In diesem SQL-Artikel lernen wir die GROUP BY-Klausel und ihre Verwendung in SQL kennen. Wir werden auch die Verwendung der GROUP BY-Klausel mit der WHERE-Klausel besprechen.
Was ist die GROUP BY-Klausel?
Die GROUP BY-Klausel ist eine SQL-Klausel, die in der SELECT-Anweisung verwendet wird, um dieselben Datensätze einer Spalte in der Gruppe mithilfe von SQL-Funktionen zu verwalten.
Syntax der GROUP BY-Klausel:
SELECT columnname1, columnname2, columnname3 FROM tablename GROUP BY columnname;Wir können mehrere Spalten aus der Tabelle in der GROUP BY-Klausel verwenden.
Es gibt einige Schritte, die wir lernen müssen, um die GROUP BY-Klausel in der SQL-Abfrage zu verwenden:
1. Erstellen Sie eine neue Datenbank oder verwenden Sie eine vorhandene Datenbank, indem Sie die Datenbank mit dem Schlüsselwort USE gefolgt vom Datenbanknamen auswählen.
2. Erstellen Sie eine neue Tabelle in der ausgewählten Datenbank oder verwenden Sie eine bereits erstellte Tabelle.
3. Wenn die Tabelle neu erstellt wird, fügen Sie die Datensätze mit der INSERT-Abfrage in die neu erstellte Datenbank ein und zeigen Sie die eingefügten Daten mit der SELECT-Abfrage ohne die GROUP BY-Klausel an.
4. Jetzt können wir die GROUP BY-Klausel in den SQL-Abfragen verwenden.
Schritt 1:Erstellen Sie eine neue Datenbank oder verwenden Sie eine bereits erstellte Datenbank.
Ich habe bereits eine Datenbank erstellt. Ich werde meinen bereits erstellten Datenbanknamen Company.
verwendenUSE Company;
Firma ist der Datenbankname.
Diejenigen, die keine Datenbank erstellt haben, folgen der folgenden Abfrage, um die Datenbank zu erstellen:
CREATE DATABASE database_name;
Nachdem Sie die Datenbank erstellt haben, wählen Sie die Datenbank mit dem Schlüsselwort USE gefolgt vom Datenbanknamen aus.
Schritt 2:Erstellen Sie eine neue Tabelle oder verwenden Sie eine bereits vorhandene Tabelle:
Ich habe bereits eine Tabelle erstellt. Ich werde die vorhandene Tabelle mit dem Namen Employees.
verwendenBefolgen Sie zum Erstellen der neuen Tabellen die folgende CREATE TABLE-Syntax:
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
Schritt 3:Fügen Sie die Datensätze mit der INSERT-Abfrage in die neu erstellte Tabelle ein und zeigen Sie die Datensätze mit der SELECT-Abfrage an.
Verwenden Sie die folgende Syntax, um neue Datensätze in die Tabelle einzufügen:
INSERT INTO table_name VALUES(value1, value2, value3);
Verwenden Sie die folgende Syntax, um die Datensätze aus der Tabelle anzuzeigen:
SELECT * FROM table_name;
Die folgende Abfrage zeigt die Datensätze der Mitarbeiter an:
SELECT * FROM Employees;
Die Ausgabe der obigen SELECT-Abfrage ist:
| MITARBEITERID | FIRST_NAME | NACHNAME | GEHALT | STADT | ABTEILUNG | MANAGERID |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 1002 | VAIBHAV | SHARMA | 60000 | NOIDA | C# | 5 |
| 1003 | NICHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIGARH | ORACLE | 1 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 2003 | RUSCHIKA | JAIN | 50000 | MUMBAI | C# | 5 |
| 3001 | PRANOTI | SCHENDE | 55500 | PUNE | JAVA | 3 |
| 3002 | ANUJA | WANRE | 50500 | JAIPUR | FMW | 2 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4001 | RAJESH | GOLD | 60500 | MUMBAI | TESTEN | 4 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 4003 | RUSCHIKA | AGARWAL | 60000 | DELHI | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTEN | 4 |
| 5002 | SANKET | CHAUHAN | 70000 | HYDERABAD | JAVA | 3 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIGARH | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALORE | TESTEN | 4 |
| 6002 | ATISH | JADHAV | 60500 | BANGALORE | C# | 5 |
| 6003 | NIKITA | INGALE | 65000 | HYDERABAD | ORACLE | 1 |
Schritt 4:Wir sind bereit, die GROUP BY-Klausel in den Abfragen zu verwenden
Wir werden nun anhand von Beispielen tief in die GROUP BY-Klausel eintauchen
Beispiel 1: Schreiben Sie eine Abfrage, um die Mitarbeiterdatensätze nach Stadt anzuzeigen.
