Einführung
- Es gibt einige spezifische Regeln, die beim Erstellen der Datenbankobjekte befolgt werden müssen. Um die Leistung einer Datenbank zu verbessern, sollten einer Tabelle ein Primärschlüssel, geclusterte und nicht geclusterte Indizes und Einschränkungen zugewiesen werden. Obwohl wir alle diese Regeln befolgen, können dennoch doppelte Zeilen in einer Tabelle auftreten.
- Es ist immer eine gute Praxis, die Datenbankschlüssel zu verwenden. Die Verwendung der Datenbankschlüssel verringert die Wahrscheinlichkeit, doppelte Datensätze in einer Tabelle zu erhalten. Wenn jedoch bereits doppelte Datensätze in einer Tabelle vorhanden sind, gibt es bestimmte Möglichkeiten, diese doppelten Datensätze zu entfernen.
Möglichkeiten zum Entfernen doppelter Zeilen
- Verwendung von DELETE JOIN Anweisung zum Entfernen doppelter Zeilen
Die DELETE JOIN-Anweisung wird in MySQL bereitgestellt, die dabei hilft, doppelte Zeilen aus einer Tabelle zu entfernen.
Stellen Sie sich eine Datenbank mit dem Namen "studentdb" vor. Wir werden darin eine Tabelle student erstellen.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
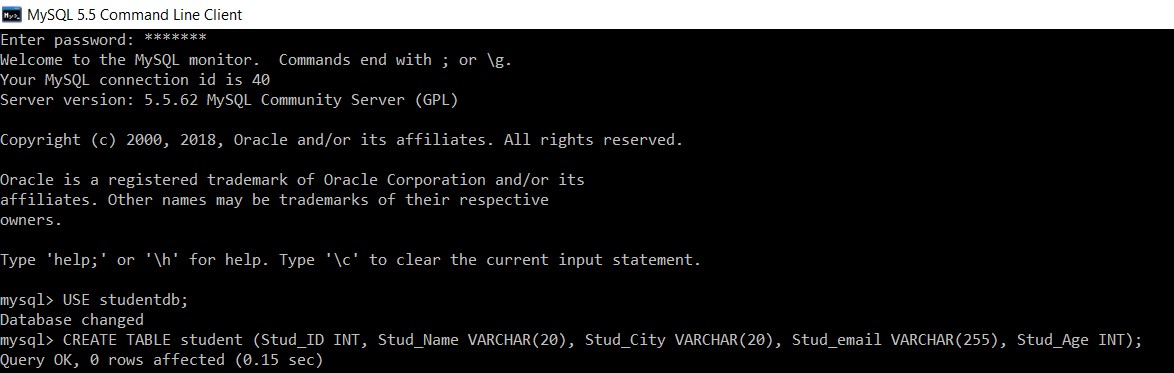
Wir haben erfolgreich eine 'student'-Tabelle in der 'studentdb'-Datenbank erstellt.
Jetzt schreiben wir die folgenden Abfragen, um Daten in die Schülertabelle einzufügen.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
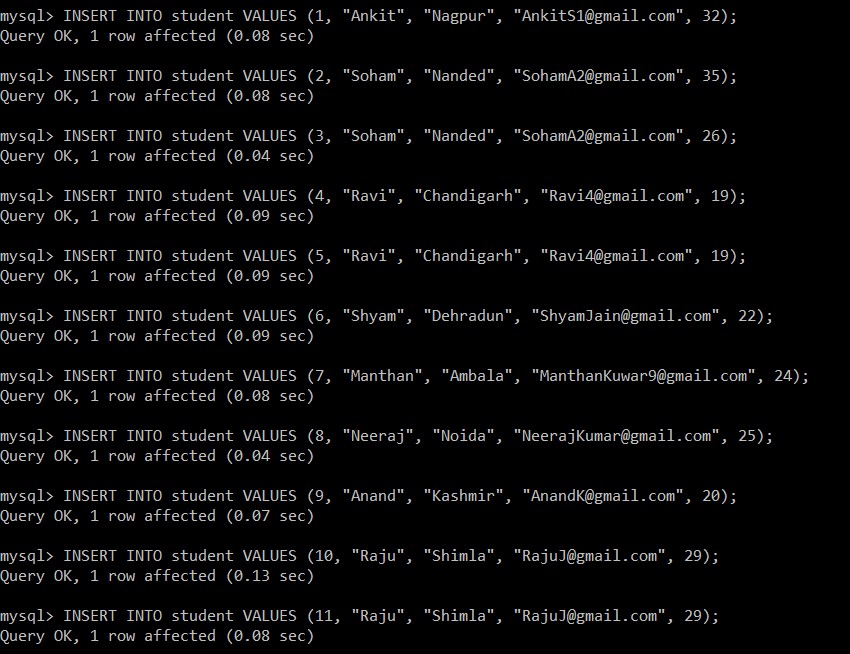
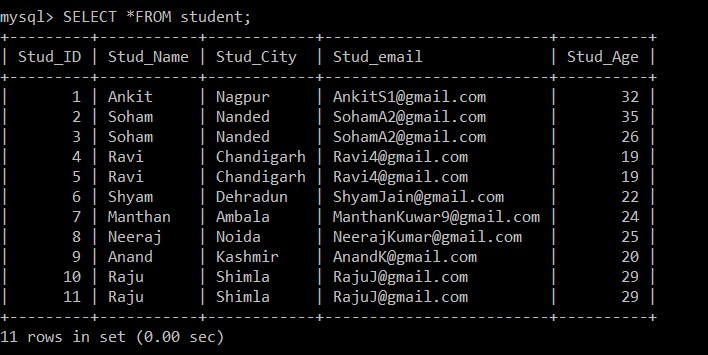
Jetzt werden wir alle Datensätze aus der Schülertabelle abrufen. Wir werden diese Tabelle und Datenbank für alle folgenden Beispiele berücksichtigen.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Beispiel 1:
Schreiben Sie eine Abfrage, um doppelte Zeilen aus der Schülertabelle zu löschen, indem Sie DELETE JOIN verwenden Erklärung.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Wir haben die DELETE-Abfrage mit INNER JOIN verwendet. Um den INNER JOIN für eine einzelne Tabelle zu implementieren, haben wir zwei Instanzen s1 und s2 erstellt. Dann haben wir mit Hilfe der WHERE-Klausel zwei Bedingungen überprüft, um die doppelten Zeilen in der Schülertabelle herauszufinden. Wenn die E-Mail-ID in zwei verschiedenen Datensätzen identisch ist und die Studenten-ID unterschiedlich ist, wird sie gemäß der Bedingung der WHERE-Klausel als doppelter Datensatz behandelt.
