Letzten Monat habe ich eine Herausforderung gepostet, um einen effizienten Zahlenreihengenerator zu erstellen. Die Rückmeldungen waren überwältigend. Es gab viele brillante Ideen und Vorschläge, mit vielen Anwendungen weit über diese besondere Herausforderung hinaus. Mir wurde klar, wie großartig es ist, Teil einer Gemeinschaft zu sein, und dass erstaunliche Dinge erreicht werden können, wenn sich eine Gruppe intelligenter Menschen zusammenschließt. Vielen Dank an Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason und John Number2 für das Teilen Ihrer Ideen und Kommentare.
Ursprünglich dachte ich daran, nur einen Artikel zu schreiben, um die eingereichten Ideen zusammenzufassen, aber es waren zu viele. Also werde ich die Berichterstattung auf mehrere Artikel aufteilen. Diesen Monat werde ich mich hauptsächlich auf die Verbesserungsvorschläge von Charlie und Alan Burstein zu den beiden ursprünglichen Lösungen konzentrieren, die ich letzten Monat in Form der Inline-TVFs namens dbo.GetNumsItzikBatch und dbo.GetNumsItzik gepostet habe. Ich nenne die verbesserten Versionen dbo.GetNumsAlanCharlieItzikBatch bzw. dbo.GetNumsAlanCharlieItzik.
Das ist so aufregend!
Itziks Originallösungen
Zur Erinnerung:Die Funktionen, die ich letzten Monat behandelt habe, verwenden einen Basis-CTE, der einen Tabellenwertkonstruktor mit 16 Zeilen definiert. Die Funktionen verwenden eine Reihe von kaskadierenden CTEs, die jeweils ein Produkt (Cross Join) von zwei Instanzen ihres vorhergehenden CTE anwenden. Auf diese Weise können Sie mit fünf CTEs über dem Basis-CTE einen Satz von bis zu 4.294.967.296 Zeilen erhalten. Ein CTE namens Nums verwendet die ROW_NUMBER-Funktion, um eine Reihe von Zahlen zu erzeugen, die mit 1 beginnen. Schließlich berechnet die äußere Abfrage die Zahlen im angeforderten Bereich zwischen den Eingaben @low und @high.
Die Funktion dbo.GetNumsItzikBatch verwendet einen Dummy-Join zu einer Tabelle mit einem Columnstore-Index, um eine Stapelverarbeitung zu erhalten. Hier ist der Code zum Erstellen der Dummy-Tabelle:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Und hier ist der Code, der die Funktion dbo.GetNumsItzikBatch definiert:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ich habe den folgenden Code verwendet, um die Funktion zu testen, wobei „Ergebnisse nach Ausführung verwerfen“ in SSMS aktiviert war:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Leistungsstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU time = 16985 ms, elapsed time = 18348 ms.
Die Funktion dbo.GetNumsItzik ist ähnlich, nur dass sie keinen Dummy-Join hat und normalerweise im gesamten Plan eine Verarbeitung im Zeilenmodus erhält. Hier ist die Definition der Funktion:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Hier ist der Code, den ich zum Testen der Funktion verwendet habe:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Leistungsstatistiken, die ich für diese Hinrichtung erhalten habe:
CPU time = 19969 ms, elapsed time = 21229 ms.
Alan Bursteins und Charlies Verbesserungen
Alan und Charlie schlugen mehrere Verbesserungen für meine Funktionen vor, einige mit moderaten Auswirkungen auf die Leistung und andere mit dramatischeren. Ich beginne mit Charlies Erkenntnissen in Bezug auf den Kompilierungsaufwand und das konstante Falten. Ich werde dann Alans Vorschläge behandeln, einschließlich 1-basierter versus @low-basierter Sequenzen (auch von Charlie und Jeff Moden geteilt), unnötiges Sortieren vermeiden und einen Zahlenbereich in umgekehrter Reihenfolge berechnen.
