Vielleicht denken Sie, dass die Datenbankpflege Sie nichts angeht. Aber wenn Sie Ihre Modelle proaktiv entwerfen, erhalten Sie Datenbanken, die denen das Leben erleichtern, die sie pflegen müssen.
Ein gutes Datenbankdesign erfordert Proaktivität, eine angesehene Qualität in jeder Arbeitsumgebung. Falls Sie mit dem Begriff nicht vertraut sind, ist Proaktivität die Fähigkeit, Probleme zu antizipieren und Lösungen parat zu haben, wenn Probleme auftreten – oder noch besser, so zu planen und zu handeln, dass Probleme gar nicht erst auftreten.
Arbeitgeber verstehen, dass die Eigeninitiative ihrer Mitarbeiter oder Auftragnehmer mit Kosteneinsparungen gleichzusetzen ist. Deshalb schätzen sie es und ermutigen die Leute, es zu praktizieren.
In Ihrer Rolle als Datenmodellierer können Sie Proaktivität am besten demonstrieren, indem Sie Modelle entwerfen, die Probleme antizipieren und vermeiden, die routinemäßig die Datenbankwartung plagen. Oder zumindest die Lösung dieser Probleme erheblich vereinfachen.
Auch wenn Sie nicht für die Datenbankwartung verantwortlich sind, bietet die Modellierung für eine einfache Datenbankwartung viele Vorteile. Zum Beispiel verhindert es, dass Sie zu irgendeinem Zeitpunkt angerufen werden, um Datennotfälle zu lösen, die wertvolle Zeit kosten, die Sie für Design- oder Modellierungsaufgaben aufwenden könnten, die Ihnen so viel Spaß machen!
Das Leben für die IT-Leute einfacher machen
Beim Entwerfen unserer Datenbanken müssen wir über die Bereitstellung eines DER und die Generierung von Aktualisierungsskripten hinausdenken. Sobald eine Datenbank in Produktion geht, müssen sich Wartungsingenieure mit allen möglichen möglichen Problemen befassen, und ein Teil unserer Aufgabe als Datenbankmodellierer besteht darin, die Wahrscheinlichkeit zu minimieren, dass diese Probleme auftreten.
Sehen wir uns zunächst an, was es bedeutet, ein gutes Datenbankdesign zu erstellen, und wie sich diese Aktivität auf regelmäßige Datenbankwartungsaufgaben bezieht.
Was ist Datenmodellierung?
Datenmodellierung ist die Aufgabe, eine abstrakte, meist grafische Darstellung eines Informationsspeichers zu erstellen. Das Ziel der Datenmodellierung besteht darin, die Attribute und die Beziehungen zwischen den Entitäten offenzulegen, deren Daten im Repository gespeichert sind.
Datenmodelle werden um die Anforderungen eines Geschäftsproblems herum aufgebaut. Regeln und Anforderungen werden im Voraus durch Beiträge von Geschäftsexperten definiert, sodass sie in das Design eines neuen Datenspeichers integriert oder bei der Iteration eines bestehenden angepasst werden können.
Im Idealfall sind Datenmodelle lebendige Dokumente, die sich mit den sich ändernden Geschäftsanforderungen weiterentwickeln. Sie spielen eine wichtige Rolle bei der Unterstützung von Geschäftsentscheidungen und bei der Planung von Systemarchitektur und -strategie. Die Datenmodelle müssen mit den Datenbanken, die sie darstellen, synchron gehalten werden, damit sie für die Wartungsroutinen dieser Datenbanken nützlich sind.
Allgemeine Herausforderungen bei der Datenbankwartung
Die Pflege einer Datenbank erfordert eine ständige Überwachung, automatisiert oder anderweitig, um sicherzustellen, dass sie ihre Vorteile nicht verliert. Best Practices für die Datenbankwartung stellen sicher, dass Datenbanken immer Folgendes behalten:
- Integrität und Qualität der Informationen
- Leistung
- Verfügbarkeit
- Skalierbarkeit
- Anpassbarkeit an Änderungen
- Rückverfolgbarkeit
- Sicherheit
Es stehen viele Datenmodellierungstipps zur Verfügung, die Ihnen dabei helfen, jedes Mal ein gutes Datenbankdesign zu erstellen. Die unten diskutierten zielen speziell darauf ab, die Aufrechterhaltung der oben genannten Datenbankqualitäten sicherzustellen oder zu erleichtern.
