Der Produktionsstart ist eine sehr wichtige Aufgabe, die im Vorfeld sorgfältig durchdacht und geplant werden muss. Einige nicht so gute Entscheidungen lassen sich im Nachhinein leicht korrigieren, andere wiederum nicht. Es ist also immer besser, diese zusätzliche Zeit damit zu verbringen, die offiziellen Dokumente, Bücher und Recherchen anderer zu lesen, als sich später zu entschuldigen. Dies gilt für die meisten Bereitstellungen von Computersystemen, und PostgreSQL ist keine Ausnahme.
Erste Systemplanung
Einige Entscheidungen müssen frühzeitig getroffen werden, bevor das System live geht. Der PostgreSQL-DBA muss eine Reihe von Fragen beantworten:Läuft die DB auf Bare Metal, VMs oder sogar containerisiert? Wird es in den Räumlichkeiten der Organisation oder in der Cloud ausgeführt? Welches Betriebssystem wird verwendet? Handelt es sich bei dem Speicher um rotierende Festplatten oder um SSDs? Für jedes Szenario oder jede Entscheidung gibt es Vor- und Nachteile, und die endgültige Entscheidung wird in Zusammenarbeit mit den Interessengruppen gemäß den Anforderungen der Organisation getroffen. Traditionell wurde PostgreSQL auf Bare-Metal ausgeführt, aber dies hat sich in den letzten Jahren dramatisch geändert, da immer mehr Cloud-Anbieter PostgreSQL als Standardoption anbieten, was ein Zeichen für die breite Akzeptanz und die zunehmende Popularität von PostgreSQL ist. Unabhängig von der konkreten Lösung muss der DBA sicherstellen, dass die Daten sicher sind, d. h. dass die Datenbank Abstürze überstehen kann, und dies ist das Kriterium Nr. 1 bei Entscheidungen über Hardware und Speicher. Das bringt uns also zum ersten Tipp!
Tipp 1
Egal womit der Disk-Controller oder Disk-Hersteller oder Cloud-Storage-Anbieter wirbt, man sollte immer darauf achten, dass der Storage nicht über fsync lügt. Sobald fsync OK zurückgibt, sollten die Daten auf dem Medium sicher sein, egal was danach passiert (Absturz, Stromausfall usw.). Ein nettes Tool, mit dem Sie die Zuverlässigkeit des Write-Back-Cache Ihrer Festplatten testen können, ist diskchecker.pl.
Lesen Sie einfach die Notizen:https://brad.livejournal.com/2116715.html und machen Sie den Test.
Verwenden Sie eine Maschine zum Abhören von Ereignissen und die eigentliche Maschine zum Testen. Sie sollten sehen:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0am Ende des Berichtes über die getestete Maschine.
Die zweite Sorge nach der Zuverlässigkeit sollte die Leistung sein. Entscheidungen über das System (CPU, Speicher) waren früher viel wichtiger, da es ziemlich schwierig war, sie später zu ändern. Aber in der heutigen Cloud-Ära können wir flexibler sein, was die Systeme betrifft, auf denen die DB läuft. Dasselbe gilt für die Speicherung, insbesondere in der Anfangsphase eines Systems und solange die Größen noch klein sind. Wenn die DB die Größe von TB überschreitet, wird es immer schwieriger, grundlegende Speicherparameter zu ändern, ohne die Datenbank vollständig kopieren zu müssen - oder noch schlimmer, ein pg_dump, pg_restore durchzuführen. Der zweite Tipp betrifft die Systemleistung.
Tipp 2
Ähnlich wie Sie immer die Versprechen der Hersteller in Bezug auf die Zuverlässigkeit testen, sollten Sie dasselbe in Bezug auf die Hardwareleistung tun. Bonnie++ ist der beliebteste Speicherleistungs-Benchmark für Unix-ähnliche Systeme. Für das Testen des Gesamtsystems (CPU, Speicher und auch Speicher) ist nichts repräsentativer als die Leistung der DB. Der grundlegende Leistungstest auf Ihrem neuen System würde also pgbench ausführen, die offizielle PostgreSQL-Benchmark-Suite basierend auf TCP-B.
Die ersten Schritte mit pgbench sind ziemlich einfach, alles, was Sie tun müssen, ist:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Sie sollten pgbench immer nach jeder wichtigen Änderung konsultieren, die Sie bewerten und die Ergebnisse vergleichen möchten.
