[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]
Im ersten Teil dieser Serie haben wir gesehen, wie das Halloween-Problem auf UPDATE zutrifft Abfragen. Um es kurz zusammenzufassen:Das Problem bestand darin, dass die Schlüssel eines Index, der zum Suchen von zu aktualisierenden Datensätzen verwendet wurde, durch den Aktualisierungsvorgang selbst geändert wurden (ein weiterer guter Grund, enthaltene Spalten in einem Index zu verwenden, anstatt die Schlüssel zu erweitern). Der Abfrageoptimierer hat einen Eager Table Spool-Operator eingeführt, um die Lese- und Schreibseiten des Ausführungsplans zu trennen, um das Problem zu vermeiden. In diesem Beitrag werden wir sehen, wie sich dasselbe zugrunde liegende Problem auf INSERT auswirken kann und DELETE Aussagen.
Anweisungen einfügen
Jetzt wissen wir ein wenig über die Bedingungen, die einen Halloween-Schutz erfordern, es ist ganz einfach, einen INSERT zu erstellen Beispiel, bei dem aus den Schlüsseln derselben Indexstruktur gelesen und in sie geschrieben wird. Das einfachste Beispiel ist das Duplizieren von Zeilen in einer Tabelle (wobei das Hinzufügen neuer Zeilen zwangsläufig die Schlüssel des Clustered-Index ändert):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
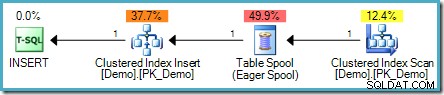
SELECT SomeKey FROM dbo.Demo; Das Problem besteht darin, dass neu eingefügte Zeilen möglicherweise von der Leseseite des Ausführungsplans gefunden werden, was möglicherweise zu einer Schleife führt, die Zeilen für immer hinzufügt (oder zumindest bis ein Ressourcenlimit erreicht ist). Der Abfrageoptimierer erkennt dieses Risiko und fügt einen Eager Table Spool hinzu, um die notwendige Phasentrennung bereitzustellen :
Ein realistischeres Beispiel
Sie schreiben wahrscheinlich nicht oft Abfragen, um jede Zeile in einer Tabelle zu duplizieren, aber Sie schreiben wahrscheinlich Abfragen, bei denen die Zieltabelle für ein INSERT ist taucht auch irgendwo im SELECT auf Klausel. Ein Beispiel ist das Hinzufügen von Zeilen aus einer Staging-Tabelle, die noch nicht im Ziel vorhanden sind:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Der Ausführungsplan ist:
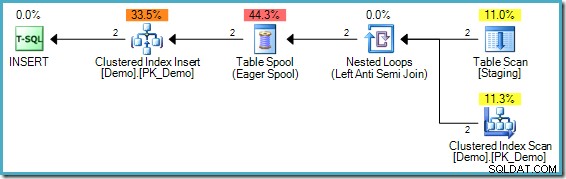
Das Problem in diesem Fall ist etwas anders, obwohl es immer noch ein Beispiel für das gleiche Kernproblem ist. Es gibt keinen Wert „1234“ in der Ziel-Demo-Tabelle, aber die Staging-Tabelle enthält zwei solcher Einträge. Ohne Phasentrennung würde der erste angetroffene „1234“-Wert erfolgreich eingefügt, aber die zweite Prüfung würde feststellen, dass der Wert „1234“ jetzt existiert, und würde nicht versuchen, ihn erneut einzufügen. Die Anweisung als Ganzes würde erfolgreich abgeschlossen werden.
Dies könnte in diesem speziellen Fall zu einem wünschenswerten Ergebnis führen (und sogar intuitiv richtig erscheinen), aber es ist keine korrekte Implementierung. Der SQL-Standard verlangt, dass Abfragen zur Datenänderung so ausgeführt werden, als ob die drei Phasen des Lesens, Schreibens und Prüfens von Constraints vollständig getrennt auftreten würden (siehe Teil 1).