Integrität und Informationsqualität
Ein grundlegendes Ziel der Best Practices für die Datenbankwartung besteht darin, sicherzustellen, dass die Informationen in der Datenbank ihre Integrität bewahren. Dies ist entscheidend, damit die Benutzer den Informationen vertrauen können.
Es gibt zwei Arten von Integrität:physische Integrität und logische Integrität .
Physische Integrität
Die Aufrechterhaltung der physischen Integrität einer Datenbank erfolgt durch den Schutz der Informationen vor externen Faktoren wie Hardware- oder Stromausfällen. Der gebräuchlichste und am weitesten verbreitete Ansatz ist eine angemessene Sicherungsstrategie, die die Wiederherstellung einer Datenbank in angemessener Zeit ermöglicht, wenn sie durch eine Katastrophe zerstört wird.
Für DBAs und Serveradministratoren, die Datenbankspeicher verwalten, ist es hilfreich zu wissen, ob Datenbanken in Abschnitte mit unterschiedlichen Aktualisierungshäufigkeiten partitioniert werden können. Dadurch können sie die Speichernutzung und Backup-Pläne optimieren.
Datenmodelle können diese Aufteilung widerspiegeln, indem sie Bereiche mit unterschiedlichen Daten-„Temperaturen“ identifizieren und Einheiten in diesen Bereichen gruppieren. „Temperatur“ bezieht sich auf die Häufigkeit, mit der Tabellen neue Informationen erhalten. Tabellen, die sehr häufig aktualisiert werden, sind die „heißesten“; diejenigen, die nie oder selten aktualisiert werden, sind die „kältesten“.

Datenmodell eines E-Commerce-Systems, das heiße, warme und kalte Daten unterscheidet.
Ein DBA oder Systemadministrator kann diese logische Gruppierung verwenden, um die Datenbankdateien zu partitionieren und unterschiedliche Sicherungspläne für jede Partition zu erstellen.
Logische Integrität
Die Aufrechterhaltung der logischen Integrität einer Datenbank ist für die Zuverlässigkeit und Nützlichkeit der von ihr bereitgestellten Informationen von entscheidender Bedeutung. Fehlt es einer Datenbank an logischer Integrität, decken die Anwendungen, die sie verwenden, früher oder später Inkonsistenzen in den Daten auf. Angesichts dieser Ungereimtheiten misstrauen Benutzer den Informationen und suchen einfach nach zuverlässigeren Datenquellen.
Unter den Datenbankwartungsaufgaben ist die Aufrechterhaltung der logischen Integrität der Informationen eine Erweiterung der Datenbankmodellierungsaufgabe, nur dass sie beginnt, nachdem die Datenbank in Betrieb genommen wurde, und während ihrer gesamten Lebensdauer fortgesetzt wird. Der kritischste Teil dieses Wartungsbereichs ist die Anpassung an Änderungen.
Änderungsmanagement
Änderungen an Geschäftsregeln oder Anforderungen sind eine ständige Bedrohung für die logische Integrität von Datenbanken. Möglicherweise sind Sie mit dem von Ihnen erstellten Datenmodell zufrieden, da Sie wissen, dass es perfekt an das Unternehmen angepasst ist, auf jede Anfrage mit den richtigen Informationen antwortet und Anomalien beim Einfügen, Aktualisieren oder Löschen auslässt. Genießen Sie diesen Moment der Zufriedenheit, denn er ist nur von kurzer Dauer!
Bei der Pflege einer Datenbank muss man sich der Notwendigkeit stellen, täglich Änderungen am Modell vorzunehmen. Es zwingt Sie, neue Objekte hinzuzufügen oder die vorhandenen zu ändern, die Kardinalität der Beziehungen zu ändern, Primärschlüssel neu zu definieren, Datentypen zu ändern und andere Dinge zu tun, die uns Modellierer erschaudern lassen.
