Um die Unterstützung mehrerer Sprachen in Ihrem Datenmodell zu implementieren, müssen Sie das Rad nicht neu erfinden. Dieser Artikel zeigt Ihnen die verschiedenen Möglichkeiten, dies zu tun, und hilft Ihnen bei der Auswahl der für Sie am besten geeigneten.
Das Konzept der Lokalisierung ist für die Entwicklung einer Softwareanwendung von entscheidender Bedeutung, insbesondere wenn der Geltungsbereich dieser Anwendung global ist. Die Unterstützung mehrerer Sprachen ist der wichtigste zu berücksichtigende Aspekt; Ein Datenbankdesign, das eine mehrsprachige Anwendung unterstützt, ermöglicht es Ihnen, Ihre Zielmärkte zu diversifizieren und so viel mehr Kunden zu erreichen. Außerdem könnte ein solches Datenbankdesign Teil Ihrer langfristigen Strategie zum Entwerfen lokalisierungsbereiter Systeme sein.
Der Schlüssel zur Integration von mehrsprachiger Unterstützung in Ihre Anwendung besteht darin, dies so zu tun, dass die Entwicklungs- oder Wartungskosten nicht drastisch steigen. Da die Datenbankmodellierung ein untrennbarer Bestandteil des Softwareentwicklungsprozesses ist, müssen Sie über die beste Datenmodelldesignstrategie nachdenken, um Ihre Anwendung mehrsprachig zu unterstützen.
Ein geeignetes Datenmodell sollte es Ihnen ermöglichen, die Anwendung zu ändern oder neue Funktionen hinzuzufügen, während die Unterstützung mehrerer Sprachen beibehalten wird – ohne zusätzlichen Aufwand oder zusätzliche Kosten. Es sollte Ihnen auch ermöglichen, neue Sprachen zu integrieren, ohne die Anwendung zu berühren; Sie müssen lediglich die entsprechenden Übersetzungsdaten zur Datenbank hinzufügen.
Einfache Implementierung vs. Flexibilität und Funktionalität
Es gibt verschiedene Ansätze, um ein Datenbankdesign für mehrsprachige Anwendungen zu erstellen. Jedes hat seine Vor- und Nachteile. Diejenigen, die einfacher zu implementieren sind, bieten weniger Flexibilität und weniger Funktionalität; diejenigen, die mehr Flexibilität und Funktionalität bieten, haben komplexere Implementierungen.
Mein Rat hier ist, sich immer für diejenigen zu entscheiden, die mehr Funktionalität und Flexibilität bieten , auch wenn sie teurer in der Umsetzung sind. Manchmal machen wir den Fehler zu denken, dass eine Anwendung zu klein ist, dass es sich nicht lohnt, komplexe Schemas zu implementieren, um Dinge wie Mehrsprachenunterstützung zu lösen. Aber irgendwann wird diese Anwendung wachsen und wir werden es bereuen, uns für den „Quick and Dirty“-Ansatz entschieden zu haben, der einfacher und kostengünstiger erschien.
Das Ideal für die Implementierung von Zubehörfunktionen in eine Anwendung – sei es mehrsprachige Unterstützung, Änderungsprotokollierung, Benutzerauthentifizierung oder etwas anderes – besteht darin, dass diese Funktionalität über ein eigenes Unterschema und eine in wiederverwendbaren Komponenten gekapselte Logik verfügt. Auf diese Weise können sowohl die Zubehörfunktionalität als auch ihr Unterschema mit minimalem Aufwand in jede neue Anwendung integriert werden.
Ein intelligentes Datenbankdesign- und Datenmodellierungstool wie Vertabelo ist eine große Hilfe für die effiziente Verwaltung Ihrer Schemas und Subschemas. Sehen Sie sich auch diese Tipps für ein besseres Datenbankdesign an und stellen Sie sicher, dass Sie alle befolgen. Bevor Sie mit dem Zeichnen Ihres ER-Diagramms beginnen, empfehle ich Ihnen, diese wichtige Reihe von Tipps zur Datenbankmodellierung zu berücksichtigen.
