Die Gruppierung ist eine wichtige Funktion, die beim Organisieren und Anordnen von Daten hilft. Es gibt viele Möglichkeiten, dies zu tun, und eine der effektivsten Methoden ist die SQL GROUP BY-Klausel.
Sie können SQL GROUP BY verwenden, um Zeilen in Ergebnissen mit einer Aggregatfunktion in Gruppen zu unterteilen . Es klingt einfach, Datensätze damit zu summieren, zu mitteln oder zu zählen.
Aber machst du es richtig?
„Richtig“ kann subjektiv sein. Wenn es ohne kritische Fehler mit einer korrekten Ausgabe läuft, gilt es als in Ordnung. Allerdings muss es auch schnell gehen.
In diesem Artikel wird auch die Geschwindigkeit berücksichtigt. Sie werden in allen Punkten viel Abfrageanalyse mit logischen Lesevorgängen und Ausführungsplänen sehen.
Fangen wir an.
1. Früh filtern
Wenn Sie sich nicht sicher sind, wann Sie WHERE und HAVING verwenden sollen, ist dies das Richtige für Sie. Denn je nach der von Ihnen angegebenen Bedingung können beide dasselbe Ergebnis liefern.
Aber sie sind anders.
HAVING filtert die Gruppen anhand der Spalten in der SQL GROUP BY-Klausel. WHERE filtert die Zeilen, bevor Gruppierungen und Aggregationen stattfinden. Wenn Sie also mit der HAVING-Klausel filtern, erfolgt die Gruppierung für alle zurückgegebene Zeilen.
Und das ist schlecht.
Wieso den? Die kurze Antwort lautet:Es ist langsam. Lassen Sie uns dies mit 2 Abfragen beweisen. Sehen Sie sich den Code unten an. Bevor Sie es in SQL Server Management Studio ausführen, drücken Sie zuerst Strg-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analyse
Die 2 obigen SELECT-Anweisungen geben dieselben Zeilen zurück. Beide geben im Jahr 2012 Produktbestellungen nach Monat zurück. Aber das erste SELECT dauerte 136 ms. um auf meinem Laptop zu laufen, während ein anderer 764ms brauchte.!
Warum?
Lassen Sie uns zuerst die logischen Lesevorgänge in Abbildung 1 überprüfen. Das STATISTICS IO hat diese Ergebnisse zurückgegeben. Dann habe ich es für die formatierte Ausgabe in StatisticsParser.com eingefügt.
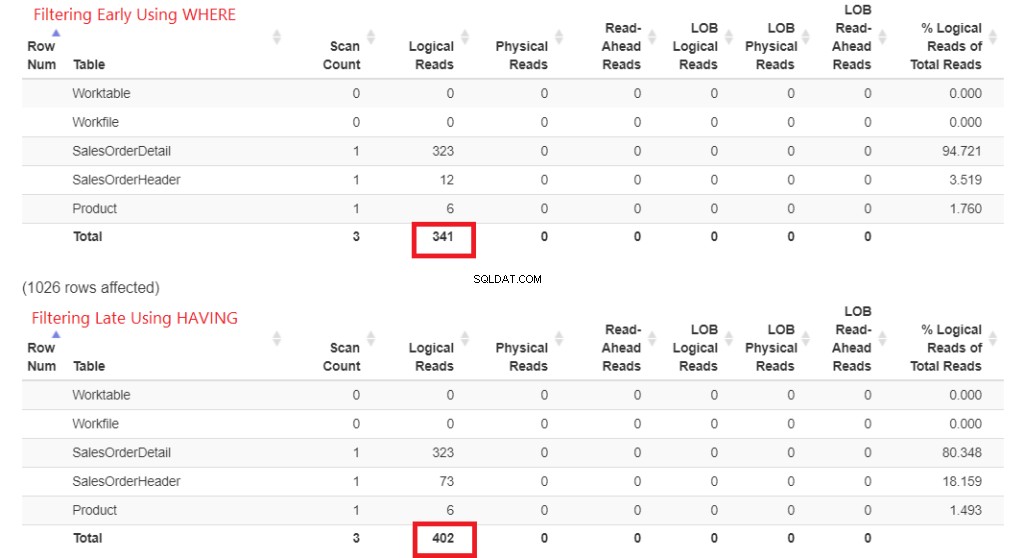
Abbildung 1 . Logische Lesevorgänge der frühen Filterung mit WHERE im Vergleich zur späten Filterung mit HAVING.
