Einführung
In Datenbankkreisen ist allgemein bekannt, dass Indizes die Abfrageleistung verbessern, indem sie entweder die erforderliche Ergebnismenge vollständig erfüllen (Covering Indexes) oder als Nachschlagewerke fungieren, die die Abfragemaschine einfach an den genauen Ort des erforderlichen Datensatzes leiten. Wie erfahrene DBAs jedoch wissen, sollte man sich nicht zu sehr für das Erstellen von Indizes in OLTP-Umgebungen interessieren, ohne die Art der Arbeitslast zu verstehen. Mit dem Abfragespeicher in einer SQL Server 2019-Instanz (der Abfragespeicher wurde in SQL Server 2016 eingeführt) ist es ganz einfach, die Auswirkung eines Indexes auf Einfügungen zu zeigen.
Ohne Index einfügen
Wir beginnen mit der Wiederherstellung der WideWorldImporters-Beispieldatenbank und erstellen dann eine Kopie der Sales. Rechnungstabelle mit dem Skript in Listing 1. Beachten Sie, dass die Beispieldatenbank den Abfragespeicher bereits im Lese-/Schreibmodus aktiviert hat.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Beachten Sie, dass die gerade erstellte Tabelle überhaupt keine Indizes enthält. Alles, was wir haben, ist die Tabellenstruktur. Sobald dies erledigt ist, führen wir Einfügungen in die neue Tabelle durch, wobei wir die Daten der übergeordneten Tabelle verwenden, wie in Listing 2 gezeigt.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Während dieses Vorgangs erfasst der Abfragespeicher den Ausführungsplan der Abfrage. Abbildung 1 zeigt kurz, was unter der Haube passiert. Von links nach rechts lesend sehen wir, dass SQL Server die Einfügungen mit Plan-ID 563 ausführt – ein Index-Scan für den Primärschlüssel der Quelltabelle, um die Daten abzurufen, und dann ein Table Insert für die Zieltabelle. (Lesung von links nach rechts). Beachten Sie, dass in diesem Fall der Großteil der Kosten auf die Tischeinlage entfällt – 99 % der Abfragekosten.
