabelle oder ein Fenster im Datensatz ist, müssen wir die Daten nach Bestelldatum partitionieren, und dies kann durch Verwendung einer Aggregatfunktion wie COUNT( erreicht werden. ) mit OVER() und Partition by inside OVER() wie folgt:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

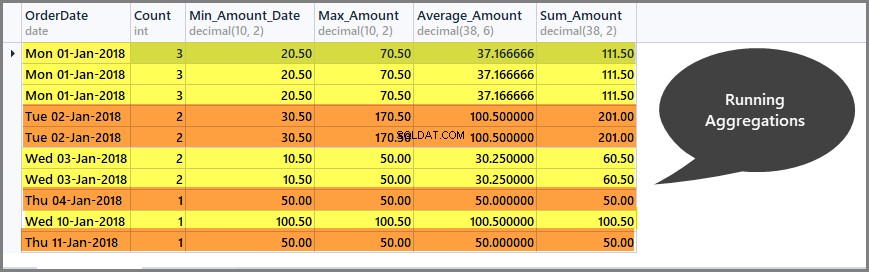
Fenster "Laufende Summen pro Datum abrufen" (Partition)
Laufende Aggregationen helfen uns, den Aggregationsumfang nur auf das definierte Fenster zu beschränken, und wir können wie folgt laufende Summen pro Fenster erhalten:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
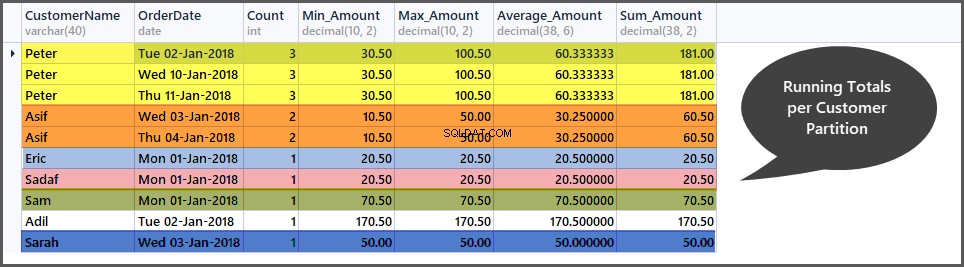
Laufende Summen pro Kundenfenster abrufen (Partition)
Genau wie die laufenden Summen pro Datumsfenster können wir auch die laufenden Summen pro Kundenfenster berechnen, indem wir den Auftragssatz (Tabelle) wie folgt in kleine Kundenuntermengen (Partitionen) partitionieren:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
Sliding Aggregations
Gleitende Aggregationen sind die Aggregationen, die auf die Frames innerhalb eines Fensters angewendet werden können, was bedeutet, dass der Bereich innerhalb des Fensters (Partition) weiter eingeschränkt wird.
Mit anderen Worten, laufende Summen geben uns Summen (Summe, Durchschnitt, Min, Max, Anzahl) für das gesamte Fenster (Teilmenge), das wir innerhalb einer Tabelle erstellen, während gleitende Summen uns Summen (Summe, Durchschnitt, Min, Max, Anzahl) liefern. für den Rahmen (Teilmenge von Teilmenge) innerhalb des Fensters (Teilmenge) der Tabelle.
Wenn wir beispielsweise ein Fenster mit Daten erstellen, die auf dem Kunden (aufgeteilt nach Kunden) basieren, können wir sehen, dass der Kunde „Peter“ drei Datensätze in seinem Fenster hat und alle Aggregationen auf diese drei Datensätze angewendet werden. Wenn wir nun einen Rahmen für jeweils nur zwei Zeilen erstellen möchten, bedeutet dies, dass die Aggregation weiter eingegrenzt und dann auf die erste und zweite Zeile und dann auf die zweite und dritte Zeile angewendet wird und so weiter.