Sehen Sie sich die gesamten logischen Lesevorgänge von jedem an. Um diese Zahlen zu verstehen, ist die Abfrage umso langsamer, je mehr logische Lesevorgänge erforderlich sind. Es beweist also, dass die Verwendung von HAVING langsamer ist und eine frühe Filterung mit WHERE schneller ist.
Das bedeutet natürlich nicht, dass HABEN sinnlos ist. Eine Ausnahme ist die Verwendung von HAVING mit einem Aggregat wie HAVING SUM(sod.Linetotal)> 100000 . Sie können eine WHERE-Klausel und eine HAVING-Klausel in einer Abfrage kombinieren.
Siehe Ausführungsplan in Abbildung 2.
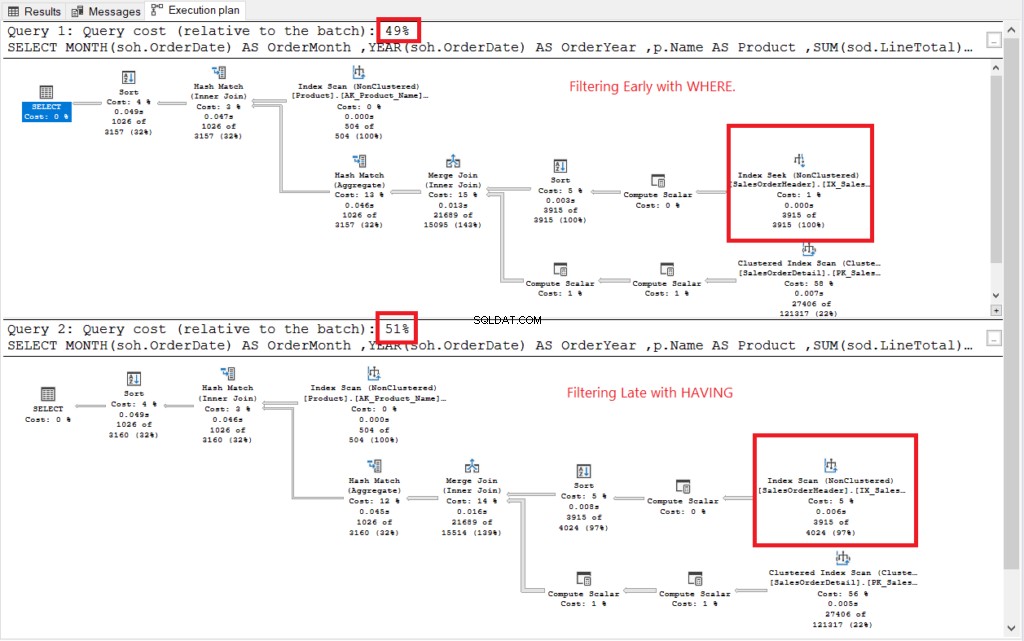
Abbildung 2 . Ausführungspläne für frühes Filtern vs. spätes Filtern.
Beide Hinrichtungspläne sahen ähnlich aus, mit Ausnahme der rot umrandeten. Beim Filtern wurde früh der Index Seek-Operator verwendet, während ein anderer Index Scan verwendete. Suchvorgänge sind in großen Tabellen schneller als Scans.
Nein Hinweis: Frühes Filtern kostet weniger als spätes Filtern. Unter dem Strich kann also das frühzeitige Filtern der Zeilen die Leistung verbessern.
2. Erst gruppieren, später beitreten
Das Verknüpfen einiger Tabellen, die Sie später benötigen, kann die Leistung ebenfalls verbessern.
Nehmen wir an, Sie möchten monatliche Produktverkäufe haben. Sie müssen auch den Produktnamen, die Nummer und die Unterkategorie in derselben Abfrage abrufen. Diese Spalten befinden sich in einer anderen Tabelle. Und sie alle müssen in der GROUP BY-Klausel hinzugefügt werden, um eine erfolgreiche Ausführung zu haben. Hier ist der Code.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Das wird gut laufen. Aber es gibt einen besseren und schnelleren Weg. Dadurch müssen Sie die 3 Spalten für Produktname, Nummer und Unterkategorie in der GROUP BY-Klausel nicht hinzufügen. Dies erfordert jedoch etwas mehr Tastenanschläge. Hier ist es.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analyse
Warum ist das schneller? Die Verknüpfungen zu Produkt und ProductSubcategory werden später erledigt. Beide sind nicht an der GROUP BY-Klausel beteiligt. Lassen Sie uns dies anhand von Zahlen in der STATISTIK IO beweisen. Siehe Abbildung 4.
