Haben Sie jemals Microsoft oder einen Microsoft-Partner kontaktiert und mit ihnen besprochen, was es kosten würde, in die Cloud zu wechseln? Wenn ja, haben Sie vielleicht schon vom DTU-Rechner von Azure SQL-Datenbank gehört, und Sie haben vielleicht auch gelesen, wie er von Andy Mallon rückentwickelt wurde. Der DTU-Rechner ist ein kostenloses Tool, mit dem Sie Leistungsmetriken von Ihrem Server hochladen und anhand der Daten die geeignete Dienstebene bestimmen können, wenn Sie diesen Server zu einer Azure SQL-Datenbank (oder zu einem Pool für elastische SQL-Datenbanken) migrieren.
Dazu müssen Sie ein Skript (Befehlszeile oder Powershell, zum Download auf der DTU-Rechner-Website verfügbar) während eines Zeitraums einer typischen Produktionsarbeitslast entweder planen oder manuell ausführen.
Wenn Sie versuchen, eine große Umgebung zu analysieren, oder Daten von bestimmten Zeitpunkten analysieren möchten, kann dies zu einer lästigen Pflicht werden. In vielen Fällen haben viele DBAs eine Art Überwachungstool, das bereits Leistungsdaten für sie erfasst. In vielen Fällen erfasst es wahrscheinlich bereits die erforderlichen Metriken oder kann einfach konfiguriert werden, um die benötigten Daten zu erfassen. Heute sehen wir uns an, wie wir SentryOne nutzen können, damit wir die entsprechenden Daten für den DTU-Rechner bereitstellen können.
Schauen wir uns zunächst die Informationen an, die vom Befehlszeilendienstprogramm und dem PowerShell-Skript abgerufen werden, die auf der Website des DTU-Rechners verfügbar sind. Es gibt 4 Leistungsmonitorzähler, die erfasst werden:
- Prozessor – % Prozessorzeit
- Logischer Datenträger – Datenträgerlesevorgänge/Sek.
- Logischer Datenträger – Datenträgerschreibvorgänge/Sek.
- Datenbank – Gelöschte Protokollbytes/Sek.
Der erste Schritt besteht darin, festzustellen, ob diese Metriken bereits als Teil der Datenerfassung in SQL Sentry erfasst werden. Zur Entdeckung schlage ich vor, diesen Blogbeitrag von Jason Hall zu lesen, in dem er erklärt, wie die Daten angeordnet sind und wie Sie sie abfragen können. Ich werde hier nicht jeden Schritt durchgehen, aber ich ermutige Sie, diese gesamte Blogserie zu lesen und mit einem Lesezeichen zu versehen.
Als ich die SentryOne-Datenbank durchsah, stellte ich fest, dass 3 der 4 Zähler bereits standardmäßig erfasst wurden. Das einzige, was fehlte, war [Database – Log Bytes Flushed/sec] , also musste ich in der Lage sein, das einzuschalten. Es gab einen weiteren Blogbeitrag von Justin Randall, der erklärt, wie das geht.
Kurz gesagt, Sie können den [PerformanceAnalysisCounter] abfragen Tabelle.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Sie werden feststellen, dass standardmäßig die [PerformanceAnalysisSampleIntervalID] auf 0 gesetzt – das heißt, es ist deaktiviert. Sie müssen den folgenden Befehl ausführen, um dies zu aktivieren. Ziehen Sie einfach die ID aus der SELECT-Abfrage, die Sie gerade ausgeführt haben, und verwenden Sie sie in diesem UPDATE:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Nach dem Ausführen des Updates müssen Sie die für dieses Ziel relevanten SentryOne-Überwachungsdienste neu starten, damit die neuen Zählerdaten erfasst werden können.
Beachten Sie, dass ich [PerformanceAnalysisSampleIntervalID] festgelegt habe auf 1, sodass die Daten alle 10 Sekunden erfasst werden. Sie könnten diese Daten jedoch seltener erfassen, um die Größe der erfassten Daten auf Kosten einer geringeren Genauigkeit zu minimieren. Siehe [PerformanceAnalysisSampleInterval] Tabelle für eine Liste von Werten, die Sie verwenden können.
Erwarten Sie nicht, dass die Daten sofort in die Tabellen fließen; Dies wird einige Zeit dauern, bis es seinen Weg durch das System gefunden hat. Sie können die Bevölkerung mit der folgenden Abfrage überprüfen:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Nachdem Sie bestätigt haben, dass die Daten angezeigt werden, sollten Sie Daten für alle Metriken haben, die vom DTU-Rechner benötigt werden, obwohl Sie mit der Extrahierung warten möchten, bis Sie eine repräsentative Stichprobe aus einer vollständigen Arbeitslast oder einem Geschäftszyklus haben.
