Bei Stack Overflow haben wir einige Tabellen, die gruppierte Columnstore-Indizes verwenden, und diese funktionieren hervorragend für den Großteil unserer Arbeitslast. Aber wir sind kürzlich auf eine Situation gestoßen, in der „perfekte Stürme“ – mehrere Prozesse, die alle versuchten, aus demselben CCI zu löschen – die CPU überwältigten, da sie alle weitgehend parallel liefen und darum kämpften, ihre Operation abzuschließen. So sah es in SolarWinds SQL Sentry aus:
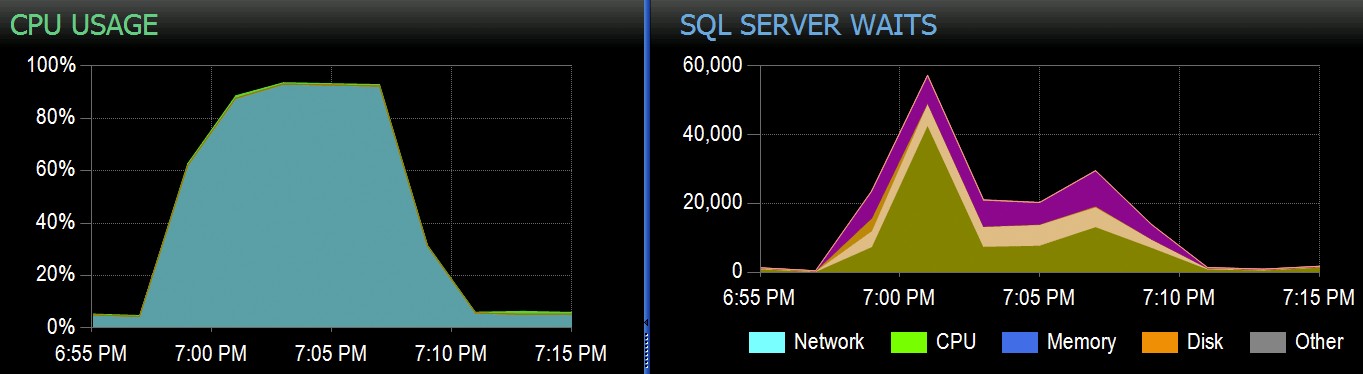
Und hier sind die interessanten Wartezeiten, die mit diesen Abfragen verbunden sind:
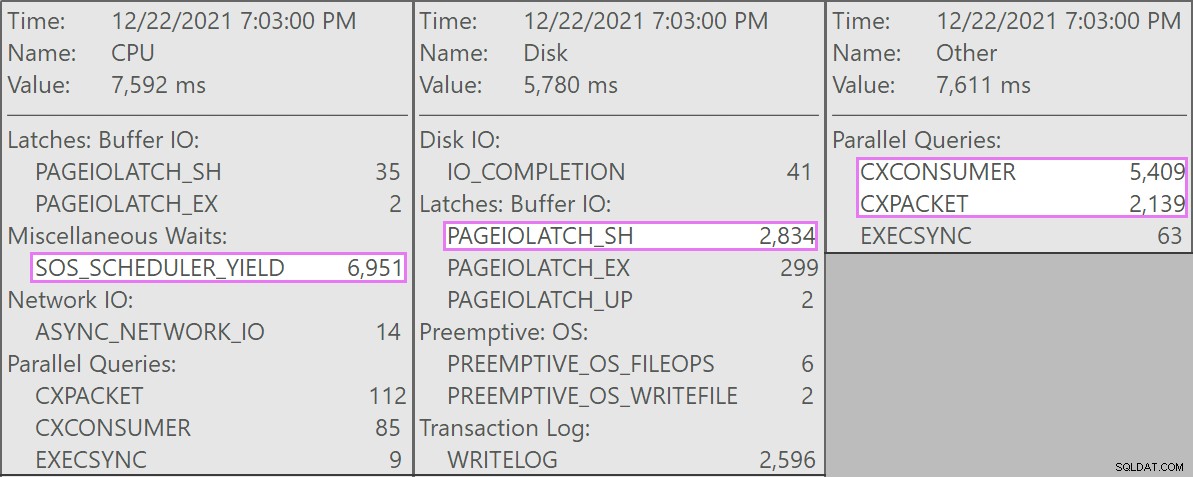
Die konkurrierenden Abfragen hatten alle folgende Form:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Der Plan sah so aus:

Und die Warnung auf dem Scan wies uns auf einige ziemlich extreme Rest-E/A hin:

Die Tabelle hat 1,9 Milliarden Zeilen, ist aber nur 32 GB groß (Danke, spaltenorientierter Speicher!). Dennoch würden diese einzelnen Zeilenlöschungen jeweils 10 bis 15 Sekunden dauern, wobei die meiste Zeit für SOS_SCHEDULER_YIELD aufgewendet wird .
