Inner Join, Outer Join, Cross Join? Was gibt?
Es ist eine berechtigte Frage. Ich habe einmal einen Visual Basic-Code mit darin eingebetteten T-SQL-Codes gesehen. Der VB-Code ruft Tabellendatensätze mit mehreren SELECT-Anweisungen ab, ein SELECT * pro Tabelle. Anschließend werden mehrere Resultsets zu einem Datensatz kombiniert. Absurd?
Für die jungen Entwickler, die es gemacht haben, war es das nicht. Aber als sie mich baten, zu bewerten, warum das System langsam war, war dieses Problem das erste, das meine Aufmerksamkeit erregte. Stimmt. Sie haben noch nie von SQL-Joins gehört. Um fair zu sein, sie waren ehrlich und offen für Vorschläge.
Wie beschreiben Sie SQL-Joins? Vielleicht erinnerst du dich an ein Lied – Imagine von John Lennon:
Sie mögen sagen, ich bin ein Träumer, aber ich bin nicht der einzige.
Ich hoffe, dass Sie sich uns eines Tages anschließen und die Welt eins sein wird.
Im Kontext des Liedes ist Verbinden gleichbedeutend mit Vereinen. In einer SQL-Datenbank bildet das Kombinieren von Datensätzen von 2 oder mehr Tabellen zu einer Ergebnismenge einen Join .
Dieser Artikel ist der Beginn einer dreiteiligen Serie über SQL-Joins:
- INNER JOIN
- OUTER JOIN, einschließlich LEFT, RIGHT und FULL
- CROSS JOIN
Aber bevor wir anfangen, INNER JOIN zu diskutieren, wollen wir Joins im Allgemeinen beschreiben.

Mehr über SQL JOIN
Joins erscheinen direkt nach der FROM-Klausel. In seiner einfachsten Form sieht es so aus, als würde es den SQL-92-Standard verwenden:
FROM <table source> [<alias1>]
<join type> JOIN <table source> [<alias2>] [ON <join condition>]
[<join type> JOIN <table source> [<alias3>] [ON <join condition>]
<join type> JOIN <table source> [<aliasN>] [ON <join condition>]]
[WHERE <condition>]Lassen Sie uns die alltäglichen Dinge rund um den JOIN beschreiben.
Tabellenquellen
Laut Microsoft können Sie bis zu 256 Tabellenquellen hinzufügen. Dies hängt natürlich von Ihren Serverressourcen ab. Ich bin in meinem Leben nie mehr als 10 Tischen beigetreten, ganz zu schweigen von 256. Wie auch immer, Tabellenquellen können eine der folgenden sein:
- Tabelle
- Anzeigen
- Tabellen- oder Ansichtssynonym
- Tabellenvariable
- Tabellenwertfunktion
- Abgeleitete Tabelle
Tabellen-Alias
Ein Alias ist optional, aber er verkürzt Ihren Code und minimiert den Tippaufwand. Es hilft Ihnen auch, Fehler zu vermeiden, wenn ein Spaltenname in zwei oder mehr Tabellen vorhanden ist, die in einem SELECT, UPDATE, INSERT oder DELETE verwendet werden. Es fügt Ihrem Code auch Klarheit hinzu. Es ist optional, aber ich würde die Verwendung von Aliasen empfehlen. (Außer Sie lieben es, Tabellenquellen nach Namen einzugeben.)
Beitrittsbedingung
Das ON-Schlüsselwort geht der Join-Bedingung voraus, die ein einzelner Join oder 2-Schlüssel-Spalten aus den 2 verknüpften Tabellen sein kann. Oder es kann sich um einen zusammengesetzten Join handeln, der mehr als zwei Schlüsselspalten verwendet. Es definiert, wie Tabellen miteinander in Beziehung stehen.
Wir verwenden die Join-Bedingung jedoch nur für INNER- und OUTER-Joins. Die Verwendung bei einem CROSS JOIN löst einen Fehler aus.
Da Join-Bedingungen die Beziehungen definieren, benötigen sie Operatoren.