Wenn Sie Jasons Blogbeitrag lesen, werden Sie feststellen, dass die Daten in verschiedenen Rollup-Tabellen gespeichert sind und dass jede dieser Rollup-Tabellen unterschiedliche Aufbewahrungsraten hat. Viele davon sind niedriger als das, was ich mir wünschen würde, wenn ich die Workloads über einen bestimmten Zeitraum analysiere. Es ist zwar möglich, diese zu ändern, aber es ist vielleicht nicht die klügste. Da das, was ich Ihnen zeige, nicht unterstützt wird, sollten Sie vermeiden, zu viel an SentryOne-Einstellungen herumzubasteln, da dies negative Auswirkungen auf die Leistung, das Wachstum oder beides haben könnte.
Um dies zu kompensieren, habe ich ein Skript erstellt, mit dem ich die Daten extrahieren kann, die ich für die verschiedenen Rollup-Tabellen benötige, und diese Daten an einem eigenen Ort speichert, sodass ich meine eigene Aufbewahrung kontrollieren und die SentryOne-Funktionalität nicht beeinträchtigen kann.
TABELLE:dbo.AzureDatabaseDTUData
Ich habe eine Tabelle namens [AzureDatabaseDTUData] erstellt und in der SentryOne-Datenbank gespeichert. Die von mir erstellte Prozedur generiert diese Tabelle automatisch, wenn sie nicht vorhanden ist. Sie müssen dies also nicht manuell tun, es sei denn, Sie möchten den Speicherort anpassen. Sie können dies in einer separaten Datenbank speichern, wenn Sie möchten, Sie müssten dazu nur das Skript bearbeiten. Die Tabelle sieht folgendermaßen aus:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Prozedur:dbo.Custom_CollectDTUDataForDevice
Dies ist die gespeicherte Prozedur, die Sie verwenden können, um alle DTU-spezifischen Daten auf einmal abzurufen (vorausgesetzt, Sie haben den Protokollbytezähler ausreichend lange gesammelt) oder planen Sie, dass sie regelmäßig zu den gesammelten Daten hinzugefügt wird, bis Sie können die Ausgabe an den DTU-Rechner senden. Wie die obige Tabelle wird die Prozedur in der SentryOne-Datenbank erstellt, aber Sie könnten sie auch leicht an anderer Stelle erstellen, indem Sie Objektreferenzen einfach drei- oder vierteilige Namen hinzufügen. Die Schnittstelle zur Prozedur ist wie folgt:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Hinweis :Das gesamte Verfahren ist etwas langwierig, daher ist es diesem Beitrag beigefügt (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Es gibt ein paar Parameter, die Sie verwenden können. Jeder hat einen Standardwert, sodass Sie ihn nicht angeben müssen, wenn Sie mit den Standardwerten zufrieden sind.
- @Geräte-ID – Auf diese Weise können Sie angeben, ob Sie Daten für einen bestimmten SQL Server oder alles sammeln möchten. Der Standardwert ist -1, was bedeutet, dass alle überwachten SQL-Server kopiert werden. Wenn Sie nur Informationen für eine bestimmte Instanz exportieren möchten, suchen Sie die
DeviceIDentsprechend dem Host in[dbo].[Device]Tabelle, und übergeben Sie diesen Wert. Sie können nur eine@DeviceIDübergeben Wenn Sie also eine Reihe von Servern durchlaufen möchten, können Sie die Prozedur mehrmals aufrufen oder die Prozedur ändern, um eine Reihe von Geräten zu unterstützen. - @DaysToPurge – Dies stellt das Alter dar, in dem Sie Daten entfernen möchten. Der Standardwert ist 14 Tage, was bedeutet, dass Sie nur Daten abrufen, die bis zu 14 Tage alt sind, und alle Daten, die älter als 14 Tage sind, in Ihrer benutzerdefinierten Tabelle gelöscht werden.
Die anderen vier Parameter dienen der Zukunftssicherheit, falls sich die SentryOne-Enumerationen für Zähler-IDs jemals ändern.
Ein paar Anmerkungen zum Drehbuch:
- Wenn die Daten abgerufen werden, wird der maximale Wert aus der abgeschnittenen Minute genommen und exportiert. Das bedeutet, dass es einen Wert pro Metrik pro Minute gibt, aber es ist der maximal erfasste Wert. Dies ist wichtig, da die Daten dem DTU-Rechner präsentiert werden müssen.
- Wenn Sie den Export zum ersten Mal ausführen, kann es etwas länger dauern. Dies liegt daran, dass alle Daten basierend auf Ihren Parameterwerten abgerufen werden. Bei jedem weiteren Lauf werden nur die Daten extrahiert, die seit dem letzten Lauf neu sind, also sollte es viel schneller sein.
