Einführung
Früher oder später bekommt jedes Informationssystem eine Datenbank, oft mehr als eine. Mit der Zeit sammelt diese Datenbank sehr viele Daten, von mehreren GB bis zu Dutzenden von TB. Um zu verstehen, wie sich die Funktionen bei steigenden Datenmengen verhalten, müssen wir die Daten generieren, um diese Datenbank zu füllen.

Alle vorgestellten und implementierten Skripte werden auf der JobEmplDB ausgeführt Datenbank eines Personalvermittlungsdienstes. Die Datenbankrealisierung ist hier verfügbar.
Ansätze zum Ausfüllen von Daten in Datenbanken zum Testen und Entwickeln
Die Datenbankentwicklung und das Testen umfassen zwei Hauptansätze zum Ausfüllen von Daten:
- Kopieren der gesamten Datenbank aus der Produktionsumgebung mit geänderten persönlichen und anderen sensiblen Daten. So sichern Sie die Daten und löschen vertrauliche Daten.
- Um synthetische Daten zu generieren. Es bedeutet, Testdaten zu generieren, die den realen Daten in Aussehen, Eigenschaften und Verbindungen ähnlich sind.
Der Vorteil von Ansatz 1 liegt darin, dass er die Daten und deren Verteilung nach unterschiedlichen Kriterien an die Produktionsdatenbank annähert. Es ermöglicht uns, alles genau zu analysieren und dementsprechend Schlussfolgerungen und Prognosen zu treffen.
Mit diesem Ansatz können Sie jedoch die Datenbank selbst nicht um ein Vielfaches vergrößern. Es wird problematisch, Änderungen in der Funktionalität des gesamten Informationssystems in der Zukunft vorherzusagen.
Andererseits können Sie unpersönliche, bereinigte Daten aus der Produktionsdatenbank analysieren. Darauf aufbauend können Sie definieren, wie die Testdaten generiert werden, die in Aussehen, Eigenschaften und Zusammenhängen den echten Daten ähneln. Auf diese Weise erzeugt Ansatz 1 Ansatz 2.
Lassen Sie uns nun beide Ansätze zum Ausfüllen von Daten in Datenbanken zum Testen und Entwickeln im Detail überprüfen.
Kopieren und Ändern von Daten in einer Produktionsdatenbank
Lassen Sie uns zunächst den allgemeinen Algorithmus zum Kopieren und Ändern der Daten aus der Produktionsumgebung definieren.
Der allgemeine Algorithmus
Der allgemeine Algorithmus lautet wie folgt:
- Erstellen Sie eine neue leere Datenbank.
- Erstellen Sie ein Schema in dieser neu erstellten Datenbank – dasselbe System wie das aus der Produktionsdatenbank.
- Kopieren Sie die erforderlichen Daten aus der Produktionsdatenbank in die neu erstellte Datenbank.
- Säubern und ändern Sie die geheimen Daten in der neuen Datenbank.
- Erstellen Sie eine Sicherungskopie der neu erstellten Datenbank.
- Liefern und stellen Sie die Sicherung in der erforderlichen Umgebung wieder her.
Allerdings wird der Algorithmus nach Schritt 5 komplizierter. Beispielsweise erfordert Schritt 6 eine spezifische, geschützte Umgebung für vorläufige Tests. Diese Phase muss sicherstellen, dass alle Daten unpersönlich sind und die geheimen Daten geändert werden.
Nach dieser Phase können Sie für die getestete Datenbank in der geschützten Nichtproduktionsumgebung erneut zu Schritt 5 zurückkehren. Anschließend leiten Sie das getestete Backup an die erforderlichen Umgebungen weiter, um es wiederherzustellen und für Entwicklung und Tests zu verwenden.
Wir haben den allgemeinen Algorithmus zum Kopieren und Ändern von Daten der Produktionsdatenbank vorgestellt. Lassen Sie uns beschreiben, wie es implementiert wird.
Realisierung des allgemeinen Algorithmus
Eine neue leere Datenbankerstellung
Sie können eine leere Datenbank mit Hilfe der CREATE DATABASE-Konstruktion wie hier erstellen.
Die Datenbank heißt JobEmplDB_Test . Es hat drei Dateigruppen:
- PRIMÄRE – Es ist standardmäßig die primäre Dateigruppe. Es definiert zwei Dateien:JobEmplDB_Test1(Pfad D:\DBData\JobEmplDB_Test1.mdf) , und JobEmplDB_Test2 (Pfad D:\DBData\JobEmplDB_Test2.ndf) . Die Anfangsgröße jeder Datei beträgt 64 MB und der Wachstumsschritt beträgt 8 MB für jede Datei.
- DBTableGroup – eine benutzerdefinierte Dateigruppe, die zwei Dateien bestimmt:JobEmplDB_TestTableGroup1 (Pfad D:\DBData\JobEmplDB_TestTableGroup1.ndf) und JobEmplDB_TestTableGroup2 (Pfad D:\DBData\JobEmplDB_TestTableGroup2.ndf) . Die Anfangsgröße jeder Datei beträgt 8 GB und der Wachstumsschritt beträgt 1 GB für jede Datei.
- DBIndexGroup – eine benutzerdefinierte Dateigruppe, die zwei Dateien bestimmt:JobEmplDB_TestIndexGroup1 (Pfad D:\DBData\JobEmplDB_TestIndexGroup1.ndf) und JobEmplDB_TestIndexGroup2 (Pfad D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . Die Anfangsgröße beträgt 16 GB für jede Datei, und der Wachstumsschritt beträgt 1 GB für jede Datei.
Außerdem enthält diese Datenbank ein Transaktionsjournal:JobEmplDB_Testlog , Pfad E:\DBLog\JobEmplDB_Testlog.ldf . Die Anfangsgröße der Datei beträgt 8 GB und der Wachstumsschritt beträgt 1 GB.
