Im Jahr 2014 habe ich hier eine Reihe von Blogbeiträgen gestartet, um über bestimmte Wartetypen zu sprechen und was sie tun und was nicht. Das brachte mich auf die Idee, die Wait- und Latch-Bibliotheken zu erstellen, die ich betreue (mehr dazu später).
Wenn Sie dies lesen und denken:"Wovon redet er?" dann ist dieser Beitrag für dich. Ich werde Ihnen Wartestatistiken vorstellen und erklären, wie wichtig sie für die Fehlerbehebung bei der Arbeitslastleistung in SQL Server sind.
Planung
Die Ausführung des internen Codes von SQL Server erfolgt mithilfe eines Mechanismus namens Threads . Jeder Thread kann SQL Server-Code ausführen, und mehrere Threads koordinieren zusammen, wenn eine Abfrage parallel ausgeführt wird. Diese Threads werden erstellt, wenn SQL Server gestartet wird, abhängig von der Anzahl der für SQL Server verfügbaren Prozessorkerne.
Threads werden in einem Scheduler platziert wenn eine Abfrage beginnt, mit einem Scheduler pro Prozessorkern, und verlassen Sie diesen Scheduler nicht, bis die Abfrage beendet ist. Ein Planer besteht aus drei grundlegenden „Teilen“:
- Der Prozessor , die genau einen Thread hat, der gerade Code ausführt.
- Die Warteliste , das alle Threads enthält, die im Grunde feststecken und darauf warten, dass eine bestimmte Ressource verfügbar wird.
- Die ausführbare Warteschlange , die alle Threads enthält, die ausgeführt werden können, aber darauf warten, auf den Prozessor zu gelangen.
Threads wechseln von Zustand 1 zu 2 zu 3 zu 1, so lange, bis die Abfrage beendet ist.
Wartet
Aus unserer Sicht ist der interessanteste Teil der Planung, wenn ein Thread auf eine Ressource warten muss, bevor er fortfahren kann. Einige Beispiele hierfür sind:
- Ein Thread muss eine Seite lesen, und die Seite befindet sich nicht im Speicher, sodass der Thread eine asynchrone physische E/A ausgibt und dann außerhalb des Prozessors warten muss, bis die E/A abgeschlossen ist.
- Ein Thread muss eine gemeinsame Sperre für eine Zeile erwerben, um sie zu lesen, aber ein anderer Thread hält bereits eine widersprüchliche exklusive Sperre, während er die Zeile aktualisiert.
Wenn ein Thread feststellt, dass eine Ressource benötigt wird, die er nicht abrufen kann, hat er keine andere Wahl, als anzuhalten und zu warten, bis die Ressource verfügbar wird (der Mechanismus, mit dem der Thread über die Ressourcenverfügbarkeit benachrichtigt wird, würde den Rahmen dieses Artikels sprengen). Wenn das passiert, notiert sich SQL Server, warum der Thread warten musste, und dies wird als Wartetyp bezeichnet . Einige Beispiele hierfür sind:
- Wenn ein Thread darauf wartet, dass eine Seite in den Speicher gelesen wird, damit sie gelesen werden kann, ist der Wartetyp PAGEIOLATCH_SH (Wenn der Thread auf eine Seite wartet, die er ändern wird, ist der Wartetyp PAGEIOLATCH_EX ).
- Wenn ein Thread auf eine Freigabesperre für eine Zeile wartet, ist der Wartetyp LCK_M_S (Sperrmodus-Freigabe)
SQL Server verfolgt auch, wie lange der Thread warten muss. Dies wird als Ressourcenwartezeit bezeichnet , und wird normalerweise nur als Wartezeit bezeichnet .
Wartestatistik
Der Gesamtsatz von Metriken darüber, wie viele Threads auf welche Ressourcen gewartet haben und wie lange im Durchschnitt, wird als Wartestatistik bezeichnet . Diese Informationen sind äußerst nützlich für die Fehlerbehebung bei der Workload-Leistung, da Sie leicht erkennen können, wo Leistungsengpässe liegen könnten.
