HAProxy und ProxySQL sind beide sehr beliebte Load Balancer in der MySQL-Welt, aber es gibt einen signifikanten Unterschied zwischen diesen beiden Proxys. Wir gehen hier nicht auf Details ein, Sie können mehr über HAProxy im HAProxy-Tutorial und ProxySQL im ProxySQL-Tutorial lesen. Der wichtigste Unterschied besteht darin, dass ProxySQL ein SQL-fähiger Proxy ist, den Datenverkehr parst und das MySQL-Protokoll versteht und daher für erweitertes Traffic-Shaping verwendet werden kann – Sie können Abfragen blockieren, sie umschreiben, sie an bestimmte Hosts leiten und zwischenspeichern sie und viele mehr. HAProxy hingegen ist ein sehr einfacher, aber effizienter Layer-4-Proxy, der lediglich Pakete an das Backend sendet. ProxySQL kann verwendet werden, um eine Lese-Schreib-Aufteilung durchzuführen – es versteht die SQL und kann so konfiguriert werden, dass es erkennt, ob eine Abfrage SELECT ist oder nicht, und sie entsprechend weiterleitet:SELECTs an alle Knoten, andere Abfragen nur an Master. Diese Funktion ist in HAProxy nicht verfügbar, das zwei separate Ports und zwei separate Backends für Master und Slaves verwenden muss – die Lese-Schreib-Aufteilung muss auf der Anwendungsseite durchgeführt werden.
Warum zu ProxySQL migrieren?
Basierend auf den oben erläuterten Unterschieden würden wir sagen, dass der Hauptgrund, warum Sie möglicherweise von HAProxy zu ProxySQL wechseln möchten, das Fehlen der Lese-Schreib-Aufteilung in HAProxy ist. Wenn Sie einen Cluster von MySQL-Datenbanken verwenden, und es spielt keine Rolle, ob es sich um eine asynchrone Replikation oder einen Galera-Cluster handelt, möchten Sie wahrscheinlich in der Lage sein, Lesevorgänge von Schreibvorgängen zu trennen. Für die MySQL-Replikation wäre dies offensichtlich die einzige Möglichkeit, Ihren Datenbankcluster zu nutzen, da Schreibvorgänge immer an den Master gesendet werden müssen. Wenn Sie also keine Lese-Schreib-Aufteilung durchführen können, können Sie Anfragen nur an den Master senden. Für Galera ist Read-Write-Split kein Muss, aber definitiv ein Good-to-have. Sicher, Sie können alle Galera-Knoten als ein Backend in HAProxy konfigurieren und den Datenverkehr an alle im Round-Robin-Verfahren senden, aber dies kann dazu führen, dass Schreibvorgänge von mehreren Knoten miteinander in Konflikt geraten, was zu Blockaden und Leistungseinbußen führt. Wir haben auch Probleme und Fehler im Galera-Cluster gesehen, für die bis zu ihrer Behebung die Problemumgehung darin bestand, alle Schreibvorgänge auf einen einzelnen Knoten zu lenken. Daher ist es am besten, alle Schreibvorgänge an einen Galera-Knoten zu senden, da dies zu einem stabileren Verhalten und einer besseren Leistung führt.
Ein weiterer sehr guter Grund für die Migration zu ProxySQL ist die Notwendigkeit, den Datenverkehr besser kontrollieren zu können. Mit HAProxy können Sie nichts tun - es sendet nur den Datenverkehr an seine Backends. Mit ProxySQL können Sie Ihren Datenverkehr mithilfe von Abfrageregeln gestalten (Abgleich des Datenverkehrs mithilfe von regulären Ausdrücken, Benutzern, Schemas, Quellhosts und vielem mehr). Sie können OLAP-SELECTs an den Analyse-Slave umleiten (das gilt sowohl für die Replikation als auch für Galera). Sie können Ihren Master auslagern, indem Sie einige der SELECTs von ihm umleiten. Sie können eine SQL-Firewall implementieren. Sie können einigen der Abfragen eine Verzögerung hinzufügen, Sie können Abfragen beenden, wenn sie länger als eine vordefinierte Zeit dauern. Sie können Abfragen umschreiben, um Optimierungshinweise hinzuzufügen. All das ist mit HAProxy nicht möglich.
Wie migriere ich von HAProxy zu ProxySQL?
Betrachten wir zunächst die folgende Topologie...
