Spark wurde 2009 als Projekt innerhalb des AMPLab an der University of California, Berkeley, ins Leben gerufen. Genauer gesagt entstand es aus der Notwendigkeit, das ebenfalls im AMPLab entstandene Konzept von Mesos zu erproben. Spark wurde erstmals im Mesos-Whitepaper mit dem Titel Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center diskutiert, das vor allem von Benjamin Hindman und Matei Zaharia verfasst wurde.
Es entwickelte sich zu einer schnellen und bequemen Lösung zur Durchführung komplexer Analysen umfangreicher Daten. Spark hat sich als neues Verarbeitungsframework für Big Data entwickelt, das viele der Mängel im MapReduce-Modell behebt. Es unterstützt die Datenanalyse im großen Maßstab, und die Daten können aus verschiedenen Quellen wie Echtzeit, Stapelverarbeitung in verschiedenen Formaten wie Bildern, Texten, Grafiken und vielem mehr stammen. Zusätzlich zu seinem Apache Spark-Kern bietet es auch einige nützliche Bibliotheken für Big-Data-Analysen.
Überblick über Spark-Komponenten
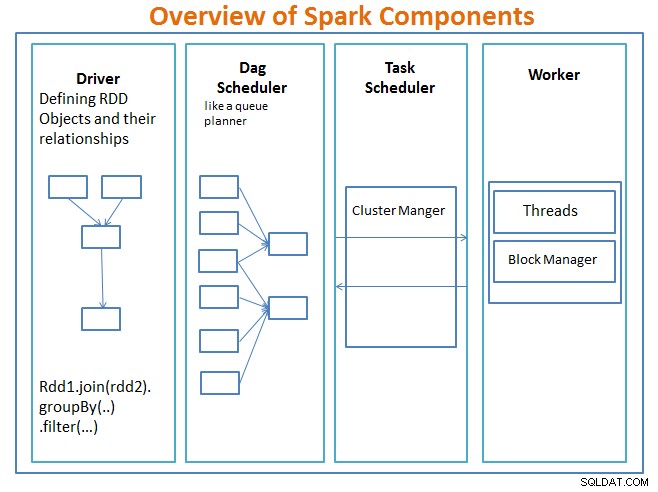
Der Fahrer ist der Code, der die Hauptfunktion enthält und die belastbaren verteilten Datensätze (RDDs) und ihre Transformationen definiert. RDDs sind die Hauptdatenstrukturen, die in unseren Spark-Programmen verwendet werden.
Parallele Operationen auf den RDDs werden an den DAG-Scheduler gesendet , wodurch der Code optimiert wird und ein effizienter DAG entsteht, der die Datenverarbeitungsschritte in der Anwendung darstellt.
Der resultierende DAG wird an den Cluster-Manager gesendet und der Cluster-Manager verfügt über Informationen über die Worker, zugewiesene Threads und den Speicherort von Datenblöcken und ist für die Zuweisung bestimmter Verarbeitungsaufgaben an Worker verantwortlich. Es wickelt auch die Palyback-Funktion ab, falls ein Worker ausfällt. Der Cluster-Manager kann YARN, Mesos, der Cluster-Manager von Spark sein.
Der Worker erhält zu verwaltende Arbeitseinheiten und Daten, und der Worker führt seine spezifische Aufgabe ohne Kenntnis der gesamten DAG aus, und seine Ergebnisse werden an die Treiberanwendungen zurückgesendet.
Spark ist wie andere Big-Data-Tools leistungsstark, leistungsfähig und gut geeignet, um eine Reihe von Datenherausforderungen zu bewältigen. Spark ist, wie andere Big-Data-Technologien, nicht unbedingt die beste Wahl für jede Datenverarbeitungsaufgabe.
In Teil 2 werden wir über die Grundlagen von Spark-Konzepten wie Resilient Distributed Datasets, Shared Variables, SparkContext, Transformations, Action sprechen , und Vorteile der Verwendung von Spark zusammen mit Beispielen und wann Spark verwendet werden sollte.
Referenz:
Lernen Sie Spark an einem Tag von Academy &Hadoop Application Architectures kennen.