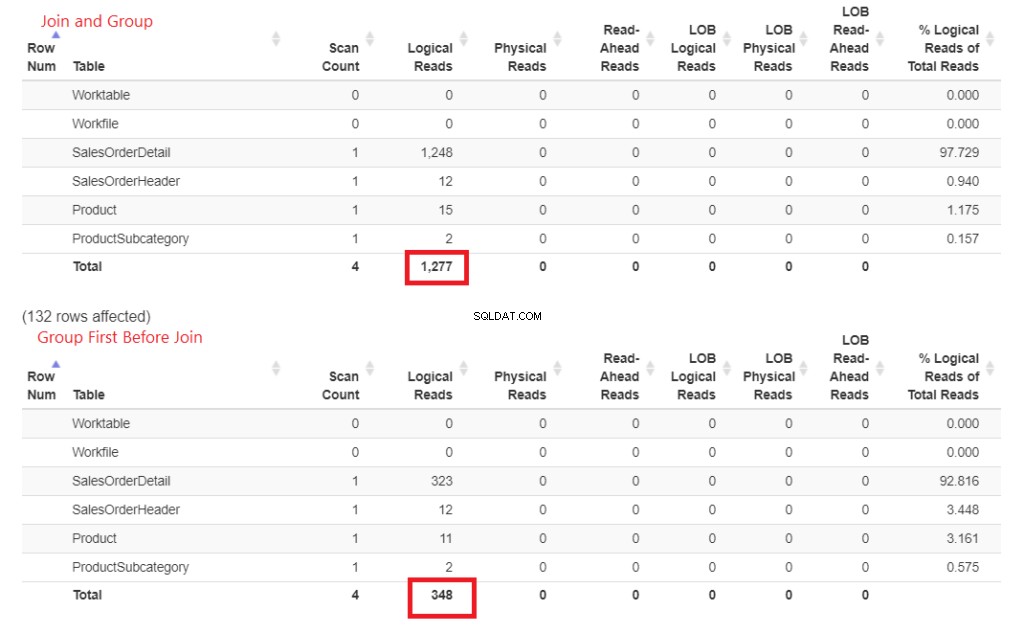
Abbildung 3 . Das frühe Beitreten und dann das Gruppieren verbrauchte mehr logische Lesevorgänge als das spätere Beitreten.
Sehen Sie diese logischen Lesevorgänge? Der Unterschied ist groß und der Gewinner ist offensichtlich.
Vergleichen wir den Ausführungsplan der beiden Abfragen, um den Grund für die obigen Zahlen zu sehen. Sehen Sie sich zunächst Abbildung 4 für den Ausführungsplan der Abfrage an, wobei alle Tabellen bei der Gruppierung zusammengeführt werden.
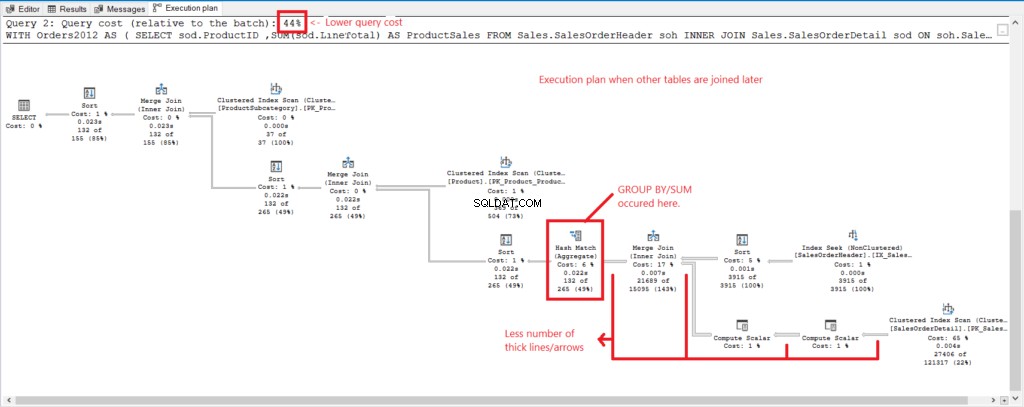
Abbildung 4 . Ausführungsplan, wenn alle Tabellen verbunden sind.
Und wir haben die folgenden Beobachtungen:
- GROUP BY und SUM wurden spät im Prozess durchgeführt, nachdem alle Tabellen zusammengeführt wurden.
- Viele dickere Linien und Pfeile – das erklärt die 1.277 logischen Lesevorgänge.
