Der String-Datentyp ist einer der bedeutendsten Datentypen in jeder Programmiersprache. Ohne sie kann man kaum ein brauchbares Programm schreiben. Dennoch kennen viele Entwickler bestimmte Aspekte dieser Art nicht. Betrachten wir daher diese Aspekte.
Darstellung von Strings im Speicher
In .Net werden Strings nach der BSTR-Regel (Basic String oder Binary String) lokalisiert. Diese Methode der Darstellung von Zeichenfolgendaten wird in COM verwendet (das Wort „Basic“ stammt von der Programmiersprache Visual Basic, in der es ursprünglich verwendet wurde). Wie wir wissen, wird PWSZ (Pointer to Wide-character String, Zero-terminated) in C/C++ zur Darstellung von Strings verwendet. Bei einer solchen Stelle im Speicher befindet sich eine nullterminierte Zeichenfolge am Ende einer Zeichenfolge. Mit diesem Terminator kann das Ende der Zeichenfolge bestimmt werden. Die Zeichenfolgenlänge in PWSZ ist nur durch ein Volumen an freiem Speicherplatz begrenzt.
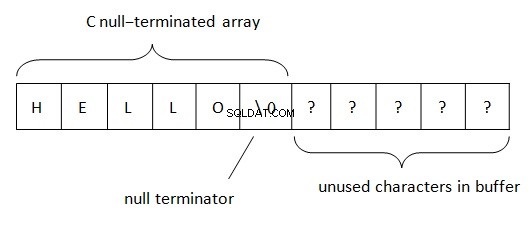
In BSTR ist die Situation etwas anders.
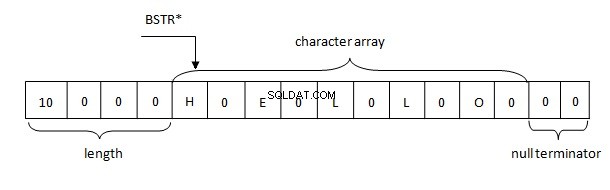
Grundlegende Aspekte der BSTR-String-Darstellung im Speicher sind die folgenden:
- Die Stringlänge ist durch eine bestimmte Zahl begrenzt. In PWSZ ist die Stringlänge durch die Verfügbarkeit von freiem Speicher begrenzt.
- BSTR-String zeigt immer auf das erste Zeichen im Puffer. PWSZ kann auf jedes Zeichen im Puffer zeigen.
- Bei BSTR steht, ähnlich wie bei PWSZ, das Nullzeichen immer am Ende. In BSTR ist das Nullzeichen ein gültiges Zeichen und kann überall im String gefunden werden.
- Da sich der Nullterminator am Ende befindet, ist BSTR mit PWSZ kompatibel, aber nicht umgekehrt.
Daher werden Zeichenfolgen in .NET gemäß der BSTR-Regel im Speicher dargestellt. Der Puffer enthält eine 4-Byte-String-Länge, gefolgt von zwei Byte langen Zeichen eines Strings im UTF-16-Format, dem wiederum zwei Null-Bytes (\u0000) folgen.
Die Verwendung dieser Implementierung hat viele Vorteile:Die Zeichenfolgenlänge muss nicht neu berechnet werden, da sie im Header gespeichert ist, eine Zeichenfolge kann überall Nullzeichen enthalten. Und das Wichtigste ist, dass die Adresse einer Zeichenfolge (gepinnt) einfach über nativen Code übergeben werden kann, wobei WCHAR* wird erwartet.
Wie viel Speicher benötigt ein String-Objekt?
Ich bin auf Artikel gestoßen, die besagen, dass die Größe des String-Objekts gleich Größe=20 + (Länge/2)*4 ist, aber diese Formel ist nicht ganz korrekt.
Zunächst einmal ist ein String ein Link-Typ, also enthalten die ersten vier Bytes SyncBlockIndex und die nächsten vier Bytes enthalten den Typzeiger.
String-Größe =4 + 4 + …
Wie ich oben erwähnt habe, wird die Zeichenfolgenlänge im Puffer gespeichert. Es ist ein Feld vom Typ Int, daher müssen wir weitere 4 Bytes hinzufügen.