Einige ansprechende (aber nicht empfehlenswerte) Lösungen für mehrsprachiges Datenbankdesign
Am einfachsten – aber am wenigsten empfohlen
Beginnen wir mit der am wenigsten empfohlenen, aber einfachsten Möglichkeit, eine mehrsprachige Anwendungsdatenbank zu implementieren. Es ermöglicht Ihnen, schnell die Notwendigkeit zu lösen, eine mehrsprachige Anwendung zu unterstützen, aber es wird Ihnen Probleme bereiten, wenn die Anwendung in der Funktionalität oder in der geografischen Abdeckung wächst.
Diese einfache Strategie besteht darin, für jede zu übersetzende Textspalte und für jede Sprache, in die die Texte übersetzt werden müssen, eine zusätzliche Spalte hinzuzufügen.
Zum Beispiel in Movies Tabelle unten gibt es einen OriginalTitle Feld. Für jede zu übersetzende Sprache wird eine zusätzliche Titelspalte hinzugefügt:
| MovieId | Originaltitel | Title_sp | Title_it | Titel_fr |
|---|---|---|---|---|
| 1 | Stirb langsam | Duro de matar | Kristalle Trappola | Kristallpiegel |
| 2 | Zurück in die Zukunft | Volver al futuro | Ritorno al futuro | Retour vers le futur |
| 3 | Jurassic Park | Parque jurásico | Giurassico Parco | Parc Jurassique |
Die Anwendung muss die Beschreibungsdaten aus der Spalte erhalten, die der vom Benutzer ausgewählten Sprache entspricht. Wenn Sie eine neue Sprache hinzufügen müssen, müssen Sie der Tabelle eine zusätzliche Spalte hinzufügen, die die in die neue Sprache übersetzten Texte enthält. Sie müssen auch die Anwendung anpassen, um die hinzugefügte Sprache und die hinzugefügten Spalten zu bestätigen.
Diese Lösung erfordert weder komplizierte JOINs, um die übersetzten Texte zu erhalten, noch doppelte Datensätze – nur die Replikation von Textinhaltsspalten. Aber seine Anwendbarkeit ist auf Situationen beschränkt, in denen nur wenige Tabellen übersetzt werden müssen.
Angenommen, Sie haben Products Tabelle und Processes Tisch. Jeder von ihnen hat ein Beschreibungsfeld, das übersetzt werden muss; scheint einfach genug, oder? Wenn jedoch die gesamte Anwendung (einschließlich aller Menüoptionen, Fehlermeldungen usw.) mehrsprachig sein muss, ist diese Lösung nicht anwendbar.
Vielseitiger, aber auch nicht ratsam
Um die Idee fortzusetzen, Übersetzungen innerhalb derselben Tabelle zu halten, besteht eine Alternative zur vorherigen Option darin, die Textfelder zu vergrößern. Dies würde es uns ermöglichen, alle Übersetzungen im selben Feld zu speichern und sie in einer Datenstruktur (z. B. einem XML-Dokument oder einem JSON-Objekt) zu organisieren. Unten haben wir ein Beispiel:
| MovieId | Originaltitel | Übersetzungen |
| 1 | Stirb langsam | [ {"Sprache":"sp", "Titel":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"Sprache":"fr", "Titel":"Piège de Cristal"} ] |
| 2 | Zurück in die Zukunft | [ {"Sprache":"sp", "Titel":"Volver al futuro"}, {"Sprache":"es", "Titel":"Ritorno al futuro"}, {"Sprache":"fr", "Titel":"Retour vers le futur"} ] |
| 3 | Jurassic Park | [ {"Sprache":"sp", "Titel":"Parque jurásico"}, {"Sprache":"es", "Titel":"Giurassico parco"}, {"Sprache":"fr", "Titel":"Parc jurassique"} ] |
Diese Option erfordert keine zusätzlichen Spalten, erhöht jedoch die Komplexität. Die Datenabfragen müssen nun in der Lage sein, die für die Mehrsprachenunterstützung verwendete Datenstruktur korrekt zu verarbeiten und zu interpretieren. Wenn beispielsweise JSON oder XML zum Speichern von Übersetzungen verwendet wird, müssen SQL-Abfragen eine SQL-Version verwenden, die den ausgewählten Datentyp unterstützt.