Da in diesem Szenario der Löschvorgang asynchron sein könnte, konnten wir das Problem zum Glück mit zwei Änderungen lösen (obwohl ich hier stark vereinfache):
- Wir haben
MAXDOPeingeschränkt auf Datenbankebene, sodass diese Löschungen nicht ganz so parallel verlaufen können - Wir haben die Serialisierung der von der Anwendung kommenden Prozesse verbessert (im Grunde haben wir Löschvorgänge über einen einzigen Dispatcher in die Warteschlange gestellt)
Als DBA können wir MAXDOP leicht steuern , es sei denn, es wird auf Abfrageebene überschrieben (ein weiteres Kaninchenloch für einen anderen Tag). Wir können die Anwendung nicht unbedingt in diesem Umfang kontrollieren, insbesondere wenn sie vertrieben wird oder nicht von uns stammt. Wie können wir in diesem Fall die Schreibvorgänge serialisieren, ohne die Anwendungslogik drastisch zu ändern?
Ein Mock-Setup
Ich werde nicht versuchen, lokal eine Tabelle mit zwei Milliarden Zeilen zu erstellen – ganz zu schweigen von der genauen Tabelle –, aber wir können etwas in kleinerem Maßstab annähern und versuchen, dasselbe Problem zu reproduzieren.
Nehmen wir an, dies sind die SuggestedEdits Tabelle (in Wirklichkeit ist es nicht). Aber es ist ein einfach zu verwendendes Beispiel, da wir das Schema aus dem Stack Exchange Data Explorer abrufen können. Auf dieser Grundlage