Die Änderungen in der internen Darstellung von partitionierten Tabellen zwischen SQL Server 2005 und SQL Server 2008 führten in den meisten Fällen zu verbesserten Abfrageplänen und verbesserter Leistung (insbesondere bei paralleler Ausführung). Leider haben dieselben Änderungen dazu geführt, dass einige Dinge, die in SQL Server 2005 gut funktionierten, plötzlich in SQL Server 2008 und höher nicht mehr so gut funktionierten. Dieser Beitrag befasst sich mit einem Beispiel, bei dem der SQL Server 2005-Abfrageoptimierer im Vergleich zu späteren Versionen einen überlegenen Ausführungsplan erstellt hat.
Beispieltabelle und Daten
Die Beispiele in diesem Beitrag verwenden die folgende partitionierte Tabelle und Daten:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Partitioniertes Datenlayout
Unsere Tabelle hat einen partitionierten Clustered-Index. In diesem Fall dient der Gruppierungsschlüssel auch als Partitionierungsschlüssel (obwohl dies im Allgemeinen nicht erforderlich ist). Die Partitionierung führt zu separaten physischen Speichereinheiten (Rowsets), die der Abfrageprozessor den Benutzern als eine Einheit präsentiert.
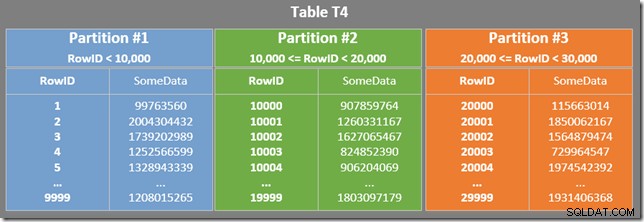
Das folgende Diagramm zeigt die ersten drei Partitionen unserer Tabelle (zum Vergrößern anklicken):
Der Nonclustered-Index wird auf die gleiche Weise partitioniert (er ist „ausgerichtet“):

Jede Partition des Nonclustered-Index deckt einen Bereich von RowID-Werten ab. Innerhalb jeder Partition werden die Daten nach SomeData geordnet (aber die RowID-Werte werden im Allgemeinen nicht geordnet).
Das MIN/MAX-Problem
Es ist allgemein bekannt, dass MIN und MAX Aggregate lassen sich für partitionierte Tabellen nicht gut optimieren (es sei denn, die zu aggregierende Spalte ist zufällig auch die Partitionierungsspalte). Über diese Einschränkung (die immer noch in SQL Server 2014 CTP 1 besteht) wurde im Laufe der Jahre viele Male geschrieben; Meine Lieblingsberichterstattung ist in diesem Artikel von Itzik Ben-Gan. Um das Problem kurz zu veranschaulichen, betrachten Sie die folgende Abfrage:
SELECT MIN(SomeData) FROM dbo.T4;
Der Ausführungsplan auf SQL Server 2008 oder höher lautet wie folgt:

Dieser Plan liest alle 150.000 Zeilen aus dem Index und ein Stream-Aggregat berechnet den Mindestwert (der Ausführungsplan ist im Wesentlichen derselbe, wenn wir stattdessen den Höchstwert anfordern). Der Ausführungsplan von SQL Server 2005 ist etwas anders (jedoch nicht besser):
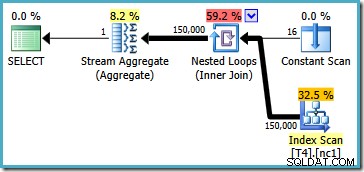
Dieser Plan iteriert über Partitionsnummern (aufgelistet in Constant Scan) und scannt jeweils eine Partition vollständig. Alle 150.000 Zeilen werden schließlich immer noch vom Stream Aggregate gelesen und verarbeitet.
Sehen Sie sich die partitionierten Tabellen- und Indexdiagramme noch einmal an und denken Sie darüber nach, wie die Abfrage für unseren Datensatz effizienter verarbeitet werden könnte. Der Nonclustered-Index scheint eine gute Wahl zum Auflösen der Abfrage zu sein, da er SomeData-Werte in einer Reihenfolge enthält, die beim Berechnen des Aggregats ausgenutzt werden könnte.
Nun, die Tatsache, dass der Index partitioniert ist, macht die Sache etwas komplizierter:jede Partition des Indexes ist nach der SomeData-Spalte geordnet, aber wir können nicht einfach den niedrigsten Wert von irgendeinem bestimmten lesen partitionieren, um die richtige Antwort auf die gesamte Abfrage zu erhalten.
Sobald die grundlegende Natur des Problems verstanden ist, kann ein Mensch erkennen, dass eine effiziente Strategie darin besteht, den einzelnen niedrigsten Wert von SomeData in jeder Partition zu finden des Index und nehmen Sie dann den niedrigsten Wert aus den Ergebnissen pro Partition.