Systembereitstellung, Automatisierung und Überwachung
Sobald Sie live gehen, ist es sehr wichtig, dass Ihre wichtigsten Systemkomponenten dokumentiert und reproduzierbar sind, automatisierte Verfahren zum Erstellen von Diensten und wiederkehrenden Aufgaben haben und auch über die Tools verfügen, um eine kontinuierliche Überwachung durchzuführen.
Tipp 3
Eine praktische Möglichkeit, mit der Verwendung von PostgreSQL mit all seinen erweiterten Unternehmensfunktionen zu beginnen, ist ClusterControl von Multiplenines. Man kann einen PostgreSQL-Cluster der Enterprise-Klasse haben, indem man nur ein paar Klicks drückt. ClusterControl bietet all diese oben genannten Dienste und viele mehr. Das Einrichten von ClusterControl ist ziemlich einfach, befolgen Sie einfach die Anweisungen in der offiziellen Dokumentation. Sobald Sie Ihre Systeme vorbereitet haben (normalerweise eines für die Ausführung von CC und eines für PostgreSQL für eine grundlegende Einrichtung) und die SSH-Einrichtung durchgeführt haben, müssen Sie die grundlegenden Parameter (IPs, Portnummern usw.) eingeben, und wenn alles gut geht, sollten Sie dies tun sehen Sie eine Ausgabe wie die folgende:
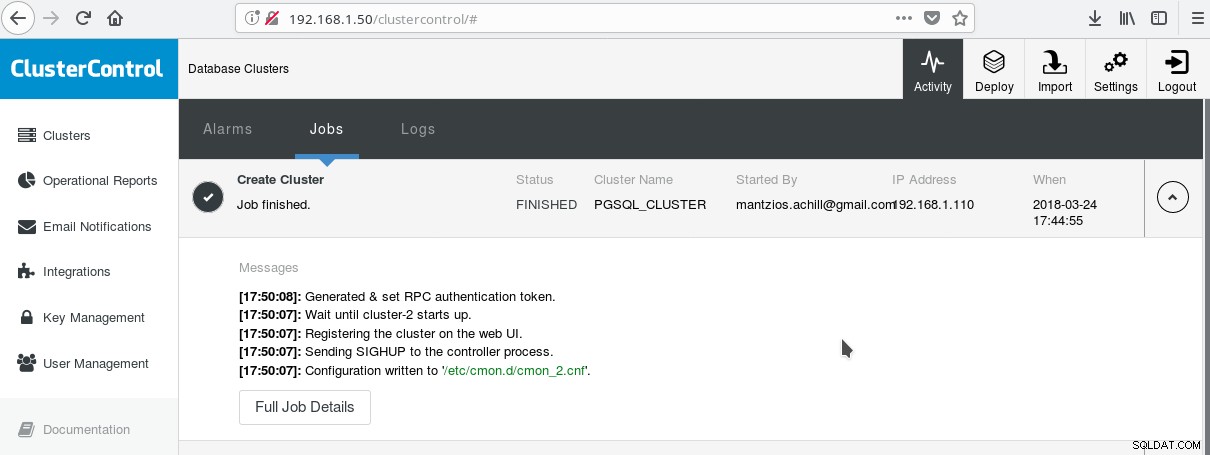
Und im Hauptbildschirm der Cluster:
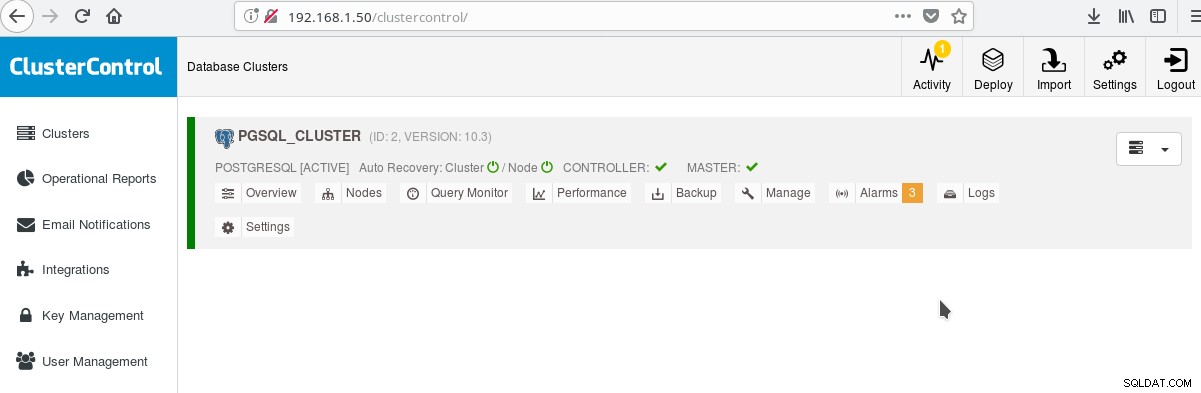
Sie können sich bei Ihrem Master-Server anmelden und mit der Erstellung Ihres Schemas beginnen! Natürlich können Sie den soeben erstellten Cluster als Grundlage für den weiteren Aufbau Ihrer Infrastruktur (Topologie) verwenden. Eine allgemein gute Idee ist es, ein stabiles Server-Dateisystem-Layout und eine endgültige Konfiguration auf Ihrem PostgreSQL-Server und Ihren Benutzer-/App-Datenbanken zu haben, bevor Sie beginnen, Klone und Standbys (Slaves) basierend auf Ihrem gerade erstellten brandneuen Server zu erstellen.
PostgreSQL-Layout, Parameter und Einstellungen
