Während Jeff Atwood und Joe Celko zu denken scheinen, dass die Kosten von GUIDs keine große Sache sind (siehe Jeffs Blogbeitrag „Primary Keys:IDs versus GUIDs“, und diesen Newsgroup-Thread mit dem Titel „Identity Vs. Uniqueidentifier“), haben andere Experten – insbesondere Index- und Architekturexperten, die sich auf den SQL-Server-Bereich konzentrieren – neigen dazu, anderer Meinung zu sein. Zum Beispiel geht Kimberly Tripp in ihrem Beitrag „Festplattenspeicherplatz ist billig – DAS IST NICHT DER ZWECK!“ auf einige Details ein, in dem sie erklärt, dass die Auswirkungen nicht nur auf den Speicherplatz und die Fragmentierung, sondern vor allem auf die Indexgröße und den Arbeitsspeicher zurückzuführen sind Fußabdruck.
Was Kimberly sagt, ist wirklich wahr – ich stoße die ganze Zeit auf die Rechtfertigung „Speicherplatz ist billig“ für GUIDs (Beispiel von gerade letzter Woche). Es gibt andere Gründe für GUIDs, einschließlich der Notwendigkeit, eindeutige Bezeichner außerhalb der Datenbank zu generieren (und manchmal bevor die Zeile tatsächlich erstellt wird) und die Notwendigkeit eindeutiger Bezeichner über getrennte verteilte Systeme hinweg (und wo Identitätsbereiche nicht praktikabel sind). Aber ich möchte wirklich mit dem Mythos aufräumen, dass GUIDs nicht allzu viel kosten, weil sie es tun, und Sie diese Kosten in Ihre Entscheidung einbeziehen müssen.
Ich habe mich auf diese Mission gemacht, um die Leistung verschiedener Schlüsselgrößen zu testen, wenn dieselben Daten über dieselbe Anzahl von Zeilen mit denselben Indizes und ungefähr derselben Arbeitslast gegeben sind (das Wiedergeben der *genau* gleichen Arbeitslast kann ziemlich herausfordernd sein). Ich wollte nicht nur die grundlegenden Dinge wie Indexgröße und Indexfragmentierung messen, sondern auch die Auswirkungen, die diese auf die ganze Linie haben, wie zum Beispiel:
- Auswirkung auf die Nutzung des Pufferpools
- Häufigkeit "schlechter" Seitenteilungen
- Gesamtauswirkung auf die realistische Arbeitsbelastungsdauer
- Auswirkung auf die durchschnittliche Laufzeit einzelner Abfragen
- Einfluss auf die Laufzeitdauer von After-Triggern
- Auswirkung auf die tempdb-Nutzung
Ich werde eine Vielzahl von Techniken verwenden, um diese Daten zu untersuchen, darunter erweiterte Ereignisse, die Standardablaufverfolgung, tempdb-bezogene DMVs und SQL Sentry Performance Advisor.
Einrichtung
Zuerst habe ich eine Million Kunden erstellt, um sie mithilfe einiger integrierter SQL Server-Metadaten in eine Seed-Tabelle einzufügen. dies würde sicherstellen, dass die "zufälligen" Kunden bei jedem Test aus den gleichen natürlichen Daten bestehen würden.
CREATE TABLE dbo.CustomerSeeds(rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. name, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ORDER BY rn;GO
Ihr Kilometerstand kann variieren, aber auf meinem System dauerte diese Population 86 Sekunden. Zehn repräsentative Reihen (zum Vergrößern anklicken):
 Beispielkunden
Beispielkunden
Als nächstes brauchte ich Tabellen, um die Startdaten für jeden Anwendungsfall unterzubringen, mit ein paar zusätzlichen Indizes, um eine Art Realität zu simulieren, und ich entwickelte kurze Suffixe, um später alle Arten von Diagnosen zu vereinfachen:
| Datentyp | Standard | Komprimierung | Anwendungsfall-Suffix |
|---|---|---|---|
| INT | IDENTITÄT | keine | Ich |
| INT | IDENTITÄT | Seite + Zeile | Ic |
| BIGINT | IDENTITÄT | keine | B |
| BIGINT | IDENTITÄT | Seite + Zeile | Bc |
| UNIQUEIDENTIFIER | NEWID() | keine | G |
| UNIQUEIDENTIFIER | NEWID() | Seite + Zeile | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | keine | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | Seite + Zeile | Sc |
Tabelle 1:Anwendungsfälle, Datentypen und Suffixe
Insgesamt acht Tabellen, die alle aus derselben Vorlage stammen (ich würde einfach die Kommentare ändern, um sie dem Anwendungsfall anzupassen, und $use_case$ ersetzen mit dem entsprechenden Suffix aus obiger Tabelle):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL STANDARD NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL STANDARD NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL, Aktiv BIT NOT NULL DEFAULT 1, DATETIME NOT NULL erstellt DEFAULT SYSDATETIME(), DATETIME NULL aktualisiert, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE INDEX C_Email_Customers_$use_case$ ON dbo. Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(Nachname, Vorname) INCLUDE (E-Mail) --WITH (DATA_COMPRESSION =PAGE);GOSobald die Tabellen erstellt waren, fuhr ich fort, die Tabellen zu füllen und viele der Metriken zu messen, auf die ich oben angespielt hatte. Ich habe den SQL Server-Dienst zwischen den einzelnen Tests neu gestartet, um sicherzustellen, dass alle von der gleichen Baseline aus gestartet wurden, dass DMVs zurückgesetzt wurden usw.