Befunde zur Kompilierzeit
Wie Charlie bemerkte, wird ein Zahlenreihengenerator häufig verwendet, um Reihen mit einer sehr kleinen Anzahl von Zeilen zu generieren. In diesen Fällen kann die Kompilierzeit des Codes einen wesentlichen Teil der gesamten Abfrageverarbeitungszeit ausmachen. Das ist besonders wichtig bei der Verwendung von iTVFs, da anders als bei Stored Procedures nicht der parametrisierte Abfragecode optimiert wird, sondern der Abfragecode nach der Parametereinbettung erfolgt. Mit anderen Worten, die Parameter werden vor der Optimierung durch die Eingabewerte ersetzt, und der Code mit den Konstanten wird optimiert. Dieser Prozess kann sowohl negative als auch positive Auswirkungen haben. Eine der negativen Auswirkungen ist, dass Sie mehr Kompilierungen erhalten, wenn die Funktion mit unterschiedlichen Eingabewerten aufgerufen wird. Aus diesem Grund sollten unbedingt Kompilierzeiten berücksichtigt werden – insbesondere bei sehr häufiger Nutzung der Funktion mit kleinen Ranges.
Hier sind die Kompilierungszeiten, die Charlie für die verschiedenen Basis-CTE-Kardinalitäten gefunden hat:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Es ist merkwürdig zu sehen, dass unter diesen 16 das Optimum ist und dass es einen sehr dramatischen Sprung gibt, wenn Sie auf die nächste Ebene aufsteigen, die 256 ist. Erinnern Sie sich daran, dass die Funktionen dbo.GetNumsItzikBacth und dbo.GetNumsItzik eine Basis-CTE-Kardinalität von 16 verwenden .
Ständige Faltung
Konstante Faltung ist oft eine positive Implikation, die unter den richtigen Bedingungen dank des Parametereinbettungsprozesses, den ein iTVF durchläuft, ermöglicht werden kann. Angenommen, Ihre Funktion hat einen Ausdruck @x + 1, wobei @x ein Eingabeparameter der Funktion ist. Sie rufen die Funktion mit @x =5 als Eingabe auf. Der eingebettete Ausdruck wird dann zu 5 + 1, und wenn er für eine konstante Faltung geeignet ist (mehr dazu in Kürze), wird er zu 6. Wenn dieser Ausdruck Teil eines ausgefeilteren Ausdrucks ist, der Spalten beinhaltet, und auf viele Millionen Zeilen angewendet wird, kann dies der Fall sein führen zu einer nicht zu vernachlässigenden Einsparung von CPU-Zyklen.
Der knifflige Teil ist, dass SQL Server sehr wählerisch ist, was konstant gefaltet werden soll und was nicht konstant gefaltet werden soll. Beispielsweise wird SQL Server nicht konstant fold col1 + 5 + 1, noch wird es 5 + col1 + 1 folden. Aber es wird 5 + 1 + col1 bis 6 + col1 folden. Ich weiss. Wenn Ihre Funktion beispielsweise SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1 zurückgibt, könnten Sie mit der folgenden kleinen Änderung das konstante Falten aktivieren:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Glaub mir nicht? Untersuchen Sie die Pläne für die folgenden drei Abfragen in der PerformanceV5-Datenbank (oder ähnliche Abfragen mit Ihren Daten) und überzeugen Sie sich selbst:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Ich habe die folgenden drei Ausdrücke in den Compute Scalar-Operatoren für diese drei Abfragen erhalten:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Sehen Sie, wohin ich damit gehe? In meinen Funktionen habe ich den folgenden Ausdruck verwendet, um die Ergebnisspalte n zu definieren:
@low + rownum - 1 AS n
Charlie erkannte, dass er mit der folgenden kleinen Änderung eine konstante Faltung ermöglichen kann:
@low - 1 + rownum AS n
Beispielsweise hatte der Plan für die frühere Abfrage, die ich für dbo.GetNumsItzik mit @low =1 bereitgestellt hatte, ursprünglich den folgenden Ausdruck, der durch den Compute Scalar-Operator definiert wurde:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Nach Anwendung der obigen geringfügigen Änderung wird der Ausdruck im Plan zu:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Das ist genial!