SELECT * FROM EMPLOYEES GROUP BY CITY;
Die obige Abfrage zeigt die Mitarbeiterdatensätze an, bei denen ein Mitarbeiter aus derselben Stadt als eine Gruppe betrachtet wird. Beispiel:Wenn in der Tabelle 10 Mitarbeiterdatensätze vorhanden sind, von denen 3 aus der Stadt Pune, 3 aus der Stadt Mumbai, 2 aus Hyderabad und Bangalore stammen, gruppiert die obige Abfrage einen Mitarbeiter der Stadt Pune, einen Mitarbeiter der Stadt Mumbai, und so weiter .
Die Ausgabe der obigen Abfrage:
| MITARBEITERID | FIRST_NAME | NACHNAME | GEHALT | STADT | ABTEILUNG | MANAGERID |
| 6001 | RAHUL | NIKAM | 54500 | BANGALORE | TESTEN | 4 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIGARH | ORACLE | 1 |
| 4003 | RUSCHIKA | AGARWAL | 60000 | DELHI | ORACLE | 1 |
| 5002 | SANKET | CHAUHAN | 70000 | HYDERABAD | JAVA | 3 |
| 1003 | NICHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUSCHIKA | JAIN | 50000 | MUMBAI | C# | 5 |
| 1002 | VAIBHAV | SHARMA | 60000 | NOIDA | C# | 5 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
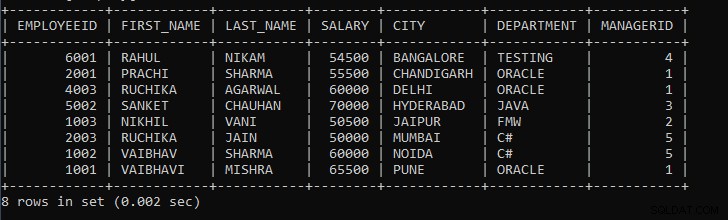
Wie wir sehen können, sind die Datensätze der Mitarbeiter nach Stadt gruppiert und Datensätze werden standardmäßig in aufsteigender Reihenfolge angezeigt.
Beispiel 2: Schreiben Sie eine Abfrage, um Mitarbeiterdatensätze nach Gehalt in absteigender Reihenfolge anzuzeigen.
SELECT * FROM EMPLOYEES GROUP BY SALARY DESC;
Die obige Abfrage zeigt die Datensätze der Mitarbeiter an, wobei Mitarbeiter mit demselben Gehalt als eine Gruppe betrachtet werden und die Datensätze in absteigender Reihenfolge angezeigt werden.
Die Ausgabe der obigen Abfrage:
| MITARBEITERID | FIRST_NAME | NACHNAME | GEHALT | STADT | ABTEILUNG | MANAGERID |
| 5002 | SANKET | CHAUHAN | 70000 | HYDERABAD | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 6003 | NIKITA | INGALE | 65000 | HYDERABAD | ORACLE | 1 |
| 4001 | RAJESH | GOLD | 60500 | MUMBAI | TESTEN | 4 |
| 1002 | VAIBHAV | SHARMA | 60000 | NOIDA | C# | 5 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIGARH | ORACLE | 1 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 1003 | NICHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUSCHIKA | JAIN | 50000 | MUMBAI | C# | 5 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIGARH | C# | 5 |
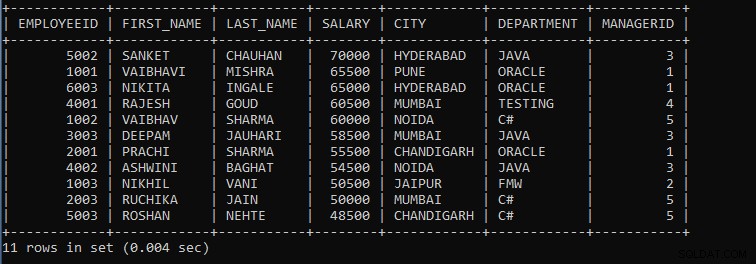
Wie wir sehen können, sind die Datensätze der Mitarbeiter nach Gehalt gruppiert und die Datensätze werden in absteigender Reihenfolge angezeigt, wie wir am Ende desc erwähnen.
