Die Funktionen OVER und PARTITION BY sind beides Funktionen, die verwendet werden, um eine Ergebnismenge nach bestimmten Kriterien zu portionieren.
Dieser Artikel erklärt, wie diese beiden Funktionen zusammen verwendet werden können, um partitionierte Daten auf sehr spezifische Weise abzurufen.
Einige Beispieldaten vorbereiten
Um unsere Beispielabfragen auszuführen, erstellen wir zunächst eine Datenbank mit dem Namen „studentdb“.
Führen Sie den folgenden Befehl in Ihrem Abfragefenster aus:
DATENBANK SCHULDB ERSTELLEN;
Als nächstes müssen wir die „student“-Tabelle in der „studentdb“-Datenbank erstellen. Die Schülertabelle hat fünf Spalten:ID, Name, Alter, Geschlecht und Gesamtpunktzahl.
Stellen Sie wie immer sicher, dass Sie gut gesichert sind, bevor Sie mit einem neuen Code experimentieren. Lesen Sie diesen Artikel zum Sichern von SQL Server-Datenbanken, wenn Sie sich nicht sicher sind.
Führen Sie die folgende Abfrage aus, um die Schülertabelle zu erstellen.
USE schooldbCREATE TABLE student( id INT PRIMARY KEY IDENTITY, name VARCHAR(50) NOT NULL, gender VARCHAR(50) NOT NULL, age INT NOT NULL, total_score INT NOT NULL, )
Schließlich müssen wir einige Dummy-Daten in die Datenbank einfügen, mit denen wir arbeiten können.
USE schooldbINSERT INTO student VALUES ('Jolly', 'Female', 20, 500), ('Jon', 'Male', 22, 545), ('Sara', 'Female', 25, 600), ('Laura', 'Weiblich', 18, 400), ('Alan', 'Männlich', 20, 500), ('Kate', 'Weiblich', 22, 500), ('Joseph', 'Männlich' , 18, 643), ('Mäuse', 'männlich', 23, 543), ('Wise', 'männlich', 21, 499), ('Elis', 'weiblich', 27, 400);
Richtig, wir sind jetzt bereit, an einem Problem zu arbeiten und zu sehen, wen wir Over und Partition By verwenden können, um es zu lösen.
Problem
Wir haben 10 Datensätze in der Schülertabelle und wir möchten den Namen, die ID und das Geschlecht für alle Schüler anzeigen, und zusätzlich möchten wir auch die Gesamtzahl der Schüler anzeigen, die jedem Geschlecht angehören, das Durchschnittsalter der Studenten jedes Geschlechts und die Summe der Werte in der Spalte total_score für jedes Geschlecht.
Die Ergebnismenge, nach der wir suchen, sieht wie folgt aus:
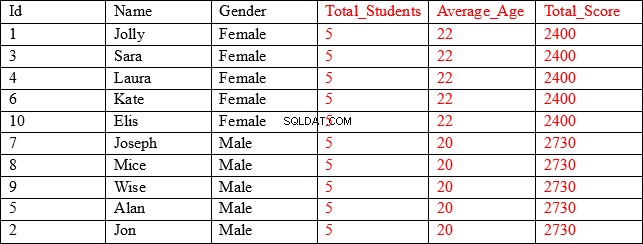
Wie Sie sehen können, enthalten die ersten drei Spalten (in Schwarz dargestellt) einzelne Werte für jeden Datensatz, während die letzten drei Spalten (in Rot dargestellt) aggregierte Werte enthalten, die nach der Spalte „Geschlecht“ gruppiert sind. Beispielsweise zeigen in der Spalte Average_Age die ersten fünf Zeilen das Durchschnittsalter und die Gesamtpunktzahl aller Datensätze an, bei denen das Geschlecht weiblich ist.
Unser Ergebnissatz enthält aggregierte Ergebnisse, die mit nicht aggregierten Spalten verbunden sind.
Um die aggregierten Ergebnisse gruppiert nach einer bestimmten Spalte abzurufen, können wir wie gewohnt die GROUP BY-Klausel verwenden.
USE schooldbSELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Sehen wir uns an, wie wir Total_Students, Average_Age und Total_Score der nach Geschlecht gruppierten Schüler abrufen können.