String-Größe =4 + 4 + 4 + …
Um eine Zeichenfolge schnell (ohne Kopieren) an nativen Code zu übergeben, befindet sich das Null-Terminator am Ende jeder Zeichenfolge, die 2 Byte benötigt. Daher
String-Größe =4 + 4 + 4 + 2 + …
Es bleibt nur noch daran zu erinnern, dass jedes Zeichen in einer Zeichenfolge in der UTF-16-Codierung vorliegt und ebenfalls 2 Bytes benötigt. Deshalb:
String-Größe =4 + 4 + 4 + 2 + 2 * Länge =14 + 2 * Länge
Noch eine Sache und wir sind fertig. Der vom Speichermanager in CLR zugewiesene Speicher ist ein Vielfaches von 4 Bytes (4, 8, 12, 16, 20, 24, …). Wenn also die Zeichenfolgenlänge insgesamt 34 Bytes beträgt, werden 36 Bytes zugewiesen. Wir müssen unseren Wert auf die nächste größere Zahl runden, die ein Vielfaches von vier ist. Dafür brauchen wir:
Stringgröße =4 * ((14 + 2 * Länge + 3) / 4) (ganzzahlige Division)
Das Problem der Versionen :Bis .NET v4 gab es zusätzlich m_arrayLength Feld vom Typ int in der String-Klasse, das 4 Bytes benötigte. Dieses Feld ist eine echte Länge des Puffers, der einer Zeichenfolge zugeordnet ist, einschließlich des Null-Terminators, d. h. es ist Länge + 1. In .NET 4.0 wurde dieses Feld aus der Klasse entfernt. Dadurch belegt ein Objekt vom Typ String 4 Bytes weniger.
Die Größe eines leeren Strings ohne m_arrayLength Feld (d. h. in .Net 4.0 und höher) ist gleich =4 + 4 + 4 + 2 =14 Bytes, und mit diesem Feld (d. h. kleiner als .Net 4.0) ist seine Größe gleich =4 + 4 + 4 + 4 + 2 =18 Byte. Wenn wir 4 Bytes runden, beträgt die Größe entsprechend 16 bzw. 20 Bytes.
String-Aspekte
Also haben wir die Darstellung von Strings und die Größe, die sie im Speicher einnehmen, betrachtet. Lassen Sie uns nun über ihre Besonderheiten sprechen.
Grundlegende Aspekte von Zeichenfolgen in .NET sind die folgenden:
- Strings sind Referenztypen.
- Strings sind unveränderlich. Einmal erstellt, kann eine Zeichenfolge nicht (mit fairen Mitteln) geändert werden. Jeder Aufruf der Methode dieser Klasse gibt einen neuen String zurück, während der vorherige String zur Beute für den Garbage Collector wird.
- Strings definieren die Object.Equals-Methode neu. Daher vergleicht die Methode Zeichenwerte in Strings, nicht Linkwerte.
Betrachten wir jeden Punkt im Detail.
Strings sind Referenztypen
Strings sind echte Referenztypen. Das heißt, sie befinden sich immer auf dem Haufen. Viele von uns verwechseln sie mit Wertetypen, da sie sich genauso verhalten. Zum Beispiel sind sie unveränderlich und ihr Vergleich erfolgt nach Wert, nicht nach Referenzen, aber wir müssen bedenken, dass es sich um einen Referenztyp handelt.
Strings sind unveränderlich
- Strings sind für einen bestimmten Zweck unveränderlich. Die String-Unveränderlichkeit hat eine Reihe von Vorteilen:
- String-Typ ist Thread-sicher, da kein einzelner Thread den Inhalt eines Strings ändern kann.
- Die Verwendung von unveränderlichen Strings führt zu einer Verringerung der Speicherlast, da es nicht notwendig ist, 2 Instanzen desselben Strings zu speichern. Dadurch wird weniger Speicherplatz verbraucht und der Vergleich wird schneller durchgeführt, da nur Verweise verglichen werden. In .NET wird dieser Mechanismus String Interning (String Pool) genannt. Wir werden später darüber sprechen.
- Wenn wir einen unveränderlichen Parameter an eine Methode übergeben, müssen wir uns keine Sorgen mehr machen, dass er geändert wird (natürlich nur, wenn er nicht als ref oder out übergeben wurde).
Datenstrukturen können in zwei Typen unterteilt werden:ephemer und persistent. Flüchtige Datenstrukturen speichern nur ihre letzten Versionen. Persistente Datenstrukturen speichern alle ihre vorherigen Versionen während der Änderung. Letztere sind in der Tat unveränderlich, da ihre Operationen die Struktur vor Ort nicht verändern. Stattdessen geben sie eine neue Struktur zurück, die auf der vorherigen basiert.
Angesichts der Tatsache, dass Strings unveränderlich sind, könnten sie persistent sein, sind es aber nicht. Strings sind in .Net kurzlebig.