Kopieren des Schemas und der notwendigen Daten aus der Produktionsdatenbank in eine neu erstellte Datenbank
Um das Schema und die notwendigen Daten aus der Produktionsdatenbank in die neue zu kopieren, können Sie mehrere Tools verwenden. Erstens ist es das Visual Studio (SSDT). Oder Sie können Dienstprogramme von Drittanbietern verwenden wie:
- DbForge-Schemavergleich und DbForge-Datenvergleich
- ApexSQL Diff und Apex Data Diff
- SQL-Vergleichstool und SQL-Datenvergleichstool
Skripte für Datenänderungen erstellen
Grundlegende Anforderungen an die Skripte für Datenänderungen
1. Es muss unmöglich sein, die echten Daten mit diesem Skript wiederherzustellen.
z. B. passt die Umkehrung der Linien nicht, da sie es uns ermöglicht, die realen Daten wiederherzustellen. Normalerweise besteht das Verfahren darin, jedes Zeichen oder Byte durch ein pseudozufälliges Zeichen oder Byte zu ersetzen. Gleiches gilt für Datum und Uhrzeit.
2. Die Datenänderung darf die Selektivität ihrer Werte nicht verändern.
Es funktioniert nicht, dem Feld der Tabelle NULL zuzuweisen. Stattdessen müssen Sie sicherstellen, dass die gleichen Werte in den realen Daten in den geänderten Daten gleich bleiben. In realen Daten haben Sie beispielsweise einen Wert von 103785, der 12 Mal in der Tabelle gefunden wird. Wenn Sie diesen Wert in den geänderten Daten ändern, muss der neue Wert 12 Mal in den gleichen Feldern der Tabelle verbleiben.
3. Die Größe und Länge der Werte sollte sich in den geänderten Daten nicht wesentlich unterscheiden. Beispielsweise ersetzen Sie jedes Byte oder Zeichen durch ein pseudozufälliges Byte oder Zeichen. Der anfängliche String bleibt in Größe und Länge gleich.
4. Zusammenhänge in den Daten dürfen nach den Änderungen nicht aufgelöst werden. Es bezieht sich auf die externen Schlüssel und alle anderen Fälle, in denen Sie sich auf die geänderten Daten beziehen. Geänderte Daten müssen in denselben Beziehungen bleiben wie die echten Daten.
Implementierung von Datenänderungsskripten
Lassen Sie uns nun den besonderen Fall der Datenänderung betrachten, um die geheimen Informationen zu entpersonalisieren und zu verbergen. Das Beispiel ist die Rekrutierungsdatenbank.
Die Beispieldatenbank enthält die folgenden personenbezogenen Daten, die Sie entpersonalisieren müssen:
- Nach- und Vorname;
- Geburtsdatum;
- Das Ausstellungsdatum des Personalausweises;
- Das Fernzugriffszertifikat als Bytefolge;
- Die Servicegebühr für die Bewerbung des Lebenslaufs.
Zuerst prüfen wir einfache Beispiele für jeden Typ der geänderten Daten:
- Datums- und Uhrzeitänderung;
- Zahlenwertänderung;
- Änderung der Byte-Reihenfolge;
- Änderung der Charakterdaten.
Datums- und Uhrzeitänderung
Mit dem folgenden Skript können Sie ein zufälliges Datum und eine zufällige Uhrzeit abrufen:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Hier, @StartDate und @FinishDate sind die Anfangs- und Endwerte des Bereichs. Sie korrelieren jeweils für die pseudozufällige Datums- und Zeitgenerierung.
Um diese Daten zu generieren, verwenden Sie die Systemfunktionen RAND, CHECKSUM und NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Das Feld [DocDate] steht für das Ausstellungsdatum des Dokuments. Wir ersetzen es durch ein pseudozufälliges Datum, wobei wir die Datumsbereiche und ihre Einschränkungen berücksichtigen.
Die „untere“ Grenze ist das Geburtsdatum des Kandidaten. Der „obere“ Rand ist das aktuelle Datum. Die Zeit brauchen wir hier nicht, also kommt am Ende die Zeit- und Datumsformat-Umwandlung in das notwendige Datum. Sie können auf die gleiche Weise Pseudozufallswerte für jeden Teil des Datums und der Uhrzeit erhalten.
Zahlenwertänderung
Sie können eine zufällige Ganzzahl mit Hilfe des folgenden Skripts erhalten:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal und @MaxVal sind die Werte des Start- und Endbereichs für die Generierung von Pseudozufallszahlen. Wir generieren es mit den Systemfunktionen RAND, CHECKSUM und NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Das Feld [CountRequest] steht für die Anzahl der Anfragen, die Unternehmen für den Lebenslauf dieses Kandidaten stellen.
Ebenso können Sie Pseudozufallswerte für jeden numerischen Wert erhalten. Schauen Sie sich zum Beispiel die Zufallszahl vom Dezimaltyp (18,2) an:
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Daher können Sie die Servicegebühr für die Bewerbung des Lebenslaufs wie folgt aktualisieren:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Änderung der Byte-Reihenfolge
Mit dem folgenden Skript können Sie eine zufällige Bytefolge erhalten:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Länge steht für die Länge der Sequenz. Es definiert die Anzahl der zurückgegebenen Bytes. Dabei darf @Length nicht größer als 16 sein.
Die Generierung erfolgt mit Hilfe der Systemfunktionen CRYPT_GEN_RANDOM und NEWID.
Beispielsweise können Sie das Fernzugriffszertifikat für jeden Kandidaten folgendermaßen aktualisieren:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Wir erzeugen eine pseudozufällige Bytefolge derselben Länge, die zum Zeitpunkt der Änderung im Feld [RemoteAccessCertificate] vorhanden ist. Wir nehmen an, dass die Länge der Bytesequenz 16 nicht überschreitet.