Sie sehen folgende Ergebnisse:

Lassen Sie uns dies jetzt erweitern und „id“ und „name“ (die nicht aggregierten Spalten in der SELECT-Anweisung) hinzufügen und sehen, ob wir unser gewünschtes Ergebnis erhalten.
USE schooldbSELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Wenn Sie die obige Abfrage ausführen, sehen Sie einen Fehler:

Der Fehler besagt, dass die ID-Spalte der Schülertabelle innerhalb der SELECT-Anweisung ungültig ist, da wir die GROUP BY-Klausel in der Abfrage verwenden.
Das bedeutet, dass wir eine Aggregatfunktion auf die ID-Spalte anwenden oder sie in der GROUP BY-Klausel verwenden müssen. Kurz gesagt, dieses Schema löst unser Problem nicht.
Lösung mit JOIN-Anweisung
Eine Lösung hierfür wäre die Verwendung der JOIN-Anweisung, um die Spalten mit aggregierten Ergebnissen mit Spalten zu verbinden, die nicht aggregierte Ergebnisse enthalten.
Dazu benötigen Sie eine Unterabfrage, die Geschlecht, Total_Students, Average_Age und den Total_Score der nach Geschlecht gruppierten Schüler abruft. Diese Ergebnisse können dann mit den Ergebnissen der Unterabfrage mit der äußeren SELECT-Anweisung verknüpft werden. Dies wird auf die Geschlechtsspalte der Unterabfrage angewendet, die das aggregierte Ergebnis enthält, und auf die Geschlechtsspalte der Studententabelle. Die äußere SELECT-Anweisung würde nicht aggregierte Spalten enthalten, d. h. „id“ und „name“, wie unten gezeigt.
USE schooldbSELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_ScoreFROM studentGROUP BY gender) AS Aggregationon Aggregation.gender =student.gender
Die obige Abfrage liefert das gewünschte Ergebnis, ist aber nicht die optimale Lösung. Wir mussten eine JOIN-Anweisung und eine Unterabfrage verwenden, was die Komplexität des Skripts erhöht. Dies ist keine elegante oder effiziente Lösung.
Ein besserer Ansatz besteht darin, die Klauseln OVER und PARTITION BY zusammen zu verwenden.
Lösung mit OVER und PARTITION BY
Um die Klauseln OVER und PARTITION BY zu verwenden, müssen Sie lediglich die Spalte angeben, nach der Sie Ihre aggregierten Ergebnisse partitionieren möchten. Dies lässt sich am besten anhand eines Beispiels erklären.
Schauen wir uns an, wie wir unser Ergebnis mit OVER und PARTITION BY erzielen.
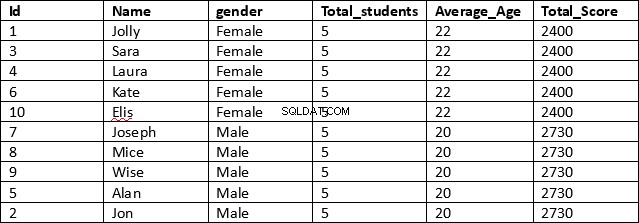
USE schooldbSELECT id, name, gender,COUNT(gender) OVER (PARTITION BY gender) AS Total_students,AVG(age) OVER (PARTITION BY gender) AS Average_Age,SUM(total_score) OVER (PARTITION BY gender) AS Total_ScoreFROM student
Dies ist ein viel effizienteres Ergebnis. In der ersten Zeile des Skripts werden die Spalten ID, Name und Geschlecht abgerufen. Diese Spalten enthalten keine aggregierten Ergebnisse.
Als Nächstes geben wir für die Spalten, die aggregierte Ergebnisse enthalten, einfach die aggregierte Funktion an, gefolgt von der OVER-Klausel, und dann geben wir innerhalb der Klammer die PARTITION BY-Klausel an, gefolgt vom Namen der Spalte, für die unsere Ergebnisse wie gezeigt partitioniert werden sollen unten.
Referenzen
- Microsoft – Verständnis der OVER-Klausel
- Mitternachts-DBA – Einführung in OVER und PARTITION BY
- StackOverflow – Unterschied zwischen PARTITION BY und GROUP BY