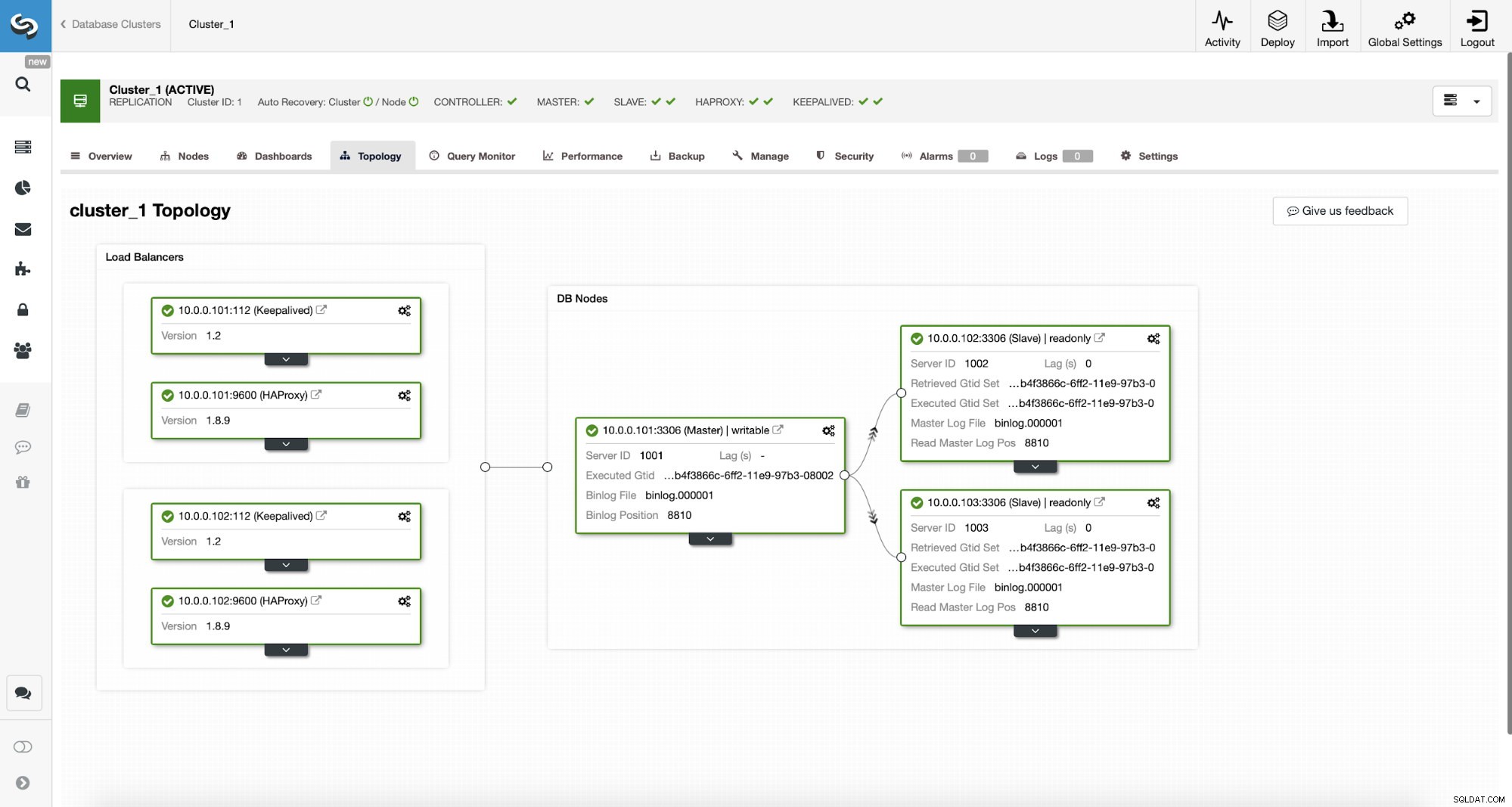 ClusterControl-MySQL-Topologie
ClusterControl-MySQL-Topologie  MySQL-Replikationscluster in ClusterControl
MySQL-Replikationscluster in ClusterControl Wir haben hier einen Replikationscluster, der aus einem Master und zwei Slaves besteht. Wir haben zwei HAProxy-Knoten bereitgestellt, die jeweils zwei Backends verwenden – auf Port 3307 für den Master (Schreibvorgänge) und 3308 für alle Knoten (Lesevorgänge). Keepalived wird verwendet, um eine virtuelle IP über diese beiden HAProxy-Instanzen bereitzustellen – sollte eine von ihnen ausfallen, wird eine andere verwendet. Unsere Anwendung verbindet sich direkt mit dem VIP und darüber mit einer der HAProxy-Instanzen. Nehmen wir an, unsere Anwendung (wir werden Sysbench verwenden) kann die Lese-Schreib-Aufteilung nicht durchführen, daher müssen wir uns mit dem „Writer“-Backend verbinden. Infolgedessen liegt der Großteil der Last auf unserem Master (10.0.0.101).
Was wären die Schritte zur Migration zu ProxySQL? Denken wir einen Moment darüber nach. Zuerst müssen wir ProxySQL bereitstellen und konfigurieren. Wir müssen ProxySQL Server hinzufügen, erforderliche Überwachungsbenutzer erstellen und geeignete Abfrageregeln erstellen. Schließlich müssen wir Keepalived zusätzlich zu ProxySQL bereitstellen, eine weitere virtuelle IP erstellen und dann für unsere Anwendung einen möglichst nahtlosen Wechsel von HAProxy zu ProxySQL sicherstellen.
Schauen wir uns an, wie wir das erreichen können...
So installieren Sie ProxySQL
Man kann ProxySQL auf viele Arten installieren. Sie können das Repository entweder von ProxySQL selbst (https://repo.proxysql.com) verwenden oder wenn Sie Percona XtraDB Cluster verwenden, können Sie auch ProxySQL aus dem Percona-Repository installieren, obwohl es möglicherweise eine zusätzliche Konfiguration erfordert, da es auf CLI basiert Admin-Tools, die für PXC erstellt wurden. Da wir über Replikation sprechen, kann ihre Verwendung die Dinge nur noch komplexer machen. Schließlich können Sie auch ProxySQL-Binärdateien installieren, nachdem Sie sie von ProxySQL GitHub heruntergeladen haben. Derzeit gibt es zwei stabile Versionen, 1.4.x und 2.0.x. Es gibt Unterschiede zwischen ProxySQL 1.4 und ProxySQL 2.0 in Bezug auf die Funktionen, für diesen Blog bleiben wir beim 1.4.x-Zweig, da er besser getestet ist und der Funktionsumfang für uns ausreicht.
Wir werden das ProxySQL-Repository verwenden und ProxySQL auf zwei zusätzlichen Knoten bereitstellen:10.0.0.103 und 10.0.0.104.
Zuerst installieren wir ProxySQL mit dem offiziellen Repository. Wir werden auch sicherstellen, dass der MySQL-Client installiert ist (wir werden ihn verwenden, um ProxySQL zu konfigurieren). Bitte beachten Sie, dass der Prozess, den wir durchlaufen, nicht produktionsreif ist. Für die Produktion sollten Sie zumindest die Standardanmeldeinformationen für den Administrator ändern. Sie sollten auch die Konfiguration überprüfen und sicherstellen, dass sie Ihren Erwartungen und Anforderungen entspricht.
apt-get install -y lsb-release
wget -O - 'https://repo.proxysql.com/ProxySQL/repo_pub_key' | apt-key add -
echo deb https://repo.proxysql.com/ProxySQL/proxysql-1.4.x/$(lsb_release -sc)/ ./ | tee /etc/apt/sources.list.d/proxysql.list
apt-get -y update
apt-get -y install proxysql
service proxysql startNachdem ProxySQL gestartet wurde, verwenden wir die CLI, um ProxySQL zu konfigurieren.
mysql -uadmin -padmin -P6032 -h127.0.0.1Zuerst definieren wir Backend-Server und Replikations-Hostgruppen:
mysql> INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES (10, '10.0.0.101'), (20, '10.0.0.102'), (20, '10.0.0.103');
Query OK, 3 rows affected (0.91 sec)mysql> INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup) VALUES (10, 20);
Query OK, 1 row affected (0.00 sec)Wir haben drei Server, wir haben auch definiert, dass ProxySQL Hostgruppe 10 für Master (Knoten mit read_only=0) und Hostgruppe 20 für Slaves (read_only=1) verwenden soll.