Auf ähnliche Weise können wir unsere Funktion erstellen, die pseudozufällige Bytesequenzen beliebiger Länge zurückgibt. Es setzt die Ergebnisse der Systemfunktion CRYPT_GEN_RANDOM zusammen, indem es den einfachen „+“-Additionsoperator verwendet. In der Praxis reichen aber meist 16 Bytes aus.
Lassen Sie uns eine Beispielfunktion erstellen, die die pseudozufällige Bytefolge der bestimmten Länge zurückgibt, wobei es möglich sein wird, die Länge auf mehr als 16 Bytes einzustellen. Machen Sie dazu folgende Präsentation:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Wir brauchen es, um die Einschränkung zu umgehen, die uns verbietet, NEWID innerhalb der Funktion zu verwenden.
Erstellen Sie auf die gleiche Weise die nächste Präsentation für denselben Zweck:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Erstellen Sie eine weitere Präsentation:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Die Definitionen aller drei Funktionen sind hier. Und hier ist die Implementierung der Funktion, die eine pseudozufällige Bytefolge bestimmter Länge zurückgibt.
Zuerst definieren wir, ob die notwendige Funktion vorhanden ist. Wenn nicht – erstellen wir zuerst ein Gestüt. In jedem Fall beinhaltet der Code, die Definition der Funktion entsprechend zu ändern. Am Ende fügen wir die Beschreibung der Funktion über die erweiterten Eigenschaften hinzu. Weitere Einzelheiten zur Dokumentation der Datenbank finden Sie in diesem Artikel.
Um das Fernzugriffszertifikat für jeden Kandidaten zu aktualisieren, können Sie wie folgt vorgehen:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Wie Sie sehen, gibt es hier keine Begrenzung der Bytesequenzlänge.
Datenänderung – Charakterdatenänderung
Hier nehmen wir ein Beispiel für das englische und russische Alphabet, aber Sie können dies auch für jedes andere Alphabet tun. Die einzige Bedingung ist, dass seine Zeichen in den NCHAR-Typen vorhanden sein müssen.
Wir müssen eine Funktion erstellen, die die Zeile akzeptiert, jedes Zeichen durch ein pseudozufälliges Zeichen ersetzt und dann das Ergebnis zusammenfügt und zurückgibt.
Allerdings müssen wir zuerst verstehen, welche Zeichen wir brauchen. Dazu können wir das folgende Skript ausführen:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Wir erstellen die Tabelle [test].[TblCharacterCode], die die folgenden Felder enthält:
- ValueInt – der numerische Wert des Zeichens;
- ValueNChar – das Zeichen vom Typ NCHAR;
- ValueChar – das Zeichen vom Typ CHAR.
Sehen wir uns den Inhalt dieser Tabelle an. Wir benötigen die folgende Anfrage:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
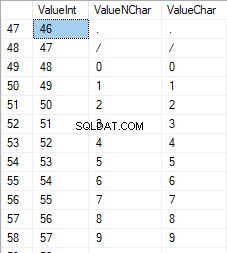
Die Zahlen liegen im Bereich von 48 bis 57:
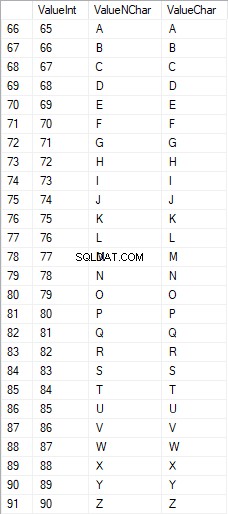
Die lateinischen Großbuchstaben liegen im Bereich von 65 bis 90:
Lateinische Zeichen in der unteren Pflege liegen im Bereich von 97 bis 122:
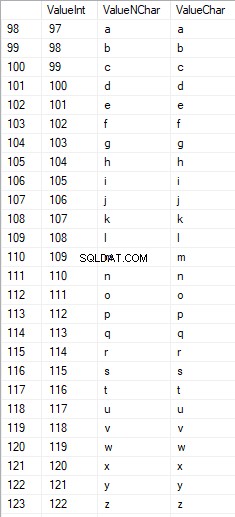
Russische Großbuchstaben liegen im Bereich von 1040 bis 1071:

Russische Zeichen in Kleinbuchstaben liegen im Bereich von 1072 bis 1103:


Und Zeichen im Bereich von 58 bis 64:

Wir wählen die erforderlichen Zeichen aus und fügen sie folgendermaßen in die Tabelle [test].[SelectCharactersCode] ein:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Lassen Sie uns nun den Inhalt dieser Tabelle mit dem folgenden Skript untersuchen:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Wir erhalten folgendes Ergebnis:

Auf diese Weise haben wir den [test].[SelectCharactersCode] Tabelle, wobei:
- ValueInt – der Zahlenwert des Zeichens
- ValueNChar – das Zeichen vom Typ NCHAR
- ValueChar – das Zeichen vom Typ CHAR
- IstZahl – das Kriterium, dass ein Zeichen eine Ziffer ist
- Ist in Großbuchstaben – das Kriterium eines Zeichens in Großbuchstaben
- Ist Latein – das Kriterium, dass ein Zeichen ein lateinisches Zeichen ist;
- IsRus – das Kriterium, dass ein Zeichen ein russisches Zeichen ist
- IstExtra – das Kriterium, dass ein Zeichen ein zusätzliches Zeichen ist
Jetzt können wir den Code für das Einfügen der erforderlichen Zeichen erhalten. So machen Sie es zum Beispiel für die lateinischen Kleinbuchstaben:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Wir erhalten folgendes Ergebnis:

Dasselbe gilt für die russischen Kleinbuchstaben:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Wir erhalten das folgende Ergebnis:

Dasselbe gilt für die Zeichen:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Das Ergebnis lautet wie folgt:

Wir haben also Codes, um die folgenden Daten separat einzufügen:
- Die lateinischen Buchstaben in Kleinbuchstaben.