- Sie müssen dieses Verfahren so planen, dass es nach einem Zeitplan ausgeführt wird, der dem SentryOne-Bereinigungsprozess voraus ist. Ich habe lediglich einen SQL-Agent-Job erstellt, der jede Nacht ausgeführt wird und alle neuen Daten seit der Nacht zuvor sammelt.
- Da der Bereinigungsprozess in SentryOne je nach Metrik variieren kann, könnten Sie Zeilen in Ihrer Kopie erhalten, die für einen bestimmten Zeitraum nicht alle 4 Zähler enthalten. Möglicherweise möchten Sie Ihre Daten erst ab dem Zeitpunkt analysieren, an dem Sie mit dem Extraktionsprozess beginnen.
- Ich habe einen Codeblock aus bestehenden SentryOne-Prozeduren verwendet, um die Rollup-Tabelle für jeden Zähler zu bestimmen. Ich hätte die aktuellen Namen der Tabellen fest codieren können, aber mit der SentryOne-Methode sollte sie mit allen Änderungen an den integrierten Rollup-Prozessen aufwärtskompatibel sein.
Nachdem Ihre Daten in eine eigenständige Tabelle verschoben wurden, können Sie sie mit einer PIVOT-Abfrage in die vom DTU-Rechner erwartete Form umwandeln.
Prozedur:dbo.Custom_ExportDataForDTUCalculator
Ich habe ein weiteres Verfahren erstellt, um die Daten in das CSV-Format zu extrahieren. Der Code für dieses Verfahren ist ebenfalls beigefügt (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Es gibt drei Parameter:
- @Geräte-ID – Smallint, das einem der Geräte entspricht, die Sie sammeln und die Sie an den Rechner senden möchten.
- @BeginTime – Datetime, das die Startzeit in Ortszeit darstellt; Beispiel:
'2018-12-04 05:47:00.000'. Die Prozedur wird in UTC übersetzt. Wenn weggelassen, wird ab dem frühesten Wert in der Tabelle gesammelt. - @EndTime – Datetime, das die Endzeit darstellt, wiederum in Ortszeit; Beispiel:
'2018-12-06 12:54:00.000'. Wenn weggelassen, wird bis zum letzten Wert in der Tabelle gesammelt.
Eine Beispielausführung, um alle für SQLInstanceA gesammelten Daten abzurufen zwischen dem 4. Dezember um 5:47 Uhr und dem 6. Dezember um 12:54 Uhr.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Die Daten müssen in eine CSV-Datei exportiert werden. Machen Sie sich keine Sorgen um die Daten selbst; Ich habe dafür gesorgt, dass die Ergebnisse so ausgegeben werden, dass die CSV-Datei keine identifizierenden Informationen über Ihren Server enthält, sondern nur Daten und Metriken.
Wenn Sie die Abfrage in SSMS ausführen, können Sie mit der rechten Maustaste klicken und Ergebnisse exportieren; Sie haben hier jedoch nur begrenzte Möglichkeiten und müssen die Ausgabe manipulieren, um das vom DTU-Rechner erwartete Format zu erhalten. (Sie können es gerne versuchen und mich wissen lassen, wenn Sie einen Weg finden, dies zu tun.)
Ich empfehle, einfach den in SSMS eingebauten Export-Assistenten zu verwenden. Klicken Sie mit der rechten Maustaste auf die Datenbank und gehen Sie zu Aufgaben -> Daten exportieren. Verwenden Sie als Datenquelle „SQL Server Native Client“ und verweisen Sie auf Ihre SentryOne-Datenbank (oder wo auch immer Sie Ihre Kopie der Daten gespeichert haben). Als Ziel sollten Sie „Flat File Destination“ auswählen. Navigieren Sie zu einem Speicherort, geben Sie der Datei einen Namen und speichern Sie die Datei als CSV.
