Hinweis:Dieser Artikel zeigt die Migration eines Modells einer relationalen Datenbank (RDB) zu einem Star-Schema unter Verwendung der Eclipse-IDE für Voracity (und die darin enthaltenen Produkte), IRI Workbench, nach einer Einführung in beide Architekturen. Wenn Sie daran interessiert sind, Ihre RDB oder Daten zu einem Data Vault 2.0-Modell zu migrieren, wird im Mai 2019 beim World Wide Data Vault Consortium ein neuer Workbench-Assistent vorgestellt. abonnieren Sie den IRI-Blog, um diese Schritt-für-Schritt-Anleitungen zu erhalten, sobald sie veröffentlicht werden!
Ein Data Warehouse (DW) ist eine Sammlung von Daten, die aus dem Betriebs- oder Transaktionssystem in einem Unternehmen extrahiert, transformiert, um Inkonsistenzen zu beseitigen, und dann so angeordnet werden, dass sie eine schnelle Analyse und/oder Berichterstellung unterstützen. Die DW benötigt ein Schema oder eine logische Beschreibung und grafische Darstellung ihrer Betriebsdatenbank. Dieser Artikel behandelt diese Themen und bietet gleichzeitig eine Anleitung zum Wechsel von einem herkömmlichen relationalen Datenbankschema zu einem beliebten DW-Schema namens Star-Schema.
Star Schema vs. Relational
Die meisten relationalen Datenstrukturen werden in Entity-Relationship (ER)-Diagrammen dargestellt. Ein ER-Diagramm wird bei der Entwicklung von konzeptionellen Modellen für ein Datenbankverwaltungssystem für die Online-Transaktionsverarbeitung (OLTP) verwendet. Es ist die Quelle, aus der die Tabellenstruktur übersetzt wird.
Das Sternschema ist jedoch der weithin akzeptierte Standard für die zugrunde liegende Tabellenstruktur eines Data Warehouse. Seine einfache Sternform (bei ER-Diagramm) zeigt die Faktentabelle (mit Transaktionswerten oder Kennzahlen) in der Mitte und Dimensionstabellen (mit beschreibenden oder attributiven Werten), die davon ausstrahlen. Normalerweise ist die Faktentabelle in dritter Normalform (3NF), während Dimensionstabellen denormalisiert sind.
Die grundlegenden Unterschiede zwischen einem Entity-Relational-Modell (ER) und einem Star-Modell sind:
- ER-Modelle verwenden logische und physische Strukturen für ein normalisiertes Datenbankdesign
- Dimensionsmodelle verwenden eine physische Struktur für denormalisiertes Datenbankdesign
Klicken Sie hier, um zu sehen, wie die IRI-Software Daten durch Zeilen-Spalten-Pivotisierung de/normalisieren kann.
Hintergrund des Conversion-Prozesses
In diesem Artikel demonstriere ich, wie man Daten aus einem relationalen Modell in Sterne umwandelt, indem man Jobs verwendet, die man mehr oder weniger manuell definieren sollte, aber automatisch erstellen und ausführen und einfach ändern kann.
Was Sie hier sehen werden, sind die 4GL-Daten und Stellenspezifikationen von IRI – ausgedrückt in „SortCL“ Skripten[1] – die Daten in Dimensionstabellen abbilden und Daten in die zentrale Faktentabelle einfügen. SortCL ist das Kernprogramm zur Datenmanipulation und -kartierung in der Datenverwaltungs- und ETL-Plattform von IRI Voracity. Das Verständnis der Methodik und Zuordnungen in meinen SortCL-Jobs ist hier jedoch der Schlüssel, nicht die Skriptsyntax.
Die kostenlose Eclipse-GUI, IRI Workbench, bietet einen syntaxfähigen SortCL-Editor sowie grafische Umrisse und Dialoge, Workflow- und Mapping-Diagramme und intuitive Jobassistenten, um diese Skripte automatisch zu erstellen oder zu ändern, wenn Sie dies nicht möchten von Hand. FYI, IRI verwendet dieselben Metadaten und dieselbe GUI für die Profilerstellung und Diagrammerstellung von DBs, das Generieren von Testdaten, das Durchführen von ETL, das Formatieren von Berichten, das Maskieren von PII, das Erfassen geänderter Daten, das Migrieren und Replizieren von Daten, das Bereinigen und Validieren von Daten usw.