- Die russischen Buchstaben in Kleinbuchstaben.
- Die Ziffern.
Es funktioniert sowohl für den NCHAR- als auch für den CHAR-Typ.
In ähnlicher Weise können wir ein Einfügungsskript für einen beliebigen Zeichensatz vorbereiten. Außerdem bekommt jeder Satz seine eigene Tabellierungsfunktion.
Der Einfachheit halber implementieren wir die allgemeine Tabellierungsfunktion, die den erforderlichen Datensatz für die zuvor ausgewählten Daten auf folgende Weise zurückgibt:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Das Endergebnis lautet wie folgt:

Das fertige Skript wird in die tabellarische Funktion [test].[GetSelectCharacters].
verpacktEs ist wichtig, ein zusätzliches UNION ALL am Ende des generierten Skripts zu entfernen, und in [ValueInt]=39 müssen wir ”’ in ”” ändern:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLDiese Tabellierungsfunktion gibt den folgenden Satz von Feldern zurück:
- Num – die Zeilennummer im zurückgegebenen Datensatz;
- ValueInt – der numerische Wert des Zeichens;
- ValueNChar – das Zeichen vom Typ NCHAR;
- ValueChar – das Zeichen vom Typ CHAR;
- IstZahl – das Kriterium, dass das Zeichen eine Ziffer ist;
- Ist in Großbuchstaben – das Kriterium, das definiert, dass das Zeichen in Großbuchstaben geschrieben ist;
- Ist Latein – das Kriterium, dass das Zeichen ein lateinisches Zeichen ist;
- IsRus – das Kriterium, dass das Zeichen ein russisches Zeichen ist;
- IstExtra – das Kriterium, das definiert, dass das Zeichen ein zusätzliches ist.
Für die Eingabe stehen Ihnen folgende Parameter zur Verfügung:
- @IsNumeral – wenn es die Zahlen zurückgeben soll;
- @IsUpperCase :
- 0 – es darf nur Kleinbuchstaben für Buchstaben zurückgeben;
- 1 – es darf nur die Großbuchstaben zurückgeben;
- NULL – es muss in jedem Fall Buchstaben zurückgeben.
- @IsLatin – es muss die lateinischen Zeichen zurückgeben
- @IsRus – es muss die russischen Zeichen zurückgeben
- @IsExtra – es muss zusätzliche Zeichen zurückgeben.
Alle Flags werden gemäß dem logischen ODER verwendet. Wenn Sie z. B. Ziffern und lateinische Zeichen in Kleinbuchstaben zurückgeben müssen, rufen Sie die Tabulatorfunktion folgendermaßen auf:
Wir erhalten das folgende Ergebnis:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Wir erhalten das folgende Ergebnis:

Wir implementieren die Funktion [test].[GetRandString], die die Zeile durch pseudozufällige Zeichen ersetzt, wobei die anfängliche Zeichenfolgenlänge beibehalten wird. Diese Funktion muss die Möglichkeit beinhalten, nur die Zeichen zu bedienen, die Ziffern sind. Dies kann z. B. nützlich sein, wenn Sie die Serie und Nummer des Personalausweises ändern.
Wenn wir die Funktion [test].[GetRandString] implementieren, erhalten wir zunächst den Satz von Zeichen, der erforderlich ist, um eine pseudozufällige Zeile der angegebenen Länge im Eingabeparameter @Length zu erzeugen. Die restlichen Parameter funktionieren wie oben beschrieben.
Dann fügen wir den empfangenen Datensatz in die Tabellenvariable @tbl ein . Diese Tabelle speichert die Felder [ID] – die Ordnungsnummer in der resultierenden Zeichentabelle und [Wert] – die Darstellung des Zeichens im NCHAR-Typ.
Danach generiert es in einem Zyklus eine Pseudozufallszahl im Bereich von 1 bis zur Mächtigkeit der zuvor empfangenen @tbl-Zeichen. Wir setzen diese Nummer in die [ID] der Tabellenvariable @tbl für die Suche. Wenn die Suche die Zeile zurückgibt, nehmen wir das Zeichen [Wert] und „kleben“ es an die resultierende Zeile @res.
Wenn die Arbeit des Zyklus endet, kommt die empfangene Zeile über die Variable @res zurück.
Sie können sowohl den Vor- als auch den Nachnamen des Kandidaten wie folgt ändern:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Daher haben wir die Implementierung der Funktion und ihre Verwendung für die Typen NCHAR und NVARCHAR untersucht. Das Gleiche können wir ganz einfach für die Typen CHAR und VARCHAR tun.
Manchmal müssen wir jedoch eine Zeile nach dem Zeichensatz erstellen, nicht nach den Buchstaben oder Zahlen. Auf diese Weise müssen wir zunächst die folgende Multi-Operator-Funktion [test].[GetListCharacters].
verwendenDie Funktion [test].[GetListCharacters] erhält die beiden folgenden Parameter für die Eingabe:
- @str – die Zeichenkette selbst;
- @IsGroupUnique – es definiert, ob eindeutige Zeichen in der Zeile gruppiert werden müssen.
Beim rekursiven CTE wird die Eingabezeile @str in die Zeichentabelle – @ListCharacters – umgewandelt. Diese Tabelle enthält die folgenden Felder:
- ID – die Ordnungsnummer der Zeile in der resultierenden Zeichentabelle;
- Charakter – die Darstellung des Zeichens in NCHAR(1)
- Zählen – die Anzahl der Wiederholungen des Zeichens in der Zeile (es ist immer 1, wenn der Parameter @IsGroupUnique=0)
Nehmen wir zwei Beispiele für die Verwendung dieser Funktion, um ihre Arbeit besser zu verstehen:
- Umwandlung der Zeile in die Liste der nicht eindeutigen Zeichen:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Wir erhalten das Ergebnis:

Dieses Beispiel zeigt, dass die Zeile „wie sie ist“ in die Liste der Zeichen umgewandelt wird, ohne sie nach der Eindeutigkeit der Zeichen zu gruppieren (das Feld [Anzahl] enthält immer 1).