Die Grundidee ist, dass SQL Server die Informationen darüber hat, warum Threads anhalten und warten müssen und worauf sie warten. Anstatt also raten zu müssen, wo Sie mit der Fehlerbehebung beginnen sollten, kann Ihnen eine sorgfältige Analyse der Wartezeitstatistiken in der Regel die Richtung weisen, die Sie einschlagen sollten.
Zum Beispiel, wenn die Mehrheit der Wartezeiten auf dem Server PAGEIOLATCH_SH sind , kann dies darauf hindeuten, dass auf dem Server Speichermangel herrscht oder dass Abfragen große Tabellenscans durchführen, anstatt Nonclustered-Indizes zu verwenden, oder dass ein Problem mit dem zugrunde liegenden E/A-Subsystem vorliegt, oder eine Reihe anderer Gründe.
Es gibt eine große Anzahl von Wartetypen, aber die meisten davon tauchen nicht sehr oft auf, also gibt es einen Kernsatz, den Sie immer wieder auf Ihren Servern sehen werden. Es ist wichtig zu verstehen, was diese bedeuten und wie man sie untersucht, damit Sie nicht dem erliegen, was ich als „knieruckartiges Leistungstuning“ bezeichne, und Zeit und Mühe verschwenden, wenn Sie versuchen, ein Problem zu beheben, das eigentlich kein Problem ist. Ich habe hier eine Reihe von Blog-Posts geschrieben, die dort auf Details eingehen, und Aaron Bertrand hat letztes Jahr auch einen zusammenfassenden Post der Top-10-Wartestatistiken geschrieben.
Nachverfolgung von Wartezeiten
Es gibt verschiedene Möglichkeiten, Wartezeiten zu verfolgen. Am einfachsten ist es, sich anzusehen, welche Wartezeiten gerade auf dem Server auftreten, indem Sie ein Skript verwenden, das die sys.dm_os_waiting_tasks untersucht DMV. Hier finden Sie ein Skript dafür, das automatisch URLs in die Wartebibliothek generiert.
Eine andere Möglichkeit besteht darin, die aggregierten Wartestatistiken für den gesamten Server mit einem Skript zu betrachten, das die sys.dm_os_wait_stats untersucht DMV. Hier finden Sie ein Skript dafür, das automatisch URLs in die Wait-Bibliothek generiert. Sie müssen bei dieser Methode jedoch vorsichtig sein, da dadurch alle Wartezeiten angezeigt werden, die seit dem Start des Servers aufgetreten sind. Ein besserer Weg ist, Wartezeiten über kleine Intervalle zu verfolgen, sagen wir eine halbe Stunde, und ein Skript, um das zu tun, ist hier.
Sie können Wartestatistiken auch mit dem Server Reports-Add-In für das neue Azure Data Studio-Tool und mit dem Abfragespeicher ab SQL Server 2017 abrufen.
Denken Sie daran, dass Sie immer noch verstehen müssen, was die Wartetypen bedeuten, nachdem Sie die Metriken erfasst haben.
Wartet auf Ressourcen
Um dies zu unterstützen, und da Microsoft keine Dokumentation zur Interpretation von Wartestatistiken hat, habe ich 2016 eine Wartetypbibliothek mit Details zu Hunderten gängiger Wartetypen und deren Fehlerbehebung veröffentlicht. Sie erreichen die Bibliothek unter https://www.SQLskills.com/help/waits. Und dann hat SentryOne 2017 ein automatisiertes System erstellt, um eine Infografik für jede Seite in der Bibliothek bereitzustellen, mit der Sie schnell sehen können, ob der Wartetyp, an dem Sie interessiert sind, wirklich häufig vorkommt oder nicht (siehe diesen Beitrag für Details). . Unten finden Sie eine Beispielinfografik für PAGEIOLATCH_SH Wartetyp:
Auf der horizontalen Achse ist eine Skala (umschaltbar zwischen linear und logarithmisch) des Prozentsatzes der Instanzen (von SentryOne fernüberwacht) dargestellt, bei denen diese Wartezeit im vorangegangenen Kalendermonat aufgetreten ist, und auf der vertikalen Achse ist der Prozentsatz der Zeit angegeben, in der diese Instanzen dies erlebt haben wait hatte tatsächlich einen Thread, der auf diesen Wait-Typ wartete.
Eine weitere Ressource, die Ihnen hilft, Wartezeiten zu verstehen, ist ein Online-Schulungskurs, den ich für Pluralsight aufgezeichnet habe – siehe hier.
Sie sollten sich zumindest die verschiedenen Blog-Beiträge in den Abschnitten Wartestatistiken und Wartezeitverfolgung weiter oben durchlesen.
Nachverfolgung von Wartezeiten mit SentryOne-Tools
SQL Sentry verfolgt Wartezeiten auf Instanzebene im Laufe der Zeit automatisch für Sie, sodass Sie keine hohen Wartezeiten „auf frischer Tat“ erwischen müssen. Jemand hat sich gestern Nachmittag über ein träges System oder einen Bericht beschwert, der letzten Dienstag abgelaufen ist? Kein Problem. Sie können sich alle Wartezeiten für jeden beliebigen Zeitpunkt oder über einen bestimmten Bereich ansehen und sie mit verschiedenen anderen zu diesem Zeitpunkt gesammelten Leistungskennzahlen korrelieren – seien es andere Trends auf dem Dashboard, wie Backup- oder Datenbank-E/A-Aktivität, bis hin zu allen die wichtigsten SQL-Befehle, die im selben Fenster ausgeführt wurden, um lang anhaltende Blockierungen zu untersuchen, oder verwenden Sie Baselines, um das Warteprofil mit anderen Zeiträumen zu vergleichen.
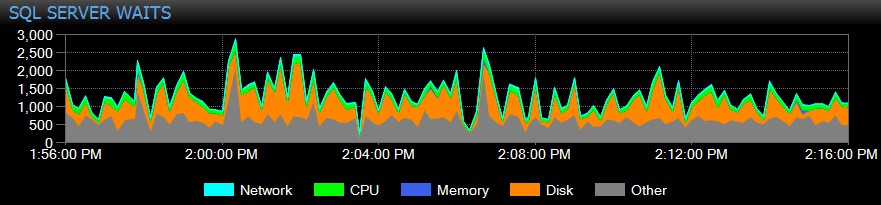
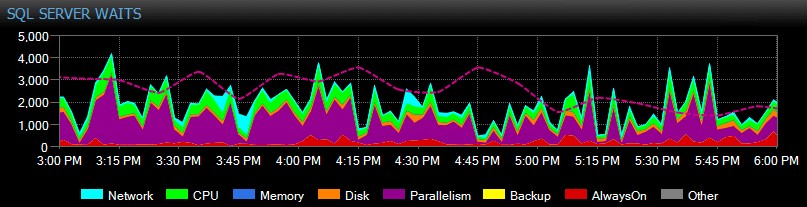
Sie können sogar erfasste oder nicht erfasste Wartezeiten anpassen, die visuell dargestellten Kategorien ändern und intelligente Warnmeldungen und/oder Reaktionen auf bestimmte Warteszenarien erstellen. Viele unserer Kunden verwenden SQL Sentry, um sich auf echte Leistungsprobleme im Zusammenhang mit Wartezeiten zu konzentrieren, da es ihnen ermöglicht, einen Großteil des Rauschens zu ignorieren, das nur normale SQL Server-Thread-Aktivität ist.
Zusammenfassung
Wie Sie den obigen Informationen entnehmen können, treten in SQL Server immer Wartezeiten auf, da Thread-Scheduling und Multithread-Systeme genau so funktionieren. Sie sind eines der leistungsstärksten Tools in Ihrer Toolbox zur Fehlerbehebung. Wenn Sie sie also noch nicht verwenden, ist es jetzt an der Zeit, damit zu beginnen. Die Lernkurve ist kurz und steil – nachdem Sie die verschiedenen Abfragen und Tools ein paar Mal ausgeführt haben, haben Sie schnell den Dreh raus, und dann müssen Sie die Anleitungen für die Wartezeiten, die Sie sehen, durchlesen und Bestimmen, ob sie ein Problem sind oder nicht.
Viel Spaß bei der Fehlerbehebung!