Was die Auswirkungen auf die Leistung betrifft, erinnern Sie sich, dass die Leistungsstatistiken, die ich für die Abfrage von dbo.GetNumsItzikBatch vor der Änderung erhalten habe, die folgenden waren:
CPU time = 16985 ms, elapsed time = 18348 ms.
Hier sind die Zahlen, die ich nach der Änderung erhalten habe:
CPU time = 16375 ms, elapsed time = 17932 ms.
Hier sind die Zahlen, die ich ursprünglich für die Abfrage gegen dbo.GetNumsItzik erhalten habe:
CPU time = 19969 ms, elapsed time = 21229 ms.
Und hier sind die Zahlen nach der Änderung:
CPU time = 19266 ms, elapsed time = 20588 ms.
Die Leistung verbesserte sich nur geringfügig um ein paar Prozent. Aber warte, es gibt noch mehr! Wenn Sie die bestellten Daten verarbeiten müssen, können die Auswirkungen auf die Leistung viel dramatischer sein, worauf ich später im Abschnitt über die Bestellung eingehen werde.
1-basierte versus @low-basierte Sequenz und entgegengesetzte Zeilennummern
Alan, Charlie und Jeff stellten fest, dass in der überwiegenden Mehrheit der realen Fälle, in denen Sie eine Reihe von Zahlen benötigen, diese mit 1 oder manchmal 0 beginnen müssen. Es ist weitaus seltener, einen anderen Ausgangspunkt zu benötigen. Daher könnte es sinnvoller sein, die Funktion immer einen Bereich zurückgeben zu lassen, der beispielsweise mit 1 beginnt, und wenn Sie einen anderen Ausgangspunkt benötigen, alle Berechnungen extern in der Abfrage auf die Funktion anzuwenden.
Alan hatte tatsächlich die elegante Idee, dass der Inline-TVF sowohl eine Spalte zurückgibt, die mit 1 beginnt (einfach das direkte Ergebnis der ROW_NUMBER-Funktion), die als rn bezeichnet wird, als auch eine Spalte, die mit @low beginnt und als n bezeichnet wird. Da die Funktion eingebettet wird, wenn die äußere Abfrage nur mit der Spalte rn interagiert, wird die Spalte n nicht einmal ausgewertet, und Sie erhalten den Leistungsvorteil. Wenn Sie möchten, dass die Sequenz mit @low beginnt, interagieren Sie mit der Spalte n und zahlen die entsprechenden zusätzlichen Kosten, sodass keine expliziten externen Berechnungen hinzugefügt werden müssen. Alan schlug sogar vor, eine Spalte namens op hinzuzufügen, die die Zahlen in umgekehrter Reihenfolge berechnet, und nur dann mit ihr zu interagieren, wenn eine solche Sequenz benötigt wird. Die Spalte op basiert auf der Berechnung:@high + 1 – rownum. Diese Spalte ist wichtig, wenn Sie die Zeilen in absteigender Nummernreihenfolge verarbeiten müssen, wie ich später im Bestellabschnitt demonstriere.
Wenden wir also die Verbesserungen von Charlie und Alan auf meine Funktionen an.
Stellen Sie bei der Batch-Modus-Version sicher, dass Sie zuerst die Dummy-Tabelle mit dem Columnstore-Index erstellen, falls dieser noch nicht vorhanden ist:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Verwenden Sie dann die folgende Definition für die Funktion dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Hier ist ein Beispiel für die Verwendung der Funktion:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Dieser Code generiert die folgende Ausgabe:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Testen Sie als Nächstes die Leistung der Funktion mit 100 Millionen Zeilen und geben Sie zuerst die Spalte n:
zurückSELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Leistungsstatistiken, die ich für diese Ausführung erhalten habe:
CPU time = 16375 ms, elapsed time = 17932 ms.
Wie Sie sehen können, gibt es eine kleine Verbesserung im Vergleich zu dbo.GetNumsItzikBatch sowohl in der CPU als auch in der verstrichenen Zeit, dank der konstanten Faltung, die hier stattfand.