In der Initialisierungsphase des Clusters ist die wichtigste Entscheidung, ob Datenprüfsummen auf Datenseiten verwendet werden sollen oder nicht. Wenn Sie maximale Datensicherheit für Ihre wertvollen (zukünftigen) Daten wünschen, dann ist jetzt der richtige Zeitpunkt dafür. Wenn die Möglichkeit besteht, dass Sie dieses Feature in Zukunft möchten und es zu diesem Zeitpunkt versäumen, können Sie es später nicht mehr ändern (ohne pg_dump/pg_restore). Das ist der nächste Tipp:
Tipp 4
Um Datenprüfsummen zu aktivieren, führen Sie initdb wie folgt aus:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Beachten Sie, dass dies zum Zeitpunkt des oben beschriebenen Tipp 3 erfolgen sollte. Wenn Sie den Cluster bereits mit ClusterControl erstellt haben, müssen Sie pg_createcluster erneut von Hand ausführen, da es zum Zeitpunkt des Schreibens dieses Artikels keine Möglichkeit gibt, dem System oder CC mitzuteilen, dass diese Option enthalten sein soll.
Ein weiterer sehr wichtiger Schritt, bevor Sie in die Produktion gehen, ist die Planung des Layouts des Serverdateisystems. Die meisten modernen Linux-Distributionen (zumindest die Debian-basierten) mounten alles auf /, aber mit PostgreSQL möchten Sie das normalerweise nicht. Es ist vorteilhaft, Ihre Tablespaces auf separaten Volumes zu haben, um ein Volume für die WAL-Dateien und ein anderes für pg log zu haben. Das Wichtigste ist jedoch, die WAL auf eine eigene Festplatte zu verschieben. Das bringt uns zum nächsten Tipp.
Tipp 5
Mit PostgreSQL 10 auf Debian Stretch können Sie Ihre WAL mit den folgenden Befehlen auf eine neue Festplatte verschieben (vorausgesetzt, die neue Festplatte heißt /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlEs ist äußerst wichtig, das Gebietsschema und die Kodierung Ihrer Datenbanken korrekt einzurichten. Wenn Sie dies in der „createb“-Phase übersehen, werden Sie dies sehr bereuen, da Ihre App/DB in die i18n-, l10n-Gebiete verschoben wird. Wie das geht, zeigt der nächste Tipp.