können wir eine äquivalente Tabelle erstellen (mit ein paar geringfügigen Änderungen, um das Auffüllen zu erleichtern) und einen gruppierten Columnstore-Index darauf werfen:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Um es mit 100 Millionen Zeilen zu füllen, können wir sys.all_objects über Kreuz verbinden und sys.all_columns fünfmal (auf meinem System erzeugt dies jedes Mal 2,68 Millionen Zeilen, aber YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Dann können wir das Leerzeichen überprüfen:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
Es sind nur 1,3 GB, aber das sollte ausreichen:

Nachahmung unseres Clustered Columnstore Delete
Hier ist eine einfache Abfrage, die grob dem entspricht, was unsere Anwendung mit der Tabelle gemacht hat:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
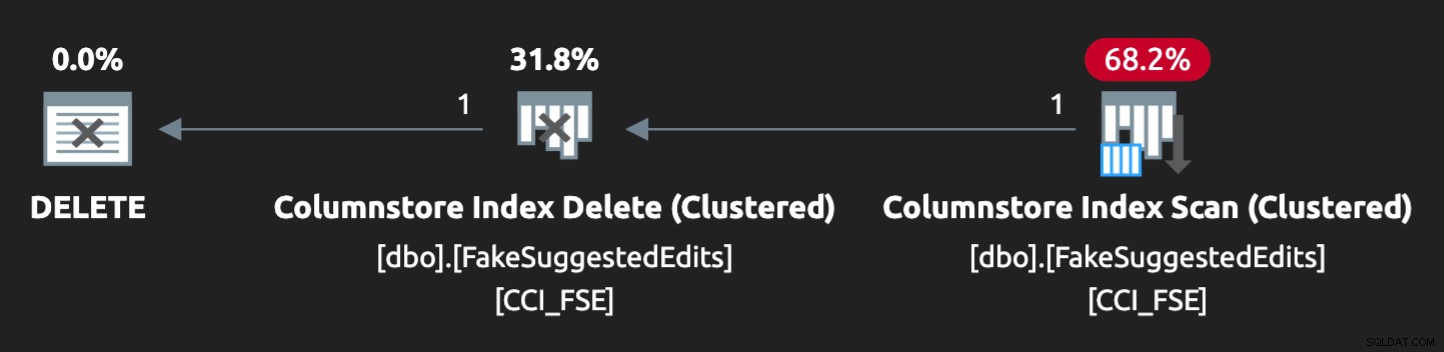
Der Plan passt jedoch nicht ganz perfekt zusammen:
Damit es parallel läuft und auf meinem mageren Laptop ähnliche Konflikte erzeugt, musste ich den Optimierer mit diesem Hinweis ein wenig zwingen:
OPTION (QUERYTRACEON 8649);
Jetzt sieht es richtig aus:

Reproduzieren des Problems
Dann können wir mit SqlStressCmd eine Welle gleichzeitiger Löschaktivitäten erzeugen, um 1.000 zufällige Zeilen mit 16 und 32 Threads zu löschen:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Wir können die Belastung beobachten, die dies auf die CPU ausübt:
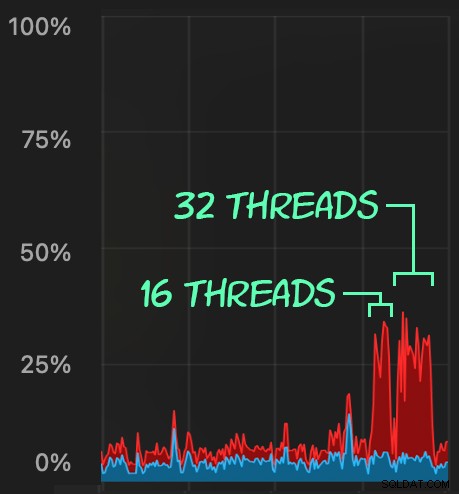
Die CPU-Belastung hält über die gesamten Batches hinweg etwa 64 bzw. 130 Sekunden an:
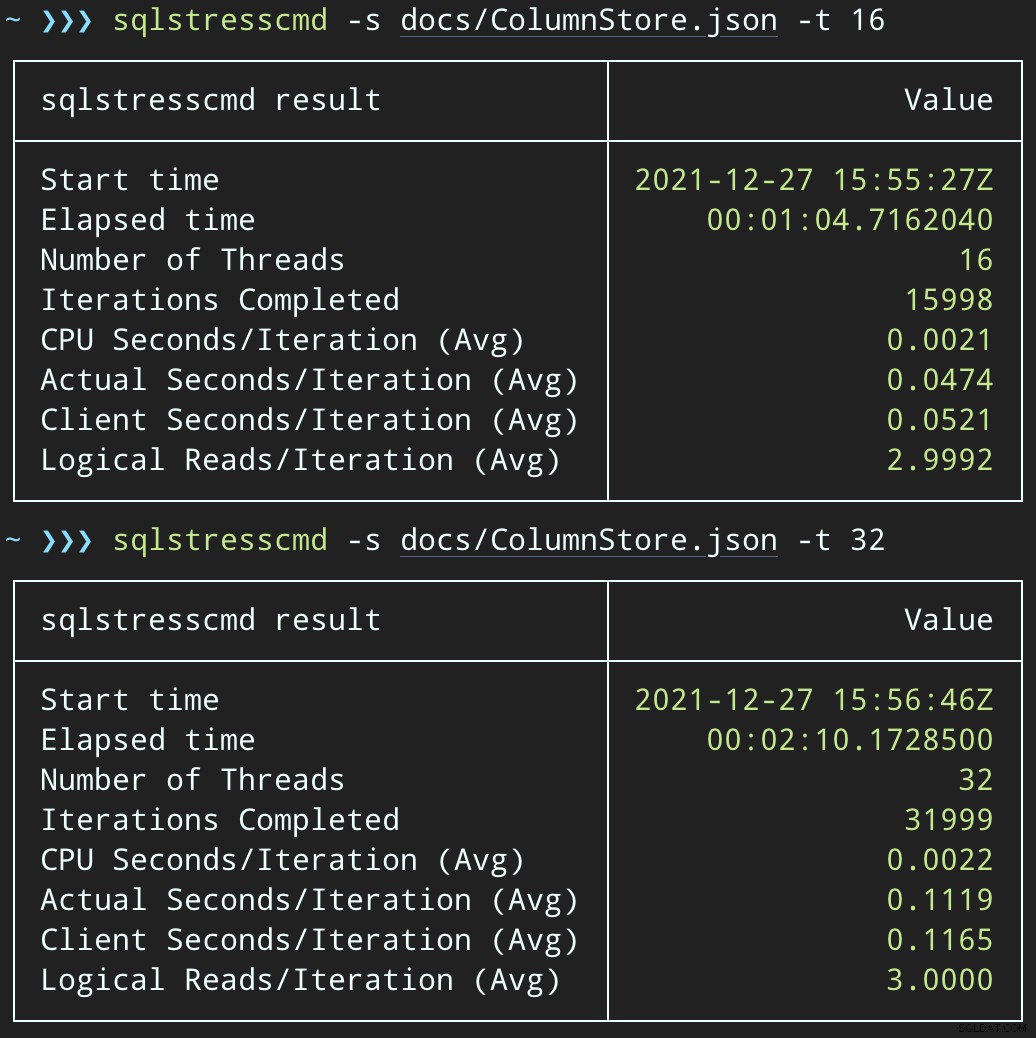
Hinweis:Die Ausgabe von SQLQueryStress weicht bei Iterationen manchmal etwas ab, aber ich habe bestätigt, dass die Arbeit, die Sie von ihr verlangen, präzise erledigt wird.
Eine mögliche Problemumgehung:Eine Löschwarteschlange
Anfangs dachte ich darüber nach, eine Warteschlangentabelle in die Datenbank einzuführen, die wir verwenden könnten, um Löschaktivitäten auszulagern:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Alles, was wir brauchen, ist ein INSTEAD OF-Trigger, um diese unerwünschten Löschungen aus der Anwendung abzufangen und sie zur Hintergrundverarbeitung in die Warteschlange zu stellen. Leider können Sie keinen Trigger für eine Tabelle mit einem gruppierten Columnstore-Index erstellen:
Msg 35358, Ebene 16, Status 1CREATE TRIGGER für Tabelle „dbo.FakeSuggestedEdits“ ist fehlgeschlagen, weil Sie keinen Trigger für eine Tabelle mit einem gruppierten Columnstore-Index erstellen können. Erwägen Sie, die Logik des Triggers auf andere Weise zu erzwingen, oder verwenden Sie stattdessen einen Heap- oder B-Tree-Index, wenn Sie einen Trigger verwenden müssen.