Testen Sie die Funktion und geben Sie diesmal nur die Spalte rn:
zurückSELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Leistungsstatistiken, die ich für diese Ausführung erhalten habe:
CPU time = 15890 ms, elapsed time = 18561 ms.
Die CPU-Zeit wurde weiter reduziert, obwohl die verstrichene Zeit bei dieser Ausführung etwas länger geworden zu sein scheint, verglichen mit der Abfrage der Spalte n.
Abbildung 1 enthält die Pläne für beide Abfragen.
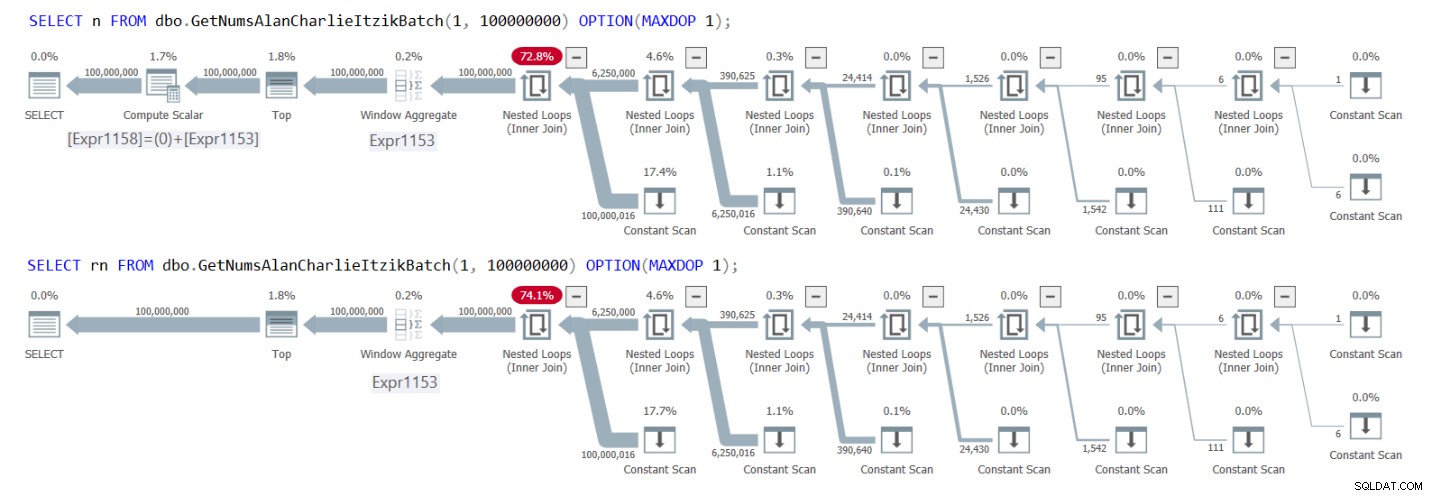 Abbildung 1:Pläne für GetNumsAlanCharlieItzikBatch, die n im Vergleich zu rn zurückgeben
Abbildung 1:Pläne für GetNumsAlanCharlieItzikBatch, die n im Vergleich zu rn zurückgeben
Sie können in den Plänen deutlich sehen, dass bei der Interaktion mit der Spalte rn der zusätzliche Compute Scalar-Operator nicht erforderlich ist. Beachten Sie im ersten Plan auch das Ergebnis der konstanten Folding-Aktivität, die ich zuvor beschrieben habe, wo @low – 1 + Rownum in 1 – 1 + Rownum eingefügt und dann in 0 + Rownum gefaltet wurde.
Hier ist die Definition der Zeilenmodusversion der Funktion namens dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Verwenden Sie den folgenden Code, um die Funktion zu testen, indem Sie zuerst die Spalte n:
abfragenSELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Hier sind die Leistungsstatistiken, die ich erhalten habe:
CPU time = 19047 ms, elapsed time = 20121 ms.
Wie Sie sehen können, ist es etwas schneller als dbo.GetNumsItzik.
