Dies ist der zweite Teil einer Serie über Lösungen für die Herausforderung des Zahlenreihengenerators. Letzten Monat habe ich Lösungen behandelt, die die Zeilen mithilfe eines Tabellenwertkonstruktors mit auf Konstanten basierenden Zeilen generieren. An diesen Lösungen waren keine E/A-Operationen beteiligt. In diesem Monat konzentriere ich mich auf Lösungen, die eine physische Basistabelle abfragen, die Sie vorab mit Zeilen füllen. Aus diesem Grund werde ich neben dem Zeitprofil der Lösungen, wie ich es letzten Monat getan habe, auch das I/O-Profil der neuen Lösungen melden. Nochmals vielen Dank an Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 und Ed Wagner für das Teilen Ihrer Ideen und Kommentare.
Bisher schnellste Lösung
Sehen wir uns als kurze Erinnerung zunächst die schnellste Lösung aus dem Artikel vom letzten Monat an, die als Inline-TVF namens dbo.GetNumsAlanCharlieItzikBatch implementiert ist.
Ich werde meine Tests in tempdb durchführen und IO- und TIME-Statistiken aktivieren:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Die schnellste Lösung aus dem letzten Monat wendet einen Join mit einer Dummy-Tabelle an, die über einen Columnstore-Index verfügt, um eine Stapelverarbeitung zu erhalten. Hier ist der Code zum Erstellen der Dummy-Tabelle:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Und hier ist der Code mit der Definition der Funktion dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Letzten Monat habe ich den folgenden Code verwendet, um die Leistung der Funktion mit 100 Millionen Zeilen zu testen, nachdem ich die Option „Ergebnisse nach Ausführung verwerfen“ in SSMS aktiviert hatte, um die Rückgabe der Ausgabezeilen zu unterdrücken:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =16031 ms, verstrichene Zeit =17172 ms.Joe Obbish bemerkte zu Recht, dass dieser Test möglicherweise einige reale Szenarien in dem Sinne nicht widerspiegelt, dass ein großer Teil der Laufzeit auf asynchrone Netzwerk-I/O-Wartezeiten (ASYNC_NETWORK_IO-Wartetyp) zurückzuführen ist. Sie können die höchsten Wartezeiten beobachten, indem Sie sich die Eigenschaftsseite des Stammknotens des tatsächlichen Abfrageplans ansehen oder eine Sitzung mit erweiterten Ereignissen mit Warteinformationen ausführen. Die Tatsache, dass Sie Ergebnisse nach der Ausführung in SSMS verwerfen aktivieren, hindert SQL Server nicht daran, die Ergebniszeilen an SSMS zu senden; es verhindert nur, dass SSMS sie druckt. Die Frage ist, wie wahrscheinlich es ist, dass Sie in realen Szenarien große Ergebnismengen an den Client zurückgeben, selbst wenn Sie die Funktion verwenden, um eine große Zahlenreihe zu erstellen. Vielleicht schreiben Sie die Abfrageergebnisse häufiger in eine Tabelle oder verwenden das Ergebnis der Funktion als Teil einer Abfrage, die schließlich eine kleine Ergebnismenge erzeugt. Sie müssen das herausfinden. Sie könnten die Ergebnismenge mit der Anweisung SELECT INTO in eine temporäre Tabelle schreiben, oder Sie könnten den Trick von Alan Burstein mit einer SELECT-Anweisung für die Zuweisung verwenden, die den Wert der Ergebnisspalte einer Variablen zuweist.
So ändern Sie den letzten Test, um die Variablenzuweisungsoption zu verwenden:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Zeitstatistiken, die ich für diesen Test erhalten habe:
CPU-Zeit =8641 ms, verstrichene Zeit =8645 ms.Dieses Mal enthält die Warteinformation keine asynchronen Netzwerk-E/A-Wartezeiten, und Sie können den erheblichen Rückgang der Laufzeit sehen.
Testen Sie die Funktion erneut und fügen Sie diesmal ordering hinzu:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Ich habe die folgenden Leistungsstatistiken für diese Ausführung:
CPU-Zeit =9360 ms, verstrichene Zeit =9551 ms.Denken Sie daran, dass für diese Abfrage kein Sortieroperator im Plan erforderlich ist, da die Spalte n auf einem Ausdruck basiert, der die Reihenfolge in Bezug auf die Spalte rownum beibehält. Das ist Charlis ständigem Falttrick zu verdanken, den ich letzten Monat behandelt habe. Die Pläne für beide Abfragen – die ohne Sortierung und die mit Sortierung – sind identisch, sodass die Leistung tendenziell ähnlich ist.
Abbildung 1 fasst die Leistungszahlen zusammen, die ich für die Lösungen des letzten Monats erhalten habe, nur dass diesmal die Variablenzuweisung in den Tests verwendet wurde, anstatt die Ergebnisse nach der Ausführung zu verwerfen.
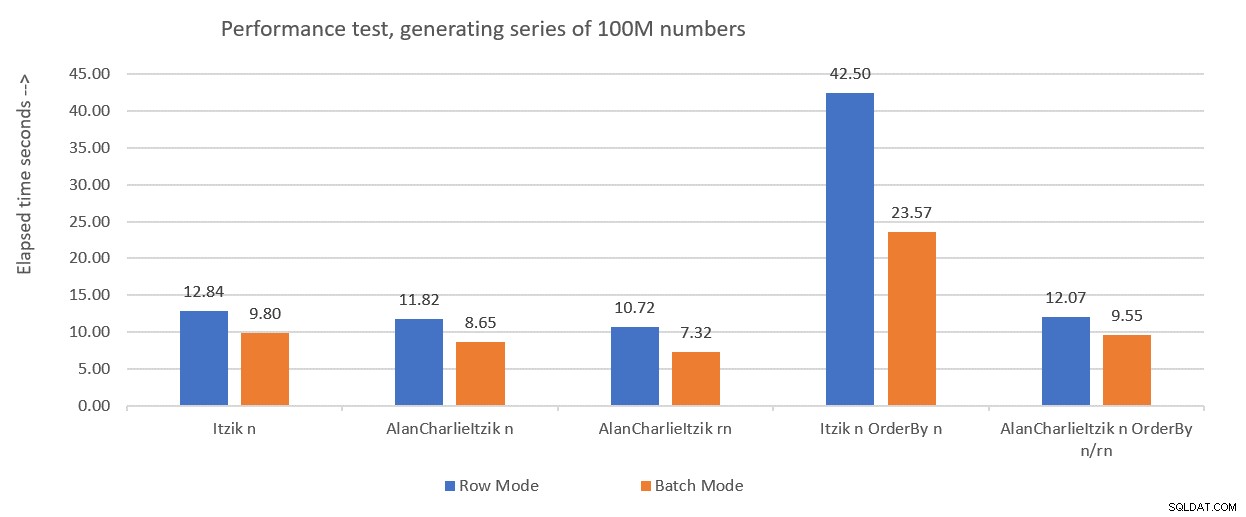 Abbildung 1:Bisherige Leistungsübersicht mit Variablenzuweisung
Abbildung 1:Bisherige Leistungsübersicht mit Variablenzuweisung
Ich werde die Variablenzuweisungstechnik verwenden, um die restlichen Lösungen zu testen, die ich in diesem Artikel vorstellen werde. Stellen Sie sicher, dass Sie Ihre Tests so anpassen, dass sie Ihre reale Situation am besten widerspiegeln, indem Sie Variablenzuweisungen, SELECT INTO verwenden, Ergebnisse nach Ausführung verwerfen oder andere Techniken verwenden.
Tipp zum Erzwingen von Serienplänen ohne MAXDOP 1
Bevor ich neue Lösungen vorstelle, wollte ich nur einen kleinen Tipp abdecken. Denken Sie daran, dass einige der Lösungen am besten funktionieren, wenn Sie einen seriellen Plan verwenden. Der offensichtliche Weg, dies zu erzwingen, ist mit einem MAXDOP 1-Abfragehinweis. Und das ist der richtige Weg, wenn Sie manchmal Parallelität aktivieren möchten und manchmal nicht. Was ist jedoch, wenn Sie bei der Verwendung der Funktion immer einen seriellen Plan erzwingen möchten, wenn auch ein weniger wahrscheinliches Szenario?
Es gibt einen Trick, um dies zu erreichen. Die Verwendung einer nicht inlineierbaren skalaren UDF in der Abfrage ist ein Parallelitätsverhinderer. Einer der skalaren UDF-Inlining-Inhibitoren ruft eine intrinsische Funktion auf, die zeitabhängig ist, wie z. B. SYSDATETIME. Hier ist also ein Beispiel für eine nicht inlineierbare skalare UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Eine andere Möglichkeit besteht darin, eine UDF mit nur einer Konstante als Rückgabewert zu definieren und die Option INLINE =OFF in ihrem Header zu verwenden. Diese Option ist jedoch erst ab SQL Server 2019 verfügbar, mit dem skalares UDF-Inlining eingeführt wurde. Mit der oben vorgeschlagenen Funktion können Sie es so erstellen, wie es mit älteren Versionen von SQL Server ist.
Ändern Sie als Nächstes die Definition der Funktion dbo.GetNumsAlanCharlieItzikBatch so, dass sie einen Dummy-Aufruf an dbo.MySYSDATETIME hat (definieren Sie eine darauf basierende Spalte, aber beziehen Sie sich nicht auf die Spalte in der zurückgegebenen Abfrage), etwa so:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Sie können den Leistungstest jetzt erneut ausführen, ohne MAXDOP 1 anzugeben, und trotzdem einen seriellen Plan erhalten:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Es ist jedoch wichtig zu betonen, dass jede Abfrage, die diese Funktion verwendet, jetzt einen seriellen Plan erhält. Wenn die Möglichkeit besteht, dass die Funktion in Abfragen verwendet wird, die von parallelen Plänen profitieren, verwenden Sie diesen Trick besser nicht, und wenn Sie einen seriellen Plan benötigen, verwenden Sie einfach MAXDOP 1.
Lösung von Joe Obbish
Joes Lösung ist ziemlich kreativ. Hier ist seine eigene Beschreibung der Lösung:
„Ich habe mich für die Erstellung eines gruppierten Columnstore-Index (CCI) mit 134.217.728 Zeilen sequenzieller Ganzzahlen entschieden. Die Funktion verweist bis zu 32 Mal auf die Tabelle, um alle Zeilen zu erhalten, die für die Ergebnismenge benötigt werden. Ich habe mich für ein CCI entschieden, weil die Daten gut komprimiert werden (weniger als 3 Bytes pro Zeile), Sie den Stapelmodus "kostenlos" erhalten und frühere Erfahrungen darauf hindeuten, dass das Lesen fortlaufender Nummern aus einem CCI schneller ist als das Generieren mit einer anderen Methode. ”Wie bereits erwähnt, bemerkte Joe auch, dass meine ursprünglichen Leistungstests aufgrund der asynchronen Netzwerk-E/A-Wartezeiten, die durch die Übertragung der Zeilen an SSMS generiert wurden, erheblich verzerrt waren. Alle Tests, die ich hier durchführe, werden Alans Idee mit der Variablenzuweisung verwenden. Stellen Sie sicher, dass Sie Ihre Tests so anpassen, dass sie Ihre reale Situation am ehesten widerspiegeln.
Hier ist der Code, den Joe verwendet hat, um die Tabelle dbo.GetNumsObbishTable zu erstellen und sie mit 134.217.728 Zeilen zu füllen:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Dieser Code hat auf meinem Computer 1:04 Minuten gedauert.
Sie können die Speicherplatznutzung dieser Tabelle überprüfen, indem Sie den folgenden Code ausführen:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Ich habe ungefähr 350 MB Speicherplatz verwendet. Im Vergleich zu den anderen Lösungen, die ich in diesem Artikel vorstelle, benötigt diese deutlich mehr Speicherplatz.
In der Columnstore-Architektur von SQL Server ist eine Zeilengruppe auf 2^20 =1.048.576 Zeilen begrenzt. Mit dem folgenden Code können Sie überprüfen, wie viele Zeilengruppen für diese Tabelle erstellt wurden:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Ich habe 128 Zeilengruppen.
Hier ist der Code mit der Definition der Funktion dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
Die 32 einzelnen Abfragen erzeugen die disjunkten 134.217.728-ganzzahligen Unterbereiche, die, wenn sie vereinheitlicht werden, den vollständigen ununterbrochenen Bereich von 1 bis 4.294.967.296 ergeben. Das wirklich Intelligente an dieser Lösung sind die WHERE-Filterprädikate, die die einzelnen Abfragen verwenden. Denken Sie daran, dass SQL Server bei der Verarbeitung eines Inline-TVF zunächst Parametereinbettung anwendet und die Parameter durch die Eingabekonstanten ersetzt. SQL Server kann dann die Abfragen optimieren, die Teilbereiche erzeugen, die sich nicht mit dem Eingabebereich überschneiden. Wenn Sie beispielsweise den Eingabebereich 1 bis 100.000.000 anfordern, ist nur die erste Abfrage relevant, und alle anderen werden optimiert. Der Plan enthält dann in diesem Fall einen Verweis auf nur eine Instanz der Tabelle. Das ist ziemlich genial!
Testen wir die Leistung der Funktion mit dem Bereich 1 bis 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Der Plan für diese Abfrage ist in Abbildung 2 dargestellt.
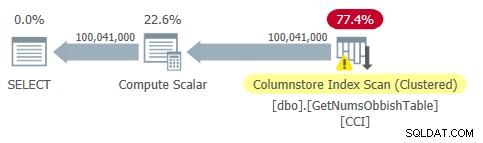 Abbildung 2:Plan für dbo.GetNumsObbish, 100 Millionen Zeilen, unsortiert
Abbildung 2:Plan für dbo.GetNumsObbish, 100 Millionen Zeilen, unsortiert
Beachten Sie, dass in diesem Plan tatsächlich nur ein Verweis auf die CCI der Tabelle benötigt wird.
Ich habe die folgenden Zeitstatistiken für diese Ausführung:
Das ist ziemlich beeindruckend und bei weitem schneller als alles andere, was ich getestet habe.
Hier sind die E/A-Statistiken, die ich für diese Ausführung erhalten habe:
Tabelle 'GetNumsObbishTable'. Scan-Anzahl 1, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Reads 0, Read-Ahead-Reads 0, Page-Server-Read-Ahead-Reads 0, logische Lob-Reads 32928 , Lob physisch liest 0, Lob Page Server liest 0, Lob Read-Ahead liest 0, Lob Page Server Read-Ahead liest 0.Tabelle 'GetNumsObbishTable'. Segment lautet 96 , Segment übersprungen 32.
Das E/A-Profil dieser Lösung ist einer der Nachteile im Vergleich zu den anderen, da für diese Ausführung über 30.000 logische Lob-Lesevorgänge erforderlich sind.
Um zu sehen, dass beim Überqueren mehrerer 134.217.728-ganzzahliger Unterbereiche der Plan mehrere Verweise auf die Tabelle beinhaltet, fragen Sie die Funktion mit dem Bereich 1 bis 400.000.000 ab, zum Beispiel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Der Plan für diese Ausführung ist in Abbildung 3 dargestellt.
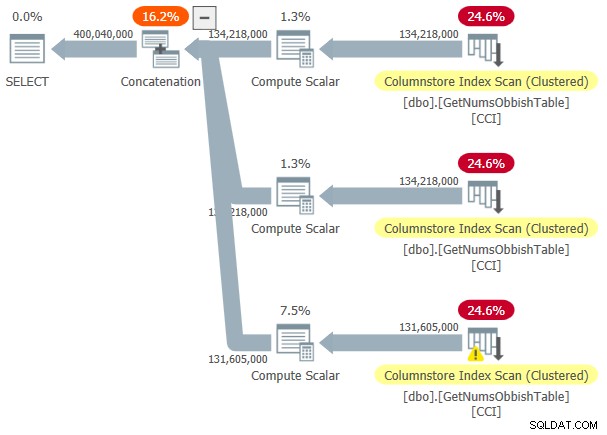 Abbildung 3:Plan für dbo.GetNumsObbish, 400 Millionen Zeilen, unsortiert
Abbildung 3:Plan für dbo.GetNumsObbish, 400 Millionen Zeilen, unsortiert
Der angeforderte Bereich hat drei 134.217.728-ganzzahlige Unterbereiche überschritten, daher zeigt der Plan drei Verweise auf den CCI der Tabelle.
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =20610 ms, verstrichene Zeit =20628 ms.Und hier sind die E/A-Statistiken:
Tabelle 'GetNumsObbishTable'. Scan-Anzahl 3, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Reads 0, Read-Ahead-Reads 0, Page-Server-Read-Ahead-Reads 0, logische Lob-Reads 131026 , Lob physisch liest 0, Lob Page Server liest 0, Lob Read-Ahead liest 0, Lob Page Server Read-Ahead liest 0.Tabelle 'GetNumsObbishTable'. Segment lautet 382 , Segment übersprungen 2.
Diesmal führte die Abfrageausführung zu über 130.000 logischen Lob-Lesevorgängen.
Wenn Sie die E/A-Kosten verkraften können und die Nummernserien nicht geordnet verarbeiten müssen, ist dies eine großartige Lösung. Wenn Sie die Reihen jedoch der Reihe nach verarbeiten müssen, führt diese Lösung zu einem Sort-Operator im Plan. Hier ist ein Test, der das bestellte Ergebnis anfordert:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Der Plan für diese Ausführung ist in Abbildung 4 dargestellt.
 Abbildung 4:Plan für dbo.GetNumsObbish, 100 Millionen Zeilen, geordnet
Abbildung 4:Plan für dbo.GetNumsObbish, 100 Millionen Zeilen, geordnet
Hier sind die Zeitstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU-Zeit =44516 ms, verstrichene Zeit =34836 ms.Wie Sie sehen können, verschlechterte sich die Leistung erheblich, da die Laufzeit aufgrund der expliziten Sortierung um eine Größenordnung zunahm.
Hier sind die E/A-Statistiken, die ich für diese Ausführung erhalten habe:
Tabelle 'GetNumsObbishTable'. Scan-Anzahl 4, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Reads 0, Read-Ahead-Reads 0, Page-Server-Read-Ahead-Reads 0, logische Lob-Reads 32928 , Lob physisch liest 0, Lob Page Server liest 0, Lob Read-Ahead liest 0, Lob Page Server Read-Ahead liest 0.Tabelle 'GetNumsObbishTable'. Segment lautet 96 , Segment übersprungen 32.
Tabelle 'Arbeitstisch'. Scan-Anzahl 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Lesungen 0, Read-Ahead-Lesungen 0, Page-Server-Read-Ahead-Lesungen 0, logische Lob-Lesevorgänge 0, Lob-physische Lesevorgänge 0, Lob-Page-Server-Lesungen 0, Lob-Read- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Beachten Sie, dass in der Ausgabe von STATISTICS IO eine Arbeitstabelle angezeigt wurde. Das liegt daran, dass eine Sortierung möglicherweise in tempdb übergreifen kann, in diesem Fall würde sie eine Arbeitstabelle verwenden. Diese Ausführung ist nicht übergelaufen, daher sind die Zahlen in diesem Eintrag alle Nullen.
Lösung von John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 hat eine Lösung gepostet, die in ihrer Einfachheit einfach schön ist. Außerdem enthält es Ideen und Vorschläge aus den anderen Lösungen von Dave, Joe, Alan, Charlie und mir.
Wie bei Joes Lösung entschied sich John für die Verwendung eines CCI, um ein hohes Maß an Komprimierung und „kostenlose“ Stapelverarbeitung zu erhalten. Nur John beschloss, die Tabelle mit 4B-Zeilen mit einer Dummy-NULL-Markierung in einer Bitspalte zu füllen und die ROW_NUMBER-Funktion die Zahlen generieren zu lassen. Da die gespeicherten Werte alle gleich sind, benötigen Sie bei der Komprimierung sich wiederholender Werte deutlich weniger Platz, was zu deutlich weniger I/Os im Vergleich zu Joes Lösung führt. Die Columnstore-Komprimierung verarbeitet sich wiederholende Werte sehr gut, da sie jeden solchen aufeinanderfolgenden Abschnitt innerhalb des Spaltensegments einer Zeilengruppe nur einmal darstellen kann, zusammen mit der Anzahl der sich aufeinanderfolgend wiederholenden Vorkommen. Da alle Zeilen denselben Wert (die NULL-Markierung) haben, benötigen Sie theoretisch nur ein Vorkommen pro Zeilengruppe. Bei 4B Zeilen sollten Sie am Ende 4.096 Zeilengruppen haben. Jeder sollte ein einzelnes Spaltensegment haben, mit sehr geringem Platzbedarf.
Hier ist der Code zum Erstellen und Füllen der Tabelle, implementiert als CCI mit Archivierungskomprimierung:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Der Hauptnachteil dieser Lösung ist die Zeit, die benötigt wird, um diese Tabelle zu füllen. Es dauerte 12:32 Minuten, bis dieser Code auf meinem Computer abgeschlossen war, wenn Parallelität zugelassen wurde, und 15:17 Minuten, wenn ein serieller Plan erzwungen wurde.
Beachten Sie, dass Sie an der Optimierung der Datenlast arbeiten könnten. Beispielsweise hat John eine Lösung getestet, die die Zeilen mit 32 gleichzeitigen Verbindungen mit OSTRESS.EXE geladen hat, wobei jede 128 Einfügungsrunden von 2^20 Zeilen (maximale Zeilengruppengröße) ausführte. Diese Lösung reduzierte Johns Ladezeit auf ein Drittel. Hier ist der Code, den John verwendet hat:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"WITH L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (A.b FROM L0 ALS CROSS JOIN L0 AS B WÄHLEN), L2 AS (A.b FROM L1 ALS CROSS JOIN L1 AS B WÄHLEN), nulls(b) AS (A.b FROM L2 AS A WÄHLEN CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Trotzdem ist die Ladezeit in Minuten. Die gute Nachricht ist, dass Sie diesen Datenladevorgang nur einmal durchführen müssen.
Die gute Nachricht ist der geringe Platzbedarf des Tisches. Verwenden Sie den folgenden Code, um die Speicherplatznutzung zu überprüfen:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Ich habe 1,64 MB. Das ist erstaunlich, wenn man bedenkt, dass die Tabelle 4B Zeilen hat!
Verwenden Sie den folgenden Code, um zu überprüfen, wie viele Zeilengruppen erstellt wurden:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Wie erwartet beträgt die Anzahl der Zeilengruppen 4.096.
Die Funktionsdefinition dbo.GetNumsJohn2DaveObbishAlanCharlieItzik wird dann ziemlich einfach:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Wie Sie sehen können, verwendet eine einfache Abfrage für die Tabelle die ROW_NUMBER-Funktion, um die Basiszeilennummern (rownum-Spalte) zu berechnen, und dann verwendet die äußere Abfrage dieselben Ausdrücke wie in dbo.GetNumsAlanCharlieItzikBatch, um rn, op und n zu berechnen. Auch hier bewahren sowohl rn als auch n die Reihenfolge in Bezug auf rownum.
Testen wir die Leistung der Funktion:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Ich habe den in Abbildung 5 gezeigten Plan für diese Ausführung erhalten.
 Abbildung 5:Plan für dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Abbildung 5:Plan für dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Hier sind die Zeitstatistiken, die ich für diesen Test erhalten habe:
CPU-Zeit =7593 ms, verstrichene Zeit =7590 ms.
Wie Sie sehen können, ist die Ausführungszeit nicht so schnell wie bei Joes Lösung, aber immer noch schneller als bei allen anderen Lösungen, die ich getestet habe.
Hier sind die E/A-Statistiken, die ich für diesen Test erhalten habe:
Tabelle 'NullBits4B'. Segment lautet 96 , Segment übersprungen 0
Beachten Sie, dass die I/O-Anforderungen deutlich geringer sind als bei Joes Lösung.
Das andere Tolle an dieser Lösung ist, dass Sie keine zusätzlichen Kosten zahlen, wenn Sie die bestellten Nummernserien verarbeiten müssen. Das liegt daran, dass dies nicht zu einer expliziten Sortieroperation im Plan führt, unabhängig davon, ob Sie das Ergebnis nach rn oder n sortieren.
Hier ist ein Test, um dies zu demonstrieren:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Sie erhalten denselben Plan wie zuvor in Abbildung 5 gezeigt.
Hier sind die Zeitstatistiken, die ich für diesen Test erhalten habe;
CPU-Zeit =7578 ms, verstrichene Zeit =7582 ms.Und hier sind die E/A-Statistiken:
Tabelle 'NullBits4B'. Scan-Anzahl 1, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Reads 0, Read-Ahead-Reads 0, Page-Server-Read-Ahead-Reads 0, logische Lob-Reads 194 , Lob physisch liest 0, Lob Page Server liest 0, Lob Read-Ahead liest 0, Lob Page Server Read-Ahead liest 0.Tabelle 'NullBits4B'. Segment lautet 96 , Segment übersprungen 0.
Sie sind im Grunde die gleichen wie im Test ohne die Reihenfolge.
Lösung 2 von John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
Johns Lösung ist schnell und einfach. Das ist fantastisch. Einziges Manko ist die Ladezeit. Manchmal ist dies kein Problem, da das Laden nur einmal erfolgt. Aber wenn es ein Problem ist, könnten Sie die Tabelle mit 102.400 Zeilen statt mit 4B Zeilen füllen und einen Kreuzjoin zwischen zwei Instanzen der Tabelle und einem TOP-Filter verwenden, um das gewünschte Maximum von 4B Zeilen zu generieren. Beachten Sie, dass es ausreichen würde, die Tabelle mit 65.536 Zeilen zu füllen und dann einen Cross Join anzuwenden, um 4B Zeilen zu erhalten; Damit die Daten jedoch sofort komprimiert werden und nicht in einen Rowstore-basierten Deltaspeicher geladen werden, müssen Sie die Tabelle mit mindestens 102.400 Zeilen laden.
Hier ist der Code zum Erstellen und Füllen der Tabelle:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Die Ladezeit ist vernachlässigbar – 43 ms auf meinem Rechner.
Überprüfen Sie die Größe der Tabelle auf der Festplatte:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Ich habe 56 KB Speicherplatz für die Daten benötigt.
Überprüfen Sie die Anzahl der Zeilengruppen, ihren Zustand (komprimiert oder offen) und ihre Größe:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Ich habe die folgende Ausgabe:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Hier wird nur eine Zeilengruppe benötigt; es ist komprimiert und hat eine vernachlässigbare Größe von 293 Bytes.
Wenn Sie die Tabelle mit einer Zeile weniger (102.399) füllen, erhalten Sie einen Rowstore-basierten unkomprimierten offenen Deltaspeicher. In einem solchen Fall meldet sp_spaceused eine Datengröße auf der Festplatte von über 1 MB und sys.column_store_row_groups meldet die folgenden Informationen:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Stellen Sie also sicher, dass Sie die Tabelle mit 102.400 Zeilen füllen!
Hier ist die Definition der Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
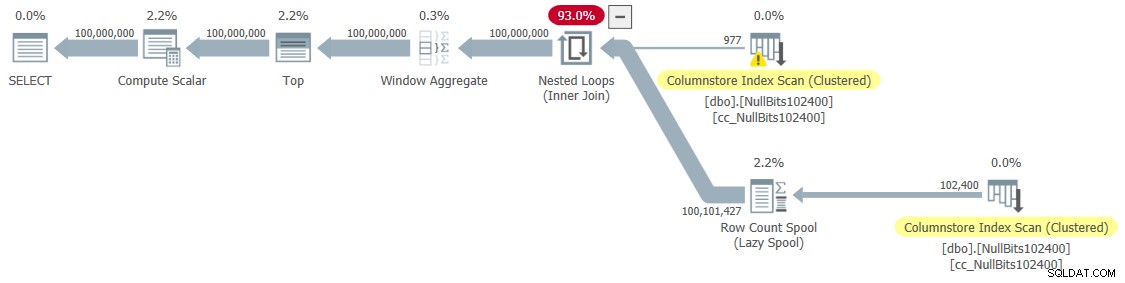 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
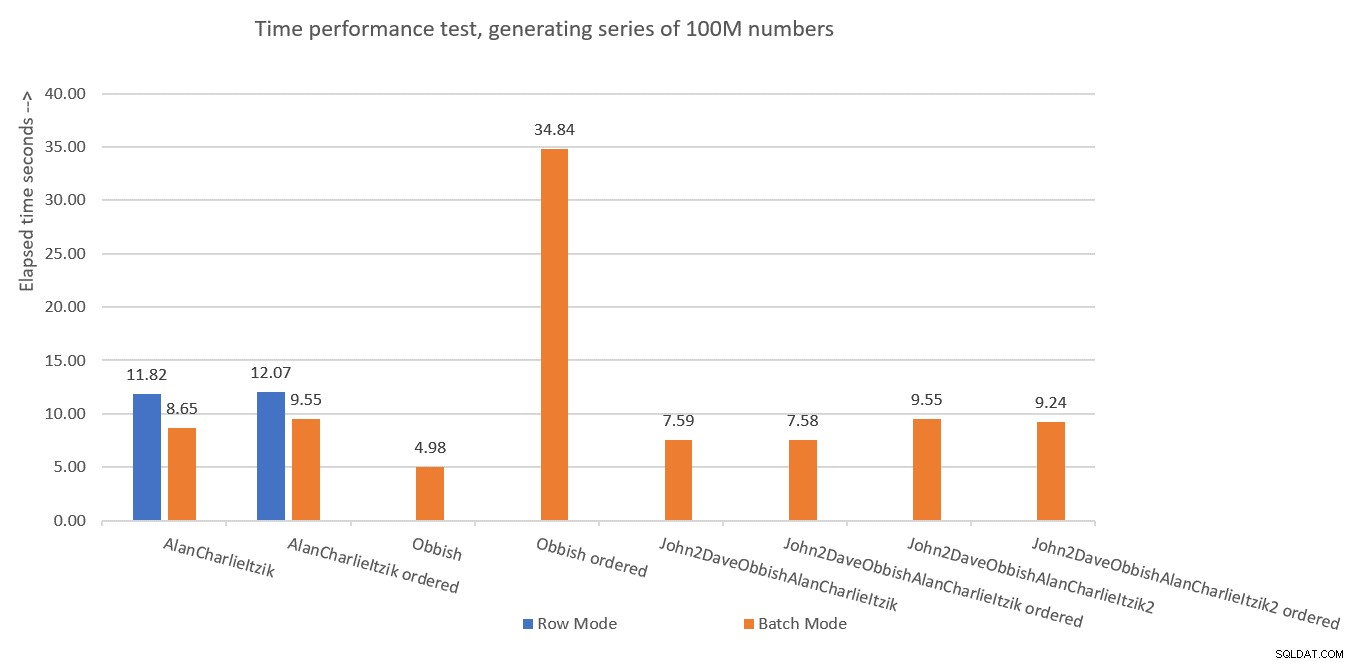 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
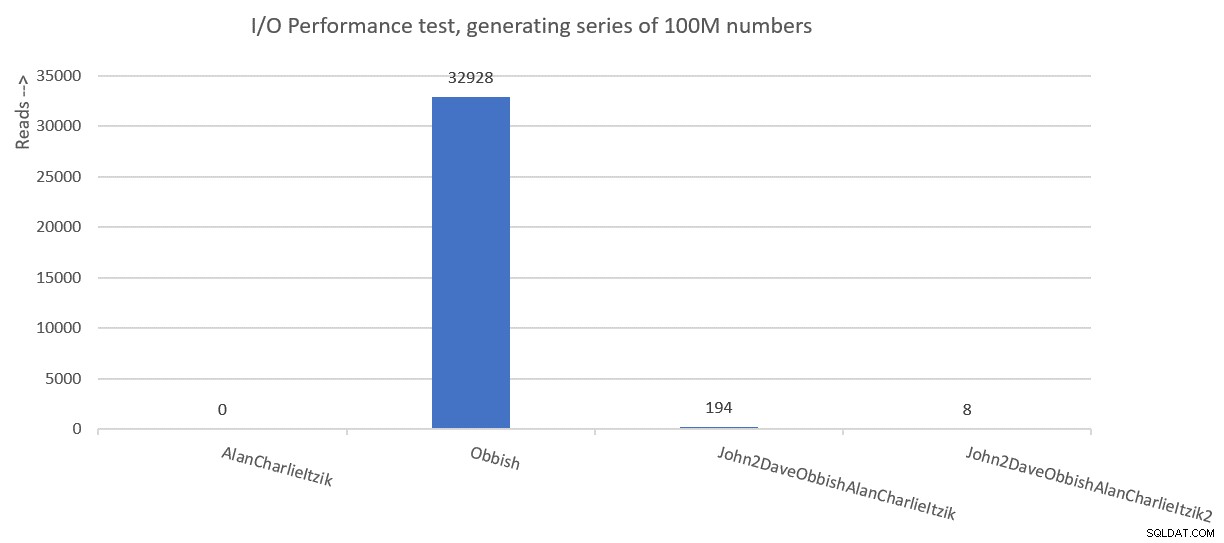 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.