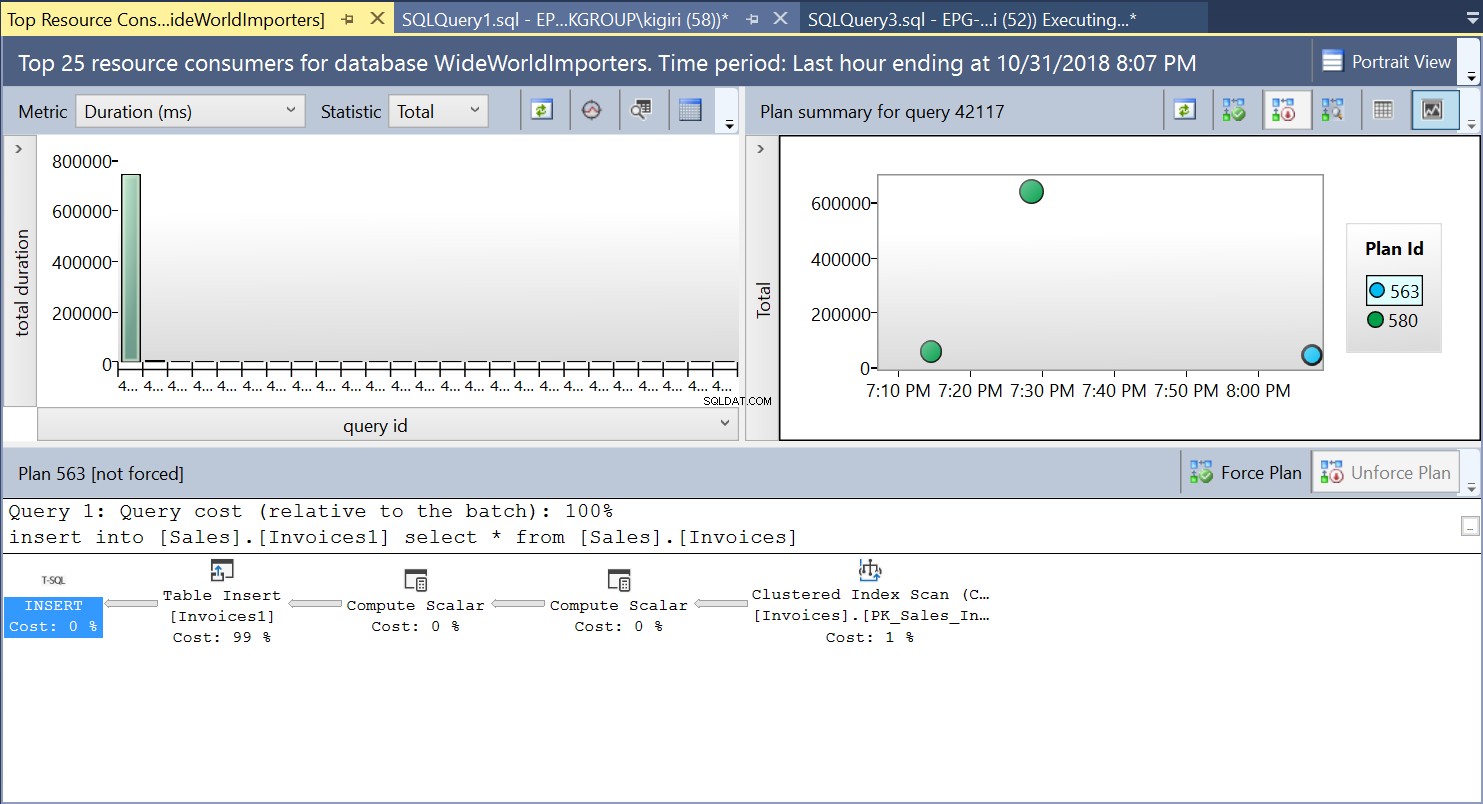
Abb. 1 Ausführungsplan 563
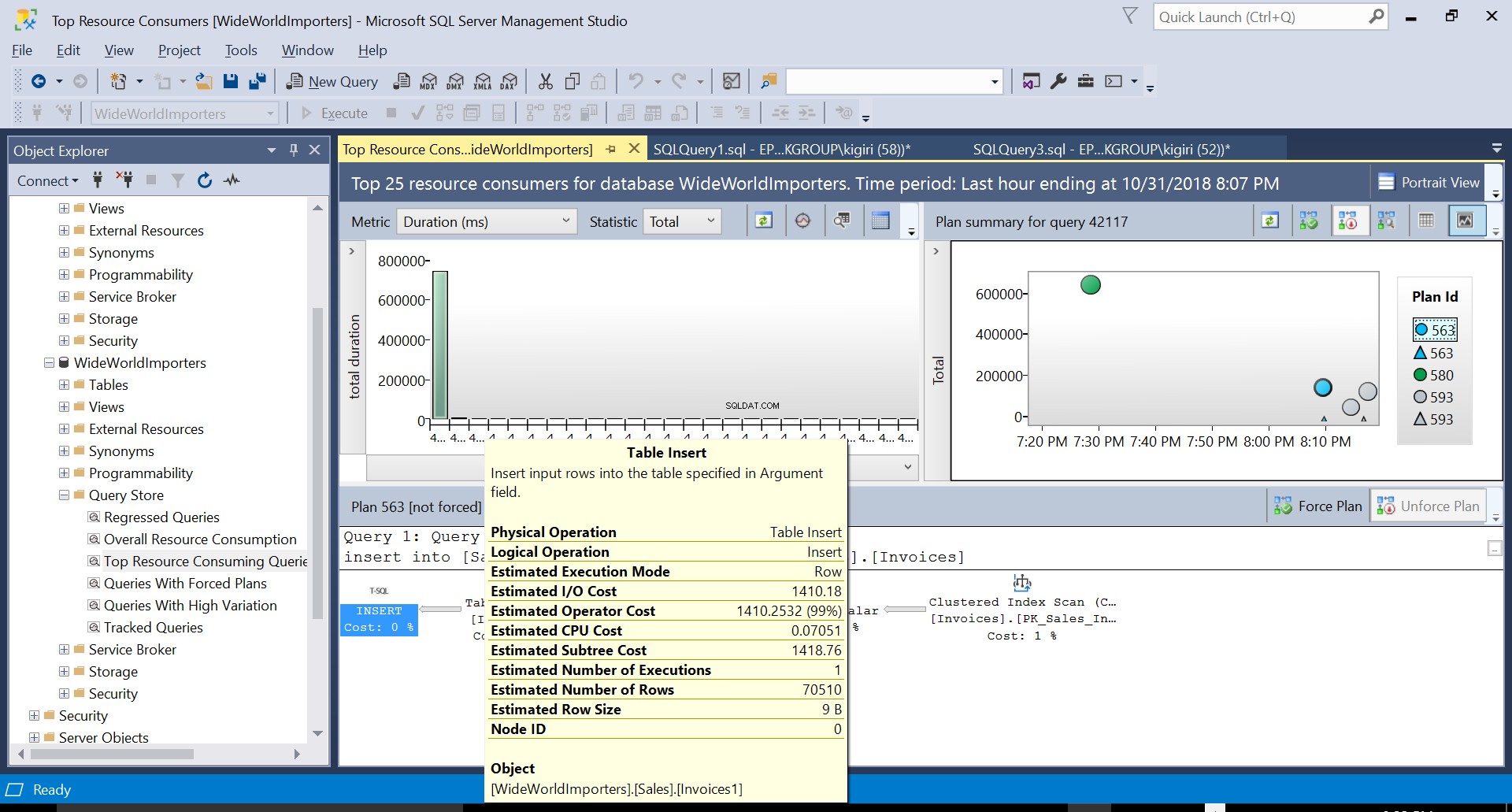
Abb. 2 Tabelleneinfügung am Ziel
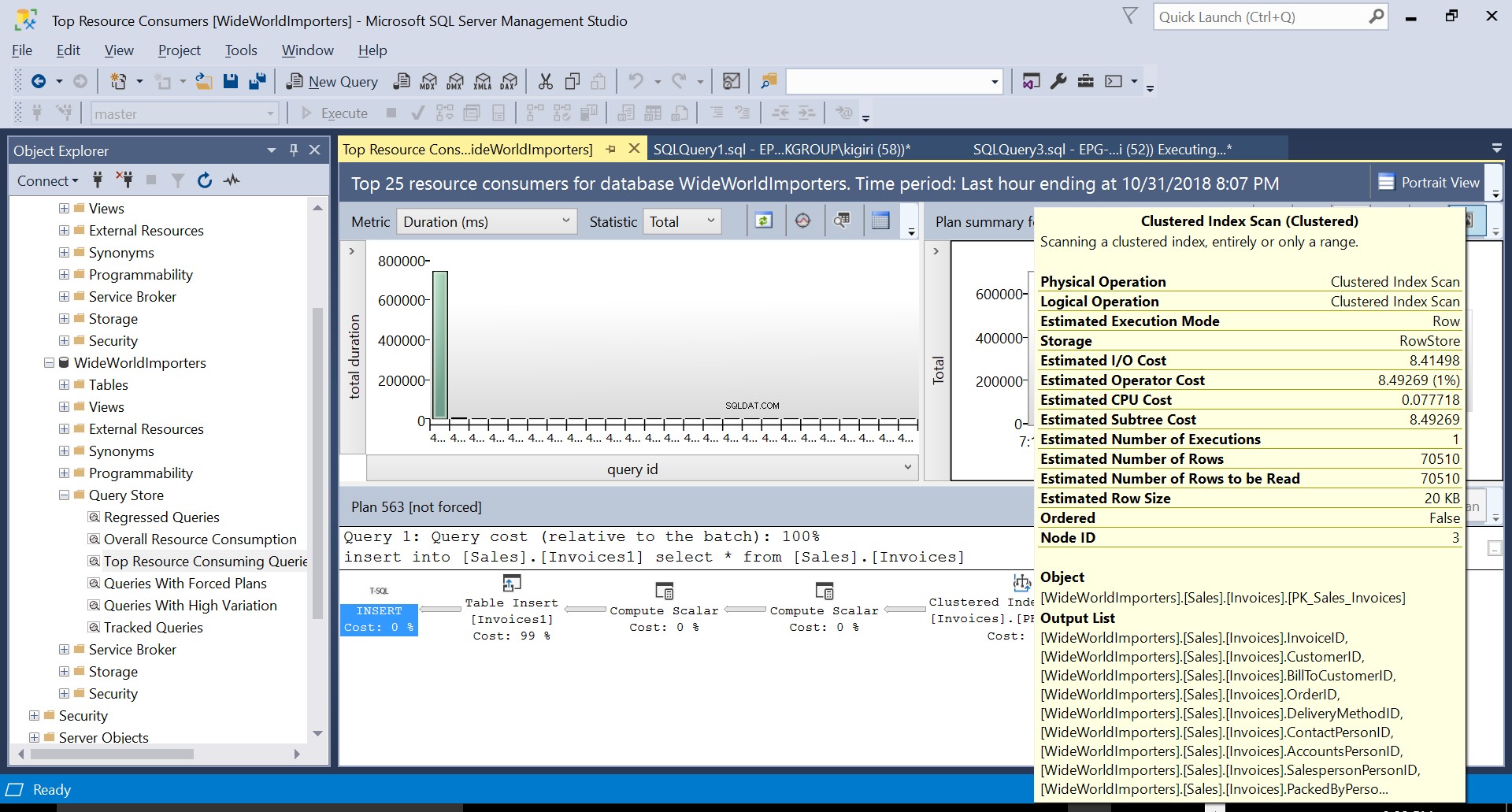
Abb. 3 Clustered Index Scan auf Quelltabelle
Mit Index einfügen
Anschließend erstellen wir mithilfe der DDL in Listing 3 einen Index für die Zieltabelle. Wenn wir die Anweisung in Listing 2 nach dem Abschneiden der Zieltabelle wiederholen, sehen wir einen etwas anderen Ausführungsplan (Plan-ID 593 in Abb. 4). Wir sehen immer noch die Tabelleneinlage, aber sie trägt nur zu 58 % bei zu den Kosten der Abfrage. Die Ausführungsdynamik wird durch die Einführung einer Sortierung und einer Index-Einfügung etwas verzerrt. Was im Wesentlichen passiert, ist, dass SQL Server entsprechende Zeilen in den Index einführen muss, wenn neue Datensätze in die Tabelle eingeführt werden.