Es gibt mehrere Methoden, um Abfragen mit schlechter Leistung in SQL Server zu untersuchen, insbesondere den Abfragespeicher, erweiterte Ereignisse und dynamische Verwaltungsansichten (DMVs). Jede Option hat Vor- und Nachteile. Extended Events liefert Daten über die individuelle Ausführung von Abfragen, während Query Store und die DMVs Leistungsdaten aggregieren. Um Query Store und Extended Events zu verwenden, müssen Sie diese im Voraus konfigurieren – entweder Query Store für Ihre Datenbank(en) aktivieren oder eine XE-Sitzung einrichten und starten. DMV-Daten sind immer verfügbar, daher ist dies oft die einfachste Methode, um einen schnellen ersten Blick auf die Abfrageleistung zu werfen. Hier sind Glenns DMV-Abfragen praktisch – in seinem Skript hat er mehrere Abfragen, die Sie verwenden können, um die Top-Abfragen für die Instanz basierend auf CPU, logischem I/O und Dauer zu finden. Das Zielen auf die ressourcenintensivsten Abfragen ist oft ein guter Anfang bei der Fehlerbehebung, aber wir dürfen das „Tod durch tausend Kürzungen“-Szenario nicht vergessen – die Abfrage oder Gruppe von Abfragen, die SEHR häufig ausgeführt werden – vielleicht hundert- oder tausendmal pro Jahr Minute. Glenn hat eine Abfrage in seinem Set, die die wichtigsten Abfragen für eine Datenbank basierend auf der Ausführungsanzahl auflistet, aber meiner Erfahrung nach gibt sie Ihnen kein vollständiges Bild Ihrer Arbeitslast.
Die wichtigste DMV, die zum Betrachten von Abfrageleistungsmetriken verwendet wird, ist sys.dm_exec_query_stats. Zusätzliche Daten speziell für gespeicherte Prozeduren (sys.dm_exec_procedure_stats), Funktionen (sys.dm_exec_function_stats) und Trigger (sys.dm_exec_trigger_stats) sind ebenfalls verfügbar, aber betrachten Sie eine Workload, die nicht nur aus gespeicherten Prozeduren, Funktionen und Triggern besteht. Stellen Sie sich eine gemischte Workload vor, die einige Ad-hoc-Abfragen enthält oder möglicherweise vollständig ad-hoc ist.
Beispielszenario
Wir leihen uns Code aus einem früheren Post, Examining the Performance Impact of an Ad-hoc Workload, und passen ihn an, und erstellen zunächst zwei gespeicherte Prozeduren. Die erste, dbo.RandomSelects, generiert und führt eine Ad-hoc-Anweisung aus, und die zweite, dbo.SPRandomSelects, generiert und führt eine parametrisierte Abfrage aus.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Jetzt führen wir beide Stored Procedures 1000 Mal aus und verwenden dieselbe Methode, die in meinem vorherigen Post mit .cmd-Dateien beschrieben wurde, die .sql-Dateien mit den folgenden Anweisungen aufrufen:
Inhalt der Adhoc.sql-Datei:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Inhalte der parametrisierten.sql-Datei:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Beispielsyntax in der .cmd-Datei, die die .sql-Datei aufruft:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Wenn wir eine Variation von Glenns Top-Worker-Time-Abfrage verwenden, um die Top-Abfragen basierend auf Worker Time (CPU) zu betrachten:
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
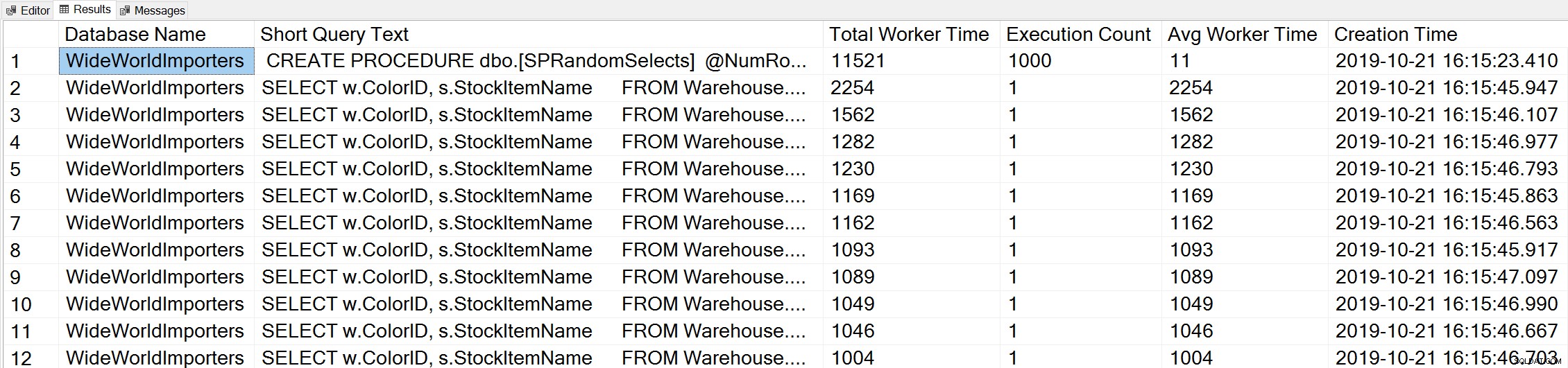
Wir betrachten die Anweisung unserer gespeicherten Prozedur als die Abfrage, die mit der höchsten kumulativen CPU ausgeführt wird.