Als nächstes fragen Sie die Spalte rn:
abSELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Die Leistungszahlen verbessern sich weiter sowohl auf der CPU- als auch auf der verstrichenen Zeitfront:
CPU time = 17656 ms, elapsed time = 18990 ms.
Hinweise zur Bestellung
Die oben genannten Verbesserungen sind sicherlich interessant, und die Auswirkungen auf die Leistung sind nicht zu vernachlässigen, aber nicht sehr signifikant. Eine viel dramatischere und tiefgreifendere Auswirkung auf die Leistung kann beobachtet werden, wenn Sie die Daten verarbeiten müssen, die nach der Zahlenspalte geordnet sind. Dies könnte so einfach sein wie die Notwendigkeit, die geordneten Zeilen zurückzugeben, ist aber genauso relevant für alle auftragsbasierten Verarbeitungsanforderungen, z. P>
Beim Abfragen von dbo.GetNumsItzikBatch oder dbo.GetNumsItzik und Sortieren nach n erkennt der Optimierer nicht, dass der zugrunde liegende Sortierausdruck @low + rownum – 1 Ordnungserhaltung ist in Bezug auf rownum. Die Implikation ähnelt ein wenig der eines nicht-SARG-fähigen Filterausdrucks, nur dass dies bei einem Sortierausdruck zu einem expliziten Sort-Operator im Plan führt. Die zusätzliche Sortierung wirkt sich auf die Antwortzeit aus. Es wirkt sich auch auf die Skalierung aus, die normalerweise zu n log n anstelle von n wird.
Um dies zu demonstrieren, fragen Sie dbo.GetNumsItzikBatch ab und fordern die Spalte n an, sortiert nach n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ich habe die folgenden Leistungsstatistiken:
CPU time = 34125 ms, elapsed time = 39656 ms.
Die Laufzeit wird im Vergleich zum Test ohne die ORDER BY-Klausel mehr als verdoppelt.
Testen Sie die dbo.GetNumsItzik-Funktion auf ähnliche Weise:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ich habe die folgenden Zahlen für diesen Test:
CPU time = 52391 ms, elapsed time = 55175 ms.
Auch hier wird die Laufzeit im Vergleich zum Test ohne die ORDER BY-Klausel mehr als verdoppelt.
Abbildung 2 enthält die Pläne für beide Abfragen.
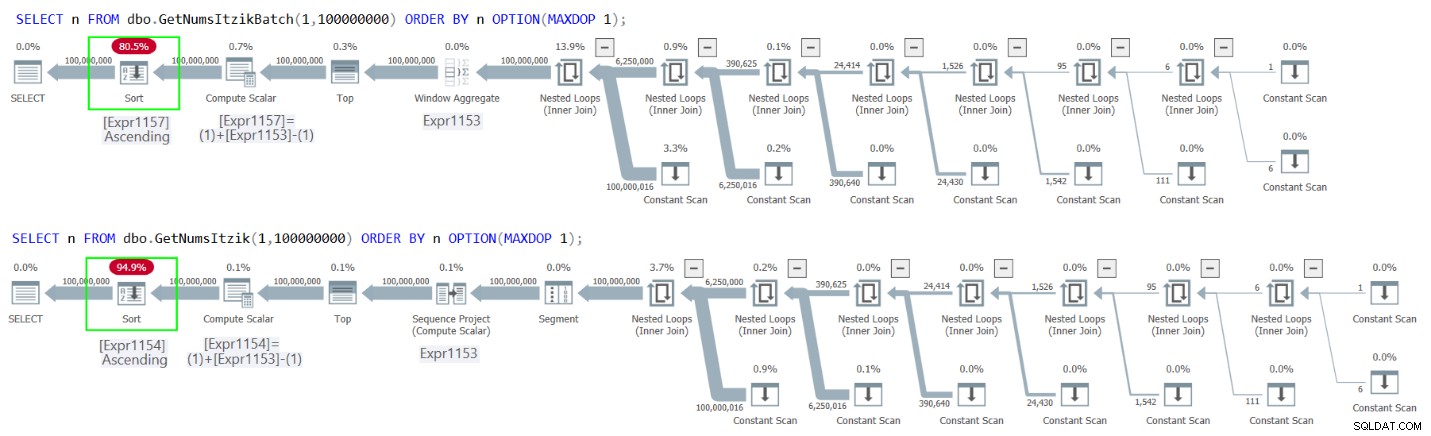 Abbildung 2:Pläne für die Sortierung von GetNumsItzikBatch und GetNumsItzik nach n
Abbildung 2:Pläne für die Sortierung von GetNumsItzikBatch und GetNumsItzik nach n
In beiden Fällen können Sie den expliziten Sort-Operator in den Plänen sehen.