Beispiel 3: Schreiben Sie eine Abfrage, um die Datensätze der Mitarbeiter nach Gehalt und Stadt gruppiert anzuzeigen.
SELECT * FROM EMPLOYEES GROUP BY SALARY, CITY;
Die obige Abfrage zeigt die Mitarbeiterdatensätze an, bei denen Mitarbeiter mit demselben Gehalt und derselben Stadt als eine Gruppe betrachtet werden.
Angenommen, die Tabelle enthält 10 Mitarbeiterdatensätze. Ab 10 Mitarbeitern stimmen 2 Mitarbeiter in Gehalt und Stadt mit anderen 2 Mitarbeitern überein und verbleiben 6 Mitarbeiter in Gehalt und Stadt, dann werden die 6 Mitarbeiter als 6 separate Gruppen betrachtet, und 2 Mitarbeiter, die mit anderen 2 Mitarbeitern übereinstimmen, werden als eine Gruppe betrachtet . Kurz gesagt werden 8 Gruppen gebildet.
Die Ausgabe der obigen Abfrage:
| MITARBEITERID | FIRST_NAME | NACHNAME | GEHALT | STADT | ABTEILUNG | MANAGERID |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIGARH | C# | 5 |
| 2003 | RUSCHIKA | JAIN | 50000 | MUMBAI | C# | 5 |
| 1003 | NICHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALORE | TESTEN | 4 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIGARH | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTEN | 4 |
| 3001 | PRANOTI | SCHENDE | 55500 | PUNE | JAVA | 3 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4003 | RUSCHIKA | AGARWAL | 60000 | DELHI | ORACLE | 1 |
| 1002 | VAIBHAV | SHARMA | 60000 | NOIDA | C# | 5 |
| 6002 | ATISH | JADHAV | 60500 | BANGALORE | C# | 5 |
| 4001 | RAJESH | GOLD | 60500 | MUMBAI | TESTEN | 4 |
| 6003 | NIKITA | INGALE | 65000 | HYDERABAD | ORACLE | 1 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 5002 | SANKET | CHAUHAN | 70000 | HYDERABAD | JAVA | 3 |
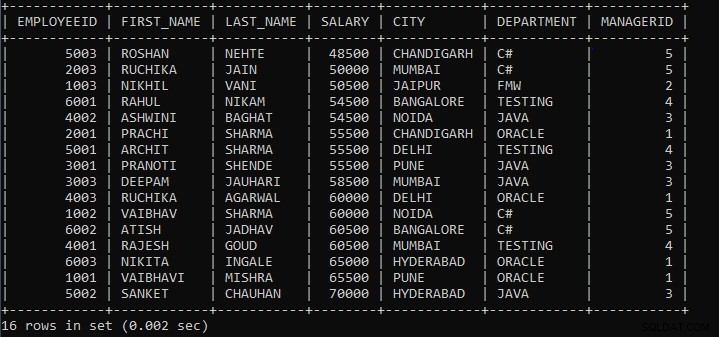
Wie wir sehen können, sind die Datensätze der Mitarbeiter nach Gehalt und Ort gruppiert, und die Datensätze werden standardmäßig in aufsteigender Reihenfolge angezeigt.
Beispiel 4: Schreiben Sie eine Abfrage, um die Datensätze der Mitarbeiter nach Stadt und Abteilung anzuzeigen.
SELECT * FROM EMPLOYEES GROUP BY CITY, DEPARTMENT;
Die obige Abfrage zeigt die Datensätze der Mitarbeiter an, in denen sich Mitarbeiter in derselben Stadt befinden, und die Abteilung wird als eine Gruppe betrachtet.