Nehmen wir zum Vergleich Java-Strings. Sie sind unveränderlich, wie in .NET, aber zusätzlich persistent. Die Implementierung der String-Klasse in Java sieht wie folgt aus:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Zusätzlich zu 8 Bytes im Header des Objekts, einschließlich einer Referenz auf den Typ und einer Referenz auf ein Synchronisationsobjekt, enthalten Strings die folgenden Felder:
- Ein Verweis auf ein Zeichenarray;
- Ein Index des ersten Zeichens der Zeichenfolge im char-Array (Offset vom Anfang)
- Die Anzahl der Zeichen in der Zeichenfolge;
- Der nach dem ersten Aufruf von HashCode() berechnete Hash-Code Methode.
Zeichenfolgen in Java benötigen mehr Speicher als in .NET, da sie zusätzliche Felder enthalten, die es ihnen ermöglichen, persistent zu sein. Aufgrund der Persistenz wird die Ausführung von String.substring() Methode in Java nimmt O(1) , da es kein Kopieren von Zeichenfolgen wie in .NET erfordert, wo die Ausführung dieser Methode O(n) erfordert .
Implementierung der Methode String.substring() in Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Wenn jedoch eine Quellzeichenfolge groß genug ist und die ausgeschnittene Teilzeichenfolge mehrere Zeichen lang ist, wird das gesamte Array von Zeichen der Anfangszeichenfolge im Speicher anstehen, bis es einen Verweis auf die Teilzeichenfolge gibt. Oder wenn Sie die empfangene Teilzeichenfolge mit Standardmitteln serialisieren und über das Netzwerk weiterleiten, wird das gesamte ursprüngliche Array serialisiert, und die Anzahl der über das Netzwerk übertragenen Bytes ist groß. Daher statt des Codes
s =ss.substring(3)
Der folgende Code kann verwendet werden:
s =neuer String(ss.substring(3)),
Dieser Code speichert den Verweis auf das Array von Zeichen der Quellzeichenfolge nicht. Stattdessen wird nur der tatsächlich verwendete Teil des Arrays kopiert. Übrigens, wenn wir diesen Konstruktor für einen String aufrufen, dessen Länge gleich der Länge des Arrays von Zeichen ist, findet kein Kopieren statt. Stattdessen wird der Verweis auf das ursprüngliche Array verwendet.
Wie sich herausstellte, wurde die Implementierung des String-Typs in der letzten Version von Java geändert. Jetzt gibt es keine Versatz- und Längenfelder in der Klasse. Das neue hash32 (mit anderem Hashing-Algorithmus) wurde stattdessen eingeführt. Das bedeutet, dass Strings nicht mehr persistent sind. Jetzt der String.substring -Methode erstellt jedes Mal einen neuen String.
String definiert Onbject.Equals neu
Die String-Klasse definiert die Object.Equals-Methode neu. Infolgedessen findet ein Vergleich statt, jedoch nicht nach Referenz, sondern nach Wert. Ich nehme an, dass Entwickler den Erstellern der String-Klasse für die Neudefinition des ==-Operators dankbar sind, da Code, der ==für String-Vergleiche verwendet, tiefgründiger aussieht als der Methodenaufruf.
if (s1 == s2)
Im Vergleich zu
if (s1.Equals(s2))
Übrigens vergleicht der Operator ==in Java nach Referenz. Wenn Sie Zeichenfolgen nach Zeichen vergleichen müssen, müssen wir die Methode string.equals() verwenden.
Stringinternierung
Betrachten wir abschließend das Internieren von Zeichenfolgen. Schauen wir uns ein einfaches Beispiel an – einen Code, der eine Zeichenfolge umkehrt.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Offensichtlich kann dieser Code nicht kompiliert werden. Der Compiler gibt Fehler für diese Strings aus, da wir versuchen, den Inhalt des Strings zu ändern. Jede Methode der String-Klasse gibt eine neue Instanz des Strings zurück, anstatt dessen Inhaltsänderung.
Die Zeichenfolge kann geändert werden, aber wir müssen den unsicheren Code verwenden. Betrachten wir das folgende Beispiel:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Nach Ausführung dieses Codes elbatummi era sgnirtS wird wie erwartet in den String geschrieben. Die Mutabilität von Strings führt zu einem ausgefallenen Fall im Zusammenhang mit dem Interning von Strings.
Internieren von Zeichenfolgen ist ein Mechanismus, bei dem ähnliche Literale im Speicher als ein einzelnes Objekt dargestellt werden.