Tipp 6
Sie sollten die offiziellen Dokumente lesen und sich für Ihre COLLATE- und CTYPE-Einstellungen (createdb --locale=) (verantwortlich für die Sortierreihenfolge und Zeichenklassifizierung) sowie die Einstellung für den Zeichensatz (createdb --encoding=) entscheiden. Wenn Sie UTF8 als Codierung angeben, kann Ihre Datenbank mehrsprachigen Text speichern.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterPostgreSQL-Hochverfügbarkeit
Seit PostgreSQL 9.0, als die Streaming-Replikation zu einer Standardfunktion wurde, wurde es möglich, einen oder mehrere schreibgeschützte Hot-Standbys zu haben, wodurch die Möglichkeit geschaffen wurde, den schreibgeschützten Datenverkehr an einen der verfügbaren Slaves zu leiten. Es gibt neue Pläne für die Multimaster-Replikation, aber zum Zeitpunkt der Erstellung dieses Dokuments (10.3) ist es zumindest im offiziellen Open-Source-Produkt nur möglich, einen Read-Write-Master zu haben. Für den nächsten Tipp, der sich genau damit beschäftigt.
Tipp 7
Wir werden unser in Tipp 3 erstelltes ClusterControl PGSQL_CLUSTER verwenden. Zuerst erstellen wir einen zweiten Computer, der als unser schreibgeschützter Slave fungiert (Hot Standby in der PostgreSQL-Terminologie). Dann klicken wir auf Replikations-Slave hinzufügen und wählen unseren Master und den neuen Slave aus. Nach Abschluss des Jobs sollten Sie diese Ausgabe sehen:
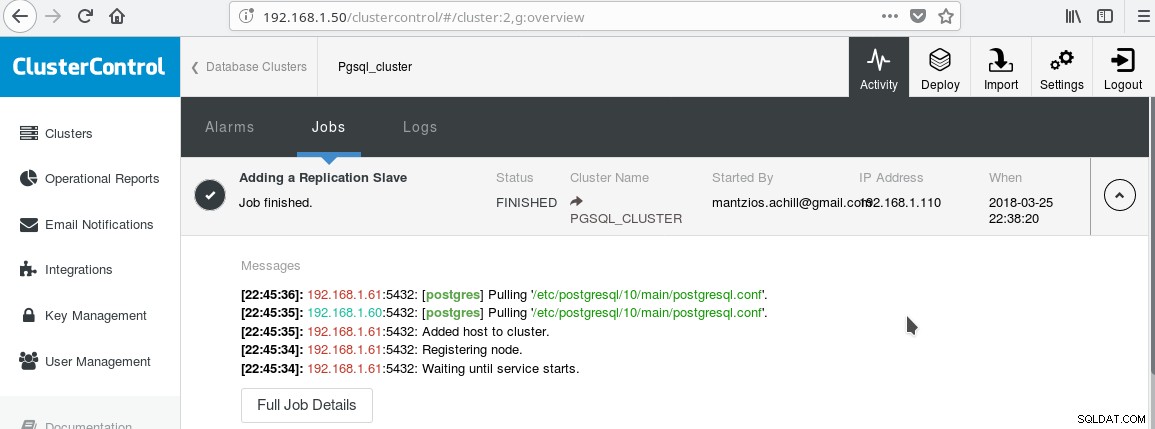
Und der Cluster sollte jetzt so aussehen:
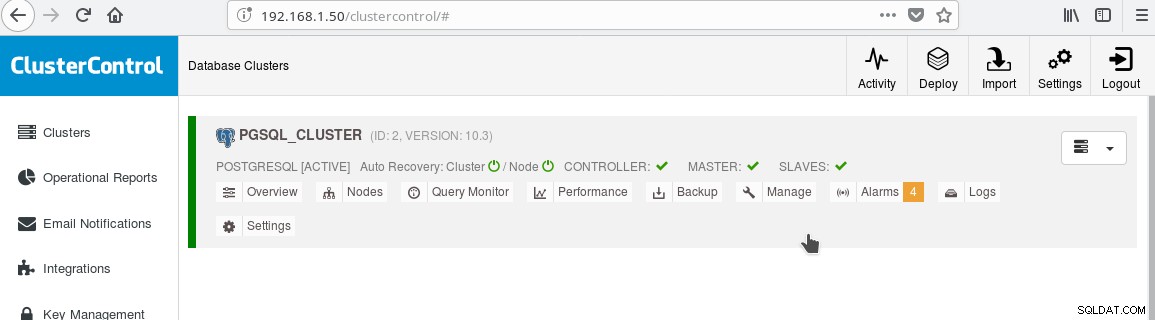
Beachten Sie das grüne „Häkchen“-Symbol auf dem „SLAVES“-Label neben „MASTER“. Sie können überprüfen, ob die Streaming-Replikation funktioniert, indem Sie ein Datenbankobjekt (Datenbank, Tabelle usw.) erstellen oder einige Zeilen in eine Tabelle auf dem Master einfügen und die Änderung auf dem Standby sehen.