Verwendung von ROWS PRECEEDING mit Order By innerhalb der OVER()-Klausel
Gleitende Aggregationen können angewendet werden, indem ROWS
Wenn wir beispielsweise Daten für nur zwei Zeilen gleichzeitig für jeden Kunden aggregieren möchten, müssen gleitende Aggregationen wie folgt auf die Bestelltabelle angewendet werden:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
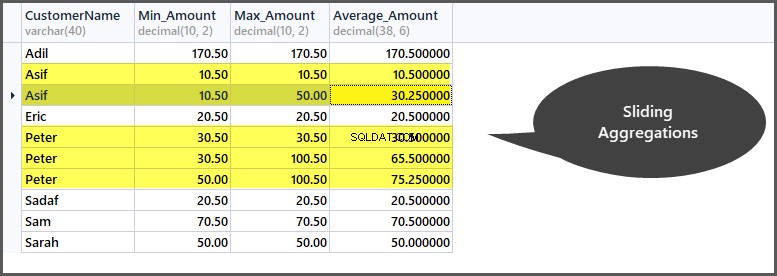
Um zu verstehen, wie es funktioniert, schauen wir uns die Originaltabelle im Kontext von Frames und Fenstern an:
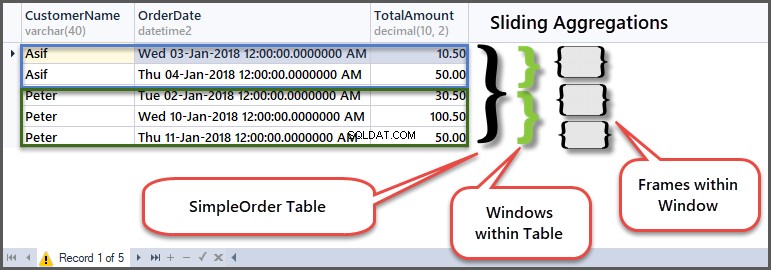
In der ersten Reihe des Fensters „Kunde Peter“ hat er eine Bestellung mit einem Betrag von 30,50 platziert, da dies der Beginn des Rahmens innerhalb des Kundenfensters ist, also Min und Max gleich sind, da es keine vorherige Reihe zum Vergleichen gibt.
Als Nächstes bleibt der Mindestbetrag gleich, aber der Höchstbetrag wird 100,50, da der Betrag der vorherigen Zeile (erste Zeile) 30,50 beträgt und dieser Zeilenbetrag 100,50 beträgt, sodass der Höchstbetrag der beiden 100,50 beträgt.
Als nächstes wird in der dritten Zeile der Vergleich mit der zweiten Zeile durchgeführt, sodass der Mindestbetrag der beiden Zeilen 50,00 und der Höchstbetrag der beiden Zeilen 100,50 beträgt.
MDX Year to Date (YTD)-Funktion und laufende Aggregationen
MDX ist eine mehrdimensionale Ausdruckssprache, die zum Abfragen mehrdimensionaler Daten (z. B. Würfel) verwendet wird und in Business-Intelligence-Lösungen (BI) verwendet wird.
Laut https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx funktioniert die Year to Date (YTD)-Funktion in MDX genauso wie laufende oder gleitende Aggregationen. Beispielsweise zeigt YTD, das häufig in Kombination mit keinem Parameter verwendet wird, eine laufende Summe bis heute an.
Das heißt, wenn wir diese Funktion auf das Jahr anwenden, erhalten wir alle Jahresdaten, aber wenn wir einen Drilldown bis März durchführen, erhalten wir alle Gesamtsummen vom Anfang des Jahres bis März und so weiter.
Dies ist sehr nützlich in SSRS-Berichten.
Dinge zu tun
Das ist es! Nachdem Sie diesen Artikel durchgearbeitet haben, sind Sie bereit, einige grundlegende Datenanalysen durchzuführen, und Sie können Ihre Fähigkeiten durch die folgenden Dinge weiter verbessern:
- Bitte versuchen Sie, ein Skript zum Ausführen von Aggregaten zu schreiben, indem Sie Fenster für andere Spalten wie den Gesamtbetrag erstellen.
- Bitte versuchen Sie auch, ein Skript für gleitende Aggregate zu schreiben, indem Sie Rahmen für andere Spalten wie Gesamtbetrag erstellen.
- Sie können der Tabelle (oder noch mehr Tabellen) weitere Spalten und Datensätze hinzufügen, um andere Aggregationskombinationen auszuprobieren.
- Die in diesem Artikel erwähnten Beispielskripts können in gespeicherte Prozeduren umgewandelt werden, die in SSRS-Berichten hinter Datensätzen verwendet werden.
Referenzen:
- Ytd (MDX)
- dbForge Studio für SQL Server