Der häufigste Join-Bedingungsoperator ist der Gleichheitsoperator (=). Andere Operatoren wie> oder
Die meisten Joins können als Unterabfragen umgeschrieben werden und umgekehrt. Lesen Sie diesen Artikel, um mehr über Unterabfragen im Vergleich zu Verknüpfungen zu erfahren.
Die Verwendung abgeleiteter Tabellen in einem Join sieht folgendermaßen aus:
Es wird aus dem Ergebnis einer anderen SELECT-Anweisung zusammengefügt und ist vollkommen gültig.
Sie werden noch mehr Beispiele haben, aber lassen Sie uns eine letzte Sache über SQL JOINS behandeln. So verarbeitet der Abfrageoptimierer von SQL Server Joins.
Um zu verstehen, wie der Prozess funktioniert, müssen Sie die beiden beteiligten Arten von Vorgängen kennen:
Ein Wort:Leistung.
Eine Sache ist zu wissen, wie man Abfragen mit Verknüpfungen bildet, um korrekte Ergebnisse zu erzielen. Eine andere ist, es so schnell wie möglich laufen zu lassen. Sie müssen sich darum besonders kümmern, wenn Sie bei Ihren Benutzern einen guten Ruf haben möchten.
Worauf müssen Sie also im Ausführungsplan für diese logischen Operationen achten?
Join-Hinweise sind neu in SQL Server 2019. Wenn Sie sie in Ihren Joins verwenden, weist sie den Abfrageoptimierer an, nicht mehr zu entscheiden, was für die Abfrage am besten ist. Sie sind der Chef, wenn es um die physische Verknüpfung geht.
Jetzt hör auf, genau dort. Die Wahrheit ist, dass der Abfrageoptimierer normalerweise den besten physischen Join für Ihre Abfrage auswählt. Wenn Sie nicht wissen, was Sie tun, verwenden Sie keine Join-Hinweise.
Die möglichen Hinweise, die Sie angeben können, sind LOOP, MERGE, HASH oder REMOTE.
Ich habe keine Join-Hinweise verwendet, aber hier ist die Syntax:
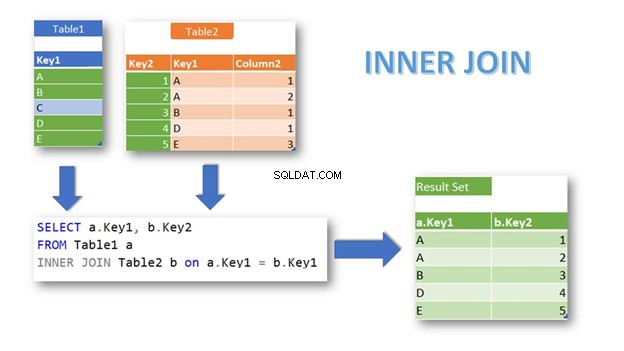
INNER JOIN gibt basierend auf einer Bedingung die Zeilen mit übereinstimmenden Datensätzen in beiden Tabellen zurück. Es ist auch der Standard-Join, wenn Sie das Schlüsselwort INNER:
Wie Sie sehen, übereinstimmende Zeilen aus Table1 und Tabelle2 werden mit Key1 zurückgegeben als Join-Bedingung. Die Tabelle1 Datensatz mit Key1 =„C“ wird ausgeschlossen, da es keine übereinstimmenden Datensätze in Tabelle2 gibt .
Immer wenn ich eine Abfrage bilde, ist meine erste Wahl INNER JOIN. OUTER JOIN kommt nur, wenn es die Anforderungen erfordern.
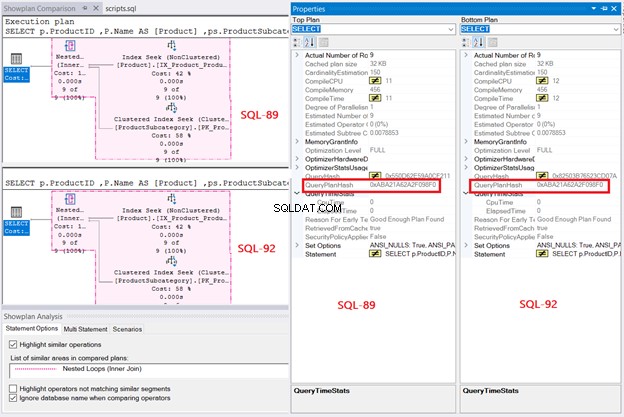
In T-SQL werden zwei INNER JOIN-Syntaxen unterstützt:SQL-92 und SQL-89.