Änderungen passieren ständig. Es kann sein, dass eine Anforderung von Anfang an falsch erklärt wurde, neue Anforderungen aufgetaucht sind oder Sie unbeabsichtigt einen Fehler in Ihr Modell eingeführt haben (schließlich sind wir Datenmodellierer nur Menschen).
Ihre Modelle müssen einfach zu modifizieren sein, wenn ein Änderungsbedarf entsteht. Es ist wichtig, ein Datenbankdesign-Tool für die Modellierung zu verwenden, das es Ihnen ermöglicht, Ihre Modelle zu versionieren, Skripte zu generieren, um eine Datenbank von einer Version zu einer anderen zu migrieren, und jede Designentscheidung ordnungsgemäß zu dokumentieren.
Ohne diese Tools führt jede Änderung, die Sie an Ihrem Design vornehmen, zu Integritätsrisiken, die zu den ungünstigsten Zeiten ans Licht kommen. Vertabelo bietet Ihnen all diese Funktionen und kümmert sich um die Pflege des Versionsverlaufs eines Modells, ohne dass Sie sich darüber Gedanken machen müssen.
Die in Vertabelo integrierte automatische Versionierung ist eine enorme Hilfe bei der Pflege von Änderungen an einem Datenmodell.
Änderungsmanagement und Versionskontrolle sind ebenfalls entscheidende Faktoren bei der Einbettung von Datenmodellierungsaktivitäten in den Lebenszyklus der Softwareentwicklung.
Refaktorisierung
Wenn Sie Änderungen an einer verwendeten Datenbank vornehmen, müssen Sie zu 100 % sicher sein, dass keine Informationen verloren gehen und ihre Integrität durch die Änderungen nicht beeinträchtigt wird. Dazu können Sie Refactoring-Techniken verwenden. Sie werden normalerweise angewendet, wenn Sie ein Design verbessern möchten, ohne seine Semantik zu beeinträchtigen, aber sie können auch verwendet werden, um Designfehler zu korrigieren oder ein Modell an neue Anforderungen anzupassen.
Es gibt eine Vielzahl von Refactoring-Techniken. Sie werden normalerweise eingesetzt, um veralteten Datenbanken neues Leben einzuhauchen, und es gibt Lehrbuchverfahren, die sicherstellen, dass die Änderungen die vorhandenen Informationen nicht beschädigen. Ganze Bücher sind darüber geschrieben worden; Ich empfehle Ihnen, sie zu lesen.
Aber zusammenfassend können wir Refactoring-Techniken in die folgenden Kategorien einteilen:
- Datenqualität: Änderungen vornehmen, die Datenkonsistenz und -kohärenz sicherstellen. Beispiele sind das Hinzufügen einer Nachschlagetabelle und das Migrieren von Daten, die in einer anderen Tabelle wiederholt werden, und das Hinzufügen einer Einschränkung für eine Spalte.
- Strukturell: Änderungen an Tabellenstrukturen vornehmen, die die Semantik des Modells nicht verändern. Beispiele hierfür sind das Kombinieren von zwei Spalten zu einer, das Hinzufügen eines Ersatzschlüssels und das Teilen einer Spalte in zwei.
- Referentielle Integrität: Anwenden von Änderungen, um sicherzustellen, dass eine referenzierte Zeile in einer verknüpften Tabelle vorhanden ist oder dass eine nicht referenzierte Zeile gelöscht werden kann. Beispiele sind das Hinzufügen einer Fremdschlüssel-Einschränkung für eine Spalte und das Hinzufügen einer Nicht-Nullwert-Einschränkung zu einer Tabelle.
- Architektur: Vornehmen von Änderungen, die darauf abzielen, die Interaktion von Anwendungen mit der Datenbank zu verbessern. Beispiele hierfür sind das Erstellen eines Indexes, das Festlegen einer schreibgeschützten Tabelle und das Kapseln einer oder mehrerer Tabellen in einer Ansicht.