Beim Abfragen von dbo.GetNumsAlanCharlieItzikBatch oder dbo.GetNumsAlanCharlieItzik und Sortieren nach rn muss der Optimierer dem Plan keinen Sort-Operator hinzufügen. Sie könnten also n zurückgeben, aber nach rn ordnen und auf diese Weise eine Sortierung vermeiden. Was jedoch etwas schockierend ist – und ich meine es positiv – ist, dass die überarbeitete Version von n, die eine konstante Faltung erfährt, die Ordnung bewahrt! Für den Optimierer ist es leicht zu erkennen, dass 0 + rownum ein reihenfolgeerhaltender Ausdruck in Bezug auf rownum ist, und somit eine Sortierung zu vermeiden.
Versuch es. Fragen Sie dbo.GetNumsAlanCharlieItzikBatch ab, geben Sie n zurück und sortieren Sie entweder nach n oder rn, etwa so:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ich habe die folgenden Leistungszahlen:
CPU time = 16500 ms, elapsed time = 17684 ms.
Das ist natürlich der Tatsache zu verdanken, dass im Plan kein Sort-Operator benötigt wurde.
Führen Sie einen ähnlichen Test gegen dbo.GetNumsAlanCharlieItzik durch:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ich habe die folgenden Nummern:
CPU time = 19546 ms, elapsed time = 20803 ms.
Abbildung 3 enthält die Pläne für beide Abfragen:
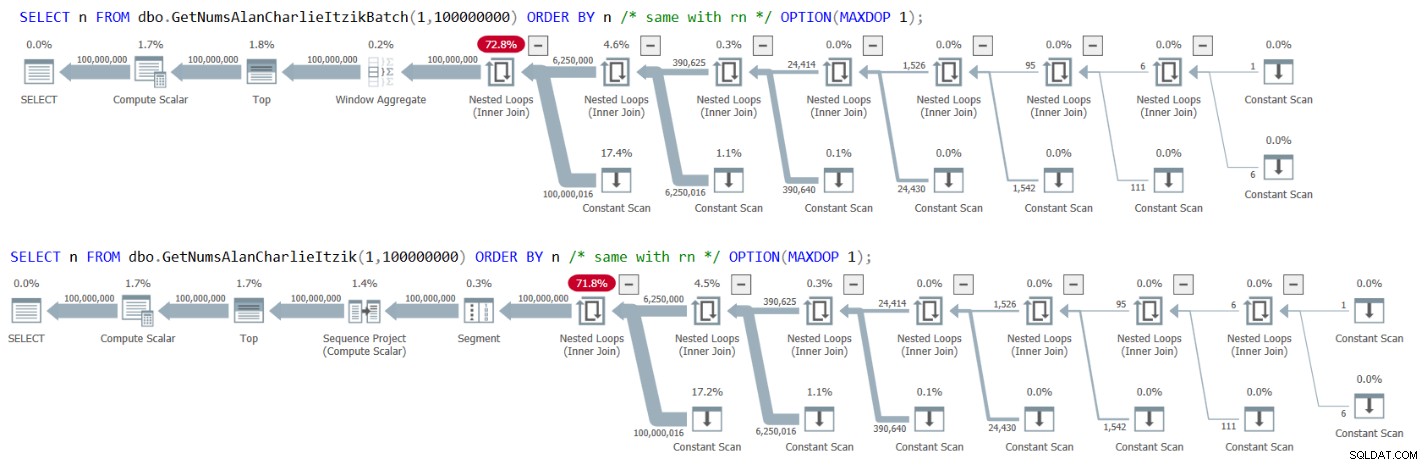
Abbildung 3:Pläne für GetNumsAlanCharlieItzikBatch und GetNumsAlanCharlieItzik, sortiert nach n oder rn
Beachten Sie, dass die Pläne keinen Sort-Operator enthalten.