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
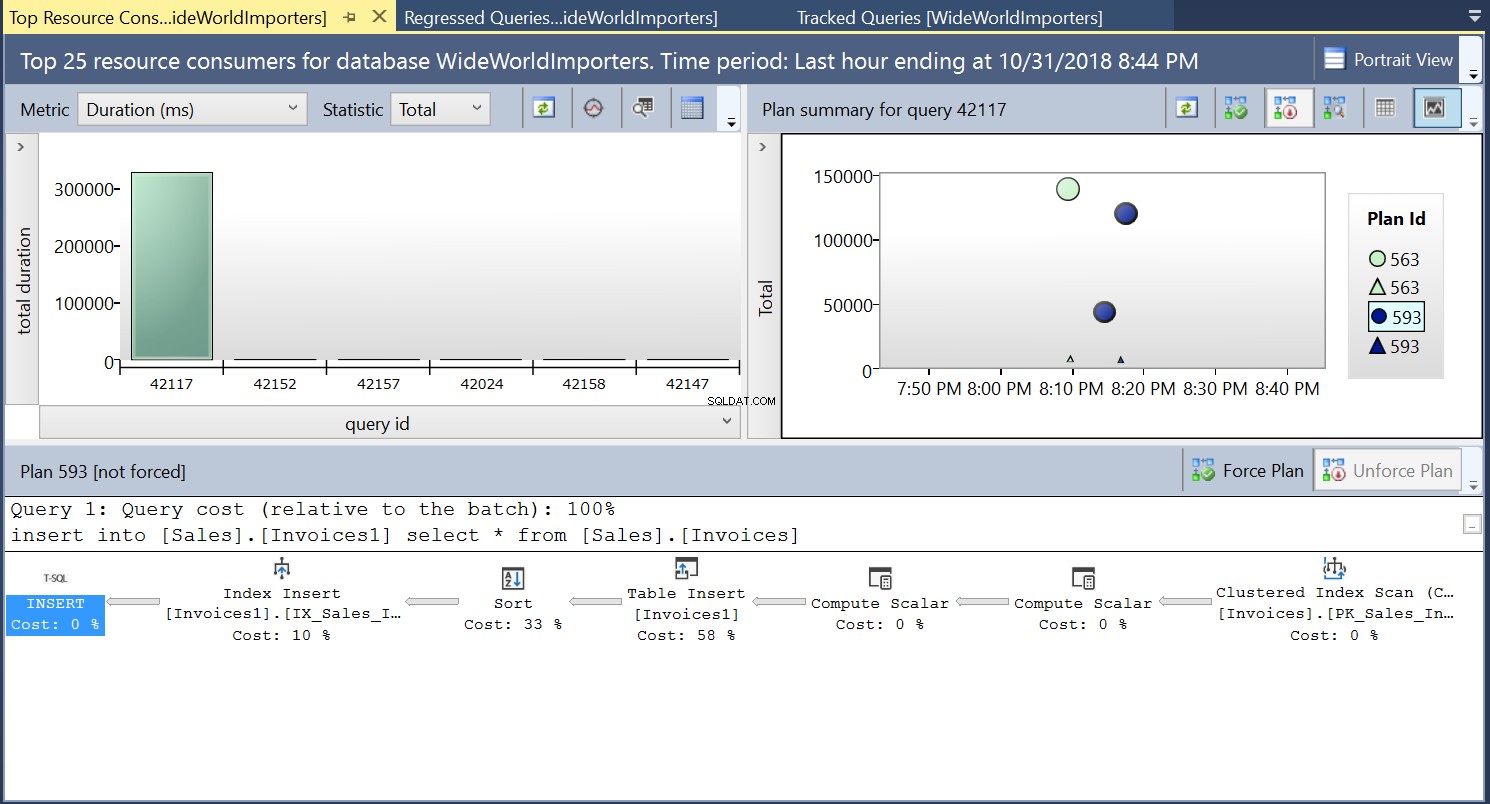
Abb. 4 Ausführungsplan 593
Tiefer schauen
Wir können die Details beider Pläne untersuchen und sehen, wie diese neuen Faktoren die Ausführungszeit der Anweisung eskalieren. Plan 593 fügt der durchschnittlichen Dauer der Anweisung weitere 300 ms oder so hinzu. Unter hoher Arbeitslast in einer Produktionsumgebung kann dieser Unterschied erheblich sein.
Das Einschalten von STATISTICS IO bei nur einmaliger Ausführung der Insert-Anweisung in beiden Fällen – mit Index auf der Zieltabelle und ohne Index auf der Zieltabelle – zeigt auch, dass mehr Arbeit in Bezug auf logische IO geleistet wird, wenn Zeilen in eine Tabelle mit Indizes eingefügt werden /P>
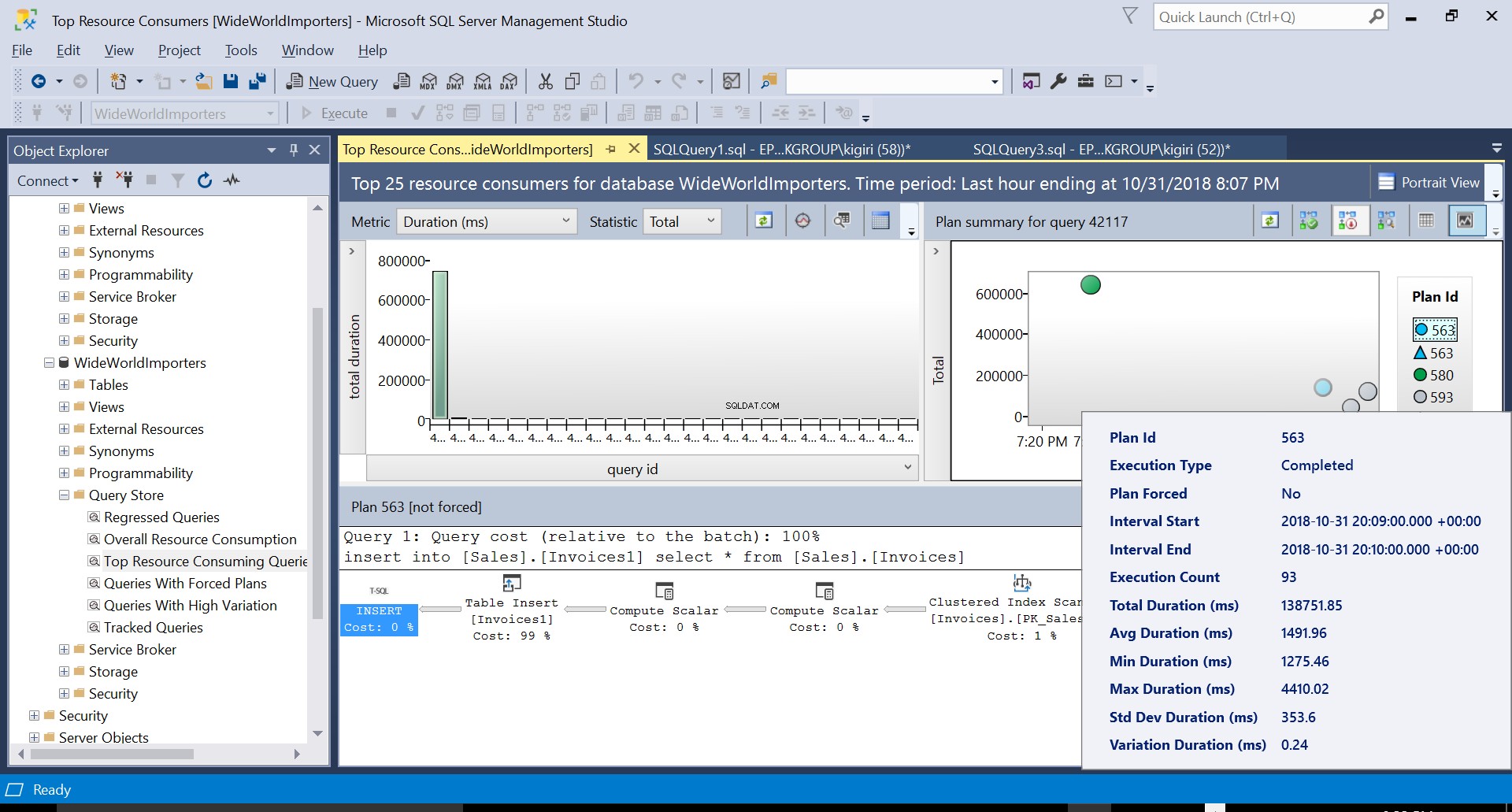
