In diesem Artikel geht es um T-SQL (Transact-SQL)-Fensterfunktionen und ihre grundlegende Verwendung bei alltäglichen Datenanalyseaufgaben.
Es gibt viele Alternativen zu T-SQL, wenn es um die Datenanalyse geht. Wenn jedoch Verbesserungen im Laufe der Zeit und die Einführung von Windows-Funktionen in Betracht gezogen werden, ist T-SQL in der Lage, Datenanalysen auf einer grundlegenden Ebene und in einigen Fällen sogar darüber hinaus durchzuführen.
Über SQL-Fensterfunktionen
Machen wir uns zunächst mit SQL Window-Funktionen im Kontext der Microsoft-Dokumentation vertraut.
Microsoft-Definition
Eine Fensterfunktion berechnet einen Wert für jede Zeile im Fenster.
Einfache Definition
Eine Fensterfunktion hilft uns, uns auf einen bestimmten Teil (Fenster) der Ergebnismenge zu konzentrieren, sodass wir die Datenanalyse nur für diesen bestimmten Teil (Fenster) und nicht für die gesamte Ergebnismenge durchführen können.
Mit anderen Worten:SQL-Fensterfunktionen wandeln eine Ergebnismenge für Datenanalysezwecke in mehrere kleinere Mengen um.
Was ist eine Ergebnismenge
Einfach ausgedrückt besteht eine Ergebnismenge aus allen Datensätzen, die durch Ausführen einer SQL-Abfrage abgerufen werden.
Beispielsweise können wir eine Tabelle mit dem Namen Produkt erstellen und fügen Sie die folgenden Daten ein:
-- (1) Create the Product table CREATE TABLE [dbo].[Product] ( [ProductId] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(40) NOT NULL, [Region] VARCHAR(40) NOT NULL ) -- (2) Populate the Product table INSERT INTO Product (ProductId,Name,Region) VALUES (1,'Laptop','UK'),(2,'PC','UAE'),(3,'iPad','UK')
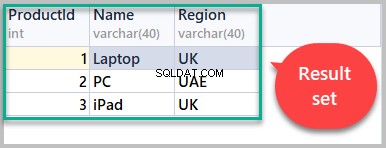
Jetzt enthält die mit dem folgenden Skript abgerufene Ergebnismenge alle Zeilen aus dem Produkt Tabelle:
-- (3) Result set SELECT [ProductId], [Name],[Region] FROM Product
Was ist ein Fenster
Es ist wichtig, zuerst das Konzept eines Fensters in Bezug auf SQL-Fensterfunktionen zu verstehen. In diesem Zusammenhang ist ein Fenster nur eine Möglichkeit, Ihren Umfang einzugrenzen, indem Sie auf einen bestimmten Teil der Ergebnismenge abzielen (wie wir bereits oben erwähnt haben).
Sie fragen sich jetzt vielleicht – was bedeutet „auf einen bestimmten Teil der Ergebnismenge abzielen“ eigentlich?
Zurück zu dem Beispiel, das wir uns angesehen haben, können wir ein SQL-Fenster basierend auf der Produktregion erstellen, indem wir die Ergebnismenge in zwei Fenster teilen.
Row_Number() verstehen
Um fortzufahren, müssen wir die Row_Number()-Funktion verwenden die den Ausgabezeilen vorübergehend eine Sequenznummer gibt.
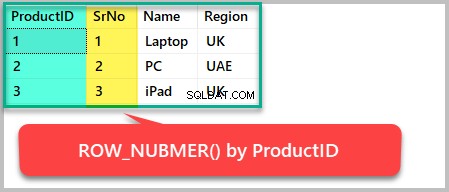
Wenn wir zum Beispiel eine Zeilennummer basierend auf ProductID, zum Resultset hinzufügen möchten wir müssen ROW_NUMBER() verwenden um es wie folgt nach Produkt-ID zu bestellen:
--Using the row_number() function to order the result set by ProductID SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID) AS SrNo,Name,Region FROM Product
Nun, wenn wir die Row_Number()-Funktion wollen um die Ergebnismenge nach ProductID zu sortieren absteigend, dann die Folge der Ausgabezeilen basierend auf ProductID ändert sich wie folgt:
--Using the row_number() function to order the result set by ProductID descending SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID DESC) AS SrNo,Name,Region FROM Product

Es gibt noch keine SQL-Fenster, da wir den Satz nur nach bestimmten Kriterien geordnet haben. Wie bereits erwähnt, bedeutet Windowing, dass die Ergebnismenge in mehrere kleinere Mengen aufgeteilt wird, um jede einzeln zu analysieren.