Dies ist im Wesentlichen die Problemumgehung, die Itzik in seinem Artikel vorstellt; Schreiben Sie die Abfrage neu, um ein Aggregat pro Partition zu berechnen (mit APPLY Syntax) und dann erneut über diese Ergebnisse pro Partition aggregieren. Unter Verwendung dieses Ansatzes wird der umgeschriebene MIN Abfrage erzeugt diesen Ausführungsplan (die genaue Syntax finden Sie in Itziks Artikel):
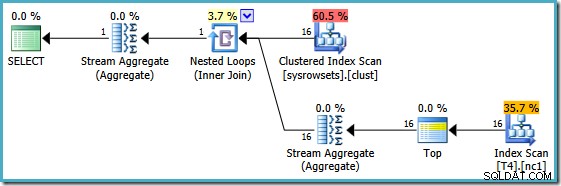
Dieser Plan liest Partitionsnummern aus einer Systemtabelle und ruft den niedrigsten Wert von SomeData in jeder Partition ab. Das endgültige Stream-Aggregat berechnet nur das Minimum über die Ergebnisse pro Partition.
Das wichtige Merkmal in diesem Plan ist, dass er eine einzelne Zeile liest aus jeder Partition (unter Ausnutzung der Sortierreihenfolge des Indexes innerhalb jeder Partition). Es ist viel effizienter als der Plan des Optimierers, der alle 150.000 Zeilen in der Tabelle verarbeitet.
MIN und MAX innerhalb einer einzelnen Partition
Betrachten Sie nun die folgende Abfrage, um den Mindestwert in der SomeData-Spalte für einen Bereich von RowID-Werten zu finden, die innerhalb einer einzelnen Partition enthalten sind :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Wir haben gesehen, dass der Optimierer Probleme mit MIN hat und MAX über mehrere Partitionen, aber wir würden erwarten, dass diese Einschränkungen nicht für eine einzelne Partitionsabfrage gelten.
Die einzelne Partition ist diejenige, die durch die RowID-Werte 10.000 und 20.000 begrenzt ist (siehe Definition der Partitionierungsfunktion). Die Partitionierungsfunktion wurde als RANGE RIGHT definiert , also gehört der 10.000-Grenzwert zu Partition Nr. 2 und die 20.000-Grenze zu Partition Nr. 3. Der von unserer neuen Abfrage angegebene Bereich von RowID-Werten ist daher allein in Partition 2 enthalten.
Die grafischen Ausführungspläne für diese Abfrage sehen auf allen SQL Server-Versionen ab 2005 gleich aus:
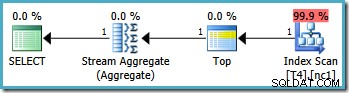
Plananalyse
Der Optimierer nahm den in WHERE angegebenen RowID-Bereich -Klausel und verglich sie mit der Partitionsfunktionsdefinition, um festzustellen, dass nur auf Partition 2 des Nonclustered-Index zugegriffen werden musste. Die Planeigenschaften von SQL Server 2005 für den Index-Scan zeigen den Einzelpartitionszugriff deutlich:
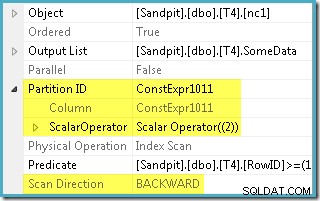
Die andere hervorgehobene Eigenschaft ist die Scanrichtung. Die Reihenfolge des Scans hängt davon ab, ob die Abfrage nach dem minimalen oder maximalen SomeData-Wert sucht. Der Nonclustered-Index ist (pro Partition, denken Sie daran) nach aufsteigenden SomeData-Werten geordnet, sodass die Richtung des Index-Scans FORWARD ist wenn die Abfrage nach dem Mindestwert fragt, und BACKWARD wenn der Maximalwert benötigt wird (der obige Screenshot wurde aus dem MAX gemacht Abfrageplan).
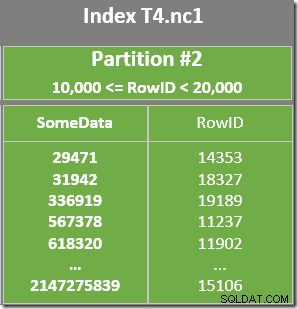
Es gibt auch ein Restprädikat für den Index-Scan, um zu prüfen, ob die von Partition 2 gescannten RowID-Werte mit WHERE übereinstimmen Klausel Prädikat. Der Optimierer geht davon aus, dass RowID-Werte ziemlich willkürlich über den Nonclustered-Index verteilt werden, also erwartet er, die erste Zeile zu finden, die mit WHERE übereinstimmt Klausel Prädikat ziemlich schnell. Das partitionierte Datenlayoutdiagramm zeigt, dass die RowID-Werte tatsächlich ziemlich zufällig im Index verteilt sind (der nach der SomeData-Spalte geordnet ist, denken Sie daran):
Der Top-Operator im Abfrageplan begrenzt den Index-Scan auf eine einzelne Zeile (entweder vom unteren oder oberen Ende des Index, abhängig von der Scan-Richtung). Index-Scans können in Abfrageplänen problematisch sein, aber der Top-Operator macht sie hier zu einer effizienten Option:Der Scan kann immer nur eine Zeile erzeugen, dann stoppt er. Die Top-and-Ordered-Index-Scan-Kombination führt effektiv eine Suche nach dem höchsten oder niedrigsten Wert im Index durch, der auch mit WHERE übereinstimmt Klausel Prädikate. Ein Stream-Aggregat erscheint auch im Plan, um sicherzustellen, dass ein NULL wird generiert, falls vom Index-Scan keine Zeilen zurückgegeben werden. Skalare MIN und MAX Aggregate sind so definiert, dass sie einen NULL zurückgeben wenn die Eingabe eine leere Menge ist.
