Jetzt hat unsere Big-Data-Analytics-Community damit begonnen, Apache Spark in vollem Gange für die Big-Data-Verarbeitung zu verwenden. Die Verarbeitung könnte für Ad-hoc-Abfragen, vorgefertigte Abfragen, Diagrammverarbeitung, maschinelles Lernen und sogar für das Datenstreaming erfolgen.
Daher ist das Verständnis von Spark Job Submission für die Community sehr wichtig. Darüber hinaus freuen wir uns, Ihnen die Erkenntnisse aus den Schritten der Apache Spark-Auftragsübermittlung mitzuteilen.
Im Grunde hat es zwei Schritte,

Auftragsübermittlung
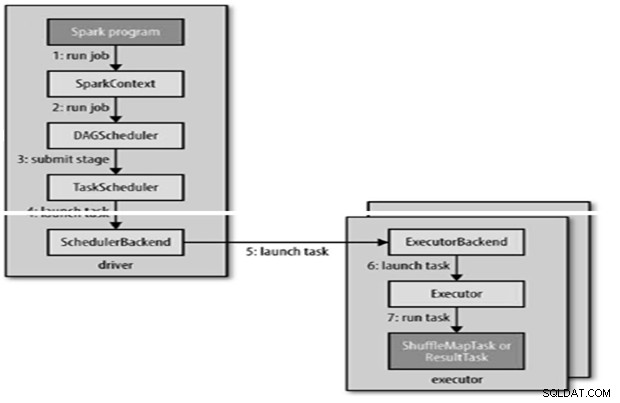
Der Spark-Job wird automatisch gesendet, wenn eine Aktion wie count() auf einem RDD ausgeführt wird.
Intern wird runJob() auf dem SparkContext aufgerufen und dann der Scheduler aufgerufen, der als Teil des Derivers ausgeführt wird.
Der Scheduler besteht aus 2 Teilen – DAG Scheduler und Task Scheduler.
DAG-Konstruktion
Es gibt zwei Arten von DAG-Konstruktionen,

- Ein einfacher Spark-Job ist ein Job, der kein Shuffle benötigt und daher nur eine einzige Stufe hat, die aus Ergebnisaufgaben besteht, wie ein Nur-Karten-Job in MapReduce
- Ein komplexer Spark-Job umfasst Gruppierungsvorgänge und erfordert eine oder mehrere Shuffle-Stufen.
- Der DAG-Scheduler von Spark verwandelt den Job in zwei Phasen.
- Der DAG-Scheduler ist dafür verantwortlich, eine Stufe in Aufgaben aufzuteilen, die an den Aufgabenplaner gesendet werden.
- Jeder Task wird vom DAG-Scheduler eine Platzierungspräferenz zugewiesen, damit der Task-Scheduler die Datenlokalität nutzen kann.
- Untergeordnete Phasen werden erst eingereicht, wenn ihre Eltern erfolgreich abgeschlossen haben.
Aufgabenplanung
- Der Aufgabenplaner sendet eine Reihe von Aufgaben; Es verwendet seine Liste von Ausführenden, die für die Anwendung ausgeführt werden, und erstellt eine Zuordnung von Aufgaben zu Ausführenden, die Platzierungspräferenzen berücksichtigt.
- Der Aufgabenplaner weist Ausführenden mit freien Kernen zu, jeder Aufgabe wird standardmäßig ein Kern zugewiesen. Es kann durch den Parameter spark.task.cpus geändert werden.
- Spark verwendet Akka, eine akteurbasierte Plattform zum Erstellen hochgradig skalierbarer, ereignisgesteuerter, verteilter Anwendungen.
- Spark verwendet den Hadoop-RPC nicht für Remoteaufrufe.
Aufgabenausführung
Ein Ausführender führt eine Aufgabe wie folgt aus:
- Es stellt sicher, dass die JAR- und Dateiabhängigkeiten für die Aufgabe aktuell sind.
- Deserialisiert den Aufgabencode.
- Aufgabencode wird ausgeführt.
- Task gibt Ergebnisse an den Treiber zurück, der sich zu einem Endergebnis zusammensetzt, das an den Benutzer zurückgegeben wird.
Referenz
- Der endgültige Hadoop-Leitfaden
- Analytics &Big Data Open Source Community
Dieser Artikel erschien ursprünglich hier. Wiederveröffentlicht mit Genehmigung. Reichen Sie Ihre Urheberrechtsbeschwerden hier ein.