Das Vorhandensein des Nur-Lese-Standby ermöglicht es uns, einen Lastausgleich für die Clients durchzuführen, die Nur-Auswahl-Abfragen zwischen den beiden verfügbaren Servern, dem Master und dem Slave, durchführen. Damit kommen wir zu Tipp 8.
Tipp 8
Sie können den Lastenausgleich zwischen den beiden Servern mit HAProxy aktivieren. Mit ClusterControl geht das ziemlich einfach. Sie klicken auf Manage->Load Balancer. Nachdem Sie Ihren HAProxy-Server ausgewählt haben, installiert ClusterControl alles für Sie:xinetd auf allen von Ihnen angegebenen Instanzen und HAProxy auf Ihrem von HAProxy designierten Server. Nachdem der Auftrag erfolgreich abgeschlossen wurde, sollten Sie Folgendes sehen:
Beachten Sie das grüne HAPROXY-Häkchen neben den SLAVES. Jetzt können Sie testen, ob HAProxy funktioniert:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Tipp 9
Neben der Konfiguration für HA und Load Balancing ist es immer von Vorteil, eine Art Verbindungspool vor dem PostgreSQL-Server zu haben. Pgpool und Pgbouncer sind zwei Projekte aus der PostgreSQL-Community. Viele Unternehmensanwendungsserver stellen auch ihre eigenen Pools bereit. Pgbouncer ist aufgrund seiner Einfachheit, Geschwindigkeit und der Funktion „Transaktionspooling“ sehr beliebt, mit der die Verbindung zum Server nach Beendigung der Transaktion freigegeben wird, wodurch sie für nachfolgende Transaktionen wiederverwendet werden kann, die aus derselben oder einer anderen Sitzung stammen können . Die Transaktionspooling-Einstellung unterbricht einige Sitzungspooling-Funktionen, aber im Allgemeinen ist die Umstellung auf ein „Transaktionspooling“-fähiges Setup einfach und die Nachteile sind im Allgemeinen nicht so wichtig. Ein gängiges Setup besteht darin, den Pool des App-Servers mit semipersistenten Verbindungen zu konfigurieren:Ein eher größerer Pool von Verbindungen pro Benutzer oder pro App (die sich mit pgbouncer verbinden) mit langen Leerlaufzeiten. Auf diese Weise ist die Verbindungszeit von der App minimal, während pgbouncer dazu beiträgt, die Verbindungen zum Server so gering wie möglich zu halten.
Eine Sache, die höchstwahrscheinlich von Bedeutung sein wird, sobald Sie mit PostgreSQL live gehen, ist das Verstehen und Beheben langsamer Abfragen. Die Überwachungstools, die wir im vorherigen Blog erwähnt haben, wie pg_stat_statements, und auch die Bildschirme von Tools wie ClusterControl helfen Ihnen dabei, Ideen zur Behebung langsamer Abfragen zu identifizieren und möglicherweise vorzuschlagen. Sobald Sie jedoch die langsame Abfrage identifiziert haben, müssen Sie EXPLAIN oder EXPLAIN ANALYZE ausführen, um genau die Kosten und Zeiten zu sehen, die mit dem Abfrageplan verbunden sind. Der nächste Tipp handelt von einem sehr nützlichen Tool, um dies zu tun.
Tipp 10
Sie müssen Ihre EXPLAIN ANALYZE in Ihrer Datenbank ausführen und dann die Ausgabe kopieren und in das Online-Tool „Explain Analysis“ von depesz einfügen und auf „Senden“ klicken. Dann sehen Sie drei Registerkarten:HTML, TEXT und STATS. HTML enthält Kosten, Zeit und Anzahl der Schleifen für jeden Knoten im Plan. Die Registerkarte STATS zeigt Statistiken pro Knotentyp. Sie sollten die Spalte „% der Abfrage“ beobachten, damit Sie wissen, wo Ihre Abfrage genau leidet.
Wenn Sie sich mit PostgreSQL vertraut machen, werden Sie selbst viele weitere Tipps finden!