- Die Umwandlung der Zeile in die Liste der eindeutigen Zeichen
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Das Ergebnis lautet wie folgt:
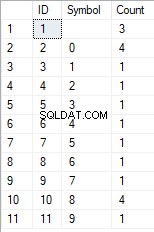
Dieses Beispiel zeigt, dass die Zeile in eine Liste von Zeichen umgewandelt wird, die nach ihrer Eindeutigkeit gruppiert sind. Das Feld [Anzahl] zeigt die Anzahl der Funde jedes Zeichens in der Eingabezeile an.
Basierend auf der Multi-Operator-Funktion [test].[GetListCharacters] erstellen wir eine Skalarfunktion [test].[GetRandString2].
Die Definition der neuen Skalarfunktion zeigt ihre Ähnlichkeit mit der Skalarfunktion [test].[GetRandString]. Der einzige Unterschied besteht darin, dass die Multi-Operator-Funktion [test].[GetListCharacters] anstelle der Tabulatorfunktion [test].[GetSelectCharacters] verwendet wird.
Sehen wir uns hier zwei Beispiele für die Verwendung der implementierten Skalarfunktion an :
Wir erzeugen eine pseudozufällige Zeile von 12 Zeichen Länge aus der Eingabezeile von Zeichen, die nicht nach Eindeutigkeit gruppiert sind:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Das Ergebnis ist:
64017!!5!!!7
Das Schlüsselwort ist DEFAULT. Es besagt, dass der Standardwert den Parameter festlegt. Hier ist es Null (0).
Oder
Wir erzeugen eine pseudozufällige Zeile in 12 Zeichen Länge aus der Eingabezeile von Zeichen, gruppiert nach Eindeutigkeit:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Das Ergebnis ist:
35792!428273
Implementierung des allgemeinen Skripts für die Datenbereinigung und die geheimen Datenänderungen
Wir haben einfache Beispiele für jede Art von geänderten Daten untersucht:
- Datum und Uhrzeit ändern;
- Zahlenwert ändern;
- Ändern der Byte-Reihenfolge;
- Ändern der Daten der Charaktere.
Diese Beispiele erfüllen jedoch nicht die Kriterien 2 und 3 für die Datenänderungsskripte:
- Kriterium 2 :Die Selektivität der Werte ändert sich in den geänderten Daten nicht wesentlich. Sie können NULL nicht für das Feld der Tabelle verwenden. Stattdessen müssen Sie sicherstellen, dass die gleichen realen Datenwerte in den geänderten Daten gleich bleiben. Wenn beispielsweise die echten Daten den Wert 103785 12 Mal in einem Feld einer Tabelle enthalten, das Änderungen unterliegt, müssen die geänderten Daten einen anderen (geänderten) Wert enthalten, der 12 Mal im selben Feld der Tabelle gefunden wurde.
- Kriterium 3 :Die Länge und Größe von Werten sollte in den geänderten Daten nicht wesentlich geändert werden. Sie ersetzen beispielsweise jedes Zeichen/Byte durch ein pseudozufälliges Zeichen/Byte.
Daher müssen wir ein Skript erstellen, das die Selektivität der Werte in den Feldern der Tabelle berücksichtigt.
Werfen wir einen Blick in unsere Datenbank für den Recruiting-Service. Wie wir sehen, sind personenbezogene Daten nur in der Kandidatentabelle [dbo].[Employee].
vorhandenAngenommen, die Tabelle enthält die folgenden Felder:
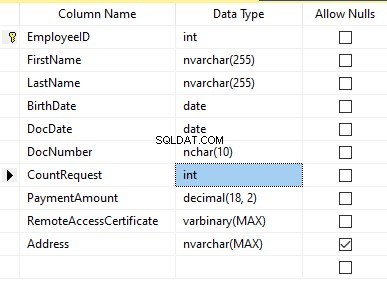
Beschreibungen:
- Vorname – Name, Zeile NVARCHAR(255)
- Nachname – Nachname, Zeile NVARCHAR(255)
- Geburtsdatum – Geburtsdatum, DATE
- DocNumber – die Ausweisnummer mit zwei Ziffern am Anfang für die Passserie, und die nächsten sieben Ziffern sind die Nummer des Dokuments. Dazwischen haben wir einen Bindestrich als NCHAR(10)-Zeile.
- DocDate – das Ausstellungsdatum des Personalausweises, DATE
- CountRequest – die Anzahl der Anfragen für diesen Kandidaten während der Suche nach dem Lebenslauf, die ganze Zahl INT
- Zahlungsbetrag – die erhaltene Servicegebühr für die Bewerbung des Lebenslaufs, die Dezimalzahl (18,2)
- RemoteAccessCertificate – das Fernzugriffszertifikat, Bytefolge VARBINARY
- Adresse – die Wohnadresse oder Meldeadresse, Zeile NVARCHAR(MAX)
Um die anfängliche Selektivität beizubehalten, müssen wir dann den folgenden Algorithmus implementieren:
- Extrahieren Sie alle eindeutigen Werte für jedes Feld und speichern Sie die Ergebnisse in temporären Tabellen oder Tabellenvariablen;
- Generieren Sie einen Pseudozufallswert für jeden eindeutigen Wert. Dieser Pseudozufallswert darf sich in Länge und Größe nicht wesentlich vom Originalwert unterscheiden. Speichern Sie das Ergebnis an derselben Stelle, an der wir die Ergebnisse von Punkt 1 gespeichert haben. Jedem neu generierten Wert muss ein eindeutiger aktueller Wert zugeordnet werden.