Ausgabe:
Query OK, 3 rows affected (0.20 sec)Die Ergebnisse der obigen Abfrage zeigen, dass in der Schülertabelle drei doppelte Datensätze vorhanden sind.

Wir werden die SELECT-Abfrage verwenden, um die doppelten Datensätze zu finden, die gelöscht wurden.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
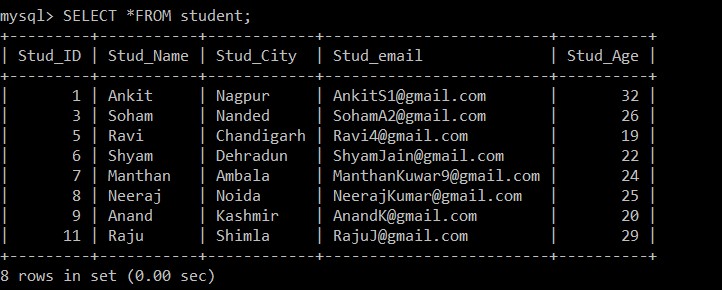
Jetzt sind nur noch 8 Datensätze in der Schülertabelle vorhanden, da die drei doppelten Datensätze aus der aktuell ausgewählten Tabelle gelöscht werden. Gemäß der folgenden Bedingung:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Wenn die E-Mail-IDs von zwei Datensätzen identisch sind, wird, da das Kleiner-als-Zeichen zwischen den Studenten-IDs verwendet wird, nur der Datensatz mit den höheren Mitarbeiter-IDs aufbewahrt, und der andere doppelte Datensatz wird zwischen den beiden Datensätzen gelöscht.
Beispiel 2:
Schreiben Sie eine Abfrage, um doppelte Zeilen aus der student-Tabelle zu löschen, indem Sie die delete join-Anweisung verwenden, während Sie den doppelten Datensatz mit einer niedrigeren Mitarbeiter-ID behalten und den anderen löschen.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Wir haben die DELETE-Abfrage mit INNER JOIN verwendet. Um den INNER JOIN für eine einzelne Tabelle zu implementieren, haben wir zwei Instanzen s1 und s2 erstellt. Dann haben wir mit Hilfe der WHERE-Klausel zwei Bedingungen überprüft, um die doppelten Zeilen in der Schülertabelle herauszufinden. Wenn die E-Mail-ID in zwei verschiedenen Datensätzen identisch ist und die Studenten-ID unterschiedlich ist, wird sie gemäß der Bedingung der WHERE-Klausel als doppelter Datensatz behandelt.
Ausgabe:
Query OK, 3 rows affected (0.09 sec)Die Ergebnisse der obigen Abfrage zeigen, dass in der Schülertabelle drei doppelte Datensätze vorhanden sind.