Bei der Suche nach allen Zeilen, die in einem einzigen Vorgang eingefügt werden sollen, sollten wir beide Zeilen „1234“ aus der Staging-Tabelle auswählen, da dieser Wert noch nicht im Ziel vorhanden ist. Der Ausführungsplan sollte daher versuchen, beide einzufügen „1234“ Zeilen aus der Staging-Tabelle, was zu einer Verletzung des Primärschlüssels führt:
Nachricht 2627, Ebene 14, Status 1, Zeile 1Verletzung der PRIMARY KEY-Einschränkung 'PK_Demo'.
Kann keinen doppelten Schlüssel in Objekt 'dbo.Demo' einfügen.
Der doppelte Schlüsselwert ist ( 1234).
Die Anweisung wurde beendet.
Die durch den Tabellen-Spool bereitgestellte Phasentrennung stellt sicher, dass alle Existenzprüfungen abgeschlossen sind, bevor irgendwelche Änderungen an der Zieltabelle vorgenommen werden. Wenn Sie die Abfrage in SQL Server mit den obigen Beispieldaten ausführen, erhalten Sie die (korrekte) Fehlermeldung.
Halloween-Schutz ist für INSERT-Anweisungen erforderlich, bei denen die Zieltabelle auch in der SELECT-Klausel referenziert wird.
Anweisungen löschen
Wir könnten erwarten, dass das Halloween-Problem nicht auf DELETE zutrifft Anweisungen, da es eigentlich egal sein sollte, ob wir versuchen, eine Zeile mehrmals zu löschen. Wir können unser Staging-Tabellenbeispiel so ändern, dass es entfernt wird Zeilen aus der Demo-Tabelle, die in Staging nicht vorhanden sind:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Dieser Test scheint unsere Intuition zu bestätigen, da der Ausführungsplan keinen Tabellen-Spool enthält:
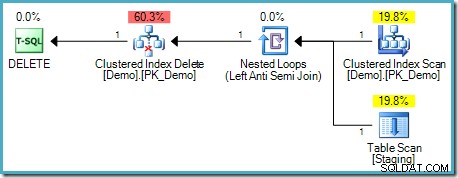
Diese Art von DELETE erfordert keine Phasentrennung, da jede Zeile eine eindeutige Kennung hat (eine RID, wenn die Tabelle ein Heap ist, gruppierte Indexschlüssel und ansonsten möglicherweise ein Uniquifier). Dieser eindeutige Zeilenlokator ist ein stabiler Schlüssel – es gibt keinen Mechanismus, durch den es sich während der Ausführung dieses Plans ändern kann, sodass das Halloween-Problem nicht auftritt.
Halloween-Schutz LÖSCHEN
Trotzdem gibt es mindestens einen Fall, in dem ein DELETE erfordert Halloween-Schutz:wenn der Plan auf eine andere Zeile in der Tabelle verweist als die, die gelöscht wird. Dies erfordert eine Selbstverknüpfung, die häufig vorkommt, wenn hierarchische Beziehungen modelliert werden. Ein vereinfachtes Beispiel ist unten dargestellt:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Es sollte hier wirklich eine Fremdschlüsselreferenz für dieselbe Tabelle definiert werden, aber lassen Sie uns für einen Moment ignorieren, dass das Design fehlschlägt – die Struktur und die Daten sind dennoch gültig (und es kommt leider ziemlich häufig vor, dass Fremdschlüssel in der realen Welt weggelassen werden). Wie auch immer, die vorliegende Aufgabe besteht darin, jede Zeile zu löschen, in der die ref Spalte zeigt auf ein nicht vorhandenes pk Wert. Das natürliche DELETE Abfrage, die dieser Anforderung entspricht, lautet:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); Der Abfrageplan ist:
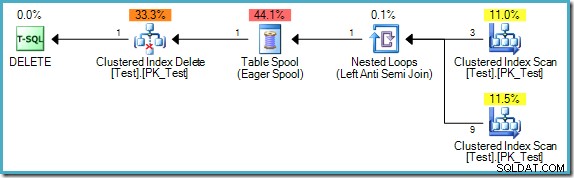
Beachten Sie, dass dieser Plan jetzt eine kostspielige Eager Table Spool enthält. Hier ist eine Phasentrennung erforderlich, da die Ergebnisse sonst von der Reihenfolge abhängen könnten, in der die Zeilen verarbeitet werden:
Wenn die Ausführungs-Engine mit der Zeile beginnt, in der pk =B, würde es keine passende Zeile finden (ref =A und es gibt keine Zeile mit pk =A). Wenn die Ausführung dann zu der Zeile weitergeht, in der pk =C, würde es auch gelöscht werden, weil wir gerade Zeile B entfernt haben, auf die durch ihre ref verwiesen wird Säule. Das Endergebnis wäre, dass die iterative Verarbeitung in dieser Reihenfolge alle Zeilen aus der Tabelle löschen würde, was eindeutig falsch ist.