Die erste Join-Syntax, die ich gelernt habe, war SQL-89. Als SQL-92 endlich ankam, fand ich es zu langatmig. Ich dachte auch, da die Ausgabe dieselbe war, warum sollte man sich die Mühe machen, mehr Schlüsselwörter einzugeben? Ein grafischer Abfrage-Designer hatte den generierten Code SQL-92, und ich habe ihn wieder in SQL-89 geändert. Aber heute bevorzuge ich SQL-92, auch wenn ich mehr tippen muss. Hier ist der Grund:
Die oben genannten Gründe sind meine. Sie haben vielleicht Ihre Gründe, warum Sie SQL-92 bevorzugen oder warum Sie es hassen. Ich frage mich, was das für Gründe sind. Lassen Sie es mich im Kommentarbereich unten wissen.
Aber wir können diesen Artikel nicht ohne Beispiele und Erklärungen beenden.
Hier ist ein Beispiel für 2 Tabellen, die mit INNER JOIN in SQL-92-Syntax miteinander verbunden wurden.
Sie geben nur die Spalten an, die Sie benötigen. Im obigen Beispiel sind 4 Spalten angegeben. Ich weiß, dass es zu langwierig ist als SELECT *, aber denken Sie daran:Es ist die beste Vorgehensweise.
Beachten Sie auch die Verwendung von Tabellenaliasen. Sowohl das Produkt und ProductSubcategory Tabellen haben eine Spalte namens [Name ]. Wenn Sie den Alias nicht angeben, wird ein Fehler ausgelöst.
Hier ist die entsprechende SQL-89-Syntax:
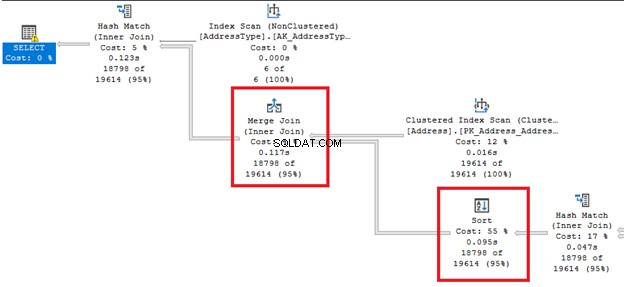
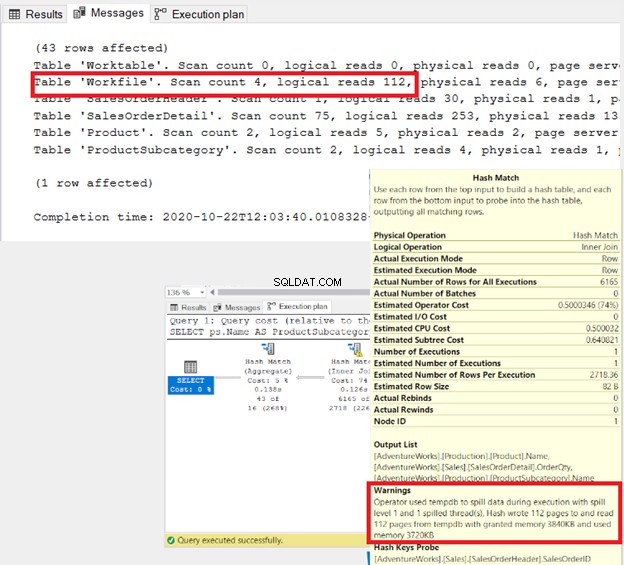
Sie sind bis auf die in der WHERE-Klausel mit einem AND-Schlüsselwort gemischte Join-Bedingung identisch. Aber sind sie unter der Haube wirklich gleich? Sehen wir uns die Ergebnismenge, den STATISTICS IO und den Execution Plan an.