Unbestrittene Beilagen
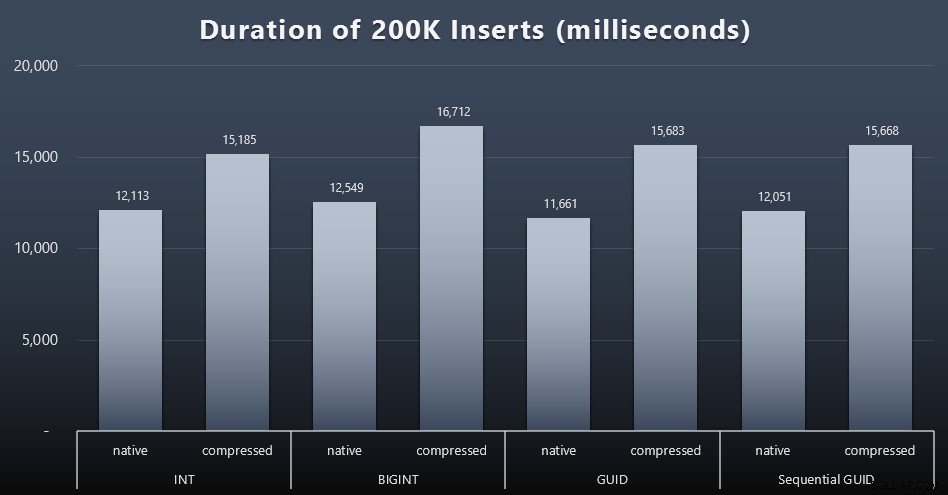
Mein letztendliches Ziel war es, die Tabelle mit 1.000.000 Zeilen zu füllen, aber zuerst wollte ich die Auswirkungen des Datentyps und der Komprimierung auf unformatierte Einfügungen ohne Konflikte sehen. Ich habe die folgende Abfrage generiert – die die Tabelle mit den ersten 200.000 Kontakten füllen würde, jeweils 2000 Zeilen – und sie für jede Tabelle ausgeführt:
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) ZEILEN NUR NÄCHSTE 2000 ZEILEN ABRUFEN; SET @i +=1;ENDErgebnisse (zum Vergrößern anklicken):
Jeder Fall dauerte ungefähr 12 Sekunden (ohne Komprimierung) und 16 Sekunden (mit Komprimierung), wobei es in beiden Speichermodi keinen klaren Gewinner gab. Die Auswirkung der Komprimierung (hauptsächlich auf den CPU-Overhead) ist ziemlich konsistent, aber da diese auf einer schnellen SSD läuft, ist die I/O-Auswirkung der verschiedenen Datentypen vernachlässigbar. Tatsächlich schien die Komprimierung gegen BIGINT den größten Einfluss zu haben (und das macht Sinn, da jeder einzelne Wert unter 2 Milliarden komprimiert werden würde).
Umstrittenere Arbeitsbelastung
Als Nächstes wollte ich sehen, wie eine gemischte Workload um Ressourcen konkurrieren und im Allgemeinen gegen jeden Datentyp abschneiden würde. Also habe ich diese Prozeduren erstellt (und
$use_case$ersetzt und$data_type$passend für jeden Test):-- zufällige Einzelaktualisierungen von Daten in mehr als einem IndexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- liest ("Paginierung") - unterstützt mehrere sorts – Verwenden Sie dynamisches SQL, um die Abfragestatistiken separat zu verfolgen. DECLARE @sql NVARCHAR(MAX) =N'SELECT Kunden-ID, Vorname, Nachname, E-Mail, Aktiv, Erstellt, Aktualisiert FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) REIHEN NÄCHSTES ABRUFEN @ps NUR REIHEN;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGODann habe ich Jobs erstellt, die diese Prozeduren mit leichten Verzögerungen wiederholt aufrufen und gleichzeitig die verbleibenden 800.000 Kontakte fertig stellen. Dieses Skript erstellt alle 32 Jobs und druckt auch eine Ausgabe, die später verwendet werden kann, um alle Jobs für einen bestimmten Test asynchron aufzurufen:
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Kunden ausfüllen', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Vorname, Nachname, E-Mail, Aktiv) SELECT Vorname, Nachname, E-Mail, Aktiv FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) ZEILEN NUR NÄCHSTE 2000 ZEILEN ABRUFEN, AUF VERZÖGERUNG WARTEN ''00:00:01''; SET @i +=1; END'),( N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sort by KundenID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; AUF VERZÖGERUNG WARTEN ''00:00:01''; SETZE @i +=2; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- Sortierung nach Nachname, Vorname SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; AUF VERZÖGERUNG WARTEN ''00:00:01''; SET @i +=2; ENDE'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; ÖFFNEN c; c IN @n, @c HOLEN; WHILE @@FETCH_STATUS <> -1BEGIN IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokal)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; c INTO @n, @c;ENDholenDas Messen der Jobzeiten war in jedem Fall trivial – ich konnte Start-/Enddaten in
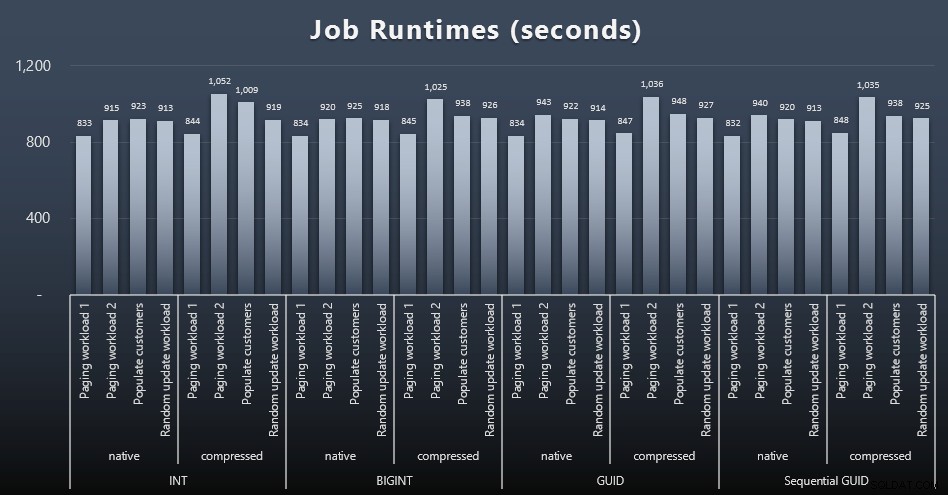
msdb.dbo.sysjobhistoryüberprüfen oder ziehen Sie sie aus dem SQL Sentry Event Manager. Hier sind die Ergebnisse (zum Vergrößern anklicken):
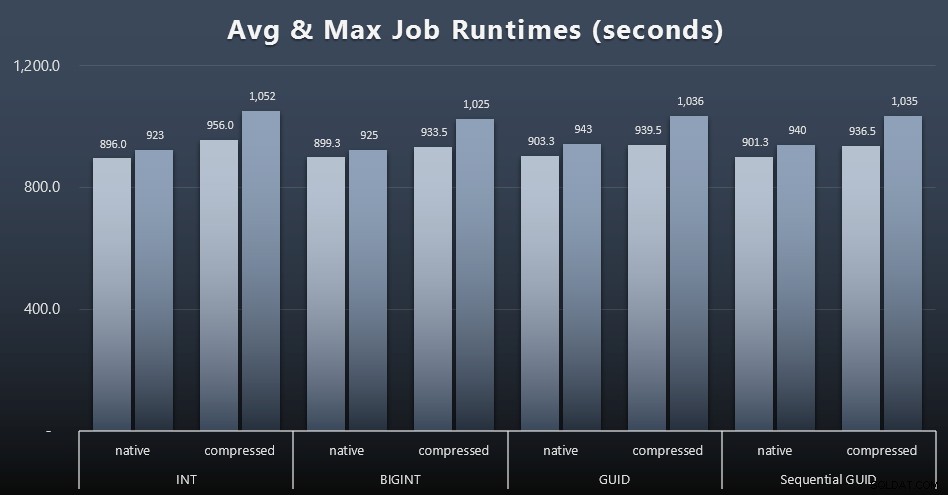
Und wenn Sie etwas weniger zu verdauen haben möchten, schauen Sie sich einfach die durchschnittlichen und maximalen Laufzeiten der vier Jobs an (zum Vergrößern anklicken):
Aber selbst in diesem zweiten Diagramm gibt es nicht wirklich genug Varianz, um überzeugende Argumente für oder gegen einen der Ansätze zu liefern.
Abfragelaufzeiten
Ich habe einige Metriken aus
sys.dm_exec_query_statsentnommen undsys.dm_exec_trigger_statsum festzustellen, wie lange einzelne Abfragen im Durchschnitt dauerten.
Bevölkerung
Die ersten 200.000 Kunden wurden recht schnell geladen – unter 20 Sekunden – da keine konkurrierenden Workloads vorhanden waren. Sobald die vier Jobs jedoch gleichzeitig ausgeführt wurden, gab es aufgrund der Parallelität erhebliche Auswirkungen auf die Schreibdauer. Die verbleibenden 800.000 Zeilen erforderten im Durchschnitt mindestens eine Größenordnung mehr Zeit zur Fertigstellung. Hier sind die Ergebnisse der Mittelwertbildung von jeweils 2.000 Kundenbeilagen (zum Vergrößern anklicken):
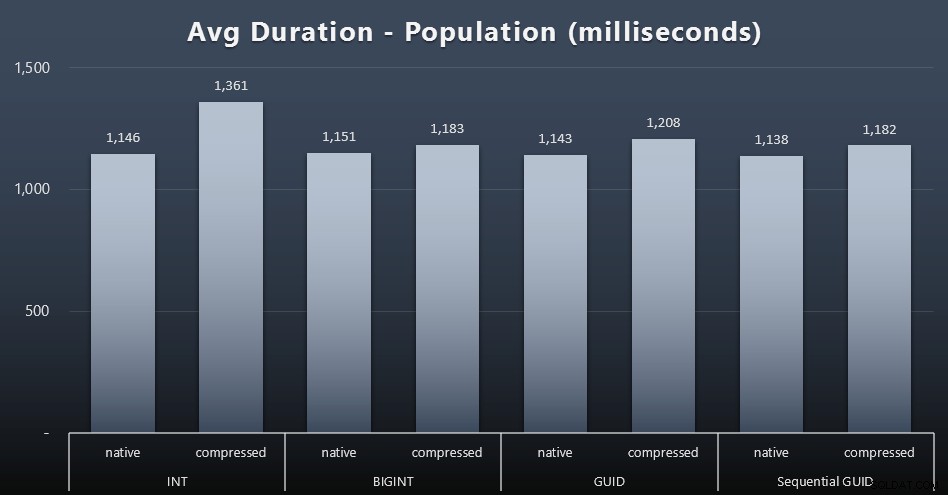
Wir sehen hier, dass das Komprimieren eines INT der einzige wirkliche Ausreißer war – ich habe einige Theorien dazu, aber noch nichts schlüssiges.