Erstellen eines Fensters mit Row_Number()
Um ein SQL-Fenster in unserer Ergebnismenge zu erstellen, müssen wir es basierend auf einer der darin enthaltenen Spalten partitionieren.
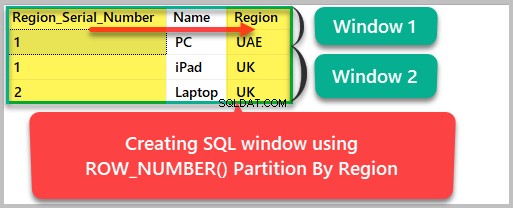
Wir können die Ergebnismenge jetzt wie folgt nach Regionen partitionieren:
--Creating a SQL window based on Region SELECT ROW_NUMBER() OVER (Partition by region ORDER BY Region) as Region_Serial_Number , Name, Region FROM dbo.Product
Select – Over-Klausel
Mit anderen Worten, Auswählen mit dem Über -Klausel ebnet den Weg für SQL-Fensterfunktionen, indem sie eine Ergebnismenge in kleinere Fenster aufteilt.
Laut Microsoft-Dokumentation Auswählen mit dem Über -Klausel definiert ein Fenster, das dann von jeder Fensterfunktion verwendet werden kann.
Lassen Sie uns nun eine Tabelle mit dem Namen KitchenProduct erstellen wie folgt:
CREATE TABLE [dbo].[KitchenProduct]
(
[KitchenProductId] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Country] VARCHAR(40) NOT NULL,
[Quantity] INT NOT NULL,
[Price] DECIMAL(10,2) NOT NULL
);
GO
INSERT INTO dbo.KitchenProduct
(Name, Country, Quantity, Price)
VALUES
('Kettle','Germany',10,15.00)
,('Kettle','UK',20,12.00)
,('Toaster', 'France',10,10.00)
,('Toaster','UAE',10,12.00)
,('Kitchen Clock','UK',50,20.00)
,('Kitchen Clock','UAE',35,15.00) Sehen wir uns nun die Tabelle an:
SELECT [KitchenProductId], [Name], [Country], [Quantity], [Price] FROM dbo.KitchenProduct

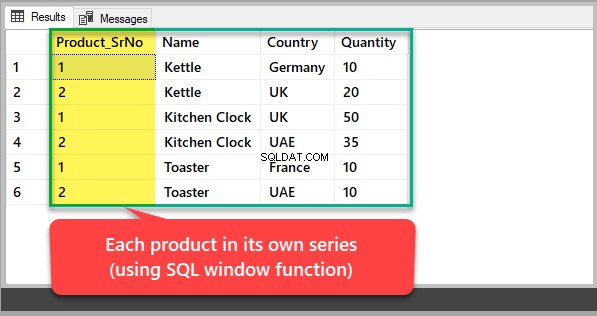
Wenn Sie jedes Produkt mit seiner eigenen Seriennummer statt einer Nummer basierend auf der allgemeinen Produkt-ID sehen möchten, müssten Sie eine SQL-Fensterfunktion verwenden, um die Ergebnismenge wie folgt nach Produkt zu partitionieren:
-- Viewing each product in its own series SELECT ROW_NUMBER() OVER (Partition by Name order by Name) Product_SrNo,Name,Country,Quantity FROM dbo.KitchenProduct
Kompatibilität (Select – Over-Klausel)
Laut Microsoft-Dokumentation , Select – Over-Klausel ist mit den folgenden SQL-Datenbankversionen kompatibel:
- SQL Server 2008 und höher
- Azure SQL-Datenbank
- Azure SQL Data Warehouse
- Paralleles Data Warehouse
Syntax
SELECT – OVER (Aufteilung nach
Bitte beachten Sie, dass ich die Syntax vereinfacht habe, um i zu machen t leicht verständlich; siehe bitte die Microsoft-Dokumentation, um die anzuzeigen voll Syntax.