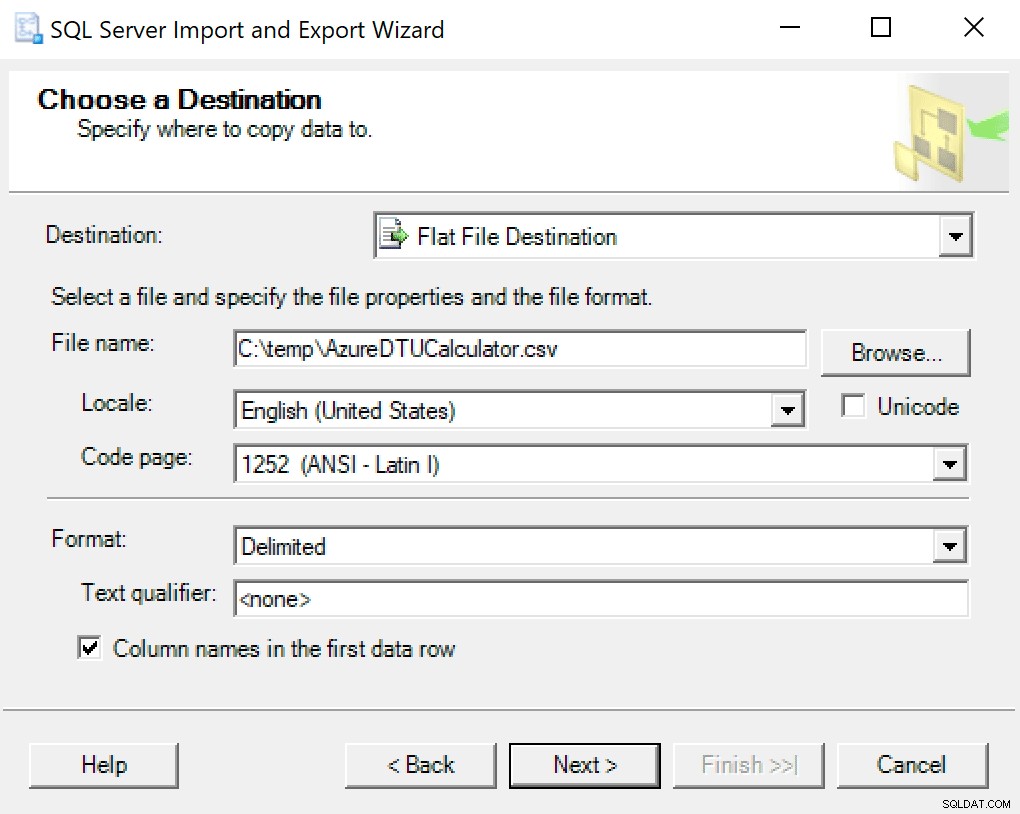
Achten Sie darauf, die Codepage in Ruhe zu lassen; einige können Fehler zurückgeben. Ich weiß, dass 1252 gut funktioniert. Die restlichen Werte belassen Sie als Standard.
Wählen Sie auf dem nächsten Bildschirm die Option Abfrage schreiben, um die zu übertragenden Daten anzugeben .
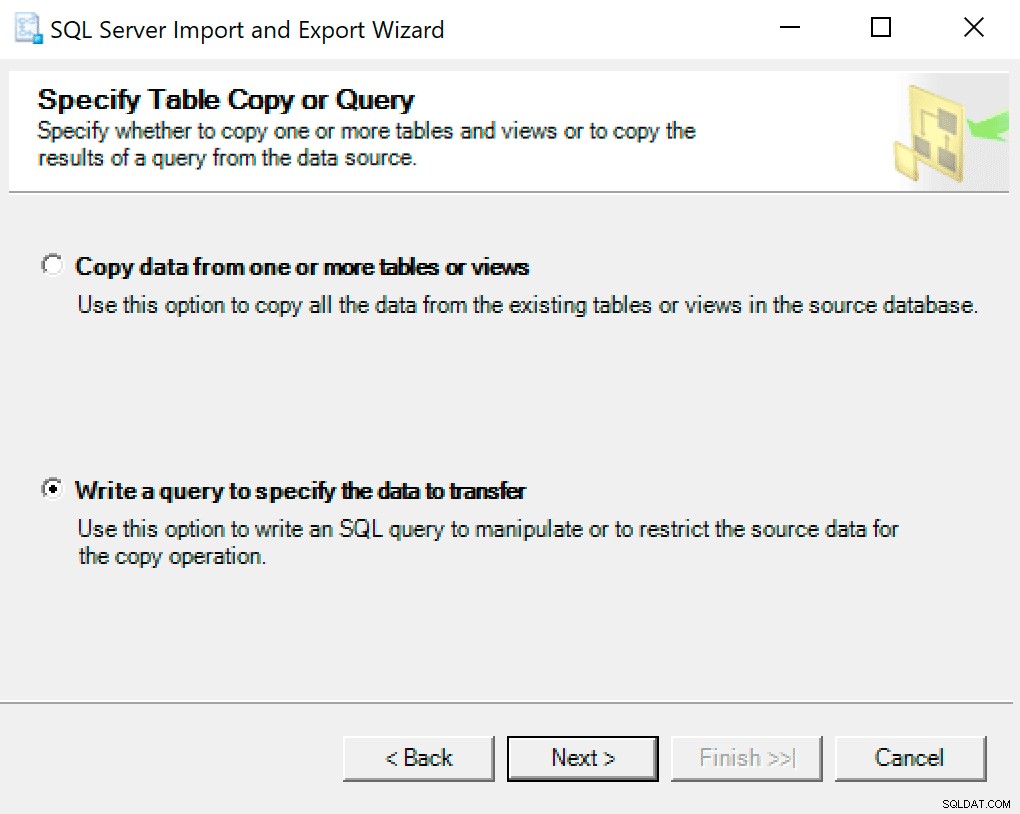
Kopieren Sie im nächsten Fenster den Prozeduraufruf mit Ihren eingestellten Parametern hinein. Klicken Sie auf Weiter.