Paging-Workloads
Auch die durchschnittlichen Laufzeiten der Paging-Anfragen scheinen im Vergleich zu meinen isolierten Testläufen deutlich von Parallelität beeinflusst worden zu sein. Hier sind die Ergebnisse (zum Vergrößern anklicken):
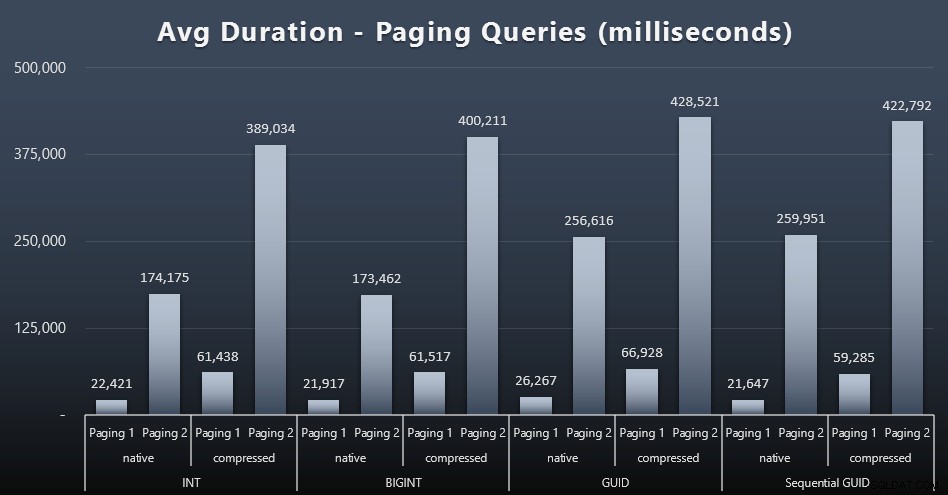
(Paging 1 =Bestellung nach Kunden-ID, Paging 2 =Bestellung nach Nachname, Vorname.)
Wir sehen, dass es sowohl für Paging 1 (Ordnung nach Kunden-ID) als auch für Paging 2 (Ordnung nach Namen) aufgrund der Komprimierung erhebliche Auswirkungen auf die Laufzeit gibt (bis zu ~700 %). Beide GUIDs scheinen die langsamsten Pferde in diesem Rennen zu sein, wobei NEWID() am schlechtesten abschneidet.
Workloads aktualisieren
Die Singleton-Updates waren selbst bei starker Parallelität ziemlich schnell, aber es gab immer noch einige merkliche Unterschiede aufgrund der Komprimierung und sogar einige überraschende Unterschiede zwischen den Datentypen (zum Vergrößern klicken):
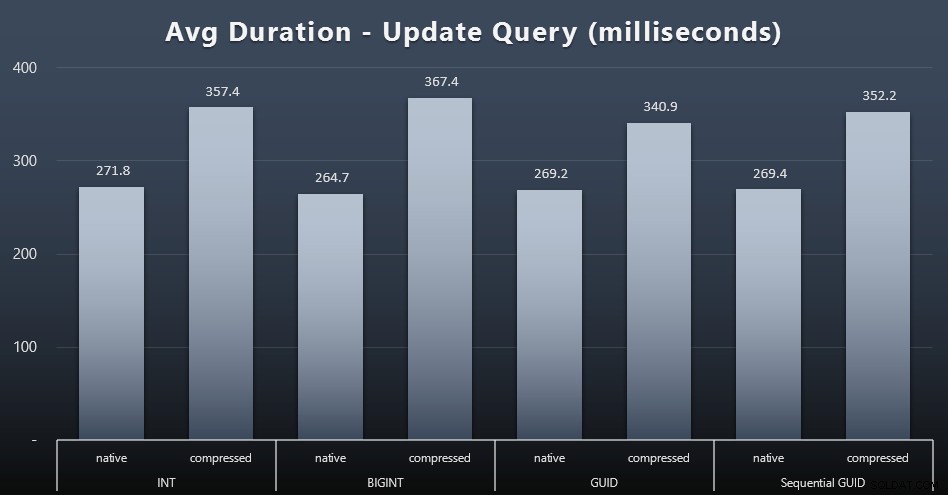
Am bemerkenswertesten war, dass die Aktualisierungen der Zeilen mit GUID-Werten tatsächlich schneller waren als die Updates, die INT/BIGINT enthalten, wenn die Komprimierung verwendet wurde. Bei nativem Speicher waren die Unterschiede weniger bemerkenswert (aber INT war dort immer noch ein Verlierer).