Sehen Sie sich die Ergebnismenge von 9 Datensätzen an:
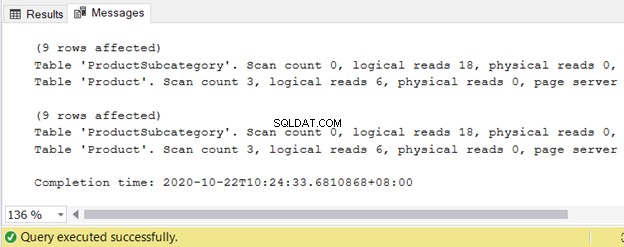
Es sind nicht nur die Ergebnisse, sondern auch die von SQL Server benötigten Ressourcen.
Siehe die logischen Lesevorgänge:
Schließlich offenbart der Ausführungsplan denselben Abfrageplan für beide Abfragen, wenn ihre QueryPlanHashes sind gleich. Beachten Sie auch die hervorgehobenen Operationen im Diagramm:
Basierend auf den Ergebnissen ist die SQL Server-Abfrageverarbeitung gleich, egal ob es sich um SQL-92 oder SQL-89 handelt. Aber wie gesagt, die Übersichtlichkeit in SQL-92 ist für mich viel besser.
Abbildung 7 zeigt auch einen im Plan verwendeten Nested Loop Join. Wieso den? Die Ergebnismenge ist klein.
Sehen Sie sich die folgende Abfrage mit 3 verknüpften Tabellen an.
Sie können auch 2 Tische verbinden, indem Sie 2 Schlüssel verwenden, um sie in Beziehung zu setzen. Sehen Sie sich das Beispiel unten an. Es verwendet 2 Join-Bedingungen mit einem UND-Operator.
Im Beispiel unten das Produkt Tabelle hat 9 Datensätze – eine kleine Menge. Die verbundene Tabelle ist SalesOrderDetail – ein großes Set. Der Abfrageoptimierer verwendet einen Nested-Loop-Join, wie in Abbildung 8 gezeigt.
Das folgende Beispiel verwendet einen Merge-Join, da beide Eingabetabellen nach SalesOrderID sortiert sind.
Das folgende Beispiel verwendet einen Hash-Join:
Im Beispiel unten der SalesPerson Tabelle hat einen Non-clustered ColumnStore Index auf der TerritoryID Säule. Der Abfrageoptimierer entschied sich für einen Nested-Loop-Join, wie in Abbildung 11 gezeigt.
Betrachten Sie diese Anweisung mit einer verschachtelten Unterabfrage:
Die gleichen Ergebnisse können herauskommen, wenn Sie ihn wie folgt in einen INNER JOIN ändern:
Eine andere Möglichkeit zum Umschreiben besteht darin, eine abgeleitete Tabelle als Tabellenquelle für den INNER JOIN zu verwenden:
Alle 3 Abfragen geben dieselben 48 Datensätze aus.
Die folgende Abfrage verwendet eine verschachtelte Schleife:
Wenn Sie einen Hash-Join erzwingen möchten, geschieht Folgendes:
Beachten Sie jedoch, dass STATISTICS IO zeigt, dass die Leistung schlecht wird, wenn Sie einen Hash-Join erzwingen.
In der Zwischenzeit verwendet die folgende Abfrage einen Merge Join:
So wird es, wenn Sie es zu einer verschachtelten Schleife zwingen:
Nach dem Überprüfen des STATISTICS IO von beiden erfordert das Erzwingen einer verschachtelten Schleife mehr Ressourcen zum Verarbeiten der Abfrage:
Daher sollte die Verwendung von Join-Hinweisen Ihr letzter Ausweg sein, wenn Sie die Leistung optimieren. Überlassen Sie dies Ihrem SQL Server.
Sie können INNER JOIN auch in einer UPDATE-Anweisung verwenden. Hier ist ein Beispiel:
Da es möglich ist, einen Join in einem UPDATE zu verwenden, warum probieren Sie es nicht mit DELETE und INSERT aus?
Also, was ist das Besondere am SQL-Join?