Workbench verwendet eine erweiterte Version des Data Tools Platform (DTP)-Plug-Ins für Eclipse, um eine Verbindung zu Datenbanken über JDBC herzustellen und um SQL-Operationen und IRI-Metadatenaustausch in der Data Source Explorer (DSE)-Ansicht zu ermöglichen. In diesem Fall unterstützt die Workbench Folgendes:
- die Erstellung und Auffüllung eingeschränkter Oracle-Test-(Quell-)Tabellen über SortCL (oder IRI RowGen Jobs, gemäß diesem Artikel)
- die Zuordnung von Entitätstabellendaten zu Dimensionstabellen über SortCL
- die Abbildung von Tatsachenelementen als n-stellige Relation, um die Hauptdimensionstabelle zuzuordnen; d. h. Durchführen eines Multi-Table-Joins in SortCL, um die Fact-Tabelle zu erstellen
- Auffüllung aller Zieltabellen (Sternschema)
- ER-Diagramme der Quell- und Zielschemas
Die Entitätstypen in meinem ursprünglichen relationalen Modell sind:Dept, Emp, Project, Category, Item, Item_Use und Sale:
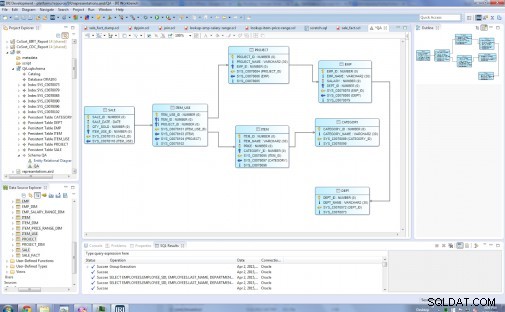
Vor …
Das nächste Diagramm zeigt das endgültige Star-Modell mit acht Dimensionstabellen und einer Faktentabelle. Die Dimensionstabellen sind: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Die Faktentabelle in der Mitte ist Sale_Fact, die Schlüssel zu allen Dimensionstabellen enthält.

… Nachher
Conversion-Schritte
- Definieren und erstellen Sie die Faktentabelle
Die Struktur für die Tabelle Sale_Fact wird in diesem Dokument gezeigt. Der Primärschlüssel ist sale_id, und der Rest der Attribute sind Fremdschlüssel, die von den Dimensionstabellen geerbt wurden. Ich verwende eine Oracle-Datenbank (obwohl jede RDB funktioniert), die mit der Workbench DSE (über JDBC) und SortCL für die Datentransformation und -zuordnung verbunden ist ( über ODBC). Ich habe meine Tabellen in SQL-Skripten erstellt, die im SQL-Sammelalbum von DSE bearbeitet und in der Workbench ausgeführt wurden.
- Definieren und erstellen Sie die Dimensionstabellen
Verwenden Sie dieselbe Technik und dieselben Metadaten, die oben verlinkt sind, um diese Dimensionstabellen zu erstellen, die die relationalen Daten erhalten, die im nächsten Schritt von SortCL-Jobs zugeordnet werden:Category_Dim table, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim und Emp to Emp_Dim. Sie können dieses .SQL-Programm mit der gesamten CREATE-Logik auf einmal ausführen, um die Tabellen zu erstellen.
- Verschieben Sie die ursprünglichen Entitätstabellendaten in die Dimensionstabellen
Definieren Sie die hier gezeigten SortCL-Jobs und führen Sie sie aus, um die (von RowGen erstellten Test-)Daten aus dem relationalen Schema Dimensionstabellen für das Star-Schema zuzuordnen. Insbesondere laden diese Skripts Daten aus der Category-Tabelle in die Tabelle „Category_Dim“, „Dept“ in „Dept_Dim“, „Project“ in „Project_Dim“, „Item“ in „Item_Dim“ und „Emp“ in „Emp_Dim“.
- Faktentabelle ausfüllen
Verwenden Sie SortCL, um Daten aus den ursprünglichen Sale-, Emp-, Project-, Item_Use-, Item- und Category-Entitätstabellen zusammenzuführen, um Daten für die neue Tabelle "Sale_Fact" vorzubereiten. Verwenden Sie hier das zweite Skript (join job).
Um unser Beispiel zu verbessern, werden wir auch SortCL verwenden, um neue dimensionale Daten in das Star-Schema einzuführen, auf denen sich auch meine Fact-Tabelle stützt. Sie können diese zusätzlichen Tabellen im Sterndiagramm oben sehen, die nicht in meinem relationalen Schema enthalten waren:Emp_Salary_Range_Dim und Item_Price_Range_Dim. Diese Tabellen werden in derselben .SQL-Datei für die Fakten- und andere Dimensionstabellen erstellt.