Statistik auslösen
Hier sind jeweils die durchschnittlichen und maximalen Laufzeiten für den einfachen Trigger (zum Vergrößern anklicken):
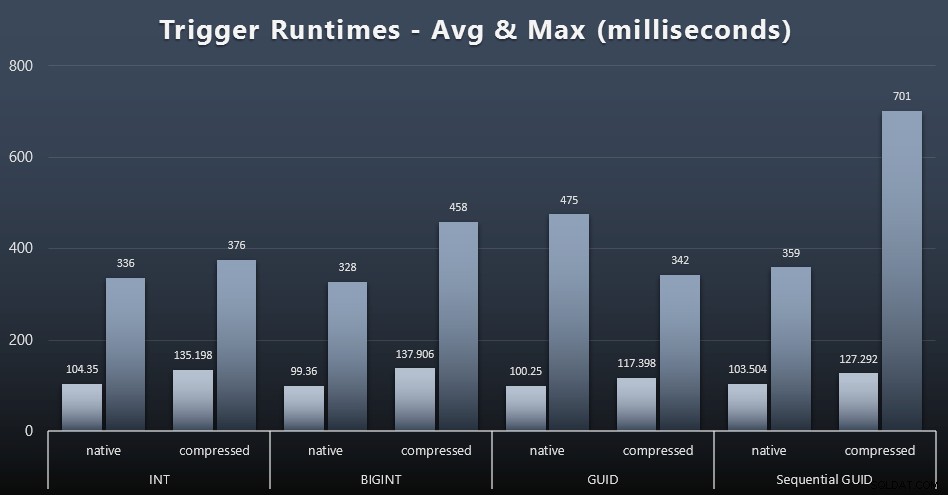
Die Komprimierung scheint hier einen viel größeren Einfluss zu haben als die Wahl des Datentyps (obwohl dies wahrscheinlich ausgeprägter wäre, wenn ein Teil meiner Update-Arbeitslast viele Zeilen aktualisiert hätte, anstatt nur aus Einzelzeilensuchen zu bestehen). Das Maximum für die sequentielle GUID ist eindeutig ein Ausreißer, den ich nicht untersucht habe (Sie können sagen, dass es unbedeutend ist, basierend auf dem Durchschnitt, der immer noch auf der ganzen Linie übereinstimmt).
Worauf haben diese Abfragen gewartet?
Nach jedem Workload habe ich mir auch die häufigsten Wartezeiten auf dem System angesehen, offensichtliche Warteschlangen-/Timer-Wartezeiten (wie von Paul Randal beschrieben) und irrelevante Aktivitäten von Überwachungssoftware (wie TRACEWRITE) weggeworfen ). Hier die Top 3 Waits jeweils (zum Vergrößern anklicken):
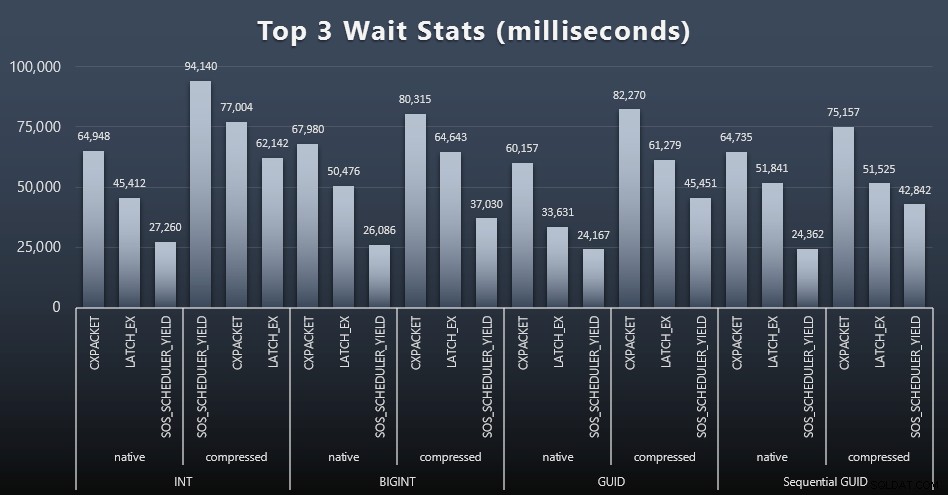
In den meisten Fällen waren die Wartezeiten CXPACKET, dann LATCH_EX, dann SOS_SCHEDULER_YIELD. Im Anwendungsfall mit Ganzzahlen und Komprimierung übernahm jedoch SOS_SCHEDULER_YIELD, was für mich eine gewisse Ineffizienz im Algorithmus zum Komprimieren von Ganzzahlen impliziert (was möglicherweise völlig unabhängig von dem Algorithmus ist, der zum Komprimieren von BIGINTs in INTs verwendet wird). Ich habe dies nicht weiter untersucht und auch keine Rechtfertigung für das Nachverfolgen von Wartezeiten pro einzelner Abfrage gefunden.