- Ersetzen Sie alle Werte in der Tabelle durch neue Werte aus Punkt 2.
Zu Beginn anonymisieren wir die Vor- und Nachnamen der Kandidaten. Wir gehen davon aus, dass Nachname und Vorname immer vorhanden sind und in jedem Feld nicht weniger als zwei Zeichen lang sind.
Zuerst wählen wir eindeutige Namen aus. Dann wird für jeden Namen eine pseudozufällige Zeile generiert. Die Länge des Namens bleibt gleich; das erste Zeichen ist in Großbuchstaben und die anderen Zeichen in Kleinbuchstaben. Wir verwenden die zuvor erstellte Skalarfunktion [test].[GetRandString], um eine Pseudozufallslinie der spezifischen Länge gemäß den definierten Kriterien der Zeichen zu generieren.
Dann aktualisieren wir die Namen in der Kandidatentabelle gemäß ihren eindeutigen Werten. Dasselbe gilt für die Nachnamen.
Wir entpersonalisieren das Feld DocNumber. Es ist die Nummer des Personalausweises (Reisepasses). Die ersten beiden Zeichen stehen für die Dokumentenserie und die letzten sieben Ziffern für die Nummer des Dokuments. Der Bindestrich steht dazwischen. Dann führen wir die Bereinigungsoperation durch.
Wir sammeln alle eindeutigen Dokumentennummern und generieren für jede eine Pseudozufallslinie. Das Format der Zeile ist 'XX-XXXXXXX', wobei X die Ziffer im Bereich von 0 bis 9 ist. Hier verwenden wir die zuvor erstellte Skalarfunktion [test].[GetRandString], um eine pseudozufällige Zeile der angegebenen Länge gemäß zu erzeugen Parametersatz der Zeichen.
Danach wird das Feld [DocNumber] in der Kandidatentabelle [dbo].[Employee].
aktualisiertWir entpersonalisieren das DocDate-Feld (das Ausstellungsdatum des Personalausweises) und das BirthDate-Feld (das Geburtsdatum des Kandidaten).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
Das Ergebnis ist:
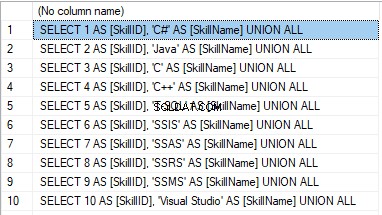
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
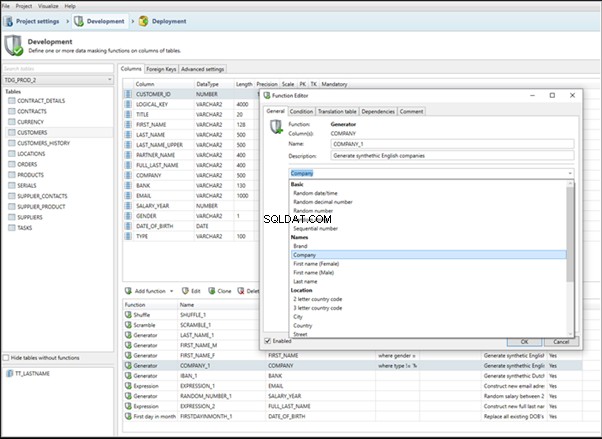
IRI RowGen
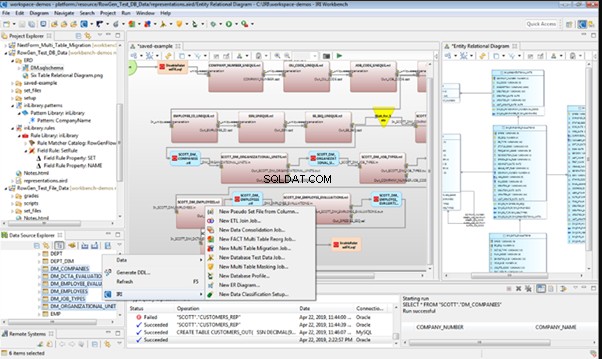
Data Generator for SQL Server
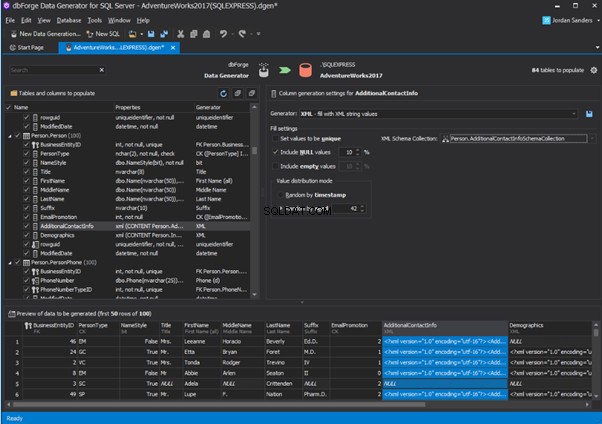
Redgate SQL Data Generator
DTM Data Generator
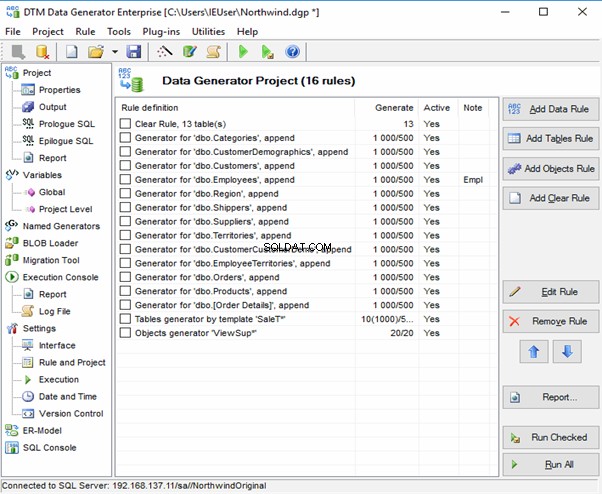
Datanamic Data Generator MultiDB
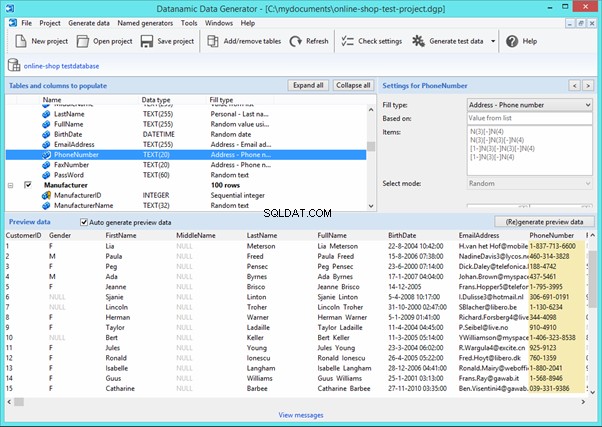
Now, let’s examine one of these tools more precisely.
