Wie werden all diese Daten der öffentlichen Meinung gespeichert? Wir prüfen ein Meinungsumfrage-Datenmodell.
Jeder möchte wissen, was die Öffentlichkeit denkt, von Politikern und Unternehmen bis hin zu Einzelpersonen, die wissen möchten, was andere zu einem bestimmten Thema denken. Diese Art von Arbeit wird normalerweise von Agenturen ausgeführt, die auf diese Art von Forschung spezialisiert sind.
Heute werfen wir einen Blick auf ein Datenmodell, mit dem eine solche Agentur alle relevanten Umfragedaten speichern könnte, von Fragen und vordefinierten Antworten bis hin zum eigentlichen Feedback. Diese Daten würden später verwendet, um verschiedene Berichte zu erstellen. Fangen wir also an.
Idee
Umfragen können überall erstellt werden. Sie könnten gut geplant sein und eine repräsentative Stichprobe der Öffentlichkeit umfassen (basierend auf demografischen Daten). Oder Sie können sie direkt vor Ort durchführen, z. Wenn Sie Wahlergebnisse basierend auf einer Stichprobe vorhersagen möchten (wie bei einer Wahlbefragung), würden Sie wahrscheinlich die Leute im Wahllokal fragen, wie sie gewählt haben.
Wenn Sie dagegen dieselbe Umfrage vor der Wahl erstellen möchten, würden Sie wahrscheinlich eine Stichprobe auswählen und Personen telefonisch oder persönlich kontaktieren. Normalerweise gibt es für diese Art von Umfrage nur wenige Fragen – einige zu demografischen Merkmalen und andere zu dem, was uns wirklich interessiert.
Umfragen können auch viel komplexer sein, z.B. wenn Sie die öffentliche Meinung zu einem bestimmten Produkt erfahren möchten, von der Leistung bis zur Verpackung.
In diesem Artikel werde ich nicht darauf eingehen, wie man eine Stichprobe von Personen auswählt; Stattdessen konzentriere ich mich auf die Umfrage selbst, ihre Fragen und die Antworten.
Datenmodell
Datenmodell der Agentur für öffentliche Meinung
Das Modell besteht aus drei Themenbereichen:
PollsQuestions & AnswersResult
Wir beschreiben jeden Themenbereich in der angegebenen Reihenfolge.
Umfragen
Bevor wir anfangen, Fragen zu stellen, müssen wir definieren, woran wir interessiert sind. Wir definieren Umfragen und Fragebögen in diesem Abschnitt und fügen dann Fragen und Antworten im nächsten hinzu.
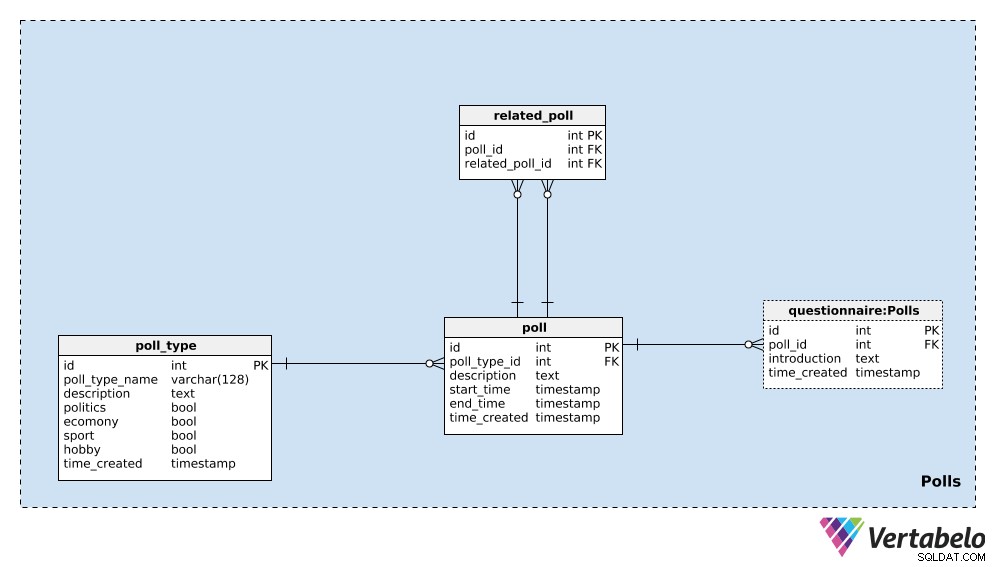
Wir beginnen mit dem poll_type Wörterbuch. Wir können damit rechnen, dass wir meist gleichartige Umfragen wiederholen werden. Der gebräuchlichste Typ sind wahrscheinlich Wahlumfragen, aber wir möchten in der Lage sein, neue Umfragetypen im Laufe der Zeit hinzuzufügen. Für jeden Umfragetyp speichern wir einen EINZIGARTIGEN poll_type_name und verwenden Sie die description -Attribut, um zusätzliche Details bereitzustellen.
Vier Flaggen – politics , economy , sport , und hobby – werden verwendet, um die Art der Umfrage zu bezeichnen. Eine Umfrage könnte eines oder mehrere dieser Themen abdecken; Bei Bedarf könnten wir diese Kategorien in ein separates Wörterbuch aufteilen und eine Viele-zu-Viele-Beziehung zwischen diesem Wörterbuch und dem poll_type Tabelle.
Das letzte Attribut in dieser Tabelle ist time_created . Es bezeichnet den Moment, in dem eine Zeile in diese Tabelle eingefügt wird.
Als nächstes müssen wir eine einzelne poll . Dies ist eine einzelne Instanz, z. „Präsidentschaftswahlen in den Vereinigten Staaten 2020 – Umfrage vom April 2020“ . Für jede Umfrage speichern wir die folgenden Details:
poll_type_id– Ein Verweis auf denpoll_type.description– Alle Details zu dieser Umfrage im Textformat.start_timeundend_time– Die definierten Start- und Endzeiten, zu denen diese Umfrage durchgeführt wird.time_created– Der tatsächliche Moment, in dem diese Umfrage erstellt wurde.
Umfragen können miteinander in Beziehung gesetzt werden. Im Beispiel der „2020 United States Presidential Election – April 2020 Polling“ , könnten wir im nächsten Monat dieselbe Umfrage durchführen, um die aktuellsten Meinungen zu sehen. Wir würden dies „Präsidentschaftswahlen in den Vereinigten Staaten 2020 – Umfrage im Mai 2020“ nennen . Diese beiden Umfragen sind verwandt, weil ihre Ergebnisse Trends zeigen. Um diese Beziehung herzustellen, verwenden wir den related_poll Tabelle in unserem Modell. Es enthält nur das EINZIGARTIGE Paar poll_id – related_poll_id , bezeichnet die Umfrage und ihren Vorgänger.
Beachten Sie, dass wir diese Tabelle verwenden könnten, um alle Umfragen zu speichern, die in irgendeiner Weise verwandt sind, nicht nur Vorgänger/Nachfolger. Wenn wir andere Beziehungen definieren wollten, müssten wir ein weiteres Wörterbuch hinzufügen – aber darauf gehen wir in diesem Artikel nicht ein.
Die letzte Tabelle in diesem Themenbereich ist der questionnaire Tisch. In den meisten Fällen enthält jede Umfrage genau einen Fragebogen, aber ich möchte die Option offen lassen, dass wir bei Bedarf mehr als einen haben könnten. Daher habe ich eine separate Tabelle verwendet. In dieser Tabelle speichern wir nur die ID der zugehörigen Umfrage (poll_id ), eine introduction die diesen Fragebogen beschreibt, und den Zeitstempel, wann der Datensatz eingefügt wurde (time_created ).
Fragen &Antworten
Jetzt können wir alle Fragebogendetails erstellen. Wir können auch alle Fragen auflisten, die wir stellen möchten, sowie alle vordefinierten Antworten.