Speicherplatz / Fragmentierung
Obwohl ich eher zustimme, dass es nicht um den Speicherplatz geht, ist es dennoch eine Metrik, die es wert ist, präsentiert zu werden. Selbst in diesem sehr vereinfachten Fall, in dem es nur eine Tabelle gibt und der Schlüssel nicht in allen anderen verwandten Tabellen vorhanden ist (was in einer realen Anwendung sicherlich vorhanden wäre), ist der Unterschied signifikant. Sehen wir uns zuerst den reserved an Spalte von sp_spaceused (zum Vergrößern anklicken):
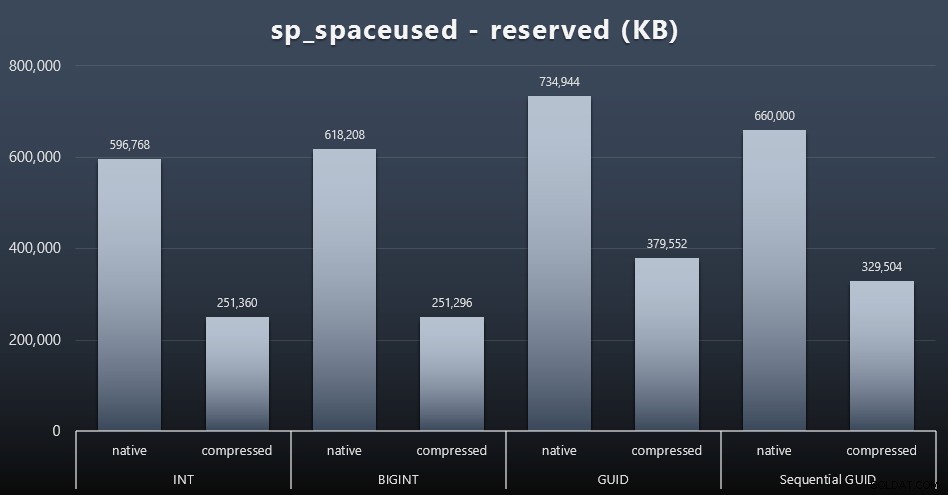
Hier nahm BIGINT nur etwas mehr Platz ein als INT, und GUID hatte (erwartungsgemäß) einen größeren Sprung. Die sequentielle GUID hatte eine weniger signifikante Zunahme des verwendeten Speicherplatzes und wurde auch viel besser komprimiert als die herkömmliche GUID. Auch hier keine Überraschungen – eine GUID ist größer als eine Zahl, Punkt. Nun könnten GUID-Befürworter argumentieren, dass der Preis, den Sie in Bezug auf den Speicherplatz zahlen, nicht so hoch ist (18 % über BIGINT ohne Komprimierung, etwa 50 % mit Komprimierung). Denken Sie jedoch daran, dass dies eine einzelne Tabelle mit 1 Million Zeilen ist. Stellen Sie sich vor, wie sich das hochrechnen lässt, wenn Sie 10 Millionen Kunden haben und viele von ihnen 10, 30 oder 500 Bestellungen haben – diese Schlüssel könnten in einem Dutzend anderer Tabellen wiederholt werden und den gleichen zusätzlichen Platz in jeder Zeile einnehmen.
Als ich mir die Fragmentierung nach jeder Arbeitslast ansah (denken Sie daran, dass keine Indexwartung durchgeführt wird) mit dieser Abfrage:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Die Ergebnisse sorgten für viel weniger interessante Bilder; alle Nicht gruppierte Indizes waren zu über 99 % fragmentiert. Die geclusterten Indizes waren jedoch entweder sehr stark fragmentiert oder überhaupt nicht fragmentiert (zum Vergrößern klicken):
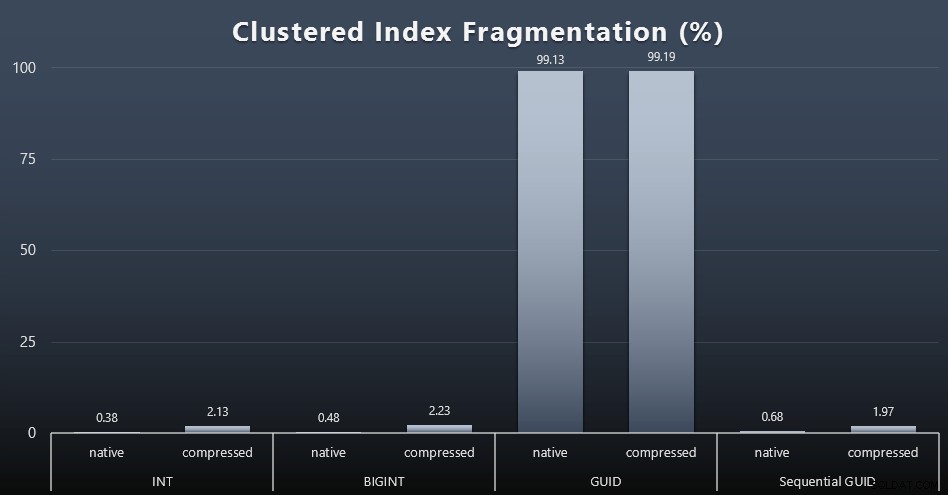
Fragmentierung ist eine weitere Metrik, die oft viel weniger bedeutet, wenn wir über SSDs sprechen, aber es ist wichtig, das Gleiche zu beachten, da nicht alle Systeme es sich leisten können, sich der Auswirkungen, die Fragmentierung auf I/O-Muster haben kann, vollkommen unbewusst zu sein. Ich glaube, dass die Verwendung nicht-sequentieller GUIDs auf einem E/A-gebundenen System allein die Auswirkung dieser Fragmentierung auf die meisten anderen Metriken in diesem Test drastisch verstärken würde.
Pufferpoolnutzung
Hier zahlt es sich wirklich aus, den von Ihren Tabellen belegten Speicherplatz mit Bedacht festzulegen – je größer Ihre Tabellen sind, desto mehr Platz nehmen sie im Pufferpool ein. Das Verschieben von Daten in den und aus dem Pufferpool ist teuer, und auch dies ist ein sehr vereinfachter Fall, in dem die Tests isoliert ausgeführt wurden und keine anderen Anwendungen und Datenbanken auf der Instanz um wertvollen Speicher konkurrierten.