Als nächsten Schritt müssen wir einen überwachenden Benutzer auf den MySQL-Knoten hinzufügen, damit ProxySQL sie überwachen kann. Wir verwenden die Standardeinstellungen, idealerweise ändern Sie die Anmeldeinformationen in ProxySQL.
mysql> SHOW VARIABLES LIKE 'mysql-monitor_username';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_username | monitor |
+------------------------+---------+
1 row in set (0.00 sec)mysql> SHOW VARIABLES LIKE 'mysql-monitor_password';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_password | monitor |
+------------------------+---------+
1 row in set (0.00 sec)Also müssen wir den Benutzer ‚monitor‘ mit dem Passwort ‚monitor‘ erstellen. Dazu müssen wir den folgenden Grant auf dem Master-MySQL-Server ausführen:
mysql> create user example@sqldat.com'%' identified by 'monitor';
Query OK, 0 rows affected (0.56 sec)Zurück zu ProxySQL – wir müssen Benutzer konfigurieren, die unsere Anwendung verwenden wird, um auf MySQL zuzugreifen, und Abfrageregeln, die uns eine Lese-Schreib-Aufteilung geben sollen.
mysql> INSERT INTO mysql_users (username, password, default_hostgroup) VALUES ('sbtest', 'sbtest', 10);
Query OK, 1 row affected (0.34 sec)mysql> INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (100, 1, '^SELECT.*FOR UPDATE$',10,1), (200,1,'^SELECT',20,1), (300,1,'.*',10,1);
Query OK, 3 rows affected (0.01 sec)Bitte beachten Sie, dass wir das Passwort im Klartext verwendet haben und uns auf ProxySQL verlassen, um es zu hashen. Aus Sicherheitsgründen sollten Sie hier explizit den MySQL-Passwort-Hash übergeben.
Schließlich müssen wir alle Änderungen übernehmen.
mysql> LOAD MYSQL SERVERS TO RUNTIME;
Query OK, 0 rows affected (0.02 sec)mysql> LOAD MYSQL USERS TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> SAVE MYSQL SERVERS TO DISK;
Query OK, 0 rows affected (0.07 sec)mysql> SAVE MYSQL QUERY RULES TO DISK;
Query OK, 0 rows affected (0.02 sec)Wir wollen auch die gehashten Passwörter aus der Laufzeit laden:Klartext-Passwörter werden gehasht, wenn sie in die Laufzeitkonfiguration geladen werden, um sie auf der Festplatte gehasht zu halten, müssen wir sie aus der Laufzeit laden und dann auf der Festplatte speichern:
mysql> SAVE MYSQL USERS FROM RUNTIME;
Query OK, 0 rows affected (0.00 sec)mysql> SAVE MYSQL USERS TO DISK;
Query OK, 0 rows affected (0.02 sec)Dies ist es, wenn es um ProxySQL geht. Bevor Sie weitere Schritte unternehmen, sollten Sie prüfen, ob Sie von Ihren Anwendungsservern eine Verbindung zu Proxys herstellen können.
example@sqldat.com:~# mysql -h 10.0.0.103 -usbtest -psbtest -P6033 -e "SELECT * FROM sbtest.sbtest4 LIMIT 1\G"
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
id: 1
k: 50147
c: 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441
pad: 22195207048-70116052123-74140395089-76317954521-98694025897In unserem Fall sieht alles gut aus. Jetzt ist es an der Zeit, Keepalived zu installieren.
Keepalived-Installation
Die Installation ist recht einfach (zumindest auf Ubuntu 16.04, das wir verwendet haben):
apt install keepalivedDann müssen Sie Konfigurationsdateien für beide Server erstellen:
Master-Keepalive-Knoten:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 101
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}Keepalive-Knoten sichern:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.shDas ist es, Sie können Keepalive auf beiden Knoten starten:
service keepalived startSie sollten Informationen in den Protokollen sehen, dass einer der Knoten in den MASTER-Status übergegangen ist und dass VIP auf diesem Knoten aktiviert wurde.
May 7 09:52:11 vagrant systemd[1]: Starting Keepalive Daemon (LVS and VRRP)...
May 7 09:52:11 vagrant Keepalived[26686]: Starting Keepalived v1.2.24 (08/06,2018)
May 7 09:52:11 vagrant Keepalived[26686]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived[26696]: Starting Healthcheck child process, pid=26697
May 7 09:52:11 vagrant Keepalived[26696]: Starting VRRP child process, pid=26698
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Initializing ipvs
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering gratuitous ARP shared channel
May 7 09:52:11 vagrant systemd[1]: Started Keepalive Daemon (LVS and VRRP).
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to load ipset library
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to initialise ipsets
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: pid 26701 exited with status 256
May 7 09:52:12 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Transition to MASTER STATE
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: pid 26763 exited with status 256
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Entering MASTER STATE
May 7 09:52:15 vagrant Keepalived_vrrp[26698]: pid 26806 exited with status 256example@sqldat.com:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:ee:87:c4 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feee:87c4/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:fc:ac:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.103/24 brd 10.0.0.255 scope global eth1
valid_lft forever preferred_lft forever
inet 10.0.0.112/32 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fefc:ac21/64 scope link
valid_lft forever preferred_lft foreverWie Sie sehen können, wurde auf Knoten 10.0.0.103 ein VIP (10.0.0.112) ausgelöst. Wir können jetzt damit abschließen, den Datenverkehr vom alten Setup in das neue zu verschieben.