Fig. 5 Details des Ausführungsplans 563
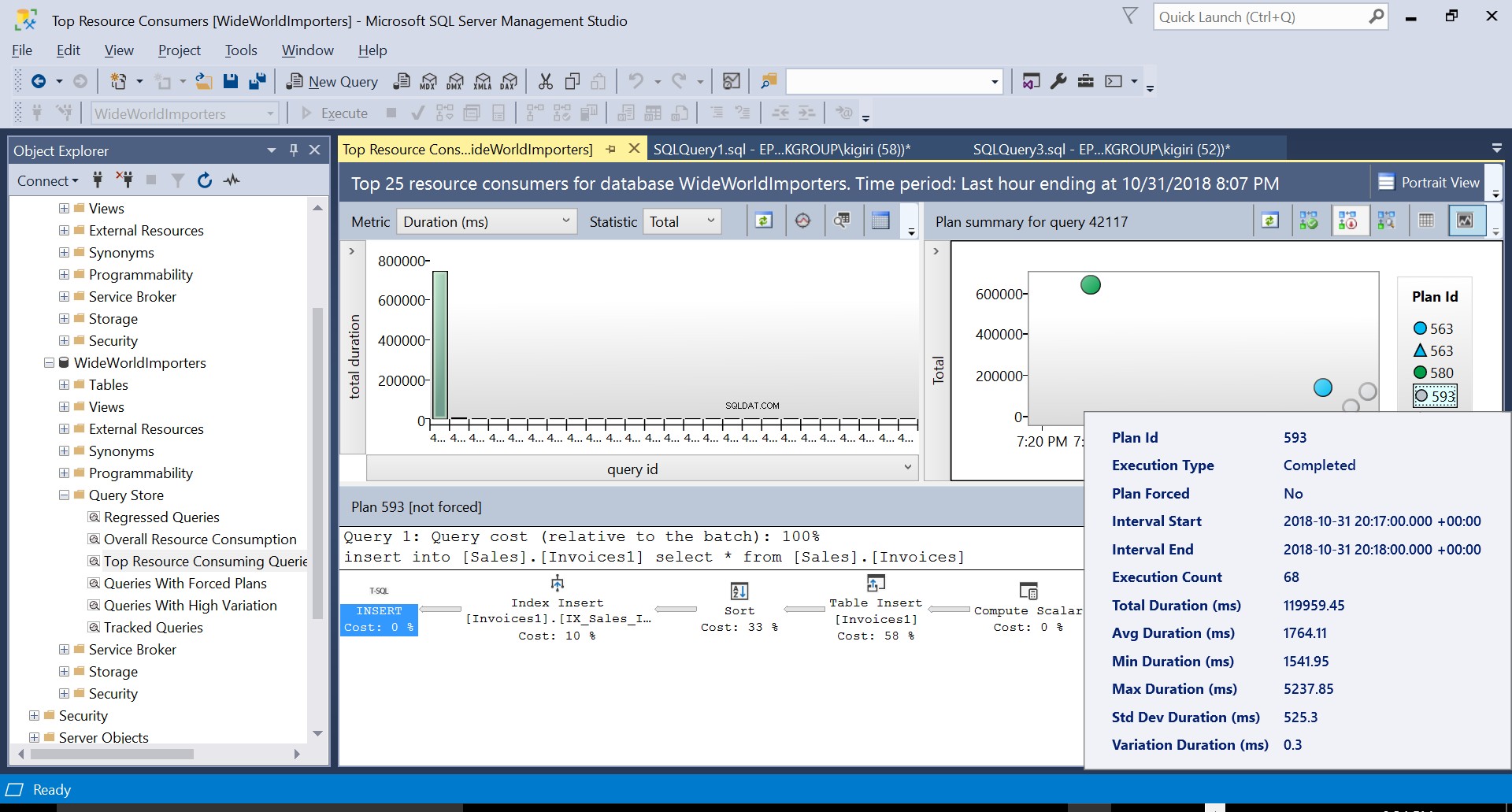
Fig. 4 Einzelheiten des Ausführungsplans 593
Kein Index:Ausgabe mit aktiviertem STATISTICS IO:
Tabelle „Rechnungen1“. Scananzahl 0, logische Lesevorgänge 78372 , Physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logical-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Tabelle „Rechnungen“. Scan-Anzahl 1, logische Lesevorgänge 11400, Physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logical-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
(70510 Zeilen betroffen)
Index:Ausgabe mit aktiviertem STATISTICS IO:
Tabelle „Rechnungen1“. Scananzahl 0, logische Lesevorgänge 81119 , Physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logical-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Tabelle ‘Worktable’. Scan-Anzahl 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Tabelle „Rechnungen“. Scananzahl 1, logische Lesevorgänge 11400 , Physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logical-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
(70510 Zeilen betroffen)
Zusätzliche Informationen
Microsoft und andere Quellen stellen Skripte bereit, um die Produktionsumgebung von Indizes zu untersuchen und Situationen wie die folgenden zu identifizieren:
- Redundante Indizes – Indizes, die dupliziert werden
- Fehlende Indizes – Indizes, die die Leistung basierend auf der Arbeitslast verbessern könnten
- Haufen – Tabellen ohne Clustered-Indizes
- Überindizierte Tabellen – Tabellen mit mehr Indizes als Spalten
- Indexnutzung – Anzahl der Suchvorgänge, Scans und Lookups in Indizes
Die Punkte 2, 3 und 5 beziehen sich eher auf die Leistungsbeeinträchtigung in Bezug auf Lesevorgänge, während sich die Punkte 1 und 4 auf die Leistungsbeeinträchtigung in Bezug auf Schreibvorgänge beziehen. Listing 4 und 5 sind zwei Beispiele für diese öffentlich verfügbaren Abfragen.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Schlussfolgerung
Wir haben mithilfe von Query Store gezeigt, dass eine zusätzliche Arbeitslast mit einem Index in den Ausführungsplan einer Beispiel-Einfügeanweisung eingeführt werden kann. In der Produktion können sich übermäßig viele und redundante Indizes negativ auf die Leistung auswirken, insbesondere in Datenbanken, die für OLTP-Workloads vorgesehen sind. Es ist wichtig, verfügbare Skripte und Tools zu verwenden, um Indizes zu untersuchen und festzustellen, ob sie die Leistung tatsächlich unterstützen oder beeinträchtigen.
Nützliches Tool:
dbForge Index Manager – praktisches SSMS-Add-in zum Analysieren des Status von SQL-Indizes und Beheben von Problemen mit der Indexfragmentierung.