Dies ist ein einfaches Maß für die folgende Abfrage am Ende jeder Arbeitslast:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Ergebnisse (zum Vergrößern anklicken):
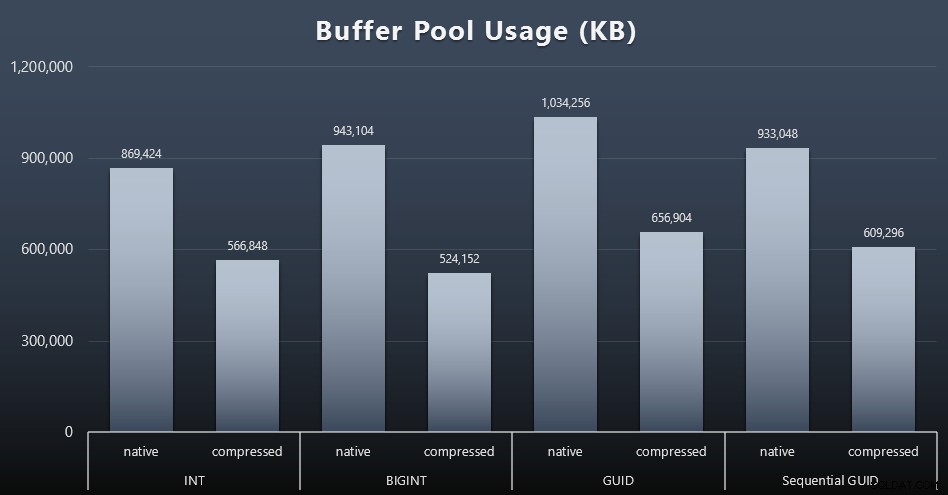
Während der größte Teil dieses Diagramms überhaupt nicht überraschend ist – GUID nimmt mehr Platz ein als BIGINT, BIGINT mehr als INT – fand ich es interessant, dass eine sequentielle GUID weniger Platz beanspruchte als eine BIGINT, selbst ohne Komprimierung. Ich habe mir notiert, einige Forensiken auf Seitenebene durchzuführen, um festzustellen, welche Art von Effizienz hier unter der Decke stattfindet.
tempdb-Nutzung
Ich bin mir nicht sicher, was ich hier erwartet habe, aber nach jeder Arbeitslast habe ich den Inhalt der drei tempdb-bezogenen Speichernutzungs-DMVs gesammelt, sys.dm_db_file|session|task_space_usage . Die einzige, die je nach Datentyp eine gewisse Volatilität zu zeigen schien, war sys.dm_db_file_space_usage 's extent_allocation_page_count . Dies zeigt, dass – zumindest in meiner Konfiguration und dieser spezifischen Arbeitslast – GUIDs tempdb einem etwas gründlicheren Training unterziehen (zum Vergrößern anklicken):
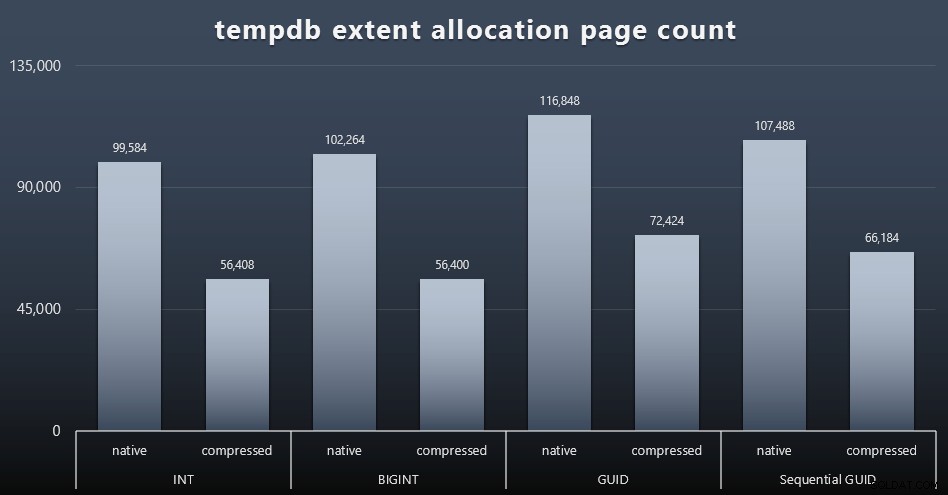
„Schlechte“ Seitenteilungen
Eines der Dinge, die ich messen wollte, war die Auswirkung auf Seitenteilungen – nicht normale Seitenteilungen (wenn Sie eine neue Seite hinzufügen), sondern wenn Sie tatsächlich Daten zwischen Seiten verschieben müssen, um Platz für mehr Zeilen zu schaffen. Jonathan Kehayias geht ausführlicher in seinem Blog-Beitrag „Tracking Problematic Pages Splits in SQL Server 2012 Extended Events – No Really This Time!“ darauf ein, der auch die Grundlage für die Extended Events-Sitzung bildet, die ich zum Erfassen der Daten verwendet habe:
EREIGNIS-SITZUNG ERSTELLEN [BadPageSplits] AUF SERVER EREIGNIS HINZUFÜGEN sqlserver.transaction_log (WHERE operation =11 AND database_id =10) ZIEL HINZUFÜGEN package0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source ='alloc_unit_id' );GOALTER EVENT SESSION [BadPageSplits] ON SERVER STATE =START;GO
Und die Abfrage, mit der ich es gezeichnet habe:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; Und hier sind die Ergebnisse (zum Vergrößern anklicken):
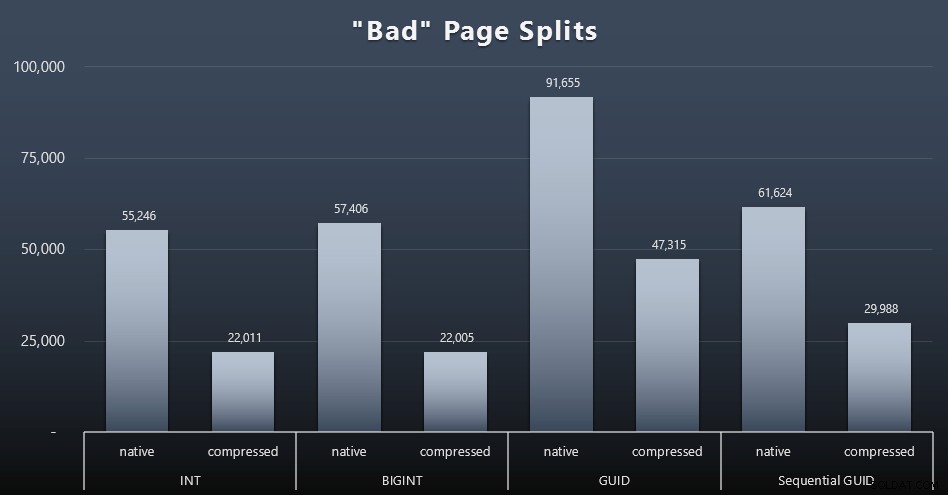
Obwohl ich bereits angemerkt habe, dass in meinem Szenario (wo ich auf schnellen SSDs laufe) der unbestreitbare Unterschied in der E/A-Aktivität keinen direkten Einfluss auf die Gesamtlaufzeit hat, ist dies dennoch eine Metrik, die Sie berücksichtigen sollten – insbesondere wenn Sie keine SSDs haben oder Ihre Workload bereits E/A-gebunden ist.