Techniken, die die Semantik des Modells ändern, sowie solche, die das Datenmodell in keiner Weise verändern, gelten nicht als Refactoring-Techniken. Dazu gehören das Einfügen von Zeilen in eine Tabelle, das Hinzufügen einer neuen Spalte, das Erstellen einer neuen Tabelle oder Ansicht und das Aktualisieren der Daten in einer Tabelle.
Aufrechterhaltung der Informationsqualität
Die Informationsqualität in einer Datenbank ist der Grad, in dem die Daten die Erwartungen der Organisation an Genauigkeit, Gültigkeit, Vollständigkeit und Konsistenz erfüllen. Die Aufrechterhaltung der Datenqualität während des gesamten Lebenszyklus einer Datenbank ist für ihre Benutzer von entscheidender Bedeutung, um anhand der darin enthaltenen Daten korrekte und fundierte Entscheidungen treffen zu können.
Ihre Verantwortung als Datenmodellierer besteht darin, sicherzustellen, dass Ihre Modelle ihre Informationsqualität auf dem höchstmöglichen Niveau halten. Dazu:
- Das Design muss mindestens der 3. Normalform folgen, damit keine Anomalien beim Einfügen, Aktualisieren oder Löschen auftreten. Diese Überlegung gilt hauptsächlich für Datenbanken zur transaktionalen Verwendung, bei denen Daten regelmäßig hinzugefügt, aktualisiert und gelöscht werden. Es gilt nicht unbedingt in Datenbanken für analytische Zwecke (d. h. Data Warehouses), da Datenaktualisierung und -löschung selten, wenn überhaupt, durchgeführt werden.
- Die Datentypen jedes Felds in jeder Tabelle müssen dem Attribut entsprechen, das sie im logischen Modell darstellen. Dies geht über die richtige Definition hinaus, ob ein Feld einen numerischen, Datums- oder alphanumerischen Datentyp hat. Es ist auch wichtig, den Bereich und die Genauigkeit der von jedem Feld unterstützten Werte richtig zu definieren. Ein Beispiel:Ein Attribut vom Typ Datum, das in einer Datenbank als Datums-/Uhrzeitfeld implementiert ist, kann Probleme in Abfragen verursachen, da ein Wert, der mit einem anderen Zeitteil als Null gespeichert wird, außerhalb des Geltungsbereichs einer Abfrage liegen kann, die einen Datumsbereich verwendet.
- Die Dimensionen und Fakten, die die Struktur eines Data Warehouse definieren, müssen mit den Anforderungen des Unternehmens übereinstimmen. Beim Design eines Data Warehouse müssen die Dimensionen und Fakten des Modells von Anfang an richtig definiert werden. Änderungen vorzunehmen, sobald die Datenbank in Betrieb ist, ist mit sehr hohen Wartungskosten verbunden.
Wachstum managen
Eine weitere große Herausforderung bei der Wartung einer Datenbank besteht darin, zu verhindern, dass ihr Wachstum unerwartet die Speicherkapazitätsgrenze erreicht. Um bei der Speicherplatzverwaltung zu helfen, können Sie dasselbe Prinzip wie bei Backup-Prozeduren anwenden:Gruppieren Sie die Tabellen in Ihrem Modell entsprechend ihrer Wachstumsrate.
Eine Unterteilung in zwei Bereiche ist in der Regel ausreichend. Platzieren Sie die Tabellen mit häufigen Zeilenergänzungen in einem Bereich, die Tabellen, in die selten Zeilen eingefügt werden, in einen anderen. Wenn das Modell auf diese Weise in Sektoren unterteilt ist, können Speicheradministratoren die Datenbankdateien gemäß der Wachstumsrate jedes Bereichs partitionieren. Sie können die Partitionen auf verschiedene Speichermedien mit unterschiedlichen Kapazitäten oder Erweiterungsmöglichkeiten verteilen.