Der folgende SQL-Befehl verwendet den MS SQL Server OPENJSON() Funktion, um den Inhalt der Translations zu verwenden Feld als untergeordnete Tabelle:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Da es in Standard-SQL keine Funktionen oder Operatoren zum Bearbeiten von JSON- oder XML-formatierten Daten gibt, sind Sie gezwungen, Ihre Abfragen für ein bestimmtes RDBMS zu schreiben, wenn Sie diese Technik zum Speichern übersetzter Texte verwenden möchten. Beispielsweise wird die vorherige Abfrage von MySQL nicht unterstützt. Wenn Sie die JSON-Daten in den Movies table mit MySQL schreiben Sie diese Abfrage:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Speichern von übersetztem Text in verschiedenen Datensätzen
Sie können auch unterschiedliche Datensätze für jede Sprache verwenden. Allerdings müssen Sie sich damit abfinden, die Normalisierung zu verlieren:Dieselben Daten werden in mehreren Datensätzen wiederholt, in denen nur die Übersetzung variiert.
| MovieId | Sprach-ID | Titel |
|---|---|---|
| 1 | de | Stirb langsam |
| 1 | sp | Duro de matar |
| 1 | es | Kristalle Trappola |
| 1 | fr | Kristallpiegel |
| 2 | de | Zurück in die Zukunft |
| 2 | sp | Volver al futuro |
| 2 | es | Ritorno al futuro |
Mit dieser Option könnten Sie Ansichten jeder Tabelle erstellen, die nur die Zeilen in einer bestimmten Sprache zurückgeben:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Um die Tabelle dann abzufragen, könnten Sie je nach Zielsprache der Übersetzung eine andere Ansicht verwenden. Aber die Normalisierung des Modells geht verloren und die Tabellenpflege ist unnötig komplex.
Übersetzten Text in separaten Tabellen speichern
Eine Möglichkeit, die übersetzten Texte zu speichern, ohne das relationale Modell zu unterbrechen, besteht darin, eine Detailtabelle für jede Tabelle zu haben, die zu übersetzende Texte enthält. Die untergeordnete Tabelle mit den Übersetzungen muss dieselben Schlüsselfelder wie die Muttertabelle haben, plus ein Feld, das die Übersetzungssprache angibt.
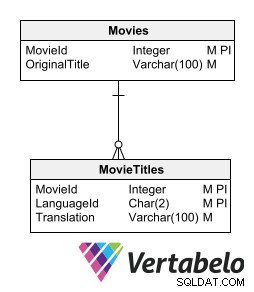
Eine untergeordnete Tabelle mit Übersetzungen muss dieselben Schlüsselfelder wie die Muttertabelle haben, plus ein Feld, das die Übersetzungssprache angibt.
Diese Option ermöglicht das Einbinden neuer Sprachen ohne Änderung der Tabellenstruktur. Es ist nicht erforderlich, redundante Informationen zu generieren oder die Modellnormalisierung zu unterbrechen.
Der Nachteil dieser Option besteht darin, dass für jede Tabelle, in der zu übersetzende Textdaten gespeichert sind, eine untergeordnete Tabelle erstellt werden muss. Die Idee, Übersetzungen in zusammengehörigen Tabellen zu speichern, bringt uns jedoch der empfehlenswertesten Methode zum Entwerfen einer mehrsprachigen Datenbank näher.
Die universelle Lösung:Ein Übersetzungs-Subschema
Damit eine Anwendung und ihre Datenbank wirklich mehrsprachig sind, sollten alle Texte eine Übersetzung in jede unterstützte Sprache haben – nicht nur die Textdaten in einer bestimmten Tabelle. Dies wird mit einem Übersetzungs-Subschema erreicht, in dem alle Daten mit Textinhalt gespeichert werden, die die Augen des Benutzers erreichen können.
In Webanwendungen, die für die Verwendung in verschiedenen Sprachen vorgesehen sind, ist ein Übersetzungssubschema eine Notwendigkeit, keine Option. Alles andere führt zu Komplexitäten, die eine ordnungsgemäße Wartung der Anwendung unmöglich machen.
Der Schlüssel zum Aufbewahren von Übersetzungen in einem separaten Schema besteht darin, einen indizierten Katalog mit allen Texten zu führen, die übersetzt werden müssen, unabhängig davon, ob es sich um Entitätsbeschreibungen, Fehlermeldungen oder Menüoptionen handelt. Die Idee ist, dass kein Text, der die Augen des Benutzers erreichen kann, in irgendeiner Tabelle außerhalb dieses Unterschemas gespeichert wird.