Schlussfolgerung
Während diese Tests mir die Augen etwas darüber geöffnet haben, wie meine langjährigen Wahrnehmungen durch modernere Hardware verändert wurden, bin ich immer noch ziemlich entschieden dagegen, Speicherplatz auf der Festplatte oder im Arbeitsspeicher zu verschwenden. Während ich versucht habe, ein gewisses Gleichgewicht zu demonstrieren und GUIDs glänzen zu lassen, gibt es hier aus Leistungssicht sehr wenig, um den Wechsel von INT/BIGINT zu einer der beiden Formen von UNIQUEIDENTIFIER zu unterstützen – es sei denn, Sie benötigen es aus anderen, weniger greifbaren Gründen (z. B. zum Erstellen des Schlüssels in der Anwendung oder Pflege eindeutiger Schlüsselwerte über unterschiedliche Systeme hinweg). Eine kurze Zusammenfassung, die zeigt, dass NEWID() bei vielen Metriken, bei denen es einen wesentlichen Unterschied gab, die schlechteste Wahl ist (und in den meisten dieser Fälle lag NEWSEQUENTIALID() dicht an zweiter Stelle)):
| Metrik | Klare Verlierer? |
|---|---|
| Unangefochtene Beilagen | – Unentschieden – |
| Gleichzeitige Arbeitslast | – Unentschieden – |
| Einzelne Suchanfragen – Population | INT (komprimiert) |
| Einzelabfragen – Paging | NEWID() / NEWSEQUENTIALID() |
| Einzelabfragen – Update | INT (nativ) / BIGINT (komprimiert) |
| Einzelabfragen – NACH Trigger | – Unentschieden – |
| Speicherplatz | NEWID() |
| Clustered-Index-Fragmentierung | NEWID() |
| Pufferpoolnutzung | NEWID() |
| tempdb-Nutzung | NEWID() |
| „Schlechte“ Seitenteilungen | NEWID() |
Tabelle 2:Größte Verlierer
Fühlen Sie sich frei, diese Dinge selbst zu testen; Ich kann meinen vollständigen Satz von Skripten zusammenstellen, wenn Sie sie in Ihrer eigenen Umgebung ausführen möchten. Der kurzatmige Zweck dieses gesamten Beitrags ist ganz einfach:Abgesehen von den vorhersehbaren Auswirkungen auf den Speicherplatz müssen viele wichtige Metriken berücksichtigt werden, daher sollte er nicht allein als Argument in beide Richtungen verwendet werden.
Nun, ich möchte nicht, dass diese Denkweise auf Schlüssel per se beschränkt wird. Es sollte wirklich darüber nachgedacht werden, wenn eine Datentypauswahl getroffen wird. Ich sehe datetime oft gewählt, zum Beispiel wenn nur ein date oder smalldatetime wird gebraucht. Bei Transaktionstabellen kann dies ebenfalls zu viel verschwendetem Speicherplatz führen, und dies sickert auch auf einige dieser anderen Ressourcen herunter.
In einem zukünftigen Test möchte ich die Ergebnisse für eine viel größere Tabelle (> 2 Milliarden Zeilen) vergleichen. Ich kann dies mit INT simulieren, indem ich den Identitätsstartwert auf -2 Milliarden setze, was ~4 Milliarden Zeilen zulässt. Und ich möchte, dass die Workload- und Speicherplatz-/Speicherbedarfsvergleiche mehr als eine einzelne Tabelle umfassen, da einer der Vorteile eines dünnen Schlüssels darin besteht, dass dieser Schlüssel in Dutzenden verwandter Tabellen dargestellt wird. Ich habe auf Autogrow-Ereignisse überwacht, aber es gab keine, da die Datenbank groß genug vordimensioniert war, um das Wachstum aufzunehmen, und ich nicht daran gedacht habe, die tatsächliche Protokollnutzung in der vorhandenen Protokolldatei zu messen, also würde ich es gerne testen wieder mit den Standardwerten für Protokollgröße und automatisches Wachstum, und dieses Mal wird DBCC SQLPERF(LOGSPACE); gemessen . Es wäre auch interessant, Rebuilds zu timen und die Protokollnutzung als Ergebnis dieser Vorgänge zu messen. Schließlich möchte ich E/A zu einem relevanteren Faktor machen, indem ich einen Server mit mechanischen Festplatten finde – ich weiß, dass es viele gibt, aber in einigen Geschäften sind sie ziemlich knapp.