Wenn wir eine Variation von Glenns Query Execution Counts-Abfrage gegen die WideWorldImporters-Datenbank ausführen:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
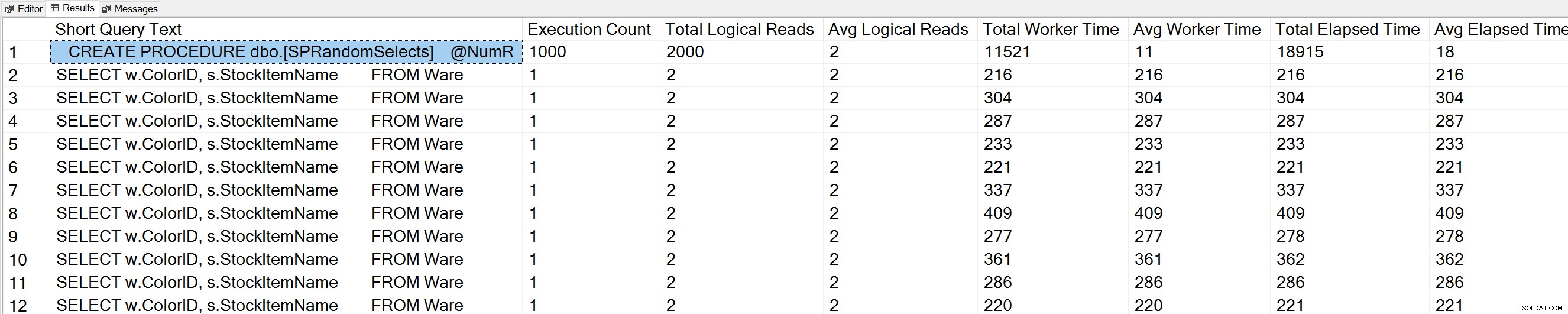
Wir sehen auch unsere gespeicherte Prozeduranweisung oben in der Liste.
Aber die Ad-hoc-Abfrage, die wir ausgeführt haben, war im Wesentlichen gleich, obwohl sie andere Literalwerte hat -Anweisung wiederholt ausgeführt, wie wir anhand des query_hash sehen können:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
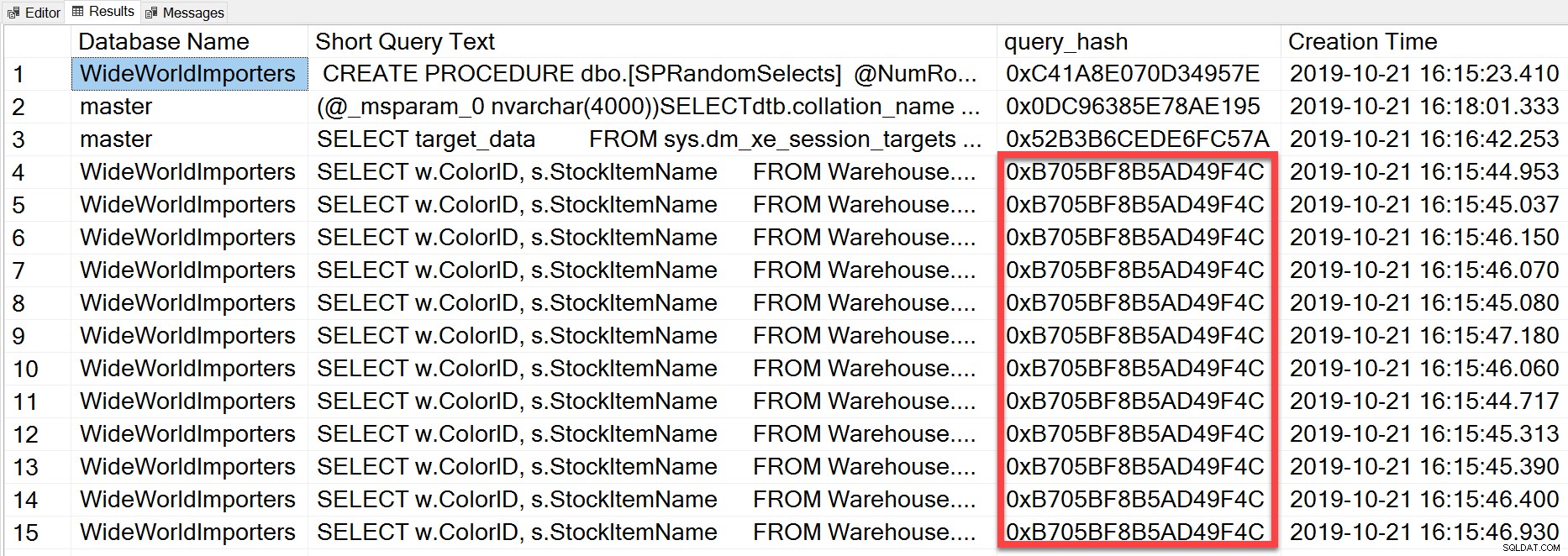
Der query_hash wurde in SQL Server 2008 hinzugefügt und basiert auf der Struktur der logischen Operatoren, die vom Abfrageoptimierer für den Anweisungstext generiert wurden. Abfragen mit ähnlichem Anweisungstext, die denselben Baum logischer Operatoren generieren, haben denselben query_hash, selbst wenn die Literalwerte im Abfrageprädikat unterschiedlich sind. Während die Literalwerte unterschiedlich sein können, müssen die Objekte und ihre Aliase sowie die Abfragehinweise und möglicherweise die SET-Optionen identisch sein. Die gespeicherte Prozedur RandomSelects generiert Abfragen mit unterschiedlichen Literalwerten:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Aber jede Ausführung hat genau den gleichen Wert für den query_hash, 0xB705BF8B5AD49F4C. Um zu verstehen, wie häufig eine Ad-hoc-Abfrage – und solche, die in Bezug auf query_hash gleich sind – ausgeführt wird, müssen wir bei dieser Anzahl nach der query_hash-Reihenfolge gruppieren, anstatt die Ausführungsanzahl in sys.dm_exec_query_stats zu betrachten (was häufig eine Wert 1).