Wenn Sie zum Ziel für Flatfiles konfigurieren gelangen, belasse ich die Optionen als Standard. Hier ist ein Screenshot, falls es bei Ihnen anders ist:
Schlagen Sie weiter und rennen Sie sofort. Es wird eine Datei erstellt, die Sie im letzten Schritt verwenden werden.
HINWEIS :Sie könnten ein SSIS-Paket erstellen, das Sie dafür verwenden können, und dann Ihre Parameterwerte an das SSIS-Paket übergeben, wenn Sie dies häufig tun. Dies würde verhindern, dass Sie jedes Mal den Assistenten durchlaufen müssen.
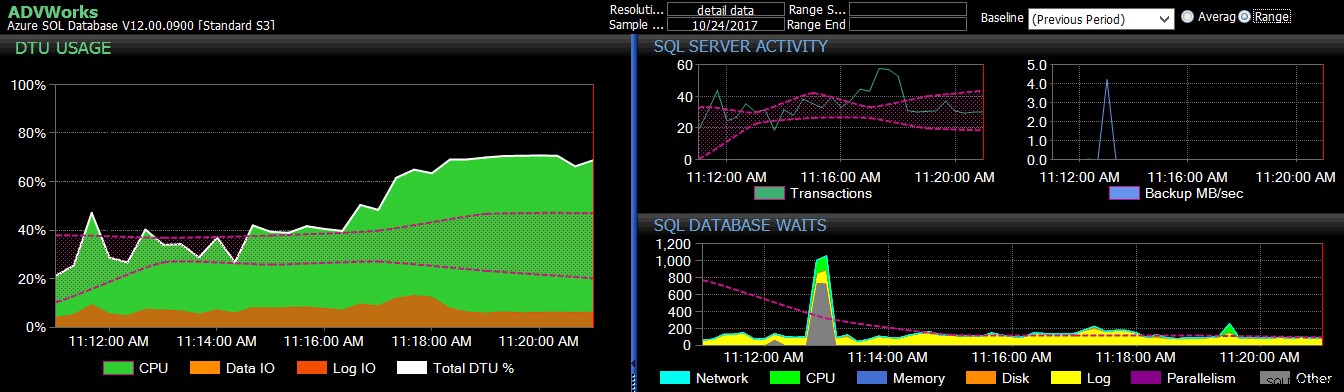
Navigieren Sie zu dem Speicherort, an dem Sie die Datei gespeichert haben, und überprüfen Sie, ob sie dort ist. Wenn Sie es öffnen, sollte es in etwa so aussehen:
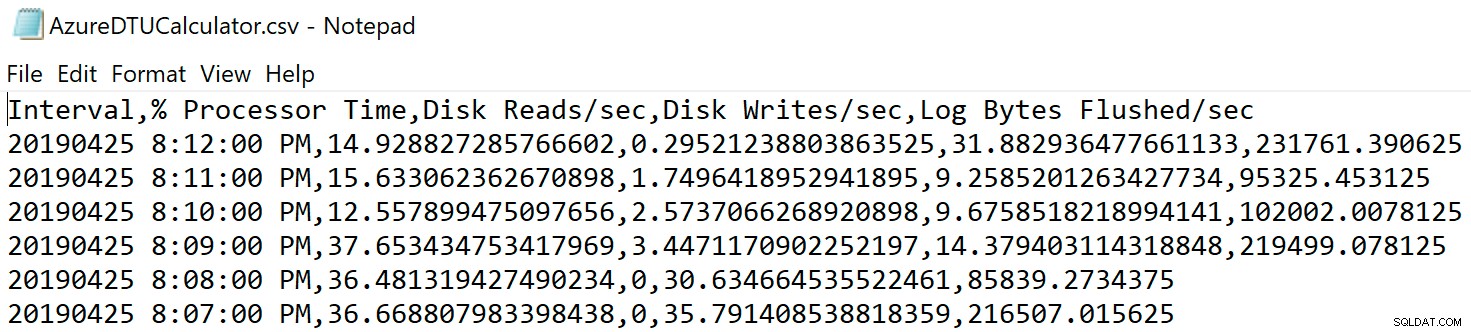