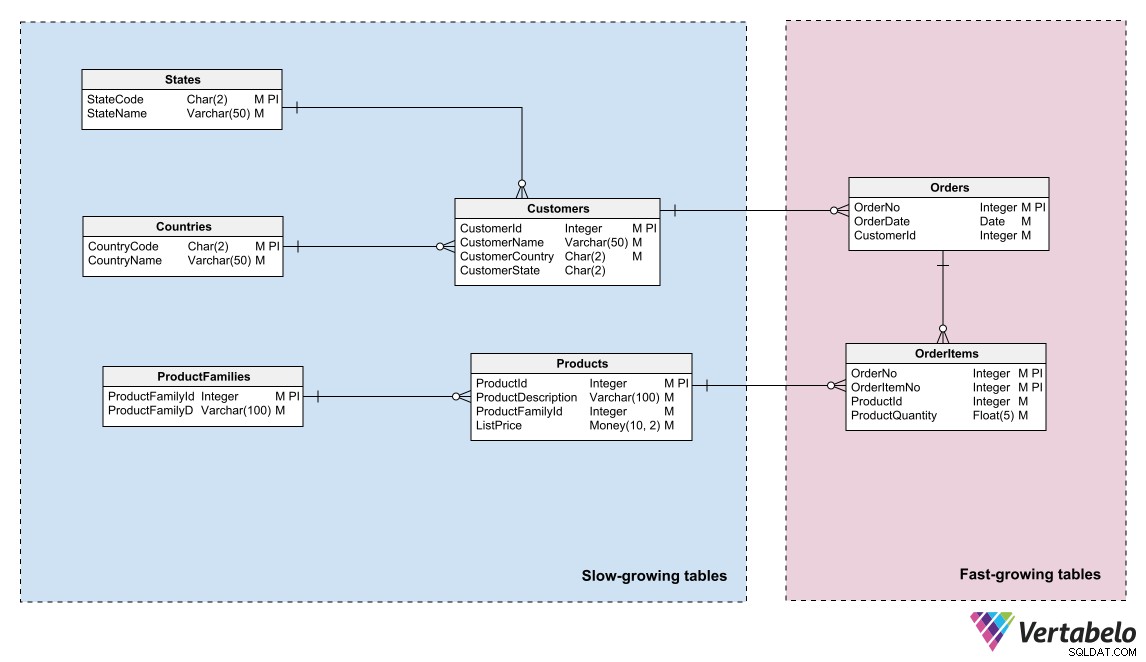
Eine Gruppierung von Tabellen nach ihrer Wachstumsrate hilft dabei, die Speicheranforderungen zu bestimmen und ihr Wachstum zu verwalten.
Protokollierung
Wir erstellen ein Datenmodell in der Erwartung, dass es die Informationen so bereitstellt, wie sie zum Zeitpunkt der Abfrage vorliegen. Wir neigen jedoch dazu, die Notwendigkeit einer Datenbank zu übersehen, die sich an alles erinnert, was in der Vergangenheit passiert ist, es sei denn, die Benutzer verlangen dies ausdrücklich.
Ein Teil der Pflege einer Datenbank besteht darin, zu wissen, wie, wann, warum und von wem ein bestimmtes Datenelement geändert wurde. Dies kann beispielsweise sein, um herauszufinden, wann sich ein Produktpreis geändert hat, oder um Änderungen in der Krankenakte eines Patienten in einem Krankenhaus zu überprüfen. Die Protokollierung kann sogar zum Korrigieren von Benutzer- oder Anwendungsfehlern verwendet werden, da Sie den Informationsstand auf einen Zeitpunkt in der Vergangenheit zurücksetzen können, ohne auf komplizierte Backup-Wiederherstellungsverfahren zurückgreifen zu müssen.
Auch wenn die Benutzer dies nicht ausdrücklich benötigen, ist die Berücksichtigung der Notwendigkeit einer proaktiven Protokollierung ein sehr wertvolles Mittel, um die Datenbankwartung zu erleichtern und Ihre Fähigkeit zu demonstrieren, Probleme vorherzusehen. Das Vorhandensein von Protokolldaten ermöglicht sofortige Reaktionen, wenn jemand historische Informationen überprüfen muss.