- Die beiden Abfragen zusammen machen 100 % der Abfragekosten aus. Der Plan dieser Abfrage hat jedoch höhere Abfragekosten (56 %).
Nun, hier ist ein Ausführungsplan, wenn wir uns zuerst gruppieren und dem Produkt beitreten und ProductSubcategory Tabellen später. Sehen Sie sich Abbildung 5 an.
Abbildung 5 . Ausführungsplan, wenn die Gruppe zuerst, später beitreten, fertig ist.
Und wir haben die folgenden Beobachtungen in Abbildung 5.
- GROUP BY und SUM wurden vorzeitig beendet.
- Weniger dicke Linien und Pfeile – dies erklärt nur die 348 logischen Lesevorgänge.
- Geringere Abfragekosten (44 %).
3. Gruppieren Sie eine indizierte Spalte
Immer wenn SQL GROUP BY für eine Spalte ausgeführt wird, sollte diese Spalte einen Index haben. Sie erhöhen die Ausführungsgeschwindigkeit, sobald Sie die Spalte mit einem Index gruppieren. Lassen Sie uns die vorherige Abfrage ändern und das Versanddatum anstelle des Bestelldatums verwenden. Die Spalte Versanddatum hat keinen Index in SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Drücken Sie Strg-M und führen Sie dann die obige Abfrage in SSMS aus. Erstellen Sie dann einen nicht geclusterten Index für das Versanddatum Säule. Beachten Sie die logischen Lesevorgänge und den Ausführungsplan. Führen Sie abschließend die obige Abfrage in einem anderen Abfragetab erneut aus. Beachten Sie die Unterschiede in logischen Lesevorgängen und Ausführungsplänen.
Hier ist der Vergleich der logischen Lesevorgänge in Abbildung 6.
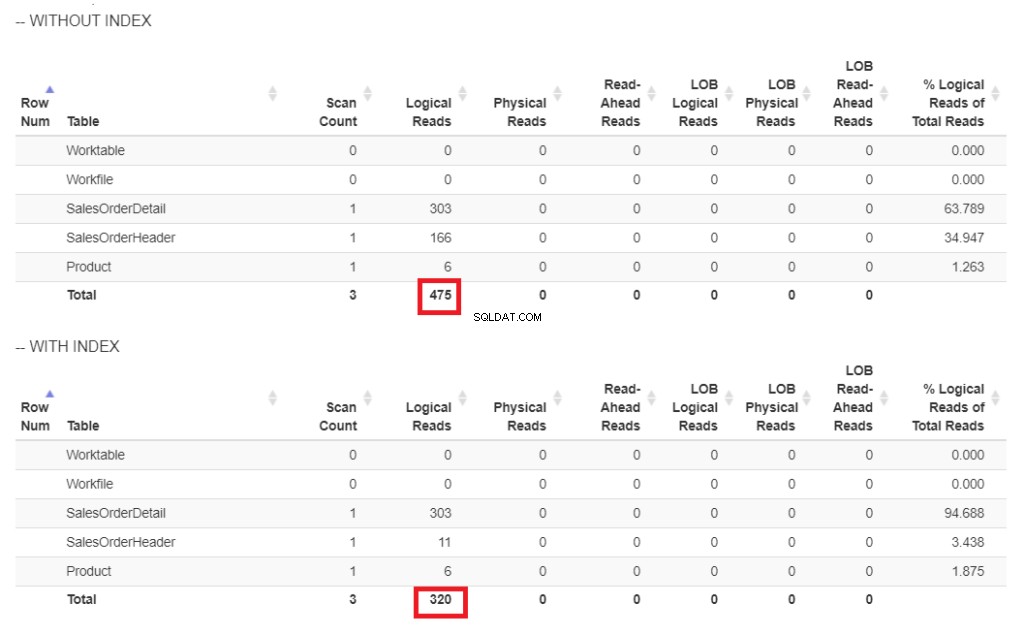
Abbildung 6 . Logische Lesevorgänge unseres Abfragebeispiels mit und ohne Index für ShipDate.
In Abbildung 6 gibt es höhere logische Lesevorgänge der Abfrage ohne einen Index für ShipDate .
Lassen Sie uns nun den Ausführungsplan haben, wenn kein Index für ShipDate vorliegt existiert in Abbildung 7.