Kurz gesagt, der Sinn des String-Interns ist der folgende:Es gibt eine einzige gehashte interne Tabelle innerhalb eines Prozesses (nicht innerhalb einer Anwendungsdomäne), in der Strings seine Schlüssel sind und Werte Referenzen auf sie sind. Während der JIT-Kompilierung werden wörtliche Zeichenfolgen nacheinander in eine Tabelle eingefügt (jede Zeichenfolge in einer Tabelle kann nur einmal gefunden werden). Aus dieser Tabelle werden während der Ausführung Verweise auf Literalstrings zugewiesen. Während der Ausführung können wir mit String.Intern einen String in die interne Tabelle stellen Methode. Außerdem können wir die Verfügbarkeit eines Strings in einer internen Tabelle mit String.IsInterned überprüfen Methode.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Beachten Sie, dass standardmäßig nur Zeichenfolgenliterale interniert werden. Da die gehashte interne Tabelle für die interne Implementierung verwendet wird, wird die Suche nach dieser Tabelle während der JIT-Kompilierung durchgeführt. Dieser Vorgang dauert einige Zeit. Wenn also alle Zeichenfolgen interniert sind, wird die Optimierung auf Null reduziert. Während der Kompilierung in IL-Code verkettet der Compiler alle Literalzeichenfolgen, da es nicht erforderlich ist, sie in Teilen zu speichern. Daher gibt die zweite Gleichheit true zurück .
Kommen wir nun zu unserem Fall zurück. Betrachten Sie den folgenden Code:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Es scheint, dass alles ziemlich offensichtlich ist und der Code Strings are immutable zurückgeben sollte . Allerdings nicht! Der Code gibt elbatummi era sgnirtS zurück . Es passiert genau wegen des Praktikums. Wenn wir Zeichenfolgen ändern, ändern wir ihren Inhalt, und da es sich um ein Literal handelt, wird es interniert und durch eine einzelne Instanz der Zeichenfolge dargestellt.
Wir können auf das Internieren von Strings verzichten, wenn wir das CompilationRelaxationsAttribute anwenden Attribut für die Versammlung. Dieses Attribut steuert die Genauigkeit des Codes, der vom JIT-Compiler der CLR-Umgebung erstellt wird. Der Konstruktor dieses Attributs akzeptiert die CompilationRelaxations Enumeration, die derzeit nur CompilationRelaxations.NoStringInterning enthält . Als Ergebnis wird die Baugruppe als diejenige gekennzeichnet, die kein Internieren erfordert.
Übrigens wird dieses Attribut in .NET Framework v1.0 nicht verarbeitet. Deshalb war es unmöglich, das Internieren zu deaktivieren. Ab Version 2 ist die mscorlib Assembly ist mit diesem Attribut gekennzeichnet. Es stellt sich also heraus, dass Strings in .NET mit dem unsicheren Code modifiziert werden können.
Was, wenn wir unsicher vergessen?
Zufällig können wir den Inhalt der Zeichenfolge ohne den unsicheren Code ändern. Stattdessen können wir den Reflexionsmechanismus verwenden. Dieser Trick war in .NET bis Version 2.0 erfolgreich. Danach haben uns die Entwickler der String-Klasse diese Möglichkeit genommen. In .NET 2.0 hat die String-Klasse zwei interne Methoden:SetChar für die Begrenzungsprüfung und InternalSetCharNoBoundsCheck das macht keine Grenzenüberprüfung. Diese Methoden setzen das angegebene Zeichen durch einen bestimmten Index. Die Implementierung der Methoden sieht folgendermaßen aus:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Daher können wir den String-Inhalt ohne unsicheren Code mit Hilfe des folgenden Codes ändern:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Wie erwartet gibt der Code elbatummi era sgnirtS zurück .
Das Problem der Versionen :In verschiedenen Versionen von .NET Framework kann string.Empty integriert werden oder nicht. Betrachten wir den folgenden Code:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); In .NET Framework 1.0, .NET Framework 1.1 und .NET Framework 3.5 mit Service Pack 1 (SP1) str1 und str2 sind nicht gleich. Derzeit string.Empty wird nicht interniert.
Aspekte der Leistung
Es gibt einen negativen Nebeneffekt des Internierens. Die Sache ist, dass der Verweis auf ein von CLR gespeichertes String-interniertes Objekt auch nach dem Ende der Anwendungsarbeit und sogar nach dem Ende der Anwendungsdomänenarbeit gespeichert werden kann. Daher ist es besser, auf große Literal-Strings zu verzichten. Wenn es immer noch erforderlich ist, muss das Interning durch Anwenden der CompilationRelaxations deaktiviert werden Attribut zur Assembly.