Voraussetzungen
Dieser Artikel ist im Grunde für Anfänger geschrieben, aber es gibt dennoch einige Voraussetzungen, die beachtet werden müssen.
Vertrautheit mit T-SQL
Dieser Artikel setzt voraus, dass die Leser über Grundkenntnisse in T-SQL verfügen und in der Lage sind, grundlegende SQL-Skripts zu schreiben und auszuführen.
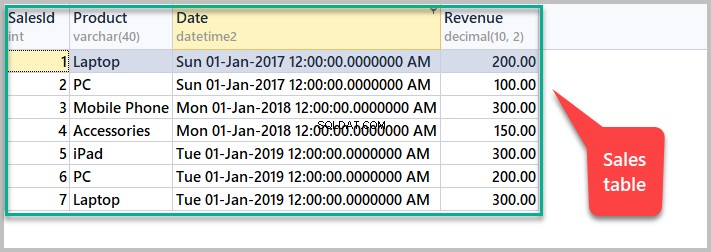
Richten Sie die Beispieltabelle Sales ein
Dieser Artikel erfordert die folgende Beispieltabelle, damit wir unsere Beispiele für SQL-Fensterfunktionen ausführen können:
-- (1) Create the Sales sample table
CREATE TABLE [dbo].[Sales]
(
[SalesId] INT NOT NULL IDENTITY(1,1),
[Product] VARCHAR(40) NOT NULL,
[Date] DATETIME2,
[Revenue] DECIMAL(10,2),
CONSTRAINT [PK_Sales] PRIMARY KEY ([SalesId])
);
GO
-- (2) Populating the Sales sample table
SET IDENTITY_INSERT [dbo].[Sales] ON
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (1, N'Laptop', N'2017-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (2, N'PC', N'2017-01-01 00:00:00', CAST(100.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (3, N'Mobile Phone', N'2018-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (4, N'Accessories', N'2018-01-01 00:00:00', CAST(150.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (5, N'iPad', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (6, N'PC', N'2019-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (7, N'Laptop', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
SET IDENTITY_INSERT [dbo].[Sales] OFF Zeigen Sie alle Verkäufe an, indem Sie das folgende Skript ausführen:
-- View sales SELECT [SalesId],[Product],[Date],[Revenue] FROM dbo.Sales
Gruppieren nach vs. SQL-Fensterfunktionen
Man kann sich fragen – was ist der Unterschied zwischen der Verwendung der Group By-Klausel und SQL-Fensterfunktionen?
Nun, die Antwort liegt in den Beispielen unten.
Gruppieren nach Beispiel
Um den Gesamtumsatz nach Produkt anzuzeigen, können wir Group By wie folgt verwenden:
-- Total sales by product using Group By SELECT Product ,SUM(REVENUE) AS Total_Sales FROM dbo.Sales GROUP BY Product ORDER BY Product

Die Group By-Klausel hilft uns also, den Gesamtumsatz zu sehen. Der Gesamtverkaufswert ist die Summe des Umsatzes für alle ähnlichen Produkte in derselben Zeile ohne Verwendung der Group By-Klausel. Was ist, wenn wir den Umsatz (Verkauf) jedes einzelnen Produkts zusammen mit dem Gesamtumsatz sehen möchten?
Hier kommen SQL-Fensterfunktionen ins Spiel.
Beispiel einer SQL-Fensterfunktion
Um das Produkt, den Umsatz und den Gesamtumsatz aller ähnlichen Produkte zu sehen, müssen wir die Daten mit OVER() auf Nebenproduktbasis partitionieren wie folgt:
-- Total sales by product using an SQL window function SELECT Product ,REVENUE ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) AS Total_Sales FROM dbo.Sales
Die Ausgabe sollte wie folgt aussehen:

So können wir jetzt ganz einfach die Verkäufe für jedes einzelne Produkt zusammen mit den Gesamtverkäufen für dieses Produkt sehen. Zum Beispiel der Umsatz für PC ist 100,00, aber der Gesamtumsatz (Summe der Einnahmen für den PC Produkt) beträgt 300,00, da zwei verschiedene PC-Modelle verkauft wurden.