Macht Lust zu singen…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Danke Charlie!
Aber was ist, wenn Sie die Zahlen in absteigender Reihenfolge zurückgeben oder verarbeiten müssen? Der offensichtliche Versuch besteht darin, ORDER BY n DESC oder ORDER BY rn DESC zu verwenden, etwa so:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Leider führen beide Fälle jedoch zu einer expliziten Sortierung in den Plänen, wie in Abbildung 4 gezeigt.
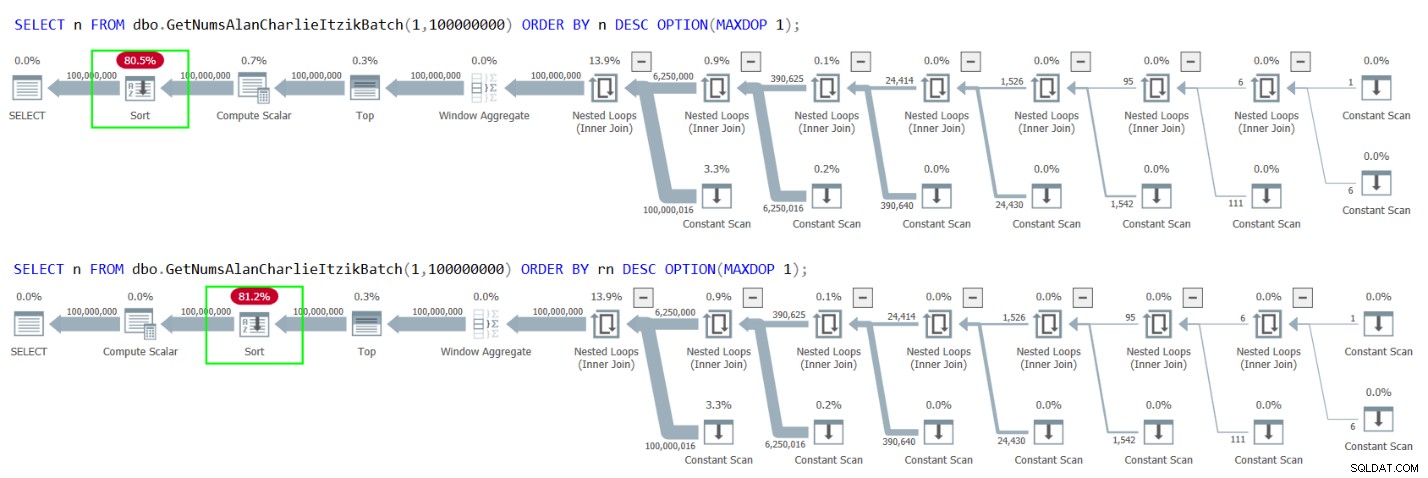 Abbildung 4:Pläne für die Sortierung von GetNumsAlanCharlieItzikBatch nach n oder rn absteigend
Abbildung 4:Pläne für die Sortierung von GetNumsAlanCharlieItzikBatch nach n oder rn absteigend
Hier wird Alans cleverer Trick mit der Spaltenoperation zum Lebensretter. Geben Sie die Spalte op zurück, während Sie entweder nach n oder rn sortieren, etwa so:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Der Plan für diese Abfrage ist in Abbildung 5 dargestellt.
 Abbildung 5:Plan für die Rückgabe von GetNumsAlanCharlieItzikBatch und die Sortierung nach n oder rn aufsteigend
Abbildung 5:Plan für die Rückgabe von GetNumsAlanCharlieItzikBatch und die Sortierung nach n oder rn aufsteigend
Sie erhalten die Daten nach n absteigend geordnet zurück und es ist keine Sortierung im Plan erforderlich.