Traffic auf ein ProxySQL-Setup umstellen
Es gibt viele Methoden, dies zu tun, es hängt hauptsächlich von Ihrer jeweiligen Umgebung ab. Wenn Sie DNS verwenden, um eine Domain zu verwalten, die auf Ihren HAProxy-VIP verweist, können Sie dort einfach eine Änderung vornehmen, und nach und nach werden alle Verbindungen auf den neuen VIP umverweisen. Sie können auch eine Änderung in Ihrer Anwendung vornehmen, insbesondere wenn die Verbindungsdetails fest codiert sind – sobald Sie die Änderung einführen, beginnen die Knoten, sich mit dem neuen Setup zu verbinden. Unabhängig davon, wie Sie es tun, wäre es großartig, das neue Setup zu testen, bevor Sie einen globalen Wechsel vornehmen. Sie haben es sicherlich in Ihrer Staging-Umgebung getestet, aber es ist keine schlechte Idee, eine Handvoll App-Server auszuwählen und sie auf den neuen Proxy umzuleiten und zu überwachen, wie sie in Bezug auf die Leistung aussehen. Unten ist ein einfaches Beispiel, das iptables verwendet, was zum Testen nützlich sein kann.
Leiten Sie auf den ProxySQL-Hosts den Datenverkehr von Host 10.0.0.11 und Port 3307 zu Host 10.0.0.112 und Port 6033 um:
iptables -t nat -A OUTPUT -p tcp -d 10.0.0.111 --dport 3307 -j DNAT --to-destination 10.0.0.112:6033Abhängig von Ihrer Anwendung müssen Sie möglicherweise den Webserver oder andere Dienste neu starten (wenn Ihre App einen konstanten Pool von Verbindungen zur Datenbank erstellt) oder einfach warten, bis neue Verbindungen zu ProxySQL geöffnet werden. Sie können überprüfen, ob ProxySQL den Datenverkehr empfängt:
mysql> show processlist;
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| SessionID | user | db | hostgroup | command | time_ms | info |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| 12 | sbtest | sbtest | 20 | Sleep | 0 | |
| 13 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest23 WHERE id=49957 |
| 14 | sbtest | sbtest | 10 | Query | 59 | DELETE FROM sbtest11 WHERE id=50185 |
| 15 | sbtest | sbtest | 20 | Query | 59 | SELECT c FROM sbtest8 WHERE id=46054 |
| 16 | sbtest | sbtest | 20 | Query | 0 | SELECT DISTINCT c FROM sbtest27 WHERE id BETWEEN 50115 AND 50214 ORDER BY c |
| 17 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest32 WHERE id=50084 |
| 18 | sbtest | sbtest | 10 | Query | 26 | DELETE FROM sbtest28 WHERE id=34611 |