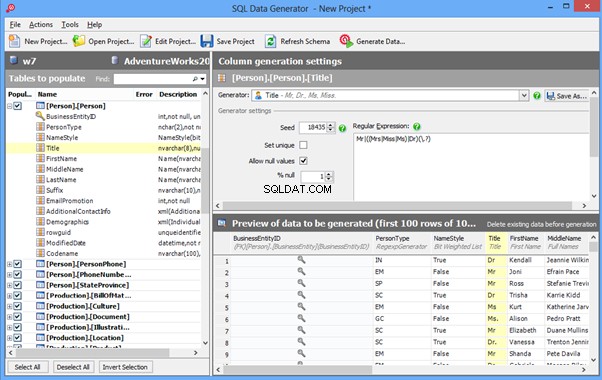
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
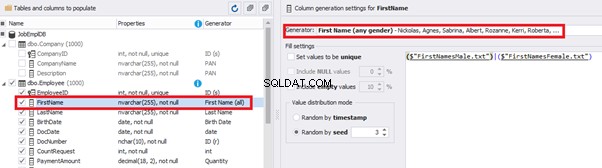
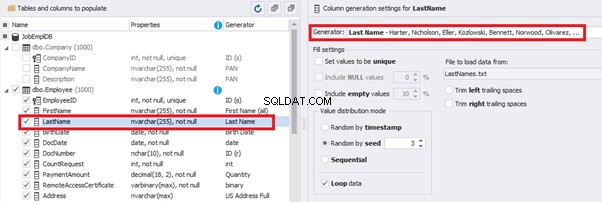
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
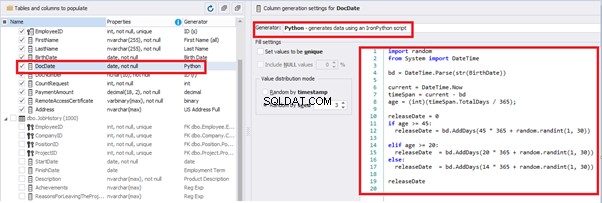
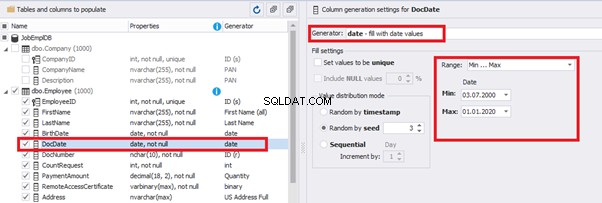
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
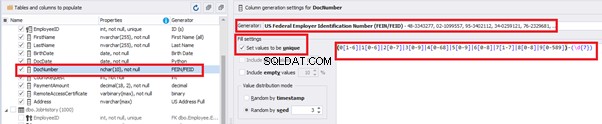
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
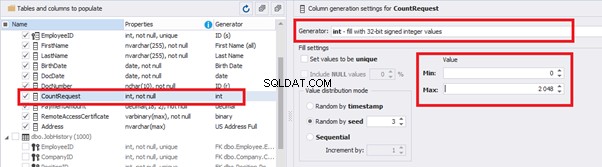
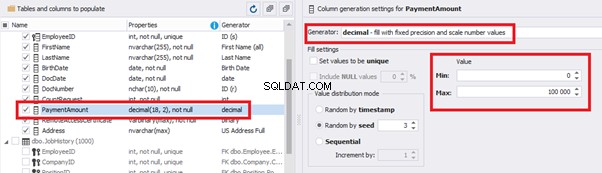
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
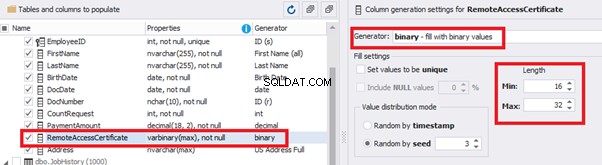
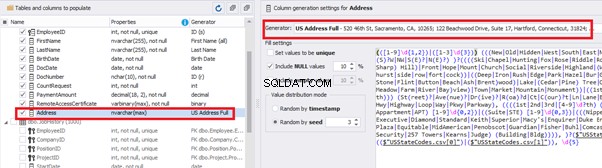
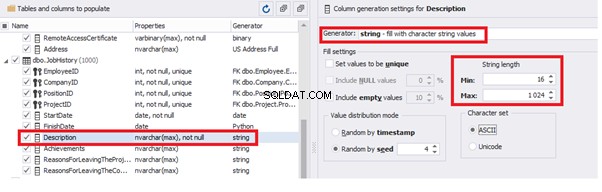
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
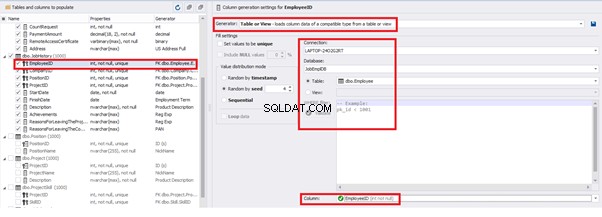
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
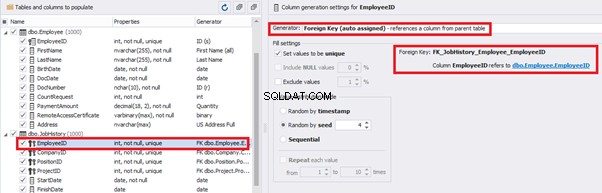
Similarly, we set up the data generation for the following fields.