Wir brauchen eine minimale Änderung am Anwendungscode, damit er eine gespeicherte Prozedur aufruft, um den Löschvorgang zu verarbeiten:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Dies ist kein dauerhafter Zustand; Dies dient nur dazu, das Verhalten beizubehalten, während nur eine Sache in der App geändert wird. Sobald die App geändert wurde und diese gespeicherte Prozedur erfolgreich aufruft, anstatt Ad-hoc-Löschabfragen zu senden, kann sich die gespeicherte Prozedur ändern:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Testen der Auswirkung der Warteschlange
Wenn wir nun SqlQueryStress ändern, um stattdessen die gespeicherte Prozedur aufzurufen:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
Und senden Sie ähnliche Batches (wobei 16.000 oder 32.000 Zeilen in die Warteschlange gestellt werden):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
Die CPU-Belastung ist etwas höher:
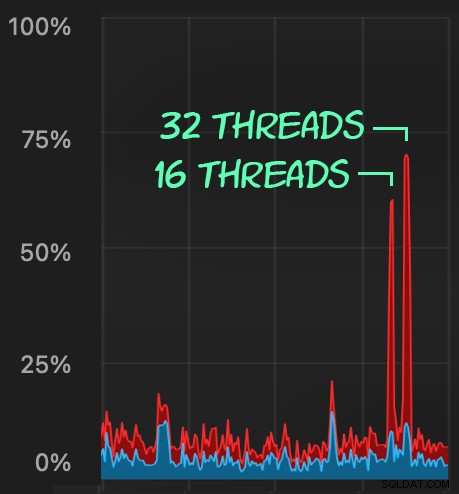
Aber die Workloads werden viel schneller beendet – 16 bzw. 23 Sekunden:
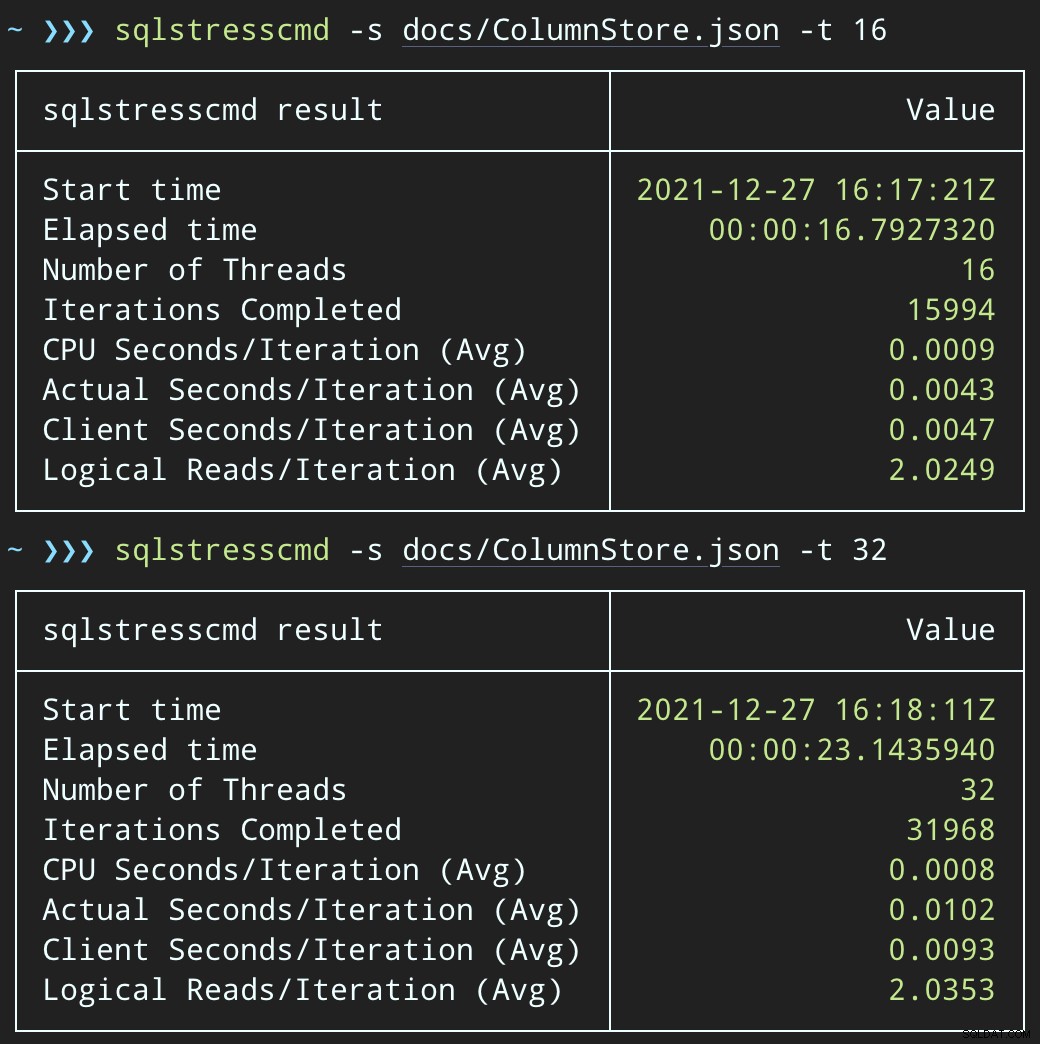
Dies ist eine deutliche Verringerung des Schmerzes, den die Anwendungen empfinden werden, wenn sie in Phasen mit hoher Parallelität geraten.