In der Zwischenzeit zeigte dieser Beitrag 10 Beispiele für INNER JOINs. Es sind nicht nur Beispielcodes. Einige von ihnen beinhalten auch eine Inspektion, wie der Code von innen nach außen funktioniert. Es soll Ihnen nicht nur beim Programmieren helfen, sondern auch dabei helfen, auf die Leistung zu achten. Am Ende sollen die Ergebnisse nicht nur stimmen, sondern auch schnell geliefert werden.
Wir sind noch nicht fertig. Der nächste Artikel befasst sich mit OUTER JOINS. Bleiben Sie dran.
Mit SQL-Joins können Sie Daten aus mehr als einer Tabelle abrufen und kombinieren. Sehen Sie sich dieses Video an, um mehr über SQL-Joins zu erfahren.SQL JOIN vs. Unterabfragen
Joins und abgeleitete Tabellen
FROM table1 a
INNER JOIN (SELECT y.column3 from table2 x
INNER JOIN table3 y on x.column1 = y.column1) b ON a.col1 = b.col2Wie SQL Server Joins verarbeitet

Warum müssen wir uns damit beschäftigen?
Beitrittshinweise
<join type> <join hint> JOIN <table source> [<alias>] ON <join condition>Alles über INNER JOIN
INNER JOIN-Syntax
SQL-92 INNER JOIN
FROM <table source1> [<alias1>]
INNER JOIN <table source2> [<alias2>] ON <join condition1>
[INNER JOIN <table source3> [<alias3>] ON <join condition2>
INNER JOIN <table sourceN> [<aliasN>] ON <join conditionN>]
[WHERE <condition>]SQL-89 INNER JOIN
FROM <table source1> [alias1], <table source2> [alias2] [, <table source3> [alias3], <table sourceN> [aliasN]]
WHERE (<join condition1>)
[AND (<join condition2>)
AND (<join condition3>)
AND (<join conditionN>)]Welche INNER JOIN-Syntax ist besser?
10 INNER JOIN-Beispiele
1. Verbinden von 2 Tischen
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE P.ProductSubcategoryID IN (25, 31, 33); -- for vest, helmet, and light
-- product subcategories-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p, Production.ProductSubcategory ps
WHERE P.ProductSubcategoryID = ps.ProductSubcategoryID
AND P.ProductSubcategoryID IN (25, 31, 33);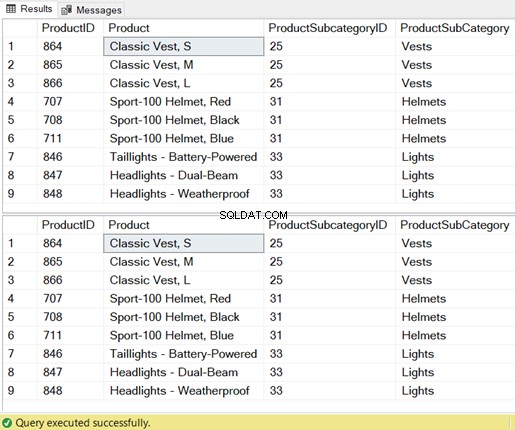
2. Beitritt zu mehreren Tischen
-- Get the total number of orders per Product Category
USE AdventureWorks
GO
SELECT
ps.Name AS ProductSubcategory
,SUM(sod.OrderQty) AS TotalOrders
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod ON P.ProductID = sod.ProductID