| 19 | sbtest | sbtest | 10 | Query | 16 | DELETE FROM sbtest4 WHERE id=50151 |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+Das war es, wir haben den Datenverkehr von HAProxy in das ProxySQL-Setup verschoben. Es waren einige Schritte erforderlich, aber es ist definitiv mit einer sehr kleinen Unterbrechung des Dienstes machbar.
Wie migriere ich mit ClusterControl von HAProxy zu ProxySQL?
Im vorherigen Abschnitt haben wir erläutert, wie Sie das ProxySQL-Setup manuell bereitstellen und dann dorthin migrieren. In diesem Abschnitt möchten wir erklären, wie Sie dasselbe Ziel mit ClusterControl erreichen. Die anfängliche Einrichtung ist genau die gleiche, daher müssen wir mit der Bereitstellung von ProxySQL fortfahren.
Bereitstellen von ProxySQL mit ClusterControl
Die Bereitstellung von ProxySQL in ClusterControl ist nur eine Frage von wenigen Klicks.
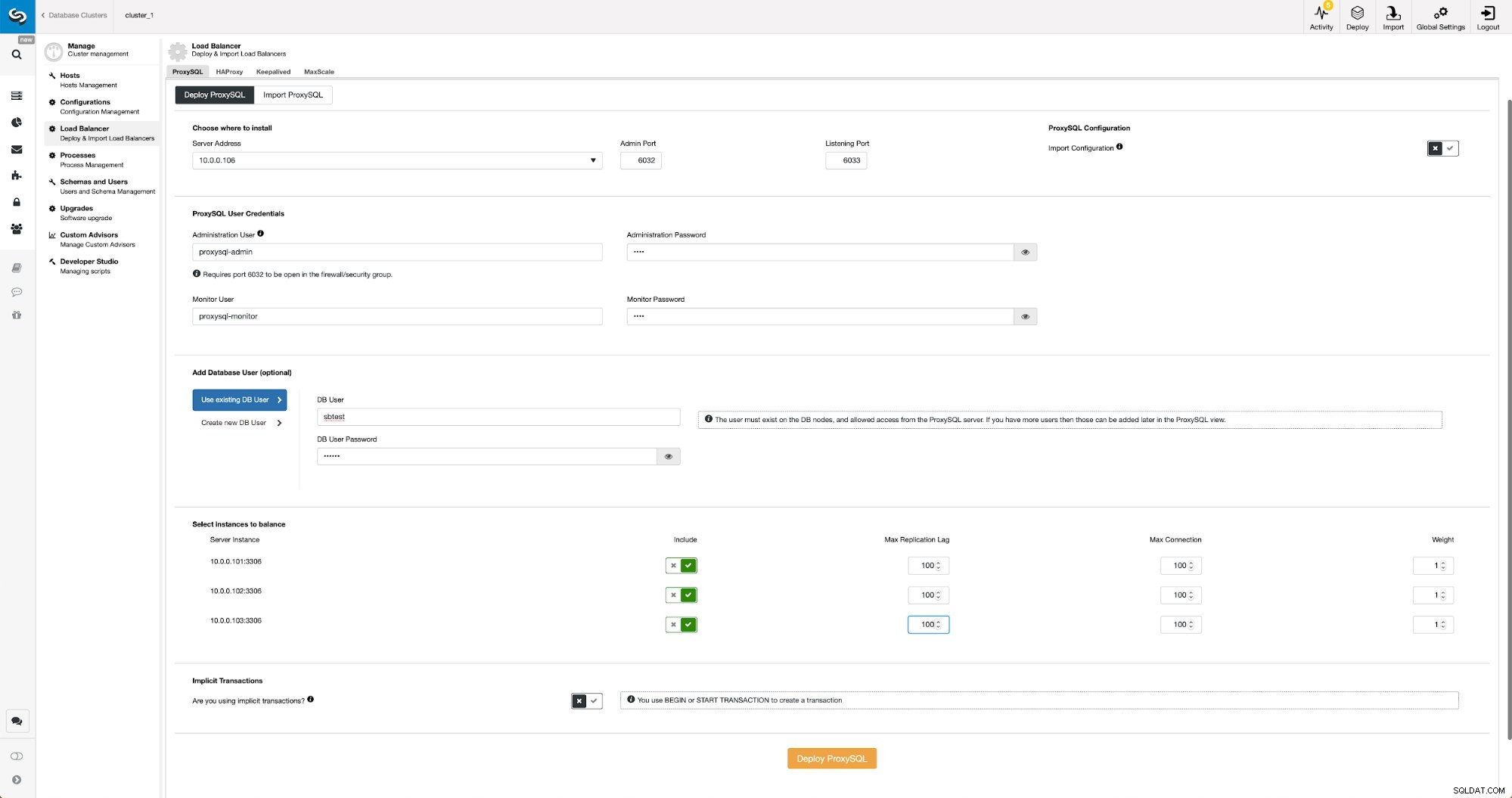 Stellen Sie ProxySQL in ClusterControl bereit
Stellen Sie ProxySQL in ClusterControl bereit Wir mussten die IP oder den Hostnamen eines Knotens auswählen, Anmeldeinformationen für den CLI-Verwaltungsbenutzer und den MySQL-Überwachungsbenutzer übergeben. Wir haben uns entschieden, vorhandenes MySQL zu verwenden, und wir haben Zugangsdaten für den Benutzer „sbtest“ @ „%“ übergeben, den wir in der Anwendung verwenden. Wir haben ausgewählt, welche Knoten wir im Load Balancer verwenden möchten, wir haben auch die maximale Replikationsverzögerung (wenn dieser Schwellenwert überschritten wird, sendet ProxySQL den Datenverkehr nicht an diesen Slave) von standardmäßig 10 Sekunden auf 100 erhöht, da wir bereits unter der Replikation leiden Verzögerung. Nach kurzer Zeit werden dem Cluster ProxySQL-Knoten hinzugefügt.
Bereitstellen von Keepalived für ProxySQL mit ClusterControl
Wenn ProxySQL-Knoten hinzugefügt wurden, ist es an der Zeit, Keepalived bereitzustellen.
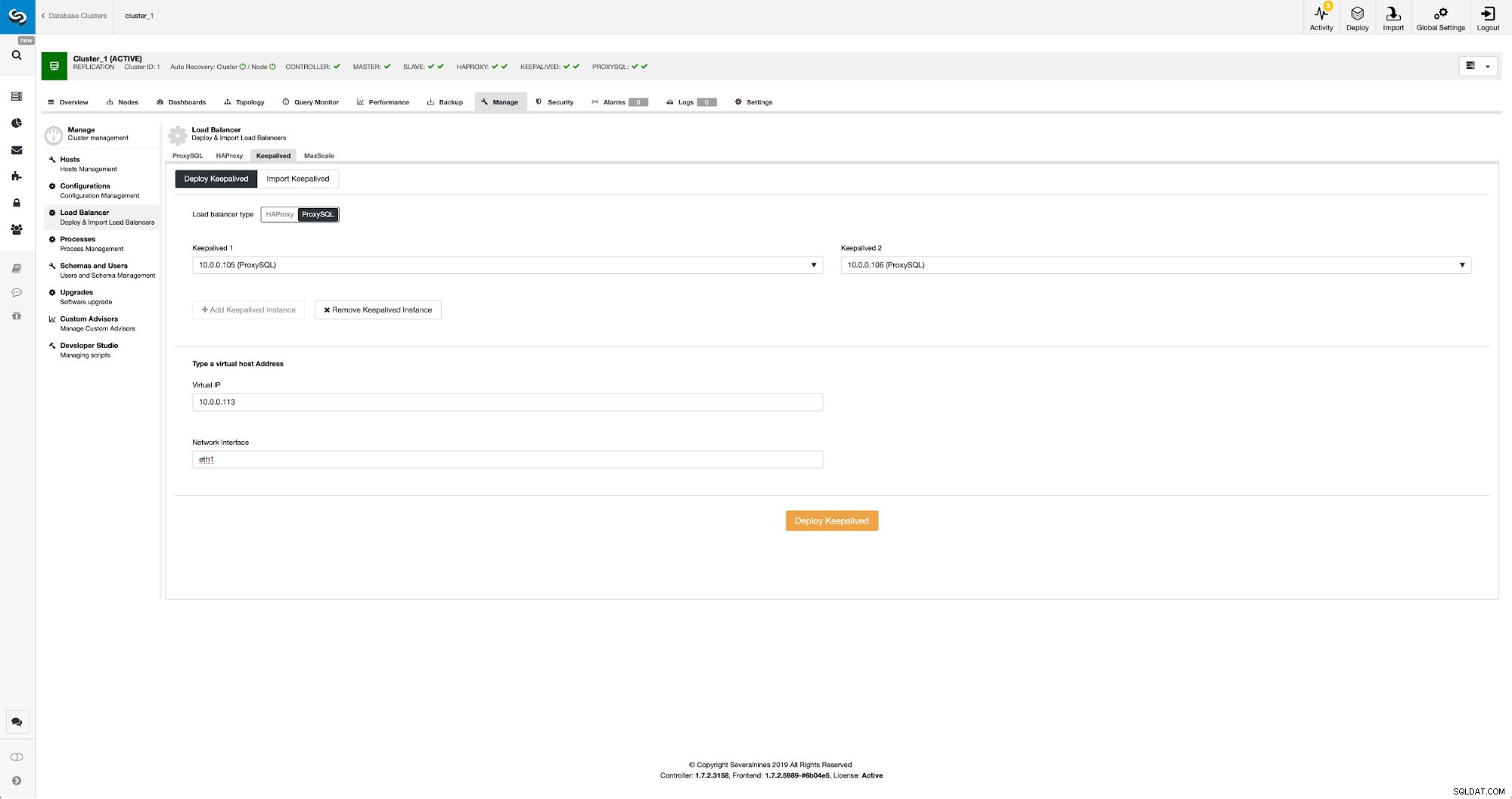 Mit ProxySQL in ClusterControl beibehalten
Mit ProxySQL in ClusterControl beibehalten Wir mussten lediglich auswählen, auf welchen ProxySQL-Knoten Keepalived bereitgestellt werden soll, sowie virtuelle IP und Schnittstelle, an die VIP gebunden wird. Wenn die Bereitstellung abgeschlossen ist, werden wir den Datenverkehr auf das neue Setup umstellen, indem wir eine der im Abschnitt „Umstellen des Datenverkehrs auf das ProxySQL-Setup“ oben genannten Methoden verwenden.