Grundlegende Analyse mit den Aggregatfunktionen
Aggregatfunktionen geben einen einzelnen Wert zurück, nachdem sie Berechnungen für einen Datensatz durchgeführt haben.
In diesem Abschnitt werden wir SQL-Fensterfunktionen weiter untersuchen – insbesondere, indem wir sie zusammen mit Aggregatfunktionen verwenden, um grundlegende Datenanalysen durchzuführen.
Allgemeine Aggregatfunktionen
Die gebräuchlichsten Aggregatfunktionen sind:
- Summe
- Zählen
- Minute
- maximal
- Durchschn. (Durchschnitt)
Aggregierte Datenanalyse nach Produkt
Um die Ergebnismenge auf Nebenproduktbasis mit Hilfe von Aggregatfunktionen zu analysieren, müssen wir einfach eine Aggregatfunktion mit einer Nebenproduktpartition innerhalb der OVER()-Anweisung verwenden:
-- Data analysis by product using aggregate functions SELECT Product,Revenue ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY PRODUCT) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY PRODUCT) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY PRODUCT) as Average_Sales FROM dbo.Sales

Schaut man sich den PC genauer an oderLaptop Produkte, Sie werden sehen, wie Aggregatfunktionen neben der SQL-Fensterfunktion zusammenarbeiten.
Im obigen Beispiel können wir sehen, dass der Umsatzwert für PC beträgt beim ersten Mal 100,00 und beim nächsten Mal 200,00, aber der Gesamtumsatz beträgt 300,00. Ähnliche Informationen können für den Rest der Aggregatfunktionen eingesehen werden.
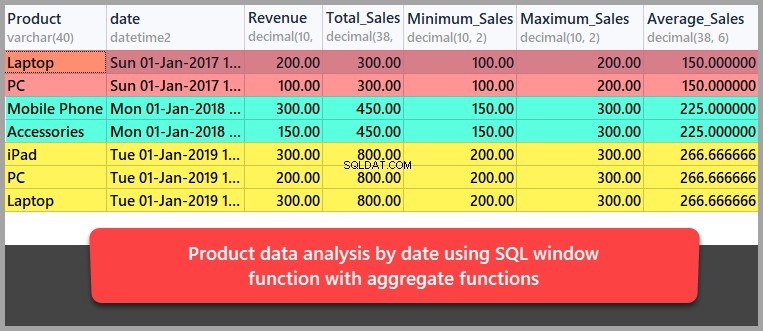
Aggregierte Datenanalyse nach Datum
Lassen Sie uns nun eine Datenanalyse der Produkte auf Datumsbasis mit SQL-Fensterfunktionen in Kombination mit Aggregatfunktionen durchführen.
Dieses Mal werden wir die Ergebnismenge wie folgt nach Datum und nicht nach Produkt partitionieren:
-- Data analysis by date using aggregate functions SELECT Product,date,Revenue ,SUM(REVENUE) OVER (PARTITION BY DATE) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY DATE) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY DATE) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY DATE) as Average_Sales FROM dbo.Sales
Damit haben wir grundlegende Datenanalysetechniken unter Verwendung des Ansatzes der SQL-Fensterfunktionen erlernt.
Dinge zu tun
Nachdem Sie nun mit den SQL-Fensterfunktionen vertraut sind, versuchen Sie bitte Folgendes:
- Denken Sie an die Beispiele, die wir uns angesehen haben, und führen Sie eine grundlegende Datenanalyse mit SQL-Fensterfunktionen in der Beispieldatenbank durch, die in diesem Artikel erwähnt wird
- Hinzufügen einer Customer-Spalte zur Sales-Beispieltabelle und sehen Sie, wie umfangreich Ihre Datenanalyse werden kann, wenn ihr eine weitere Spalte (Customer) hinzugefügt wird.
- Hinzufügen einer Spalte "Region" zur Beispieltabelle "Sales" und Durchführen einer grundlegenden Datenanalyse mit aggregierten Funktionen nach Region.