Wir werden die SELECT-Abfrage verwenden, um die doppelten Datensätze zu finden, die gelöscht wurden.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
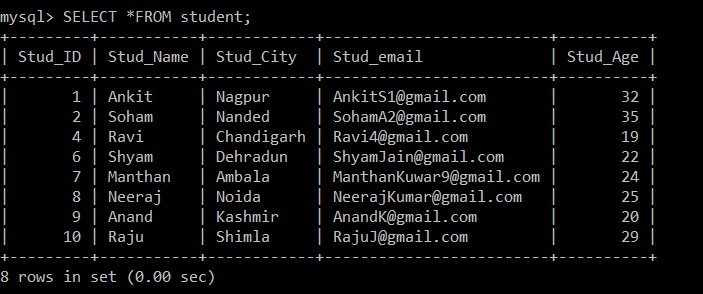
Jetzt sind nur noch 8 Datensätze in der Schülertabelle vorhanden, da die drei doppelten Datensätze aus der aktuell ausgewählten Tabelle gelöscht werden. Gemäß der folgenden Bedingung:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Wenn die E-Mail-IDs von zwei Datensätzen identisch sind, da das Größer-als-Zeichen zwischen der Studenten-ID verwendet wird, wird nur der Datensatz mit der kleineren Mitarbeiter-ID aufbewahrt und der andere doppelte Datensatz wird zwischen den beiden Datensätzen gelöscht. P>
- Verwendung einer Zwischentabelle zum Entfernen doppelter Zeilen
Die folgenden Schritte sollten befolgt werden, während die doppelten Zeilen mit Hilfe einer Zwischentabelle entfernt werden.
- Eine neue Tabelle sollte erstellt werden, die mit der tatsächlichen Tabelle identisch ist.
- Fügen Sie der neu erstellten Tabelle verschiedene Zeilen aus der aktuellen Tabelle hinzu.
- Löschen Sie die aktuelle Tabelle und benennen Sie die neue Tabelle mit demselben Namen wie eine aktuelle Tabelle um.
Beispiel:
Schreiben Sie eine Abfrage, um die doppelten Datensätze aus der Studententabelle zu löschen, indem Sie eine Zwischentabelle verwenden.
Schritt 1:
Zuerst erstellen wir eine Zwischentabelle, die mit der Mitarbeitertabelle identisch ist.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Hier ist „employee“ die ursprüngliche Tabelle und „temp_student“ die Zwischentabelle.
Schritt 2:
Jetzt holen wir nur die eindeutigen Datensätze aus der student-Tabelle und fügen alle abgerufenen Datensätze in die temp_student-Tabelle ein.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Hier werden vor dem Einfügen der eindeutigen Datensätze aus der student-Tabelle in temp_student alle doppelten Datensätze nach Stud_email gefiltert. Dann werden nur die Datensätze mit eindeutiger E-Mail-ID in temp_student.
eingefügtSchritt 3:
Dann entfernen wir die student-Tabelle und benennen die Tabelle temp_student in student-Tabelle um.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
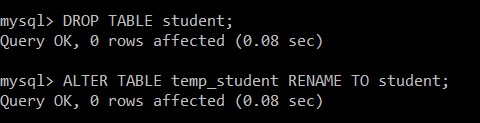
Die student-Tabelle wird erfolgreich entfernt und temp_student wird in die student-Tabelle umbenannt, die nur die eindeutigen Datensätze enthält.
Dann müssen wir überprüfen, ob die Schülertabelle jetzt nur die eindeutigen Datensätze enthält. Um dies zu überprüfen, haben wir die SELECT-Abfrage verwendet, um die in der Schülertabelle enthaltenen Daten anzuzeigen.
mysql> SELECT *FROM student;Ausgabe:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
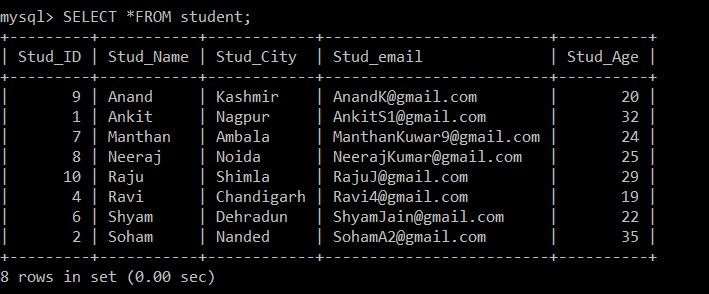
Jetzt sind nur noch 8 Datensätze in der Schülertabelle vorhanden, da die drei doppelten Datensätze aus der aktuell ausgewählten Tabelle gelöscht werden. In Schritt 2 wurde beim Abrufen der unterschiedlichen Datensätze aus der ursprünglichen Tabelle und Einfügen in eine Zwischentabelle eine GROUP BY-Klausel für Stud_email verwendet, sodass alle Datensätze basierend auf den E-Mail-IDs der Schüler eingefügt wurden. Hier wird standardmäßig nur der Datensatz mit einer niedrigeren Mitarbeiter-ID unter den doppelten Datensätzen behalten und der andere gelöscht.