Öffnen Sie die DTU-Rechner-Website und scrollen Sie nach unten zu dem Abschnitt mit der Aufschrift „CSV-Datei hochladen und berechnen“. Geben Sie die Anzahl der Kerne des Servers ein, laden Sie die CSV-Datei hoch und klicken Sie auf Berechnen. Sie erhalten eine Reihe von Ergebnissen wie diese (zum Vergrößern auf ein beliebiges Bild klicken):
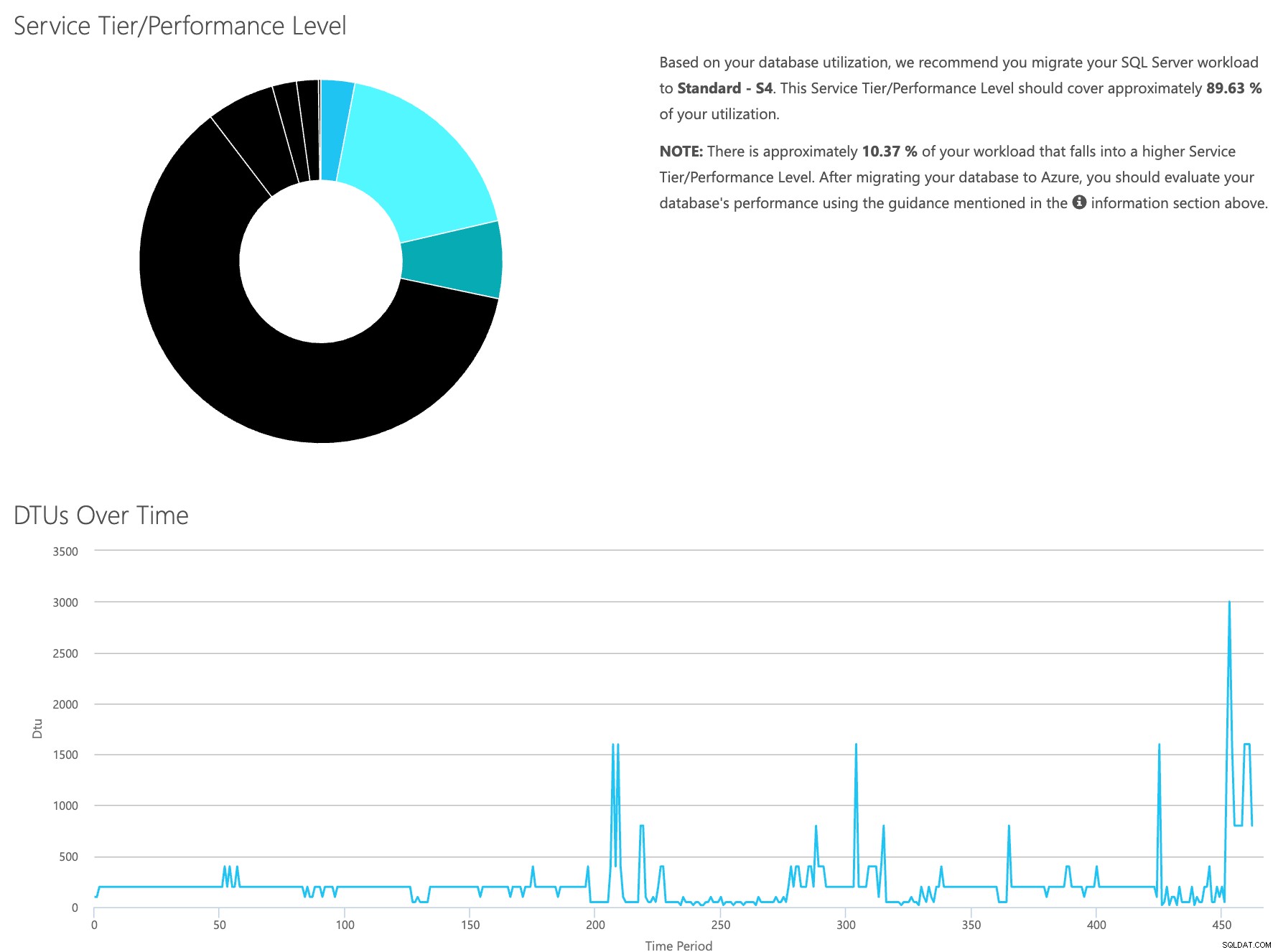
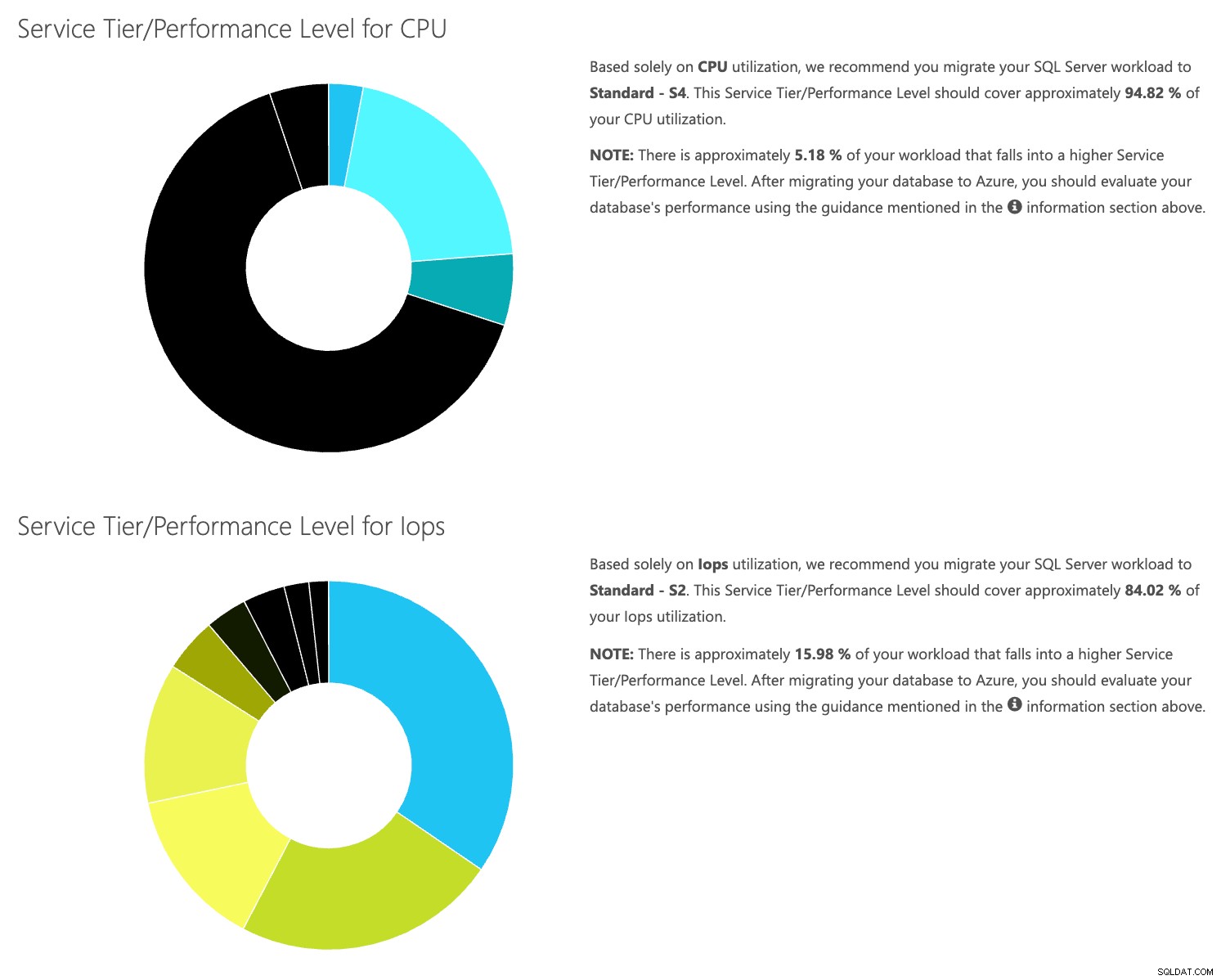
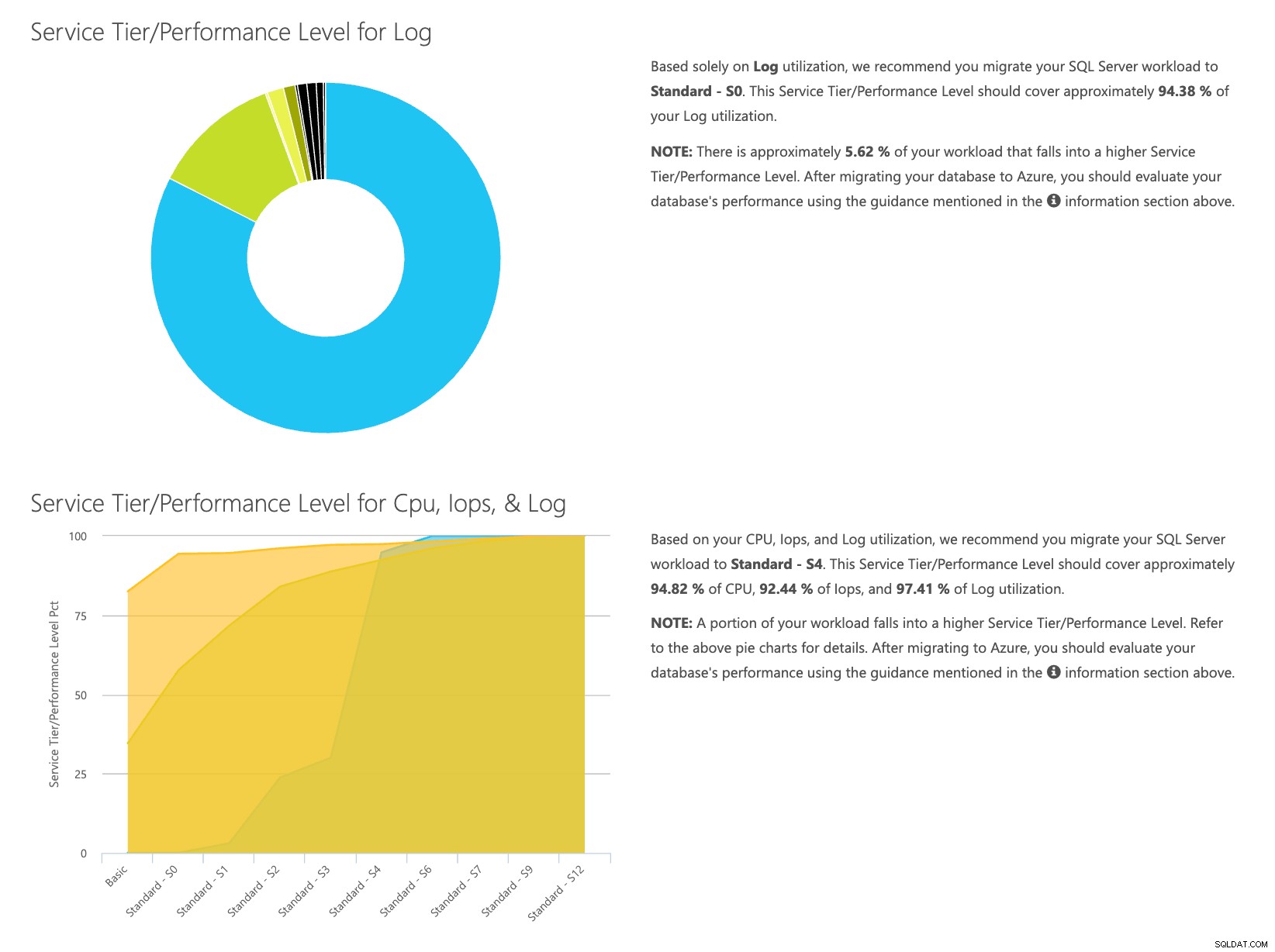
Da die Daten separat gespeichert werden, können Sie Workloads aus verschiedenen Zeiten analysieren, und Sie können dies tun, ohne das Befehlsdienstprogramm\Powershell-Skript für einen Server, den Sie bereits mit SentryOne überwachen, manuell ausführen/planen zu müssen.
Um die Schritte kurz zusammenzufassen, hier ist, was getan werden muss:
- Aktivieren Sie den Zähler [Database – Log Bytes Flush/sec] und überprüfen Sie, ob die Daten erfasst werden
- Kopieren Sie die Daten aus den SentryOne-Tabellen in Ihre eigene Tabelle (und planen Sie diese gegebenenfalls ein).