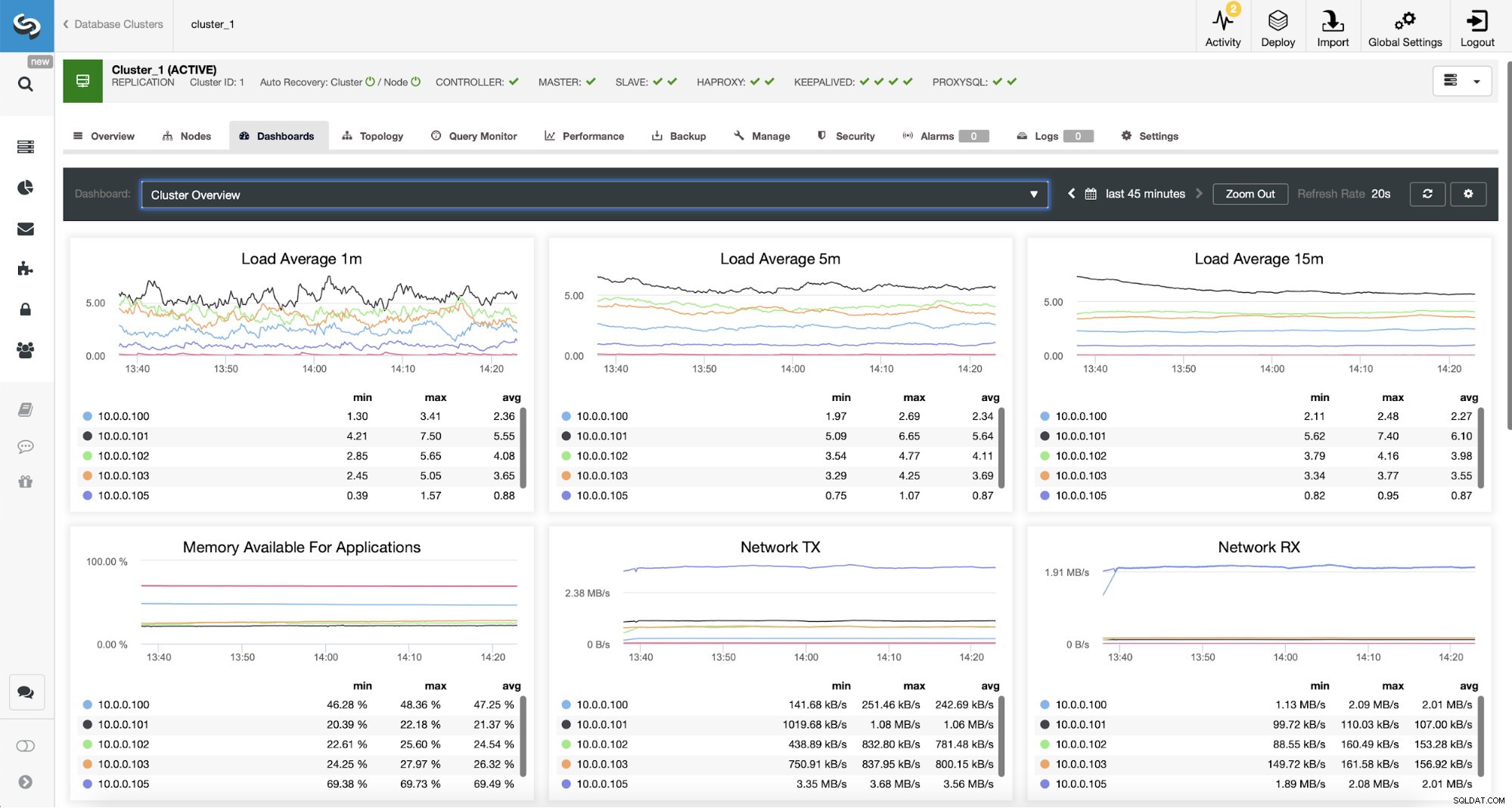 Überwachung des ProxySQL-Datenverkehrs in ClusterControl
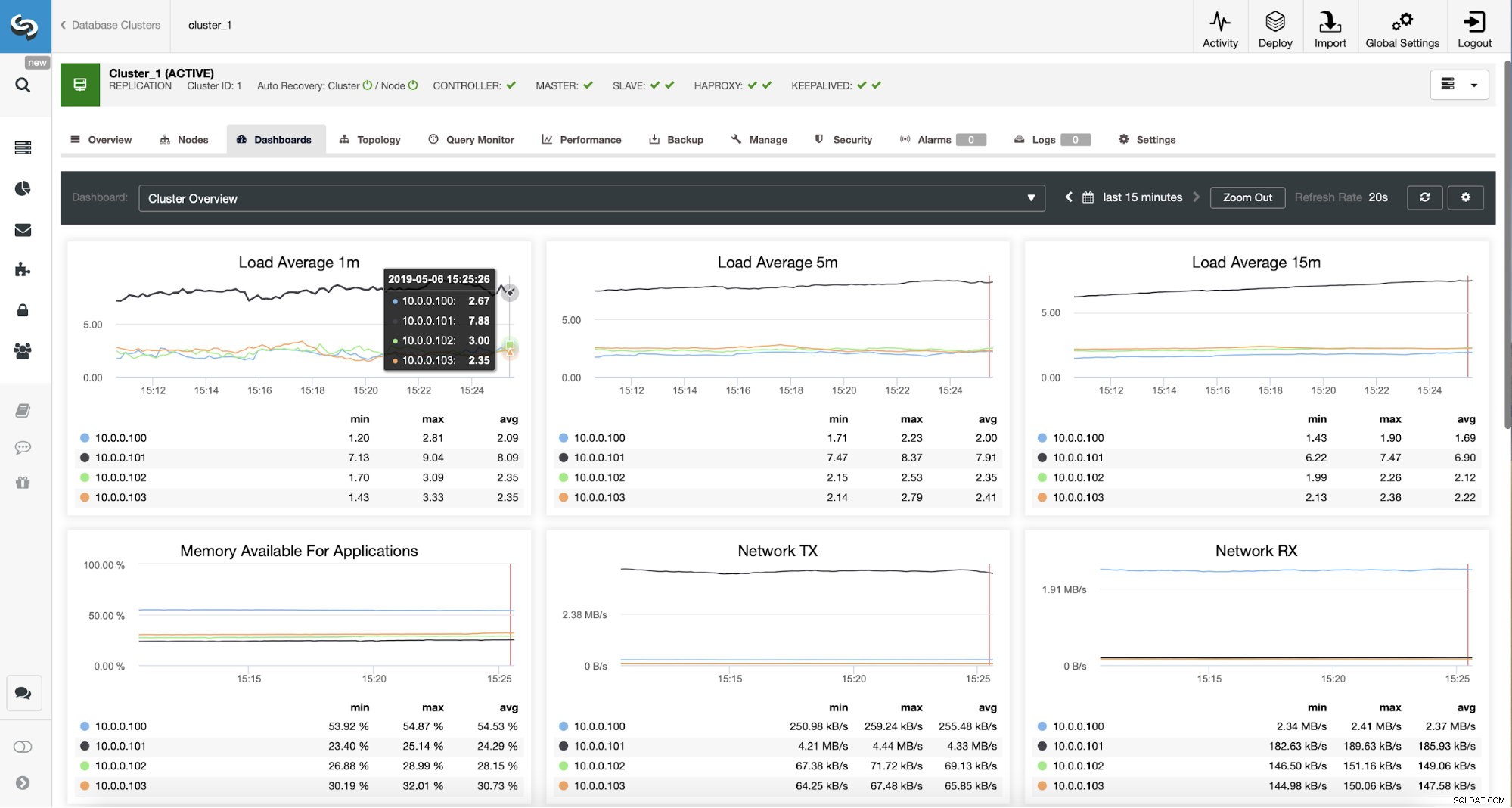
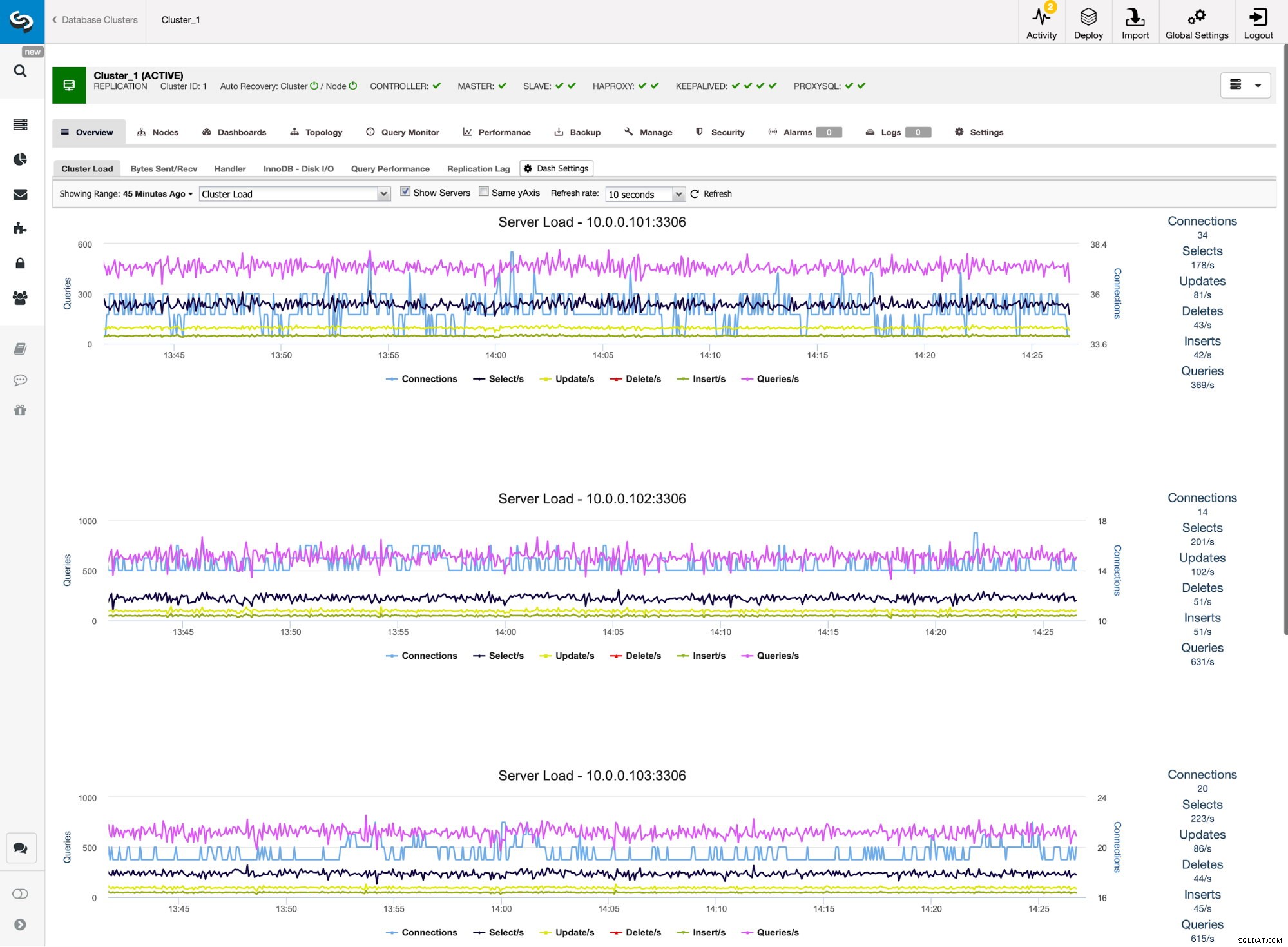
Überwachung des ProxySQL-Datenverkehrs in ClusterControl Wir können überprüfen, ob der Datenverkehr auf ProxySQL umgestellt wurde, indem wir uns das Lastdiagramm ansehen – wie Sie sehen können, ist die Last viel stärker auf die Knoten im Cluster verteilt. Sie können dies auch im Diagramm unten sehen, das die Verteilung der Abfragen im Cluster zeigt.