Die Faktentabelle benötigt die Daten emp_salary_range_id und item_price_range_id aus diesen Tabellen, um den Wertebereich in diesen Dimensionstabellen darzustellen. Wenn ich beispielsweise die dimensionalen Preiswerte in das Data Warehouse lade, möchte ich sie einer Preisspanne zuweisen:
| Item_Price | Range_Id | Bereichsname | Bereich_Ende |
|---|---|---|---|
| 1 | Niedrig | 1 | 100 |
| 2 | Mitte | 101 | 500 |
| 3 | Hoch | 501 | 999 |
Die einfachste Möglichkeit zum Zuweisen von Bereichs-IDs im Jobskript (das Daten für meine Sale_Fact-Tabelle vorbereitet) ist die Verwendung einer IF-THEN-ELSE-Anweisung im Ausgabeabschnitt. Weitere Informationen finden Sie in diesem Artikel über Bucket-Werte.
Wie auch immer, ich habe diesen ganzen Job mit dem CoSort New Join Job erstellt Assistent in der Workbench. Und sobald ich es ausgeführt habe, wurde meine Faktentabelle ausgefüllt:
 Sale_Fact-Tabellenanzeige in der IRI Workbench DSE
Sale_Fact-Tabellenanzeige in der IRI Workbench DSE
Fazit
Der Hauptvorteil der dimensionalen Datendarstellung besteht darin, die Komplexität einer Datenbankstruktur zu reduzieren. Dies erleichtert das Verständnis der Datenbank und das Schreiben von Abfragen, indem die Anzahl der Tabellen und damit die Anzahl der erforderlichen Verknüpfungen minimiert wird. Wie bereits erwähnt, optimieren dimensionale Modelle auch die Abfrageleistung. Es hat jedoch sowohl Schwäche als auch Stärke. Die feste Struktur des Star-Schemas schränkt die Abfragen ein. Da es das Schreiben der häufigsten Abfragen erleichtert, schränkt es auch die Art und Weise ein, wie die Daten analysiert werden können.
Die IRI Workbench-GUI für Voracity verfügt über einen leistungsstarken und umfassenden Satz von Tools, die die Datenintegration vereinfachen, einschließlich der Erstellung, Wartung und Erweiterung von Data Warehouses. Mit dieser intuitiven, benutzerfreundlichen Oberfläche erleichtert Voracity die schnelle, flexible End-to-End-ETL-Prozesserstellung (Extrahieren, Transformieren, Laden) mit Datenstrukturen auf unterschiedlichen Plattformen.
Bei ETL-Vorgängen werden Daten aus verschiedenen Quellen extrahiert, separat transformiert und in ein Data Warehouse und möglicherweise andere Ziele geladen. Der Aufbau des ETL-Prozesses ist möglicherweise eine der größten Aufgaben beim Aufbau eines Lagers. es ist komplex und zeitaufwändig. Der ETL-Ansatz von IRI unterstützt diesen Prozess auf hocheffiziente und datenbankunabhängige Weise, indem die gesamte Datenintegration und -bereitstellung im Dateisystem durchgeführt wird.
[1] Wenn Sie ein Syntaxhund sind, beachten Sie, dass SortCL-Skripte, die im IRI CoSort-Produkt oder der IRI Voracity-Plattform verwendet werden, dieselbe Syntax und Datendefinitionen wie IRI RowGen für die Testdatengenerierung, IRI NextForm für die Datenmigration und IRI unterstützen FieldShield zur Datenmaskierung. Alle diese Tools werden alle in der IRI Workbench-GUI unterstützt, und ihre Metadaten können auch gemeinsam genutzt und vom Team verwaltet werden für Versionskontrolle, Job-/Datenherkunft und Sicherheit in der Cloud.
[2] So zeigen Sie E-R-Diagramme in IRI Workbench an:
- Neues IRI-Projekt auswählen und neuen Ordner erstellen
- Wählen Sie diesen Ordner aus und markieren Sie alle zutreffenden Datenbanktabellen im Datenquellen-Explorer; dann Rechtsklick IRI, Neues ER-Diagramm
- Eine Datei (Schema.QA) wird erstellt
- Klicken Sie mit der rechten Maustaste auf diese Datei und wählen Sie Neue Darstellung, Neues Entitätsbeziehungsdiagramm.
[3] Zu den Elementen des ER-Diagramms, die solche Modelle veranschaulichen, gehören:
- definierte Entitätstypen
- definierte Attribute
- die Beziehung zwischen den Entitätstypen
- Gesamtbild oder Konzeptdiagramm
[4] IRI FACT und SQL*Loader sind Massenextraktions- bzw. Ladeoptionen.