Die Ausgabe der obigen Abfrage:
| MITARBEITERID | FIRST_NAME | NACHNAME | GEHALT | STADT | ABTEILUNG | MANAGERID |
| 6002 | ATISH | JADHAV | 60500 | BANGALORE | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | BANGALORE | TESTEN | 4 |
| 5003 | ROSHAN | NEHTE | 48500 | CHANDIGARH | C# | 5 |
| 2001 | PRACHI | SHARMA | 55500 | CHANDIGARH | ORACLE | 1 |
| 4003 | RUSCHIKA | AGARWAL | 60000 | DELHI | ORACLE | 1 |
| 5001 | ARCHIT | SHARMA | 55500 | DELHI | TESTEN | 4 |
| 5002 | SANKET | CHAUHAN | 70000 | HYDERABAD | JAVA | 3 |
| 6003 | NIKITA | INGALE | 65000 | HYDERABAD | ORACLE | 1 |
| 1003 | NICHIL | VANI | 50500 | JAIPUR | FMW | 2 |
| 2003 | RUSCHIKA | JAIN | 50000 | MUMBAI | C# | 5 |
| 3003 | DEEPAM | JAUHARI | 58500 | MUMBAI | JAVA | 3 |
| 4001 | RAJESH | GOLD | 60500 | MUMBAI | TESTEN | 4 |
| 1002 | VAIBHAV | SHARMA | 60000 | NOIDA | C# | 5 |
| 4002 | ASHWINI | BAGHAT | 54500 | NOIDA | JAVA | 3 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 3001 | PRANOTI | SCHENDE | 55500 | PUNE | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
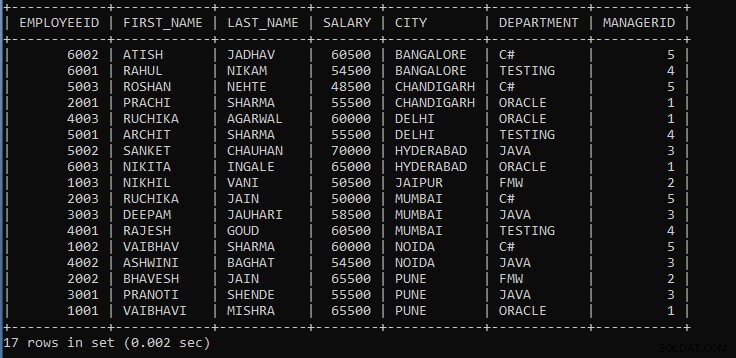
Wie wir sehen können, sind die Datensätze der Mitarbeiter nach Stadt und Abteilung gruppiert, und die Datensätze werden standardmäßig in aufsteigender Reihenfolge angezeigt.
Beispiel 5: Schreiben Sie eine Abfrage, um die Liste der Mitarbeiter in jeder Abteilung aus der Mitarbeitertabelle zu zählen.
SELECT DEPARTMENT, COUNT(DEPARTMENT) FROM EMPLOYEES GROUP BY DEPARTMENT;Die obige Abfrage zeigt die Anzahl der Mitarbeiter in jeder Abteilungsgruppe nach Abteilung an. Wie sechs Mitarbeiter arbeiten in der Personalabteilung, fünf arbeiten in einer anderen Abteilung.
Die Ausgabe der obigen Abfrage:
| ABTEILUNG | COUNT(ABTEILUNG) |
| C# | 4 |
| FMW | 3 |
| JAVA | 4 |
| ORACLE | 4 |
| TESTEN | 3 |
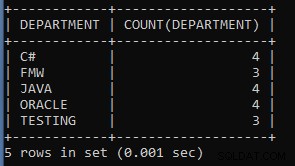
Wie wir sehen können, arbeiten vier Mitarbeiter in der C#-Abteilung, drei in der FMW-Abteilung usw.
Beispiel 6: Schreiben Sie eine Abfrage, um die Liste der Mitarbeiter aus jeder Stadt aus der Mitarbeitertabelle zu zählen.
SELECT CITY, COUNT(CITY) FROM EMPLOYEES GROUP BY CITY;
Die obige Abfrage zeigt die Anzahl der Mitarbeiter in jeder Stadtgruppe nach Stadt an. Beispielsweise arbeiten drei Mitarbeiter in der Stadt Pune, vier in einer anderen Stadt und so weiter.
Die Ausgabe der obigen Abfrage:
| STADT | COUNT(CITY) |
| BANGALORE | 2 |
| CHANDIGARH | 2 |
| DELHI | 2 |
| HYDERABAD | 2 |
| JAIPUR | 2 |
| MUMBAI | 3 |
| NOIDA | 2 |
| PUNE | 3 |
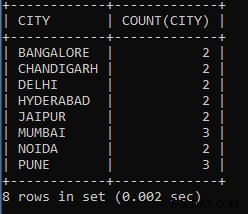
Wie wir sehen können, arbeiten zwei Mitarbeiter in der Stadt Bangalore, drei in der Stadt Mumbai und so weiter.