Wenn wir den Kontext zur WideWorldImporters-Datenbank ändern und basierend auf der Ausführungsanzahl nach Top-Abfragen suchen, wobei wir nach query_hash gruppieren, können wir jetzt sowohl die gespeicherte Prozedur als auch sehen unsere Ad-hoc-Anfrage:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Hinweis:Die DMV sys.dm_exec_function_stats wurde in SQL Server 2016 hinzugefügt. Zum Ausführen dieser Abfrage auf SQL Server 2014 und früher muss der Verweis auf diese DMV entfernt werden.
Diese Ausgabe bietet ein viel umfassenderes Verständnis dafür, welche Abfragen wirklich am häufigsten ausgeführt werden, da sie basierend auf dem query_hash aggregiert wird, und nicht einfach durch Betrachten der Ausführungsanzahl in sys.dm_exec_query_stats, die mehrere Einträge für denselben query_hash haben kann, wenn es sich um unterschiedliche Literalwerte handelt Gebraucht. Die Abfrageausgabe enthält auch query_plan_hash, was für Abfragen mit demselben query_hash unterschiedlich sein kann. Diese zusätzlichen Informationen sind nützlich, wenn Sie die Planleistung für eine Abfrage auswerten. Im obigen Beispiel hat jede Abfrage denselben query_plan_hash, 0x299275DD475C4B17, was zeigt, dass der Abfrageoptimierer auch bei unterschiedlichen Eingabewerten denselben Plan generiert – er ist stabil. Wenn mehrere query_plan_hash-Werte für denselben query_hash vorhanden sind, besteht eine Planvariabilität. In einem Szenario, in dem dieselbe Abfrage basierend auf query_hash tausende Male ausgeführt wird, besteht eine allgemeine Empfehlung darin, die Abfrage zu parametrisieren. Wenn Sie überprüfen können, dass keine Planvariabilität vorhanden ist, entfernt die Parametrisierung der Abfrage die Optimierungs- und Kompilierungszeit für jede Ausführung und kann die Gesamt-CPU reduzieren. In einigen Szenarien kann die Parametrisierung von fünf bis zehn Ad-hoc-Abfragen die Systemleistung insgesamt verbessern.
Zusammenfassung
Für jede Umgebung ist es wichtig zu verstehen, welche Abfragen in Bezug auf die Ressourcennutzung am teuersten sind und welche Abfragen am häufigsten ausgeführt werden. Bei Verwendung des DMV-Skripts von Glenn können für beide Analysetypen dieselben Abfragen angezeigt werden, was irreführend sein kann. Daher ist es wichtig festzustellen, ob die Arbeitsbelastung hauptsächlich prozedural, hauptsächlich ad hoc oder gemischt ist. Obwohl viel über die Vorteile gespeicherter Prozeduren dokumentiert ist, finde ich, dass gemischte oder stark ad-hoc-Workloads sehr häufig vorkommen, insbesondere bei Lösungen, die objektrelationale Mapper (ORMs) wie Entity Framework, NHibernate und LINQ to SQL verwenden. Wenn Sie sich über die Art der Arbeitslast für einen Server nicht im Klaren sind, ist das Ausführen der obigen Abfrage, um die am häufigsten ausgeführten Abfragen basierend auf einem query_hash anzuzeigen, ein guter Anfang. Wenn Sie anfangen, die Arbeitslast zu verstehen und was sowohl für die Schwergewichts- als auch für den Tod durch tausend Kürzungen-Abfragen vorhanden ist, können Sie die Ressourcennutzung und die Auswirkungen dieser Abfragen auf die Systemleistung wirklich verstehen und Ihre Bemühungen auf die Optimierung ausrichten.