Das relationale Modell der Datenverwaltung wurde erstmals 1969 von Dr. Edgar F. Codd entwickelt. Moderne Verwaltungssysteme für relationale Datenbanken (RDBMS) sind an diesem Paradigma ausgerichtet. Die mit RDBMS identifizierte Schlüsselstruktur ist die logische Struktur, die als „Tabelle“ bezeichnet wird. Tabellen bestehen hauptsächlich aus Zeilen und Spalten (auch Datensätze und Attribute oder Tupel und Felder genannt). Im streng mathematischen Sinne der Begriff Tabelle wird eigentlich als Relation bezeichnet und erklärt den Begriff „Relational Model“. In der Mathematik ist eine Relation eine Darstellung einer Menge.
Das Ausdrucksattribut gibt eine gute Beschreibung des Zwecks einer Spalte – es charakterisiert die damit verbundene Reihe von Zeilen. Jede Spalte muss einen bestimmten Datentyp haben und jede Zeile muss einige eindeutige Identifizierungsmerkmale haben, die als „Schlüssel“ bezeichnet werden. Datenänderungen sind in der Regel effizienter, wenn sie mit dem relationalen Modell durchgeführt werden, während der Datenabruf mit dem älteren hierarchischen Modell, das in Modell-NoSQL-Systemen neu definiert wurde, möglicherweise schneller ist.
Datennormalisierung ist ein mathematischer Prozess zur Modellierung von Geschäftsdaten in einer Form, die sicherstellt, dass jede Entität durch eine einzige Beziehung (Tabelle) dargestellt wird. Die frühen Befürworter des relationalen Modells schlugen ein Konzept von Normalformen vor. Edgar Codd definierte die erste, die zweite und die dritte Normalform. Er wurde dann von Raymond F. Boyce unterstützt. Gemeinsam definierten sie die Boyce-Codd-Normalform. Inzwischen sind theoretisch sechs Normalformen definiert, aber in den meisten praktischen Anwendungen erweitern wir die Normalisierung normalerweise bis zur dritten Normalform. Jede Normalform ist bestrebt, Anomalien während der Datenänderung zu vermeiden und die Redundanz und Abhängigkeit von Daten innerhalb einer Tabelle zu reduzieren. Jede Ebene der Normalisierung neigt dazu, mehr Tabellen einzuführen, Redundanz zu reduzieren, die Einfachheit jeder Tabelle zu erhöhen, aber auch die Komplexität des gesamten Managementsystems für relationale Datenbanken zu erhöhen. Daher sind RDBM-Systeme strukturell tendenziell komplexer als hierarchische Systeme.
Warum Datenbanknormalisierung:Vier Anomalien
Datenspeicherung ohne Normalisierung verursacht eine Reihe von Problemen beim Datenverbrauch. Die Befürworter der Normalisierung nannten solche Probleme Anomalien. Um diese Anomalien zu beschreiben, schauen wir uns die in Abb. 1 dargestellten Daten an.

Abb. 1 Mitarbeitertisch
Listing 1. Basistabelle zur Demonstration der Datenbanknormalisierung.
1.1. Tabelle erstellen
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Zeilen einfügen
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Abfrage der Tabelle
select * from staffers;
Diese Tabelle stellt im Wesentlichen zwei Datensätze dar, die versehentlich kombiniert wurden:Mitarbeiternamen und Abteilungen. Beachten Sie, dass alle Mitarbeiter aus derselben Abteilung stammen:Engineering. Dies geschah der Einfachheit halber und um die Normalisierung zu demonstrieren. Es gibt drei Hauptprobleme, die mit der Manipulation dieser Struktur verbunden sind:
Die Einfügungsanomalie
Um einen neuen Datensatz einzufügen, müssen wir die Abteilungs- und Managernamen immer wieder wiederholen.
Die Löschanomalie
Um den Datensatz eines Mitarbeiters zu löschen, müssen wir auch den zugehörigen Manager und die zugehörige Abteilung löschen. Wenn ALLE Mitarbeiterdatensätze entfernt werden müssen, müssen wir auch alle Abteilungen und alle Manager entfernen.