- Exportieren Sie die Daten aus der neuen Tabelle im richtigen Format für den DTU-Rechner
- Laden Sie die CSV-Datei in den DTU-Rechner hoch
Für alle Server/Instanzen, die Sie in die Cloud migrieren möchten und die Sie derzeit mit SQL Sentry überwachen, ist dies eine relativ unkomplizierte Methode, um abzuschätzen, welche Art von Dienstebene Sie benötigen und wie viel dies kosten wird. Sie müssen es jedoch immer noch überwachen, sobald es dort oben ist. Sehen Sie sich dazu SentryOne DB Sentry an.
Über den Autor
 Dustin Dorsey ist derzeit Managing Database Engineer für LifePoint Health, wo er ein Team leitet, das für die Verwaltung und Entwicklung von Lösungen verantwortlich ist in Datenbanktechnologien für 90 Krankenhäuser. Seit 2008 arbeitet er hauptsächlich im Gesundheitswesen mit und unterstützt SQL Server in den Bereichen Verwaltung, Architektur, Entwicklung und BI. Er ist leidenschaftlich daran interessiert, Wege zur Lösung von Problemen zu finden, die den DBA-Alltag plagen, und liebt es, dies mit anderen zu teilen. Man findet ihn als Redner bei Veranstaltungen der SQL-Community und als Blogger auf DustinDorsey.com.
Dustin Dorsey ist derzeit Managing Database Engineer für LifePoint Health, wo er ein Team leitet, das für die Verwaltung und Entwicklung von Lösungen verantwortlich ist in Datenbanktechnologien für 90 Krankenhäuser. Seit 2008 arbeitet er hauptsächlich im Gesundheitswesen mit und unterstützt SQL Server in den Bereichen Verwaltung, Architektur, Entwicklung und BI. Er ist leidenschaftlich daran interessiert, Wege zur Lösung von Problemen zu finden, die den DBA-Alltag plagen, und liebt es, dies mit anderen zu teilen. Man findet ihn als Redner bei Veranstaltungen der SQL-Community und als Blogger auf DustinDorsey.com.