Beispiel 7: Schreiben Sie eine Abfrage, um die Gehaltsgruppe der Mitarbeiter nach Stadt zu summieren.
SELECT CITY, SUM(SALARY) AS SALARY FROM EMPLOYEES GROUP BY CITY;Das Obige wird verwendet, um die Gehälter der Angestellten zu summieren, gruppiert nach Stadtnamen. Zum Beispiel wird für Mitarbeiter aus derselben Stadt ihr Gehalt die Summe sein und als eine Gruppe betrachtet. Wir haben die Gesamtsummenfunktion gefolgt von der Gehaltsspalte zum Hinzufügen des Gehalts verwendet.
Die Ausgabe der obigen Abfrage:
| STADT | GEHALT |
| BANGALORE | 115000 |
| CHANDIGARH | 104000 |
| DELHI | 115500 |
| HYDERABAD | 135000 |
| JAIPUR | 101000 |
| MUMBAI | 169000 |
| NOIDA | 114500 |
| PUNE | 186500 |
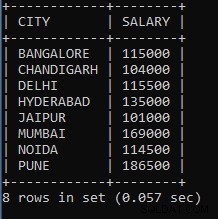
Wie wir sehen können, beträgt das Summengehalt der Stadt Bangalore 115000, das Summengehalt der Stadt Chandigarh 104000, was die Addition verschiedener Mitarbeitergehälter darstellt, aber von der Stadt aus wird für jede Stadt der gleiche Ansatz verwendet.
Beispiel 8: Schreiben Sie eine Abfrage, um das Mindestgehalt jeder Abteilung zu ermitteln.
SELECT DEPARTMENT, MIN(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT;Die obige Abfrage wird verwendet, um das Mindestgehalt des Mitarbeiters aus jeder Abteilung zu ermitteln. Das Gehalt eines Angestellten aus der Java-Abteilung beträgt 54500, was das niedrigste in der gesamten Java-Abteilung ist. Dieselben 48500 sind das niedrigste Gehalt, das einem Mitarbeiter in der C#-Abteilung gezahlt wird.
Die Ausgabe der obigen Abfrage:
| ABTEILUNG | MIN(GEHALT) |
| C# | 48500 |
| FMW | 50500 |
| JAVA | 54500 |
| ORACLE | 55500 |
| TESTEN | 54500 |
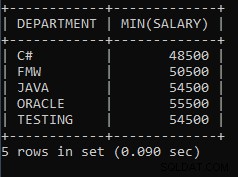
Wie wir sehen können, ist 50500 das niedrigste Gehalt, das einem der Mitarbeiter in der FMW-Abteilung gezahlt wird, 55500 ist das niedrigste Gehalt, das einem der Mitarbeiter in der ORACLE-Abteilung gezahlt wird.
Beispiel 9: Schreiben Sie eine Abfrage, um das Mindestgehalt von jeder Stadt zu finden.
SELECT CITY, MAX(SALARY) FROM EMPLOYEES GROUP BY CITY;Die obige Abfrage wird verwendet, um das maximale Gehalt aus jeder Stadt zu ermitteln. Das Gehalt eines Angestellten aus der Stadt Pune beträgt 65500, was das höchste in der gesamten Stadt Pune ist, die gleichen 60500 sind das höchste Gehalt, das an den Angestellten in der Stadt Mumbai gezahlt wird.
Die Ausgabe der obigen Abfrage:
| STADT | MAX(GEHALT) |
| BANGALORE | 60500 |
| CHANDIGARH | 55500 |
| DELHI | 60000 |
| HYDERABAD | 70000 |
| JAIPUR | 50500 |
| MUMBAI | 60500 |
| NOIDA | 60000 |
| PUNE | 65500 |
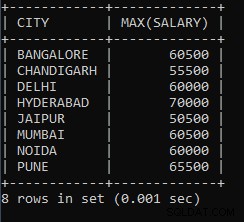
Wie wir sehen können, ist 50500 das höchste Gehalt, das einem der Angestellten in der Stadt Jaipur gezahlt wird, 55500 ist das höchste Gehalt, das einem der Angestellten in der Stadt Chandigarh gezahlt wird.