Insgesamt ist dies eine sehr effiziente Strategie, und die Pläne haben geschätzte Kosten von nur 0,0032921 Einheiten als Ergebnis. So weit, so gut.
Das Grenzwertproblem
Dieses nächste Beispiel ändert das obere Ende des RowID-Bereichs:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Beachten Sie, dass die Abfrage ausschließt den Wert 20.000, indem Sie einen „kleiner als“-Operator verwenden. Denken Sie daran, dass der Wert 20.000 zu Partition 3 gehört (nicht zu Partition 2), da die Partitionsfunktion als RANGE RIGHT definiert ist . Der SQL Server2005 Der Optimierer handhabt diese Situation korrekt und erstellt den optimalen Abfrageplan für eine einzelne Partition mit geschätzten Kosten von 0,0032878 :
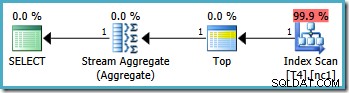
Dieselbe Abfrage erzeugt jedoch einen anderen Plan auf SQL Server 2008 und höher (einschließlich SQL Server 2014 CTP 1):
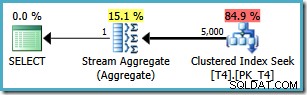
Jetzt haben wir einen Clustered Index Seek (anstelle der gewünschten Kombination aus Index Scan und Top-Operator). Alle 5.000 Zeilen, die mit WHERE übereinstimmen -Klausel werden in diesem neuen Ausführungsplan durch das Stream Aggregate verarbeitet. Die geschätzten Kosten dieses Plans betragen 0,0199319 Einheiten – mehr als sechsmal die Kosten des Plans für SQL Server 2005.
Ursache
Die Optimierer von SQL Server 2008 (und höher) verstehen die interne Logik nicht ganz richtig, wenn ein Intervall verweist, aber ausschließt , ein Grenzwert, der zu einer anderen Partition gehört. Der Optimierer geht fälschlicherweise davon aus, dass auf mehrere Partitionen zugegriffen wird, und kommt zu dem Schluss, dass er die Einzelpartitionsoptimierung für MIN nicht verwenden kann und MAX Aggregate.
Problemumgehungen
Eine Möglichkeit besteht darin, die Abfrage mit den Operatoren>=und <=neu zu schreiben, sodass wir nicht auf einen Grenzwert aus einer anderen Partition verweisen (auch nicht, um ihn auszuschließen!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Dies ergibt den optimalen Plan, der eine einzelne Partition berührt:
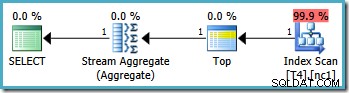
Leider ist es nicht immer möglich, auf diese Weise korrekte Grenzwerte anzugeben (abhängig vom Typ der Partitionierungsspalte). Ein Beispiel dafür sind Datums- und Zeittypen, bei denen es am besten ist, halboffene Intervalle zu verwenden. Ein weiterer Einwand gegen diese Problemumgehung ist subjektiver:Die Partitionierungsfunktion schließt eine Grenze aus dem Bereich aus, daher scheint es am natürlichsten, die Abfrage auch mit halboffener Intervallsyntax zu schreiben.
Eine zweite Problemumgehung besteht darin, die Partitionsnummer explizit anzugeben (und das halboffene Intervall beizubehalten):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Dies erzeugt den optimalen Plan, allerdings auf Kosten des Erfordernisses eines zusätzlichen Prädikats und der Verlässlichkeit, dass der Benutzer herausfindet, wie die Partitionsnummer lauten sollte.
Natürlich wäre es besser, wenn die Optimierer von 2008 und höher den gleichen optimalen Plan wie SQL Server 2005 erstellen würden. In einer perfekten Welt würde eine umfassendere Lösung auch den Fall mehrerer Partitionen ansprechen, wodurch die Problemumgehung, die Itzik beschreibt, ebenfalls unnötig wird.