Es gibt verschiedene Strategien für ein Datenbankmodell zur Unterstützung der Protokollierung, die alle das Modell komplexer machen. Ein Ansatz wird als direkte Protokollierung bezeichnet, bei der jeder Tabelle Spalten hinzugefügt werden, um Versionsinformationen aufzuzeichnen. Dies ist eine einfache Option, bei der keine separaten Schemas oder protokollierungsspezifischen Tabellen erstellt werden müssen. Es wirkt sich jedoch auf das Modelldesign aus, da die ursprünglichen Primärschlüssel der Tabellen nicht mehr als Primärschlüssel gültig sind – ihre Werte werden in Zeilen wiederholt, die verschiedene Versionen derselben Daten darstellen.
Eine weitere Option zum Aufbewahren von Protokollinformationen ist die Verwendung von Schattentabellen. Schattentabellen sind Repliken der Modelltabellen mit zusätzlichen Spalten zum Aufzeichnen von Log-Trail-Daten. Diese Strategie erfordert keine Änderung der Tabellen im ursprünglichen Modell, aber Sie müssen daran denken, die entsprechenden Schattentabellen zu aktualisieren, wenn Sie Ihr Datenmodell ändern.
Eine weitere Strategie besteht darin, ein Unterschema generischer Tabellen zu verwenden, die jede Einfügung, Löschung oder Änderung an einer anderen Tabelle aufzeichnen.
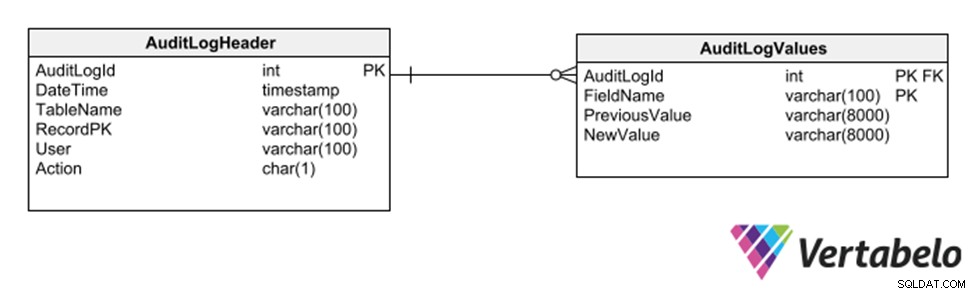
Generische Tabellen, um einen Audit-Trail einer Datenbank zu führen.
Diese Strategie hat den Vorteil, dass keine Änderungen am Modell zum Aufzeichnen eines Audit-Trails erforderlich sind. Da es jedoch generische Spalten des Typs varchar verwendet, schränkt es die Datentypen ein, die im Protokollpfad aufgezeichnet werden können.
Leistungspflege und Indexerstellung
Praktisch jede Datenbank hat eine gute Leistung, wenn sie gerade erst verwendet wird und ihre Tabellen nur wenige Zeilen enthalten. Aber sobald Anwendungen beginnen, es mit Daten zu füllen, kann die Leistung sehr schnell abnehmen, wenn beim Entwerfen des Modells keine Vorsichtsmaßnahmen getroffen werden. In diesem Fall bitten DBAs und Systemadministratoren Sie um Hilfe bei der Lösung von Leistungsproblemen.
Die automatische Erstellung/Vorschlagung von Indizes auf Produktionsdatenbanken ist ein nützliches Werkzeug, um Performance-Probleme „in der Hitze des Gefechts“ zu lösen. Datenbank-Engines können Datenbankaktivitäten analysieren, um zu sehen, welche Vorgänge am längsten dauern und wo Möglichkeiten zur Beschleunigung durch das Erstellen von Indizes bestehen.
Es ist jedoch viel besser, proaktiv zu sein und die Situation zu antizipieren, indem Sie Indizes als Teil des Datenmodells definieren. Dadurch wird der Wartungsaufwand zur Verbesserung der Datenbankleistung erheblich reduziert. Wenn Sie mit den Vorteilen von Datenbankindizes nicht vertraut sind, empfehle ich Ihnen, alles über Indizes zu lesen, beginnend mit den Grundlagen.
Es gibt praktische Regeln, die genügend Anleitungen zum Erstellen der wichtigsten Indizes für effiziente Abfragen geben. Die erste besteht darin, Indizes für den Primärschlüssel jeder Tabelle zu generieren. Praktisch jedes RDBMS generiert automatisch einen Index für jeden Primärschlüssel, sodass Sie diese Regel vergessen können.