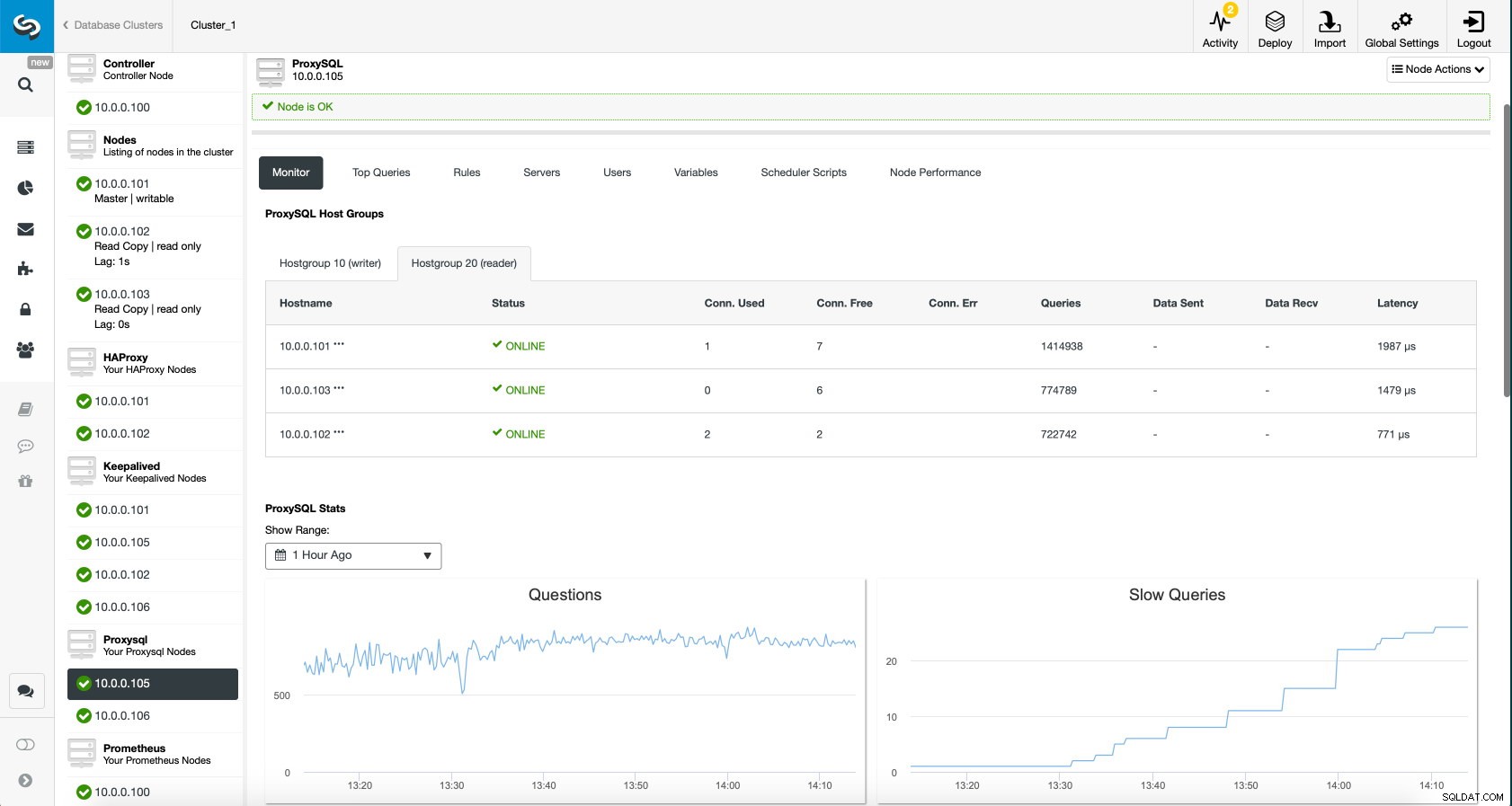
 ProxySQL-Dashboard in ClusterControl
ProxySQL-Dashboard in ClusterControl Schließlich zeigt das ProxySQL-Dashboard auch, dass der Datenverkehr auf alle Knoten im Cluster verteilt wird:
 ProxySQL-Dashboard in ClusterControl
ProxySQL-Dashboard in ClusterControl Wir hoffen, dass Sie von diesem Blogbeitrag profitieren werden, wie Sie sehen können, da die Bereitstellung der neuen Architektur mit ClusterControl nur einen Moment dauert und nur eine Handvoll Klicks erfordert, um die Dinge zum Laufen zu bringen. Teilen Sie uns Ihre Erfahrungen mit solchen Migrationen mit.