Eine Möglichkeit, den Übersetzungskatalog zu organisieren, besteht darin, drei Tabellen zu verwenden:
- Eine Haupttabelle von Sprachen.
- Eine Tabelle mit Texten in der Originalsprache.
- Eine Tabelle mit übersetzten Texten.
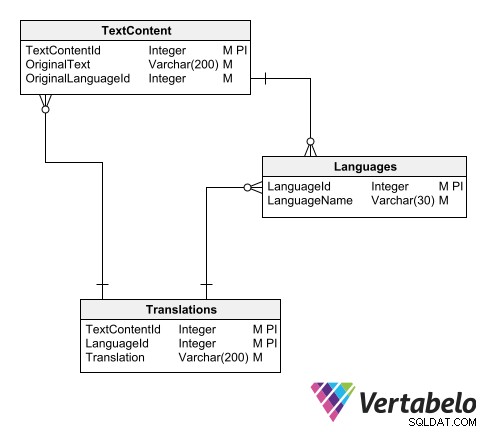
Schema für einen universellen Übersetzungskatalog.
In der Haupttabelle der Sprachen fügen wir einfach einen Datensatz für jede vom Datenmodell unterstützte Sprache ein. Jeder hat einen ID-Code und einen Namen:
| LanguageId | Sprachname |
|---|---|
| en | Englisch |
| sp | Spanisch |
| es | Italienisch |
| fr | Französisch |
Die Texttabelle erfasst alle zu übersetzenden Texte. Jeder Datensatz hat eine beliebige ID, den Originaltext und die ID der Originalsprache.
Im TextContent Tabelle, der Originaltext und die Kennung der Originalsprache sind nicht zwingend erforderlich. Aber sie vereinfachen Abfragen, die keine Übersetzung erfordern. Wenn Sie beispielsweise statistische Analysen oder Verwaltungskontrollabfragen durchführen (die normalerweise nur Benutzern zur Verfügung stehen, die die Originalsprache verstehen), können die Abfragen vereinfacht werden, indem die Standardtexte (nicht übersetzt) verwendet werden.
Die Originaltexte sind auch für diejenigen nützlich, die die Tabelle der übersetzten Texte ausfüllen müssen. Die Eingabe von Übersetzungsdaten kann mithilfe einer Minianwendung erfolgen, die den Originaltext und Übersetzungen in allen verfügbaren Sprachen anzeigt. Es ist auch möglich, Informationen für das Übersetzungssubschema durch einen automatischen Prozess unter Verwendung einer Übersetzungs-API zu generieren.
Verknüpfung mit dem Hauptschema
Im Hauptschema der Anwendung werden Spalten mit zu übersetzenden Textwerten durch IDs ersetzt, die auf die Tabelle der übersetzten Texte verweisen:
Das Hauptschema ist mit dem Übersetzungsschema durch Tabellen mit zu übersetzenden Texten verknüpft.
Sie können das ursprüngliche Textfeld in einigen der Hauptschematabellen belassen, um Abfragen zu erleichtern, bei denen keine Übersetzung erforderlich ist, obwohl dies redundante Informationen erzeugt. Zum Beispiel könnten wir die ProductDescription behalten im Feld Products Tabelle, um statistische Abfragen zu vereinfachen oder die Dimensionen eines Data Warehouse zu füllen, wobei das Übersetzungssubschema beiseite gelassen wird, wenn es nicht benötigt wird.
- Mehrsprachiges Datenbankdesign:Mach es einmal und mach es richtig
Wir haben mehrere Alternativen zum Erstellen eines mehrsprachigen Datenbankdesigns gesehen. Einige sind einfacher und schneller zu implementieren. Die letzte Lösung ist etwas komplexer, gibt Ihnen aber viel mehr Flexibilität. Es erspart Ihnen auch Ärger, wenn es an der Zeit ist, die Anwendung und die Datenbank zu warten. Auf lange Sicht wird es also viel günstiger.
Manchmal verleitet Sie der kürzeste Weg im Datenbankdesign zu der Annahme, dass Sie Zeit und Mühe sparen. Aber wenn Sie es wählen, übersehen Sie die Tatsache, dass Sie es wahrscheinlich mehrmals hinuntergehen müssen. Wenn Sie die Best Practices für das Design mehrsprachiger Datenbanken ignorieren, werden Sie am Ende wahrscheinlich immer wieder die gleiche Arbeit machen.