Eine weitere Regel besteht darin, Indizes für alternative Schlüssel einer Tabelle zu generieren, insbesondere in Tabellen, für die ein Ersatzschlüssel erstellt wird. Wenn eine Tabelle einen natürlichen Schlüssel hat, der nicht als Primärschlüssel verwendet wird, verwenden Abfragen, um diese Tabelle mit anderen zu verknüpfen, höchstwahrscheinlich den natürlichen Schlüssel und nicht den Ersatz. Diese Abfragen funktionieren nicht gut, es sei denn, Sie erstellen einen Index für den natürlichen Schlüssel.
Die nächste Faustregel für Indizes ist, sie für alle Felder zu generieren, die Fremdschlüssel sind. Diese Felder eignen sich hervorragend zum Herstellen von Verknüpfungen mit anderen Tabellen. Wenn sie in Indizes enthalten sind, werden sie von Abfrageparsern verwendet, um die Ausführung zu beschleunigen und die Datenbankleistung zu verbessern.
Schließlich ist es eine gute Idee, während Leistungstests ein Profilerstellungstool für eine Staging- oder QA-Datenbank zu verwenden, um nicht offensichtliche Gelegenheiten zur Indexerstellung zu erkennen. Die Integration der von den Profiling-Tools vorgeschlagenen Indizes in das Datenmodell ist äußerst hilfreich, um die Leistung der Datenbank zu erreichen und aufrechtzuerhalten, sobald sie in Produktion ist.
Sicherheit
In Ihrer Rolle als Datenmodellierer können Sie zur Aufrechterhaltung der Datenbanksicherheit beitragen, indem Sie eine solide und sichere Basis zum Speichern von Daten für die Benutzerauthentifizierung bereitstellen. Denken Sie daran, dass diese Informationen hochsensibel sind und keinen Cyberangriffen ausgesetzt werden dürfen.
Damit Ihr Design die Wartung der Datenbanksicherheit vereinfacht, befolgen Sie die bewährten Methoden zum Speichern von Authentifizierungsdaten, von denen die wichtigste darin besteht, Kennwörter nicht einmal in verschlüsselter Form in der Datenbank zu speichern. Das Speichern nur seines Hashs anstelle des Passworts für jeden Benutzer ermöglicht es einer Anwendung, eine Benutzeranmeldung zu authentifizieren, ohne ein Risiko der Passwortoffenlegung zu schaffen.
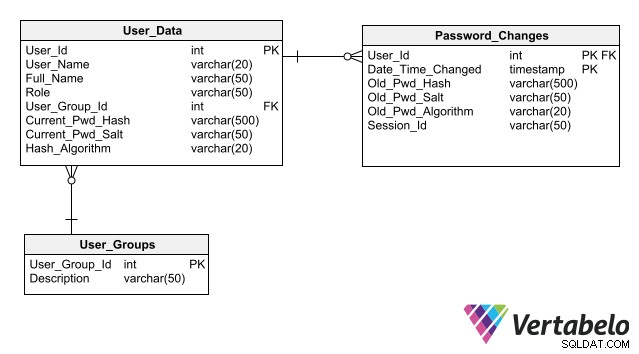
Ein vollständiges Schema für die Benutzerauthentifizierung, das Spalten zum Speichern von Passwort-Hashes enthält.
Vision für die Zukunft
Erstellen Sie also Ihre Modelle für eine einfache Datenbankwartung mit guten Datenbankdesigns, indem Sie die oben genannten Tipps berücksichtigen. Mit besser wartbaren Datenmodellen sieht Ihre Arbeit besser aus und Sie gewinnen die Wertschätzung von DBAs, Wartungstechnikern und Systemadministratoren.
Sie investieren auch in Seelenfrieden. Das Erstellen leicht zu wartender Datenbanken bedeutet, dass Sie Ihre Arbeitszeit damit verbringen können, neue Datenmodelle zu entwerfen, anstatt herumzulaufen und Datenbanken zu patchen, die nicht rechtzeitig die richtigen Informationen liefern.