Ich setze eine Reihe von Artikeln über die Grundlagen von EXPLAIN in PostgreSQL fort, die eine kurze Besprechung von „Understanding EXPLAIN“ von Guillaume Lelarge ist.
Um das Problem besser zu verstehen, empfehle ich dringend, das Original „Understanding EXPLAIN“ von Guillaume Lelarge und zu lesen lies meinen ersten und zweiten Artikel.
BESTELLUNG PER
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Zunächst führen Sie einen sequentiellen Scan (Seq Scan) der foo-Tabelle durch und führen dann die Sortierung (Sort) durch. Das ->-Zeichen des EXPLAIN-Befehls gibt die Hierarchie der Schritte (Knoten) an. Je früher der Schritt ausgeführt wird, desto stärker wird er eingerückt.
Der Sortierschlüssel ist eine Bedingung für die Sortierung.
Sortiermethode:External Merge Disk Beim Sortieren wird eine temporäre Datei auf der Festplatte mit einer Kapazität von 4592 kB verwendet.
Prüfen Sie mit der Option BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
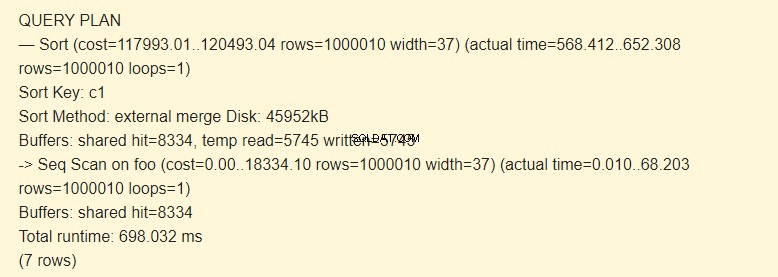
Tatsächlich bedeutet die Zeile temp read=5745 written=5745, dass 45960 KB (5745 Blöcke mit jeweils 8 KB) in der temporären Datei gespeichert und gelesen wurden. Die Operationen mit 8334 Blöcken wurden im Cache ausgeführt.
Die Operationen mit dem Dateisystem sind langsamer als Operationen im RAM.
Versuchen wir, die Speicherkapazität von work_mem zu erhöhen:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Sortiermethode:quicksort Speicher:102702kB – die gesamte Sortierung wurde im RAM durchgeführt.
Der Index lautet wie folgt:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Uns ist nur Index Scan geblieben, was die Geschwindigkeit der Abfrage erheblich beeinflusst hat.
GRENZE
Löschen Sie den zuvor erstellten Index:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Wie erwartet werden Seq Scan und Filter verwendet.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan liest Zeilen der Tabelle und vergleicht sie (Filter) mit der Bedingung. Sobald 10 Datensätze die Bedingung erfüllen, wird der Scan beendet. In unserem Fall mussten wir, um 10 Ergebniszeilen zu erhalten, nur 3063 Datensätze und nicht die gesamte Tabelle lesen. 3053 Zeilen dieser Nummer wurden zurückgewiesen (Zeilen durch Filter entfernt).
Dasselbe passiert mit Index Scan.
MITGLIED
Erstellen Sie eine neue Tabelle und generieren Sie Statistiken dafür:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Die Abfrage für zwei Tabellen lautet wie folgt:
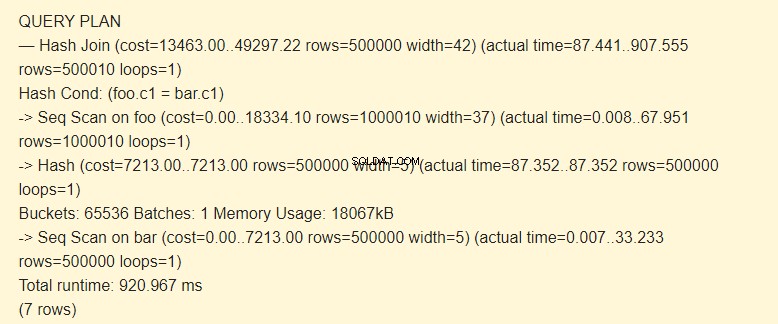
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Zuerst liest der sequentielle Scan (Seq Scan) den Bartisch. Für jede Zeile wird ein Hash (Hash) berechnet.
Dann scannt es die foo-Tabelle und für jede Zeile wird ein Hash berechnet, der mit dem Hash der bar-Tabelle durch die Bedingung Hash Cond verglichen wird (Hash Join). Wenn sie übereinstimmen, wird ein resultierender String ausgegeben.
18067 KB Speicher werden verwendet, um Hashes für die Bar zu speichern.
Fügen Sie den Index hinzu:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash wird nicht mehr verwendet. Merge Join und Index Scan auf den Indizes beider Tabellen verbessern die Leistung erheblich.
LINKS VERBINDEN:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
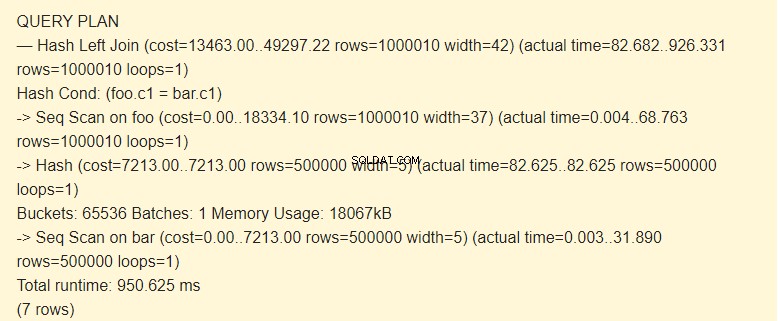
Seq-Scan?
Mal sehen, welches Ergebnis wir haben, wenn wir Seq Scan deaktivieren.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Laut Planer ist die Verwendung von Indizes teurer als die Verwendung von Hashes. Dies ist mit einer ausreichend großen Menge an zugewiesenem Speicher möglich. Erinnerst du dich, dass wir work_mem erhöht haben?
Wenn Sie jedoch nicht genügend Speicher haben, verhält sich der Scheduler anders:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Welches Ergebnis wird EXPLAIN angezeigt, wenn wir den Index-Scan deaktivieren?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
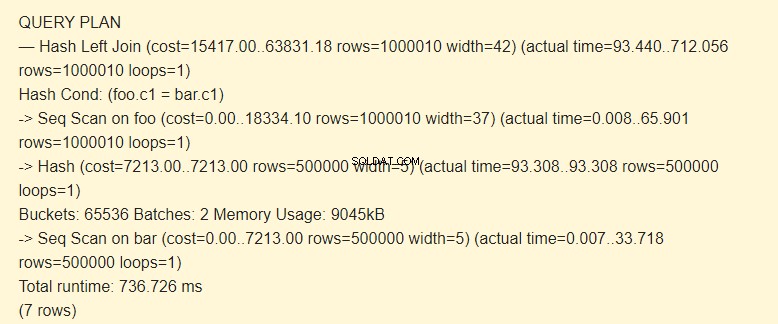
Chargen:2 hat erhöhte Kosten. Der gesamte Hash passte nicht in den Speicher; wir mussten es in zwei Pakete von 9045 kB aufteilen.
Vielen Dank für das Lesen meiner Artikel! Ich hoffe, sie waren nützlich. Sollten Sie Kommentare oder Feedback haben, lassen Sie es mich bitte wissen.