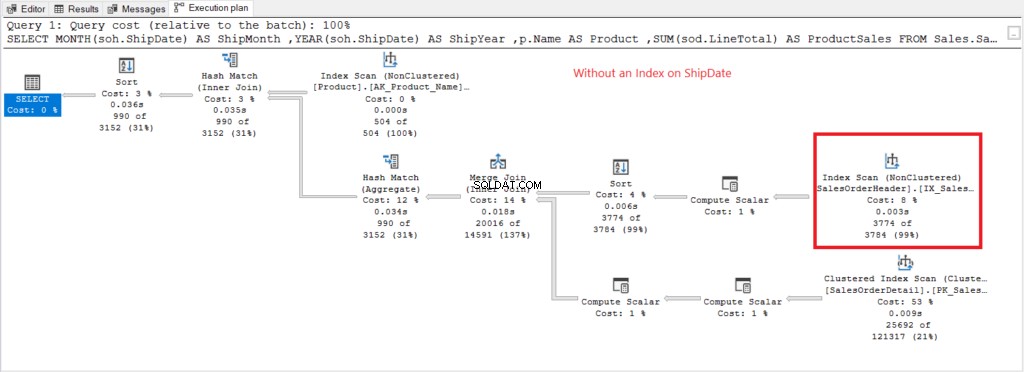
Abbildung 7 . Ausführungsplan bei Verwendung von GROUP BY auf ShipDate nicht indiziert.
Der Index-Scan Operator, der im Plan in Abbildung 7 verwendet wird, erklärt die höheren logischen Lesevorgänge (475). Hier ist ein Ausführungsplan nach der Indexierung des ShipDate Spalte.
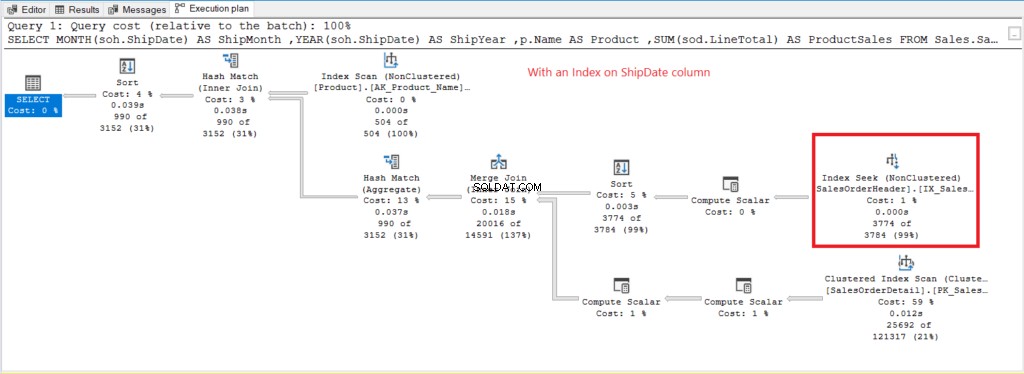
Abbildung 8 . Ausführungsplan bei Verwendung von GROUP BY auf Versanddatum indiziert.
Anstelle von Index Scan wird ein Index Seek verwendet, nachdem das ShipDate indexiert wurde Säule. Dies erklärt die unteren logischen Lesevorgänge in Abbildung 6.
Um die Leistung bei der Verwendung von GROUP BY zu verbessern, sollten Sie daher erwägen, die Spalten zu indizieren, die Sie zum Gruppieren verwendet haben.
Takeaways bei der Verwendung von SQL GROUP BY
SQL GROUP BY ist einfach zu verwenden. Aber Sie müssen den nächsten Schritt tun, um über das Zusammenfassen der Daten für Berichte hinauszugehen. Hier nochmal die Punkte:
- Frühzeitig filtern . Entfernen Sie die Zeilen, die Sie nicht zusammenfassen müssen, indem Sie die WHERE-Klausel anstelle der HAVING-Klausel verwenden.
- Gruppe zuerst, später beitreten . Manchmal gibt es Spalten, die Sie neben den gruppierten Spalten hinzufügen müssen. Anstatt sie in die GROUP BY-Klausel aufzunehmen, teilen Sie die Abfrage mit einem CTE und verbinden Sie später andere Tabellen.
- Verwenden Sie GROUP BY mit indizierten Spalten . Diese grundlegende Sache kann nützlich sein, wenn die Datenbank so schnell wie eine Schnecke ist.
Ich hoffe, dies hilft Ihnen, Ihr Spiel beim Gruppieren von Ergebnissen zu verbessern.
Wenn Ihnen dieser Beitrag gefällt, teilen Sie ihn bitte auf Ihren bevorzugten Social-Media-Plattformen.