Wir müssen die Löschung trotzdem durchführen
Wir müssen diese Löschungen immer noch im Hintergrund verarbeiten, aber wir können jetzt Batching einführen und haben die volle Kontrolle über die Rate und alle Verzögerungen, die wir zwischen den Vorgängen einfügen möchten. Hier ist die grundlegende Struktur einer gespeicherten Prozedur zur Verarbeitung der Warteschlange (zugegebenermaßen ohne vollständig übertragene Transaktionskontrolle, Fehlerbehandlung oder Bereinigung der Warteschlangentabelle):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Jetzt dauert das Löschen von Zeilen länger – der Durchschnitt für 10.000 Zeilen beträgt 223 Sekunden, von denen etwa 100 absichtliche Verzögerungen sind. Aber kein Benutzer wartet, also wen interessiert das? Das CPU-Profil ist fast null, und die App kann der Warteschlange weiterhin Elemente so hochgradig gleichzeitig hinzufügen, wie sie möchte, ohne dass es zu Konflikten mit dem Hintergrundjob kommt. Während ich 10.000 Zeilen verarbeitete, fügte ich der Warteschlange weitere 16.000 Zeilen hinzu, und es verwendete dieselbe CPU wie zuvor – es dauerte nur eine Sekunde länger als wenn der Job nicht ausgeführt wurde:
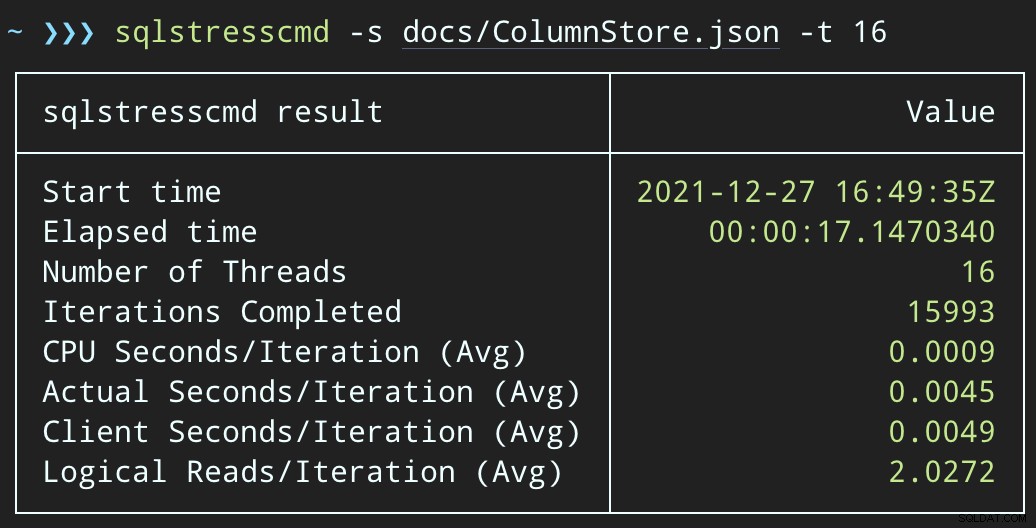
Und der Plan sieht jetzt so aus, mit viel besseren geschätzten/tatsächlichen Zeilen:
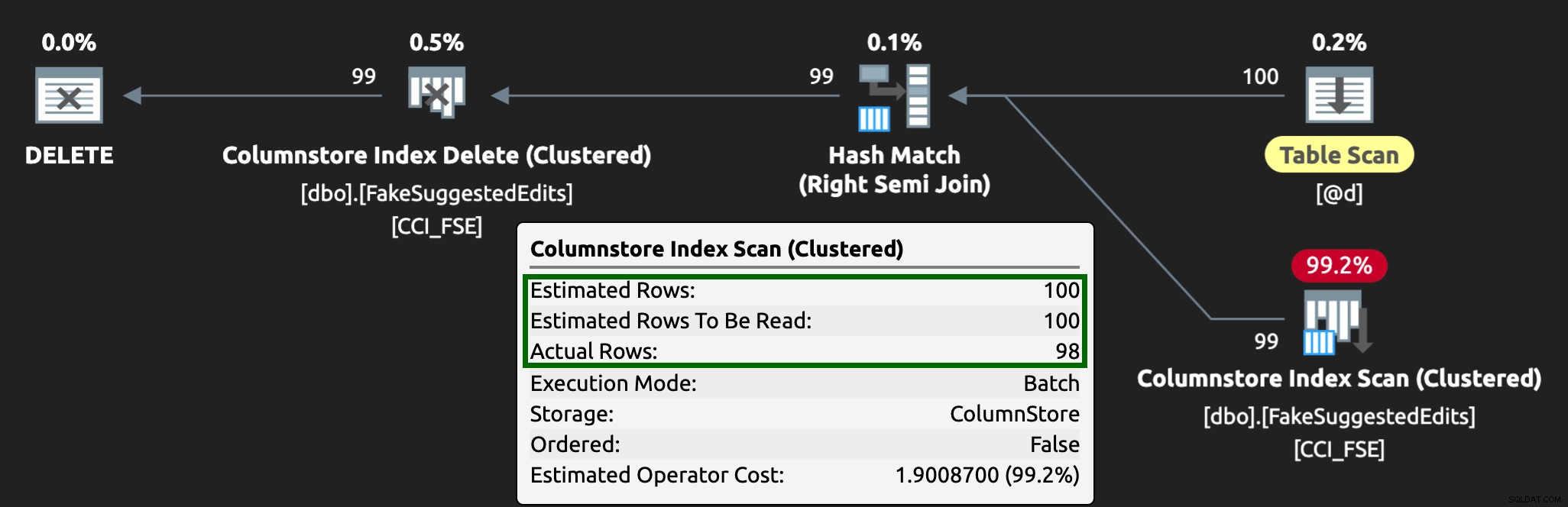
Ich kann mir vorstellen, dass dieser Warteschlangentabellen-Ansatz ein effektiver Weg ist, um mit hoher DML-Parallelität umzugehen, aber er erfordert zumindest ein wenig Flexibilität bei den Anwendungen, die DML übermitteln – das ist einer der Gründe, warum ich es wirklich mag, wenn Anwendungen gespeicherte Prozeduren aufrufen, da sie Geben Sie uns viel mehr Kontrolle näher an den Daten.
Andere Optionen
Wenn Sie die von der Anwendung kommenden Löschabfragen nicht ändern können – oder wenn Sie die Löschvorgänge nicht auf einen Hintergrundprozess verschieben können – können Sie andere Optionen in Betracht ziehen, um die Auswirkungen der Löschvorgänge zu verringern:
- Ein nicht gruppierter Index für die Prädikatspalten zur Unterstützung von Punktsuchen (wir können dies isoliert tun, ohne die Anwendung zu ändern)
- Nur vorläufige Löschungen verwenden (erfordert weiterhin Änderungen an der Anwendung)
Es wird interessant sein zu sehen, ob diese Optionen ähnliche Vorteile bieten, aber ich hebe sie mir für einen zukünftigen Beitrag auf.