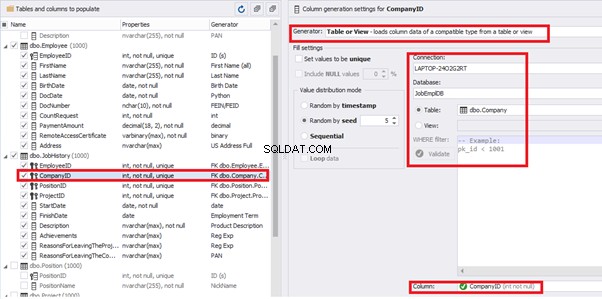
[CompanyID] – from [dbo].[Company], the “companies” table:
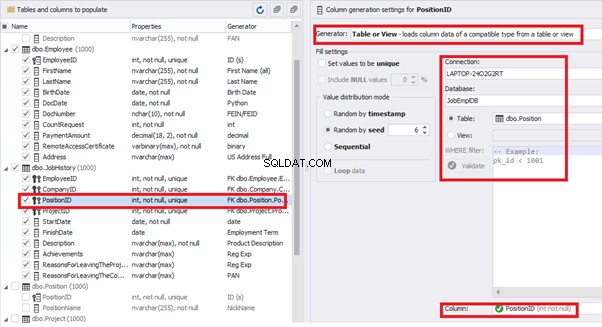
[PositionID] – from the table of positions [dbo].[Position]:
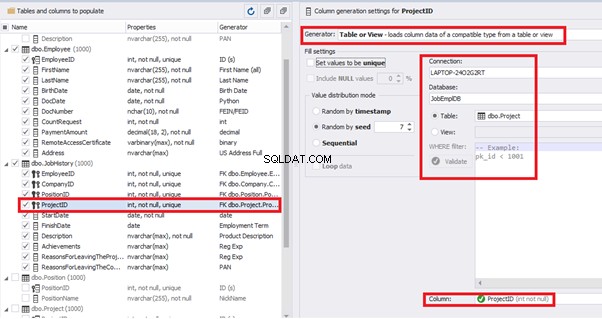
[ProjectID] – from the table of projects [dbo].[Project]:
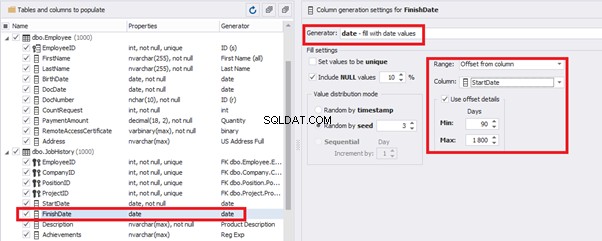
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
That’s why we resolve the dates’ problem (BirthDate
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
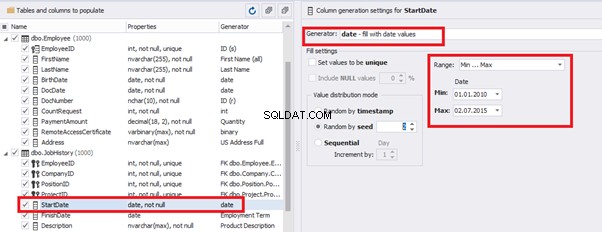
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
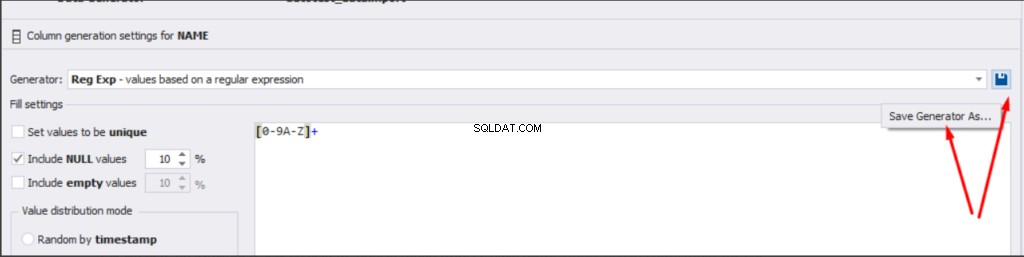
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 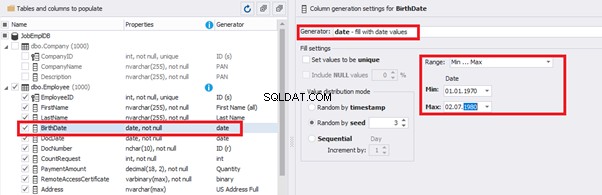
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate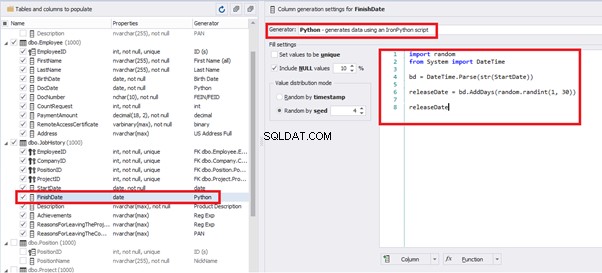
Schlussfolgerung
References
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation