Wir sind alle verwöhnt von der Fähigkeit der Suchmaschinen, Dinge wie Rechtschreibfehler, Unterschiede in der Schreibweise von Namen oder andere Situationen zu „umgehen“, in denen der Suchbegriff auf Seiten passt, deren Autoren möglicherweise eine andere Schreibweise eines Wortes bevorzugen. Das Hinzufügen solcher Funktionen zu unseren eigenen datenbankgesteuerten Anwendungen kann unsere Anwendungen in ähnlicher Weise bereichern und verbessern, und obwohl kommerzielle Angebote für relationale Datenbankverwaltungssysteme (RDBMS) ihre eigenen, vollständig entwickelten, kundenspezifischen Lösungen für dieses Problem bieten, können die Lizenzkosten dieser Tools niedrig sein Reichweite für kleinere Entwickler oder kleine Softwareentwicklungsfirmen.
Man könnte argumentieren, dass dies stattdessen mit einer Rechtschreibprüfung erfolgen könnte. Eine Rechtschreibprüfung ist jedoch normalerweise nutzlos, wenn eine korrekte, aber alternative Schreibweise eines Namens oder eines anderen Worts gefunden werden soll. Matching by Sound füllt diese funktionale Lücke. Das ist das Thema des heutigen Programmier-Tutorials:wie man Sounds mit Python mit Metaphones abfragt.
Was ist Soundex?
Soundex wurde im frühen 20. Jahrhundert entwickelt, um bei der US-Volkszählung Namen anhand ihres Klangs abzugleichen. Es wurde dann von verschiedenen Telefongesellschaften verwendet, um Kundennamen abzugleichen. Es wird bis heute für den phonetischen Datenabgleich verwendet, obwohl es auf die Schreibweise und Aussprache des amerikanischen Englisch beschränkt ist. Es ist auch auf englische Buchstaben beschränkt. Die meisten RDBMS, wie SQL Server und Oracle, implementieren zusammen mit MySQL und seinen Varianten eine Soundex-Funktion, und trotz ihrer Einschränkungen wird sie weiterhin verwendet, um viele nicht-englische Wörter zu finden.
Was ist ein Doppelmetaphon?
Das Metaphon Der Algorithmus wurde 1990 entwickelt und überwindet einige der Einschränkungen von Soundex. Im Jahr 2000 ein verbesserter Nachfolger, Double Metaphone , wurde entwickelt. Double Metaphone gibt einen primären und einen sekundären Wert zurück, die zwei Arten entsprechen, wie ein einzelnes Wort ausgesprochen werden könnte. Bis heute ist dieser Algorithmus einer der besseren phonetischen Open-Source-Algorithmen. Metaphone 3 wurde 2009 als Verbesserung von Double Metaphone veröffentlicht, aber dies ist ein kommerzielles Produkt.
Leider implementieren viele der oben erwähnten prominenten RDBMS kein Double Metaphone, und die meisten Bekannte Skriptsprachen bieten keine unterstützte Implementierung von Double Metaphone. Python bietet jedoch ein Modul, das Double Metaphone implementiert.
Die in diesem Python-Programmier-Tutorial vorgestellten Beispiele verwenden MariaDB Version 10.5.12 und Python 3.9.2, die beide unter Kali/Debian Linux ausgeführt werden.
Wie man Double Metaphone zu Python hinzufügt
Wie jedes Python-Modul kann das Pip-Tool verwendet werden, um Double Metaphone zu installieren. Die Syntax hängt von Ihrer Python-Installation ab. Eine typische Installation von Double Metaphone sieht wie im folgenden Beispiel aus:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Beachten Sie, dass die zusätzliche Großschreibung beabsichtigt ist. Der folgende Code ist ein Beispiel für die Verwendung von Double Metaphone in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Das obige Python-Skript gibt die folgende Ausgabe aus, wenn es in Ihrer integrierten Entwicklungsumgebung (IDE) oder Ihrem Code-Editor ausgeführt wird:
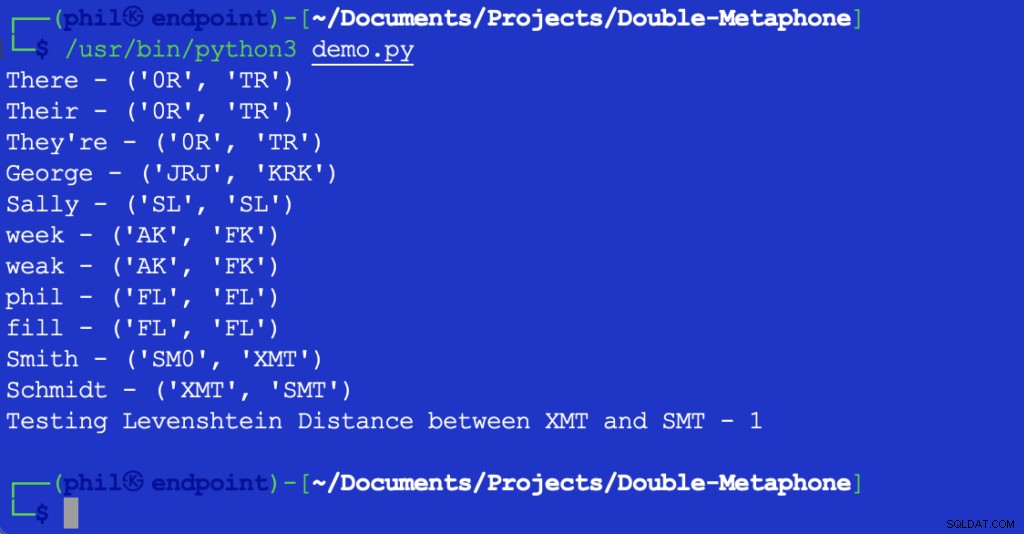
Abbildung 1 – Ausgabe des Demoskripts
Wie hier zu sehen ist, hat jedes Wort sowohl einen primären als auch einen sekundären phonetischen Wert. Wörter, die sowohl bei primären als auch bei sekundären Werten übereinstimmen, werden als phonetische Übereinstimmungen bezeichnet. Wörter, die mindestens einen phonetischen Wert oder die ersten paar Zeichen eines phonetischen Werts gemeinsam haben, werden als phonetisch nahe beieinander bezeichnet.
Die meisten Die angezeigten Buchstaben entsprechen ihrer englischen Aussprache. X kann KS entsprechen , SH , oder C . 0 entspricht dem ten Ton in dem oder dort . Vokale werden nur am Anfang eines Wortes abgeglichen. Aufgrund der unzähligen Unterschiede in den regionalen Akzenten ist es nicht möglich zu sagen, dass Wörter eine objektiv exakte Übereinstimmung sein können, selbst wenn sie die gleichen phonetischen Werte haben.
Phonetische Werte mit Python vergleichen
Es gibt zahlreiche Online-Ressourcen, die die vollständige Funktionsweise des Double Metaphone-Algorithmus beschreiben können. Dies ist jedoch nicht erforderlich, um es zu verwenden, da wir mehr am Vergleichen interessiert sind die berechneten Werte, mehr als wir daran interessiert sind, die Werte zu berechnen. Wie bereits erwähnt, kann man sagen, dass es sich bei diesen Werten um phonetische Übereinstimmungen handelt, wenn es zwischen zwei Wörtern mindestens einen gemeinsamen Wert gibt , und phonetische Werte, die ähnlich sind sind phonetisch nah .
Absolutwerte zu vergleichen ist einfach, aber wie kann man feststellen, dass Zeichenketten ähnlich sind? Obwohl es keine technischen Einschränkungen gibt, die Sie davon abhalten, Zeichenfolgen mit mehreren Wörtern zu vergleichen, sind diese Vergleiche normalerweise unzuverlässig. Bleiben Sie beim Vergleich einzelner Wörter.
Was sind Levenshtein-Distanzen?
Die Levenshtein-Distanz zwischen zwei Zeichenfolgen ist die Anzahl der einzelnen Zeichen, die in einer Zeichenfolge geändert werden müssen, damit sie mit der zweiten Zeichenfolge übereinstimmt. Ein Saitenpaar mit einem geringeren Levenshtein-Abstand ist einander ähnlicher als ein Saitenpaar mit einem höheren Levenshtein-Abstand. Die Levenshtein-Distanz ähnelt der Hamming-Distanz , letzteres ist aber auf gleich lange Zeichenketten beschränkt, da die phonetischen Werte der Doppelmetaphone unterschiedlich lang sein können, ist es sinnvoller, diese mit der Levenshtein-Distanz zu vergleichen.
Python Levenshtein Distance Library
Python kann erweitert werden, um Levenshtein-Entfernungsberechnungen über ein Python-Modul zu unterstützen:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Beachten Sie das wie bei der Installation des DoubleMetaphone oben die Syntax des Aufrufs von pip variieren. Das Python-Levenshtein-Modul bietet weit mehr Funktionalität als nur die Berechnung der Levenshtein-Distanz.
Der folgende Code zeigt einen Test für die Berechnung der Levenshtein-Distanz in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Die Ausführung dieses Skripts ergibt die folgende Ausgabe:
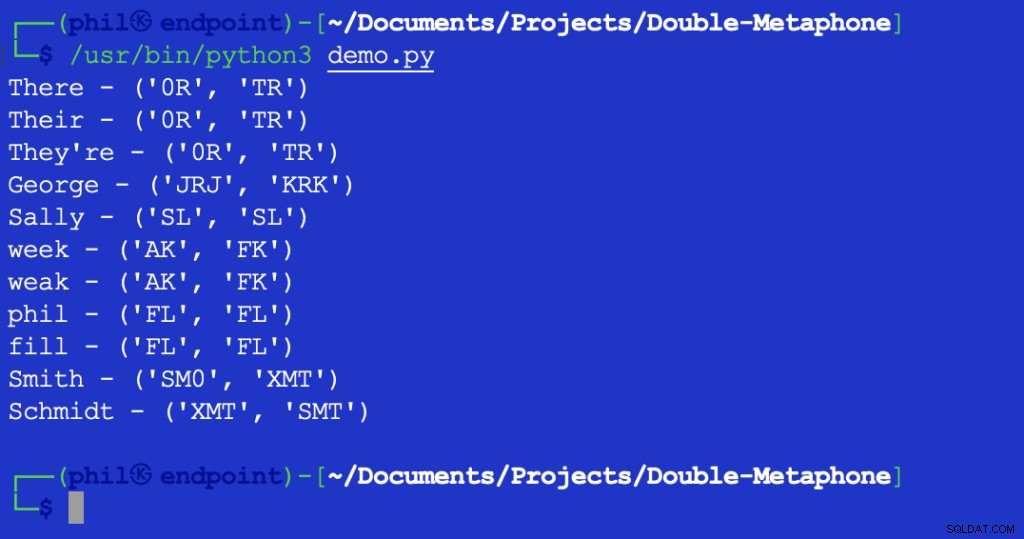
Abbildung 2 – Ergebnis des Levenshtein-Distanztests
Der zurückgegebene Wert von 1 gibt an, dass zwischen XMT ein Zeichen steht und SMT das ist anders. In diesem Fall ist es das erste Zeichen in beiden Zeichenfolgen.
Doppelte Metaphone in Python vergleichen
Was folgt, ist nicht das A und O der phonetischen Vergleiche. Es ist einfach eine von vielen Möglichkeiten, einen solchen Vergleich durchzuführen. Um die phonetische Nähe beliebiger zwei gegebener Zeichenfolgen effektiv zu vergleichen, muss jeder phonetische Doppelmetaphonwert einer Zeichenfolge mit dem entsprechenden phonetischen Doppelmetaphonwert einer anderen Zeichenfolge verglichen werden. Da beide phonetischen Werte einer gegebenen Zeichenfolge gleich gewichtet werden, ergibt der Durchschnitt dieser Vergleichswerte eine ziemlich gute Annäherung an die phonetische Nähe:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Wo:
- DM1(1) :Erster doppelter Metaphonwert von String 1,
- DM1(2) :Zweiter doppelter Metaphonwert von String 1
- DM2(1) :Erster doppelter Metaphonwert von String 2
- DM2(2) :Zweiter doppelter Metaphonwert von String 2
- PN :Phonetische Nähe, wobei niedrigere Werte näher sind als höhere Werte. Ein Nullwert zeigt phonetische Ähnlichkeit an. Der höchste Wert dafür ist die Anzahl der Buchstaben in der kürzesten Zeichenfolge.
Diese Formel versagt in Fällen wie Schmidt (XMT, SMT) und Smith (SM0, XMT) wobei der erste phonetische Wert der ersten Zeichenfolge mit dem zweiten phonetischen Wert der zweiten Zeichenfolge übereinstimmt. In solchen Situationen sind sowohl Schmidt und Smith können aufgrund des gemeinsamen Wertes als phonetisch ähnlich angesehen werden. Der Code für die Nähefunktion sollte die obige Formel nur dann anwenden, wenn alle vier phonetischen Werte unterschiedlich sind. Auch beim Vergleich unterschiedlich langer Strings weist die Formel Schwächen auf.
Beachten Sie, dass es keine wirklich effektive Möglichkeit gibt, Zeichenfolgen unterschiedlicher Länge zu vergleichen, obwohl die Berechnung der Levenshtein-Distanz zwischen zwei Zeichenfolgen Unterschiede in der Zeichenfolgenlänge berücksichtigt. Ein möglicher Workaround wäre, beide Strings bis zur Länge des kürzeren der beiden Strings zu vergleichen.
Nachfolgend finden Sie ein Beispielcode-Snippet, das den obigen Code implementiert, zusammen mit einigen Testbeispielen:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Der Beispiel-Python-Code liefert die folgende Ausgabe:
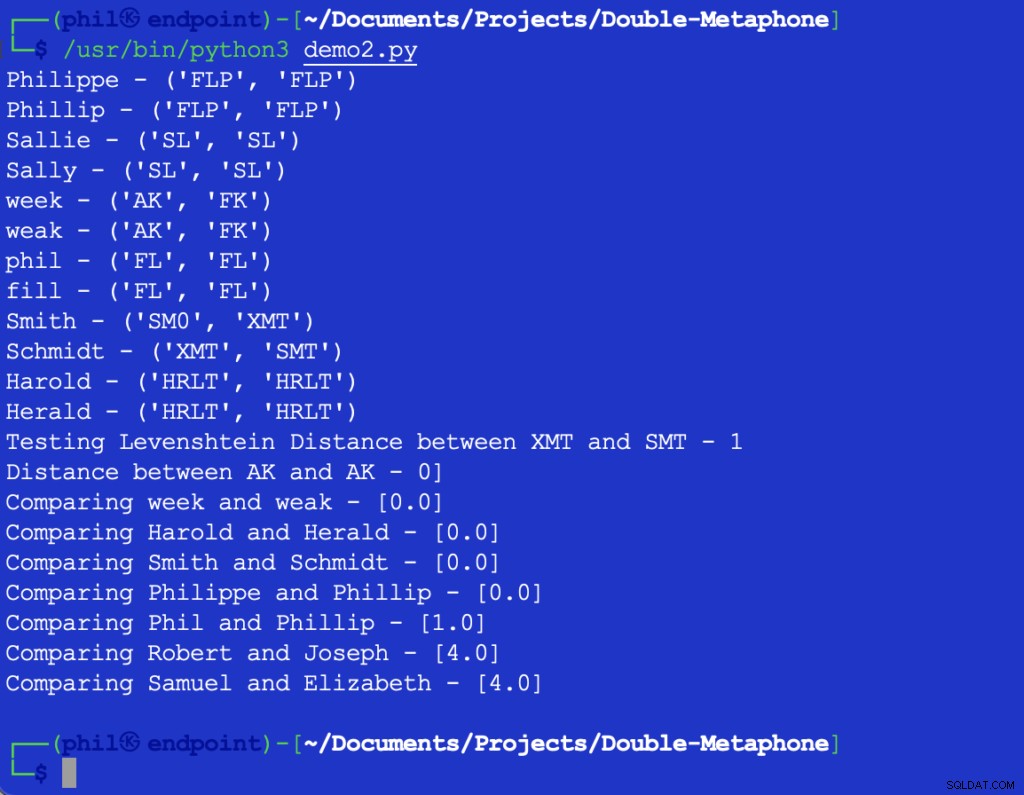
Abbildung 3 – Ausgabe des Nearness-Algorithmus
Das Sample-Set bestätigt den allgemeinen Trend, dass je größer die Unterschiede in den Wörtern sind, desto höher ist der Output der Nähe Funktion.
Datenbankintegration in Python
Der obige Code durchbricht die funktionale Lücke zwischen einem bestimmten RDBMS und einer Double Metaphone-Implementierung. Darüber hinaus durch die Implementierung der Nähe Funktion in Python, kann sie einfach ersetzt werden, falls ein anderer Vergleichsalgorithmus bevorzugt wird.
Betrachten Sie die folgende MySQL/MariaDB-Tabelle:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
In den meisten datenbankgesteuerten Anwendungen erstellt die Middleware SQL-Anweisungen zum Verwalten der Daten, einschließlich des Einfügens. Der folgende Code fügt einige Beispielnamen in diese Tabelle ein, aber in der Praxis könnte jeder Code aus einer Web- oder Desktop-Anwendung, die solche Daten sammelt, dasselbe tun.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Das Ausführen dieses Codes druckt nichts, aber es füllt die Testtabelle in der Datenbank für die nächste zu verwendende Auflistung. Durch direktes Abfragen der Tabelle im MySQL-Client kann überprüft werden, ob der obige Code funktioniert hat:
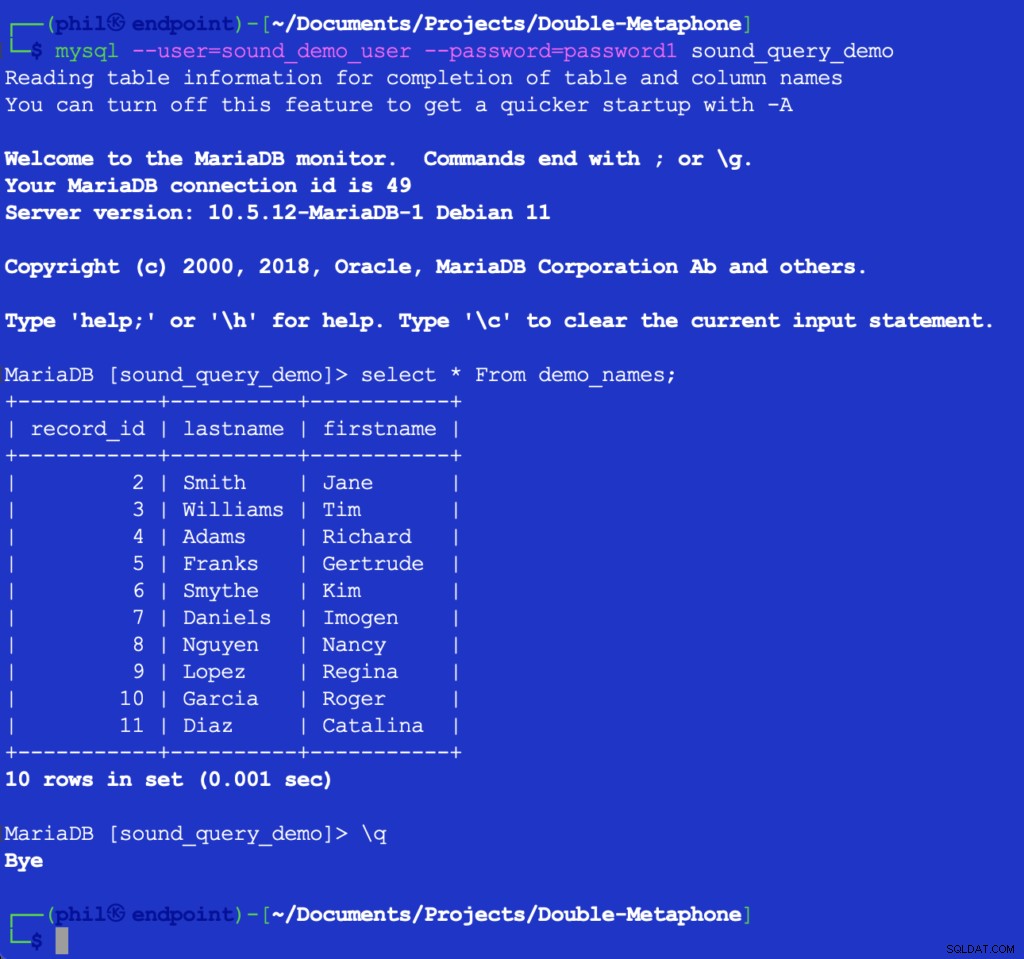
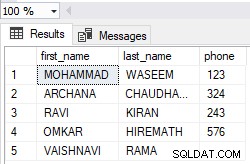
Abbildung 4 – Die eingefügten Tabellendaten
Der folgende Code speist einige Vergleichsdaten in die obigen Tabellendaten ein und führt einen Vergleich der Nähe damit durch:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Wenn Sie diesen Code ausführen, erhalten Sie die folgende Ausgabe:
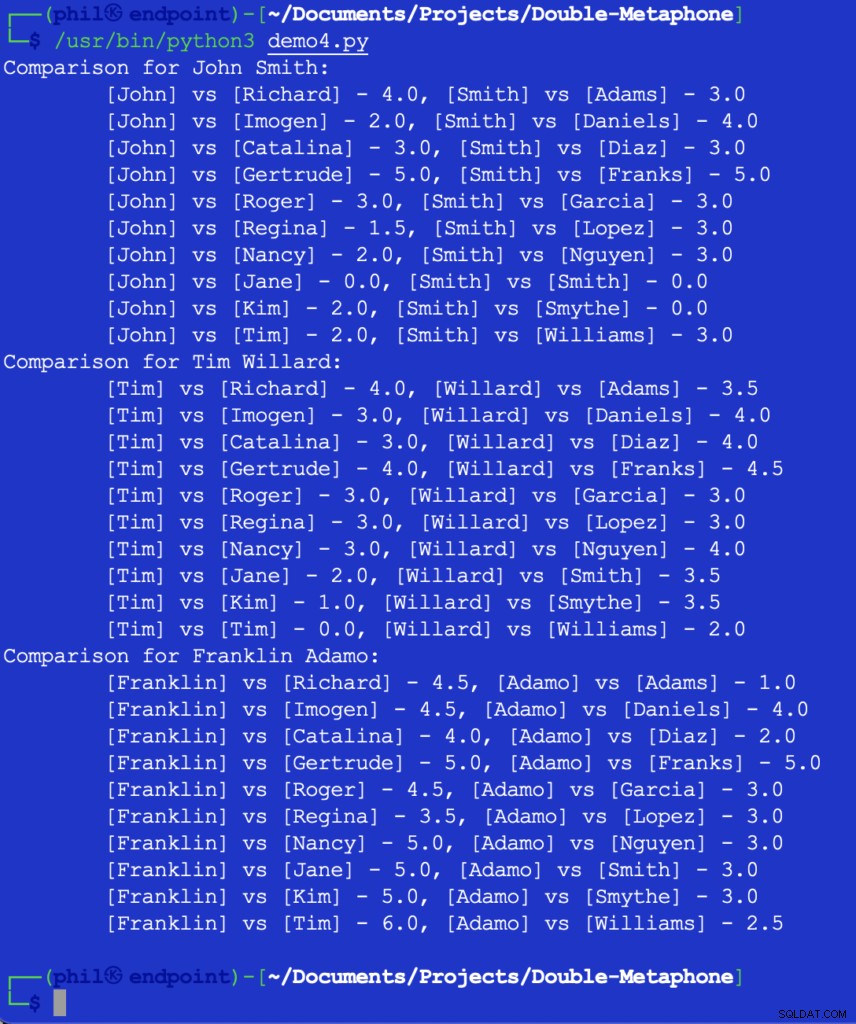
Abbildung 5 – Ergebnisse des Nähe-Vergleichs
An diesem Punkt wäre es Sache des Entwicklers, zu entscheiden, was der Schwellenwert für einen nützlichen Vergleich sein würde. Einige der obigen Zahlen mögen unerwartet oder überraschend erscheinen, aber eine mögliche Ergänzung des Codes könnte ein IF sein -Anweisung, um alle Vergleichswerte herauszufiltern, die größer als 2 sind .
Es kann erwähnenswert sein, dass die phonetischen Werte selbst nicht in der Datenbank gespeichert werden. Dies liegt daran, dass sie als Teil des Python-Codes berechnet werden und nicht unbedingt irgendwo gespeichert werden müssen, da sie beim Beenden des Programms verworfen werden. Ein Entwickler kann jedoch Wert darauf legen, diese in der Datenbank zu speichern und dann den Vergleich zu implementieren Funktion innerhalb der Datenbank eine gespeicherte Prozedur. Der einzige große Nachteil dabei ist jedoch der Verlust der Codeportabilität.
Abschließende Gedanken zum Abfragen von Daten nach Ton mit Python
Der Vergleich von Daten nach Ton scheint nicht die „Liebe“ oder Aufmerksamkeit zu erhalten, die der Vergleich von Daten durch Bildanalyse erhalten kann, aber wenn eine Anwendung mit mehreren ähnlich klingenden Varianten von Wörtern in mehreren Sprachen umgehen muss, kann dies von entscheidender Bedeutung sein Werkzeug. Ein nützliches Merkmal dieser Art von Analyse besteht darin, dass ein Entwickler kein Linguistik- oder Phonetikexperte sein muss, um diese Tools zu verwenden. Der Entwickler hat auch eine große Flexibilität bei der Definition, wie solche Daten verglichen werden können; Die Vergleiche können basierend auf den Anforderungen der Anwendung oder der Geschäftslogik optimiert werden.
Hoffentlich wird dieses Studiengebiet mehr Aufmerksamkeit im Forschungsbereich erhalten und es wird in Zukunft leistungsfähigere und robustere Analysewerkzeuge geben.