Die Update-Anomalie
Wenn der Manager einer Abteilung geändert werden muss, müssen wir die Änderung in jeder einzelnen Zeile dieser Tabelle vornehmen, da die Werte für jeden Mitarbeiter dupliziert werden.
Datenbank-Normalformen
In den folgenden Abschnitten des Artikels werden wir versuchen, die 1., 2. und 3. Normalform zu beschreiben, die viel wahrscheinlicher in echten RDBM-Systemen beobachtet werden. Es gibt andere Erweiterungen der Theorie, wie die vierte, die fünfte und die Boyce-Codd-Normalform, aber in diesem Artikel beschränken wir uns auf drei Normalformen.
Die erste Normalform
Die 1. Normalform wird durch vier Regeln definiert:
Jede Spalte muss Werte desselben Datentyps enthalten.
Die Staffers-Tabelle erfüllt diese Regel bereits.
Jede Spalte in einer Tabelle muss atomar sein.
Das bedeutet im Wesentlichen, dass Sie den Inhalt einer Spalte teilen sollten, bis sie nicht mehr geteilt werden können. Beachten Sie, dass die Rolle Spalte in den Mitarbeitern Tabelle verstößt gegen Regel 2 für die Zeile mit StaffID=3.
Jede Zeile in einer Tabelle muss eindeutig sein.
Eindeutigkeit in normalisierten Tabellen wird normalerweise mit Primärschlüsseln erreicht. Ein Primärschlüssel definiert jede Zeile in einer Tabelle eindeutig. Meistens wird ein Primärschlüssel durch nur eine Spalte definiert. Ein Primärschlüssel, der aus mehr als einer Spalte besteht, wird als zusammengesetzter Schlüssel bezeichnet.
Die Reihenfolge, in der Datensätze gespeichert werden, spielt keine Rolle.
Um die Daten in den Stabs auszurichten Tabelle mit den Grundsätzen der ersten Normalform müssen wir die Tabelle wie in den Abbildungen 2, 3 und 4 gezeigt aufteilen.
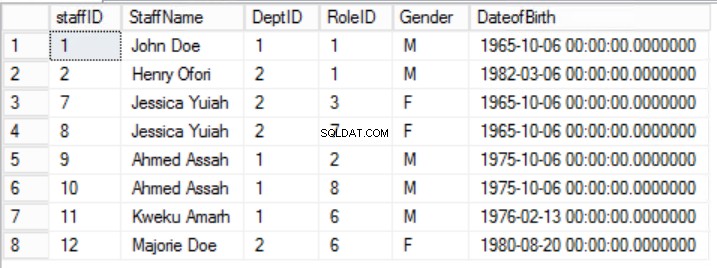
Abb. 2 Mitarbeitertisch
Wir haben die Daten in den Mitarbeitern eingegrenzt Tabelle und implementiert einen zusammengesetzten Primärschlüssel, um die Eindeutigkeit zu gewährleisten. Wir haben auch zwei zusätzliche Tabellen Rollen erstellt und Abteilungen die Beziehungen zu den Kern-Mitarbeitern haben Tabelle mit Fremdschlüsseln implementiert. Überprüfen Sie die DDL in Listing 2.
Listing 2. DDL neuer Mitarbeiter Tabelle für die erste Normalform.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
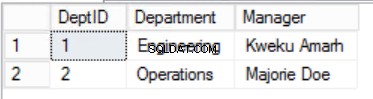
Abb. 3 Abteilungstabelle
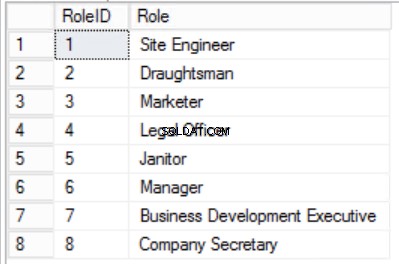
Abb. 4 Rollentabelle
Die zweite Normalform
Die 1. Normalform muss bereits vorhanden sein.
Jede Nicht-Schlüsselspalte darf keine teilweise Abhängigkeit vom Primärschlüssel haben.
Der Kernpunkt der zweiten Regel ist, dass alle Spalten der Tabelle von allen Spalten abhängen müssen, die zusammen den Primärschlüssel bilden. Wenn wir auf die Tabellen in den Abbildungen 2, 3 und 4 zurückblicken, stellen wir fest, dass wir alle Anforderungen der ersten Normalform erfüllt haben. Wir haben auch die Anforderungen der zweiten Normalform für zwei Tabellen Rollen erreicht und Abteilungen . Allerdings im Fall der Staffs Tabelle, wir haben immer noch ein Problem. Unser Primary Key setzt sich aus den Spalten StaffID und RoleID zusammen.
Regel 2 der zweiten Normalform wird hier dadurch verletzt, dass Geschlecht und Geburtsdatum von Mitarbeitern nicht von der RoleID abhängen. Es besteht eine teilweise Abhängigkeit.
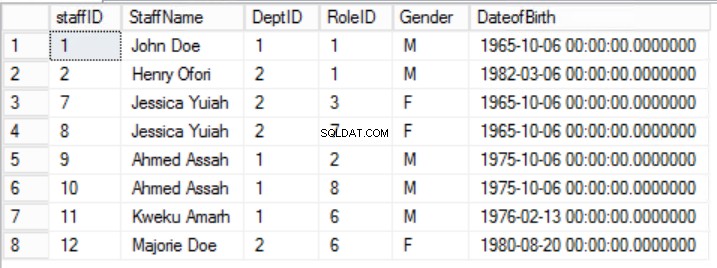
Abb. 5 Mitarbeiter für die Erste Normalform
In dem gegebenen Beispiel können wir versuchen, dies zu beheben, indem wir RoleID aus dem Primärschlüssel entfernen, aber wenn wir dies tun, werden wir eine andere Regel brechen:die Rolle der Eindeutigkeit, die in der ersten Normalform angegeben ist. Wir müssen einen anderen Ansatz wählen. Wir ändern die Staffs Tisch mit dem Verständnis, dass ein Mitarbeiter mehr als eine Rolle spielen kann. Siehe Abb. 6.
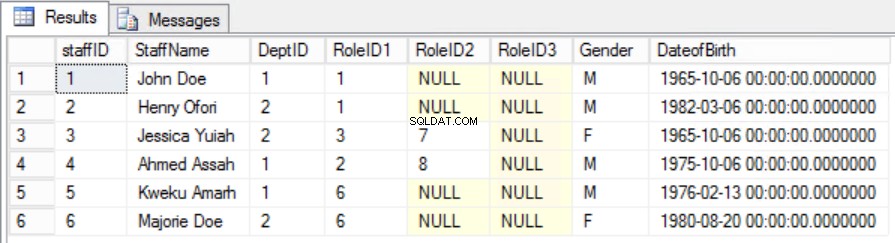
Abb. 6 Staffers Table für die zweite Normalform
Es ist uns gelungen, die Eindeutigkeit zu bewahren und die teilweise Abhängigkeit zu beseitigen.
Listing 3. DDL der New Staffers-Tabelle für die zweite Normalform.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Die dritte Normalform
Die 2. Normalform muss bereits vorhanden sein.
Jede Nicht-Schlüsselspalte darf keine transitive Abhängigkeit vom Primärschlüssel haben.
Der Kernpunkt der dritten Normalform ist, dass es keine Spalten geben darf, die von Nichtschlüsselspalten abhängen, selbst wenn diese Nichtschlüsselspalten bereits vom Primärschlüssel abhängen.
Nehmen Sie als Beispiel an, wir haben uns entschieden, den Mitarbeitern eine zusätzliche Spalte hinzuzufügen Tabelle wie in Abb. 7 gezeigt, um den Vorgesetzten des Mitarbeiters deutlich zu sehen. Damit hätten wir gegen die zweite Regel der dritten Normalform verstoßen, da der Managername von der DeptID und die DeptID wiederum von der StaffID abhängt. Dies ist eine transitive Abhängigkeit.
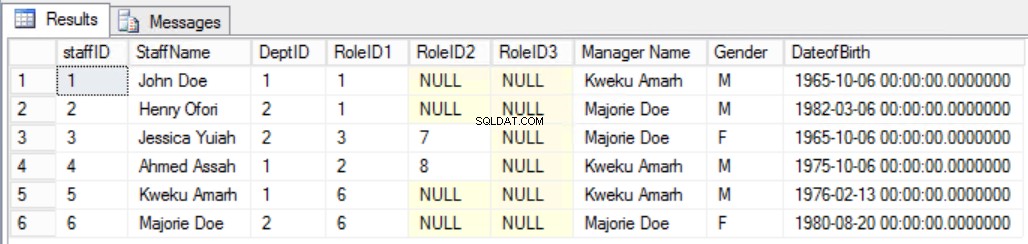
Abb. 7 Staffers Table für die dritte Normalform (gebrochene Regel)
Es wäre besser, das alte Formular beizubehalten und die erforderlichen Informationen mithilfe eines Joins zwischen der Staffers-Tabelle und der Department-Tabelle anzuzeigen.
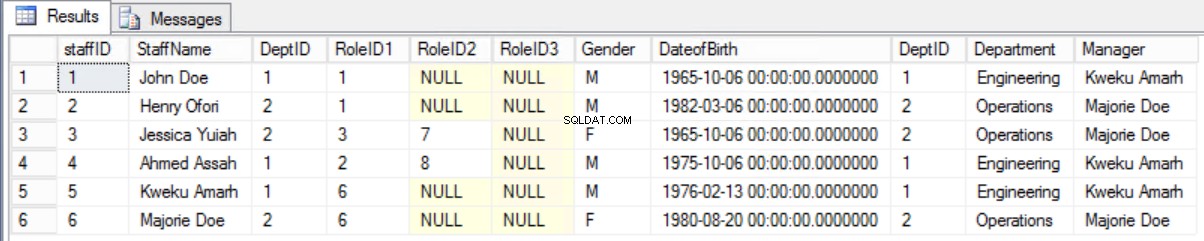
Abb. 8 Verbindung zwischen Mitarbeiter und Abteilung herstellen
Listing 4. Abfrage zum Anzeigen von Mitarbeitern und Managern.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktische Anwendung
Die meisten ausgereiften Anwendungen implementieren die Regeln der Normalisierung in angemessenem Umfang. Wir sehen, dass die Implementierung der Datennormalisierung zur Verwendung von Primärschlüsseleinschränkungen und Fremdschlüsseleinschränkungen führt. Darüber hinaus tauchen auch Probleme wie die Fremdschlüsselindizierung auf, wenn wir uns eingehender mit dem Thema befassen. Zuvor haben wir erwähnt, wie die fehlende Normalisierung die reibungslose Manipulation von Daten beeinträchtigen kann, wie in den Anomalien beim Einfügen, Löschen und Aktualisieren beschrieben. Ein Mangel an richtiger Normalisierung kann sich auch indirekt auf die Abfrageleistung auswirken.
Ich bin kürzlich auf eine Tabelle gestoßen, die die in Tabelle 1 gezeigte Form hatte, die wir Customer_Accounts nennen werden.
S/Nein | Name | Kontonummer | Telefonnummer |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernst Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabelle 1 Kundenkonten
Das Hauptproblem bei dieser Tabelle ist, dass sie gegen die zweite Regel der Ersten Normalform verstößt. Das Ergebnis in unserem Fall war, dass die Suche nach Kunden anhand ihrer Telefonnummern die Verwendung eines LIKE in der WHERE-Klausel und eines führenden % erforderte.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Die Auswirkung des obigen Konstrukts war, dass der Optimierer niemals einen Index verwendet hat, was ein großes Leistungsproblem darstellte.
Schlussfolgerung
Datennormalisierung liegt im Bereich des Datenbankdesigns und sowohl Entwickler als auch DBAs sollten die in diesem Artikel beschriebenen Regeln beachten. Es ist immer besser, die Normalisierung durchzuführen, bevor die Datenbank in Produktion geht. Die Vorteile eines richtig gestalteten Managementsystems für relationale Datenbanken sind die Mühe einfach wert.