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '1/1/2014' AND '12/31/2014'
AND p.ProductSubcategoryID IN (1,2)
GROUP BY ps.Name
HAVING ps.Name IN ('Mountain Bikes', 'Road Bikes')3. Zusammengesetzter Join
SELECT
a.column1
,b.column1
,b.column2
FROM Table1 a
INNER JOIN Table2 b ON a.column1 = b.column1 AND a.column2 = b.column24. INNER JOIN Verwenden eines physikalischen Joins mit verschachtelten Schleifen
USE AdventureWorks
GO
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);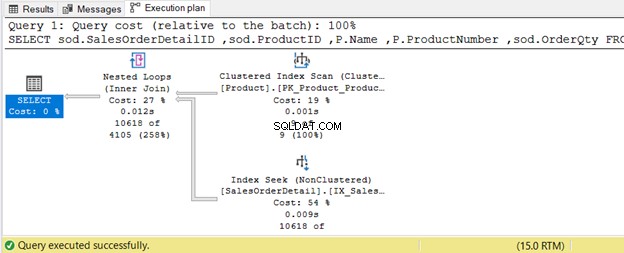
5. INNER JOIN Verwenden eines Merge Physical Joins
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID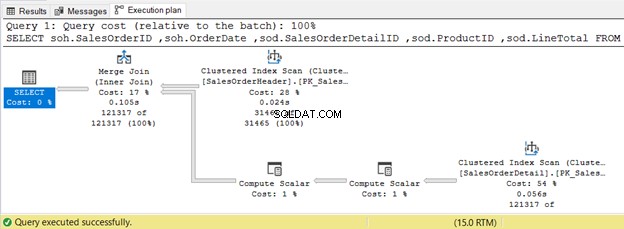
6. INNER JOIN mit einem physischen Hash-Join
SELECT
s.Name AS Store
,SUM(soh.TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.Store s ON soh.SalesPersonID = s.SalesPersonID
GROUP BY s.Name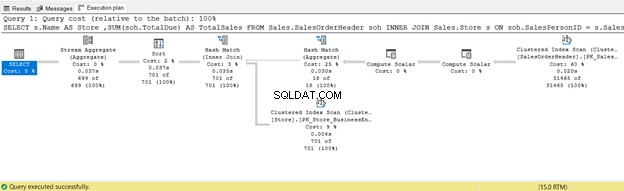
7. INNER JOIN Adaptive Physical Join verwenden
SELECT
sp.BusinessEntityID
,sp.SalesQuota
,st.Name AS Territory
FROM Sales.SalesPerson sp
INNER JOIN Sales.SalesTerritory st ON sp.TerritoryID = st.TerritoryID
WHERE sp.TerritoryID BETWEEN 1 AND 5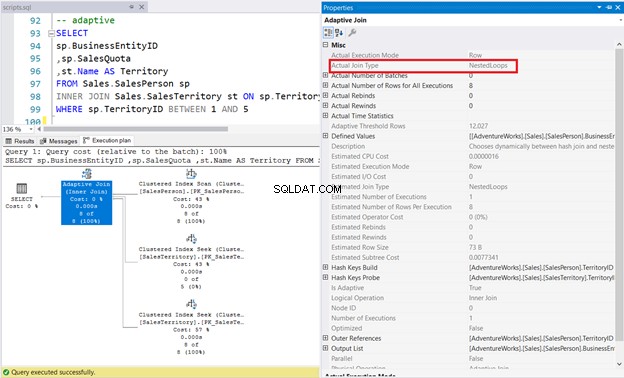
8. Zwei Möglichkeiten, eine Unterabfrage in einen INNER JOIN umzuschreiben
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT [CustomerID] FROM Sales.Customer
WHERE PersonID IN (SELECT BusinessEntityID FROM Person.Person
WHERE lastname LIKE N'I%' AND PersonType='SC'))SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.lastname LIKE N'I%'SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN (SELECT c.CustomerID, P.PersonType, P.LastName
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = P.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.LastName LIKE N'I%') AS q ON o.CustomerID = q.CustomerID9. Join-Hinweise verwenden
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER HASH JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDSELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID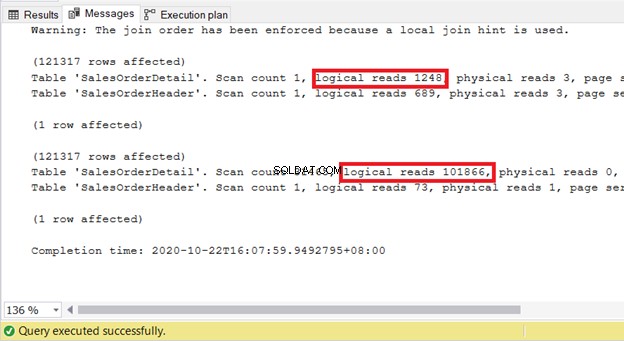
10. Verwendung von INNER JOIN in UPDATE
UPDATE Sales.SalesOrderHeader
SET ShipDate = getdate()
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'SQL Join und INNER JOIN Takeaways
Siehe auch