Danke Alan!
Leistungszusammenfassung
Was haben wir also aus all dem gelernt?
Kompilierungszeiten können ein Faktor sein, insbesondere wenn die Funktion häufig mit kleinen Reichweiten verwendet wird. Auf einer logarithmischen Skala mit der Basis 2 scheint die süße 16 eine schöne magische Zahl zu sein.
Verstehe die Besonderheiten des konstanten Faltens und nutze sie zu deinem Vorteil. Wenn ein iTVF Ausdrücke enthält, die Parameter, Konstanten und Spalten beinhalten, setzen Sie die Parameter und Konstanten in den führenden Teil des Ausdrucks. Dies erhöht die Wahrscheinlichkeit für das Folden, reduziert den CPU-Overhead und erhöht die Wahrscheinlichkeit für die Beibehaltung der Reihenfolge.
Es ist in Ordnung, mehrere Spalten zu haben, die für unterschiedliche Zwecke in einem iTVF verwendet werden, und die jeweils relevanten abzufragen, ohne sich Gedanken darüber zu machen, für diejenigen zu bezahlen, auf die nicht verwiesen wird.
Wenn Sie die Zahlenfolge in umgekehrter Reihenfolge zurückgeben möchten, verwenden Sie die ursprüngliche n- oder rn-Spalte in der ORDER BY-Klausel mit aufsteigender Reihenfolge und geben Sie die Spalte op zurück, die die Zahlen in umgekehrter Reihenfolge berechnet.
Abbildung 6 fasst die Leistungszahlen zusammen, die ich in den verschiedenen Tests erhalten habe.
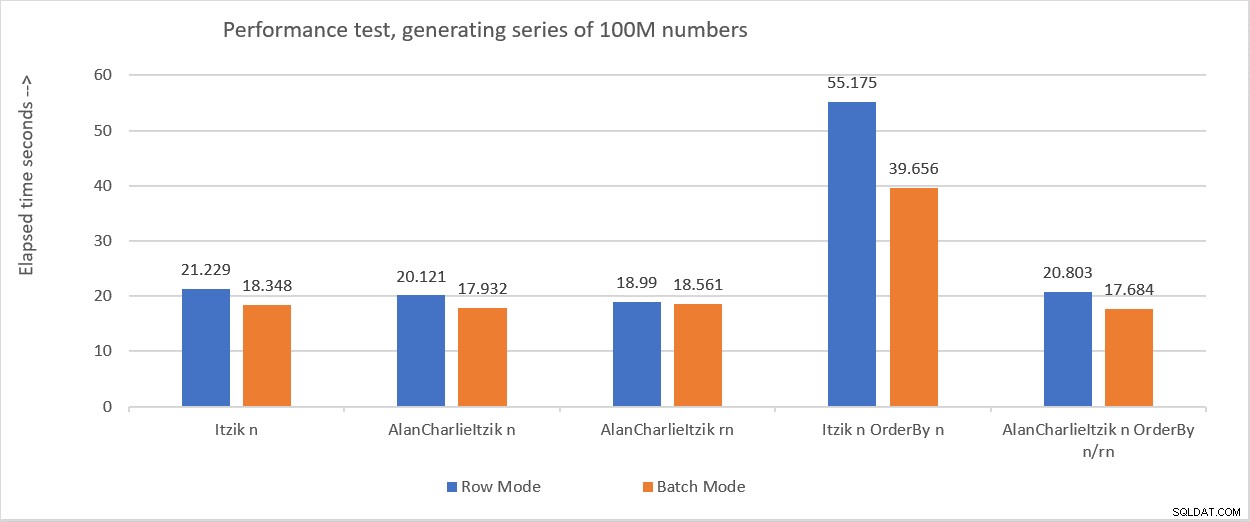 Abbildung 6:Leistungszusammenfassung
Abbildung 6:Leistungszusammenfassung
Nächsten Monat werde ich weiter nach weiteren Ideen, Erkenntnissen und Lösungen für die Zahlenserien-Generator-Herausforderung suchen.