Andererseits, wenn die Ausführungs-Engine die Zeile mit pk verarbeitet hat =D zuerst würde es eine passende Zeile finden (ref =C). Unter der Annahme, dass die Ausführung in umgekehrter Reihenfolge pk fortgesetzt wird Reihenfolge, die einzige Zeile, die aus der Tabelle gelöscht wird, wäre diejenige, in der pk =B. Dies ist das richtige Ergebnis (denken Sie daran, dass die Abfrage so ausgeführt werden sollte, als ob die Lese-, Schreib- und Validierungsphase nacheinander und ohne Überschneidungen erfolgt wäre).
Phasentrennung für Constraint-Validierung
Nebenbei können wir ein weiteres Beispiel für Phasentrennung sehen, wenn wir dem vorherigen Beispiel eine Fremdschlüssel-Einschränkung für dieselbe Tabelle hinzufügen:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Der Ausführungsplan für das INSERT ist:
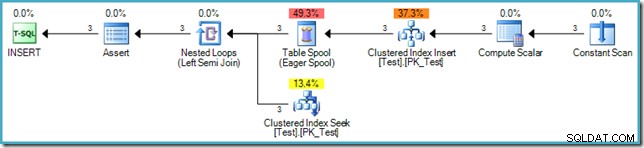
Die Einfügung selbst erfordert keinen Halloween-Schutz, da der Plan nicht aus derselben Tabelle liest (die Datenquelle ist eine virtuelle In-Memory-Tabelle, die durch den Constant Scan-Operator dargestellt wird). Der SQL-Standard verlangt jedoch, dass Phase 3 (Constraint-Prüfung) nach Abschluss der Schreibphase stattfindet. Aus diesem Grund wird dem Plan nach eine Phasentrennung Eager Table Spool hinzugefügt dem Clustered Index Index, und kurz bevor jede Zeile überprüft wird, um sicherzustellen, dass die Fremdschlüsseleinschränkung gültig bleibt.
Wenn Sie anfangen zu glauben, dass das Übersetzen einer mengenbasierten deklarativen SQL-Änderungsabfrage in einen robusten iterativen physischen Ausführungsplan eine schwierige Angelegenheit ist, beginnen Sie zu verstehen, warum die Aktualisierungsverarbeitung (von der Halloween-Schutz nur ein sehr kleiner Teil ist) dies ist komplexeste Teil des Abfrageprozessors.
DELETE-Anweisungen erfordern Halloween-Schutz, wenn ein Self-Join der Zieltabelle vorhanden ist.
Zusammenfassung
Halloween-Schutz kann eine teure (aber notwendige) Funktion in Ausführungsplänen sein, die Daten ändern (wobei „Ändern“ die gesamte SQL-Syntax umfasst, die Zeilen hinzufügt, ändert oder entfernt). Halloween-Schutz ist für UPDATE erforderlich Pläne, bei denen die Schlüssel einer gemeinsamen Indexstruktur sowohl gelesen als auch geändert werden, für INSERT Pläne, bei denen auf der Leseseite des Plans auf die Zieltabelle verwiesen wird, und für DELETE Pläne, bei denen ein Self-Join für die Zieltabelle durchgeführt wird.
Der nächste Teil dieser Serie behandelt einige spezielle Halloween-Problemoptimierungen, die nur für MERGE gelten Aussagen.
[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]