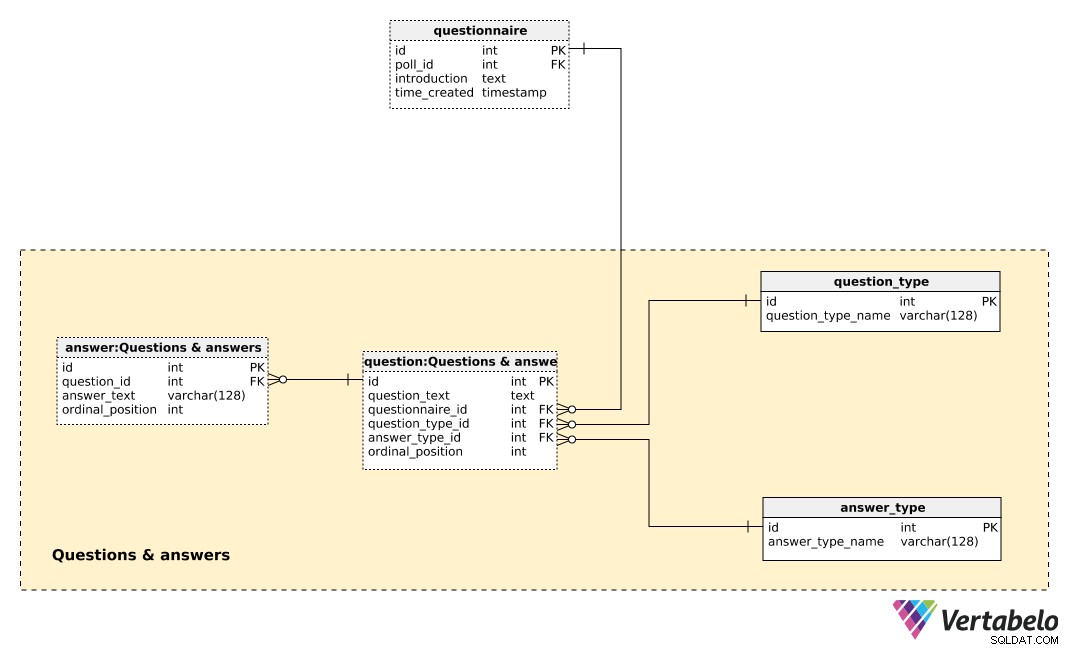
Die zentrale Tabelle in diesem Themenbereich ist die question Tisch. Jede Frage wird durch die folgenden Details definiert:
question_text– Ein Text, der jeder abgefragten Person angezeigt wird.questionnaire_id– Eine Referenz, die den Fragebogen dieser Frage bezeichnet.question_type_id– Eine Referenz, die denquestion_type, der EINMALIG durch denquestion_type_namegekennzeichnet ist . Dies sind im Grunde Kategorien, z. „Demografie“, „Meinung“, „Kontrolle“ usw. Diese würden es uns ermöglichen, demografische und Meinungsfragen zu trennen und eine Korrelation zwischen ihnen zu finden.answer_type_id– Ein Hinweis auf die Art der Antwort, die für diese Frage verwendet wird. Jederanswer_typewird EINMALIG durch denanswer_type_namedefiniert und gibt an, wie die Antwort angezeigt wird. Einige erwartete Typen sind „open“, „list“, „checkbox“ und „multiple“.ordinal_position– Dieser Wert bezeichnet die Position dieser Frage im Fragebogen. Zusammen mit derquestionnaire_id, es bildet den alternativen Schlüssel dieser Tabelle.
Eine Liste aller vordefinierten Antworten ist im answer Tisch. Wenn der Fragetyp nicht offen ist (d. h. kein Text von der Person eingegeben wird), haben wir eine Reihe vordefinierter Antworten. Für jede Antwort definieren wir die Frage, zu der sie gehört (question_id ), den answer_text , und die ordinal_position dieser Antwort in dieser Frage. Wieder ein EINZIGARTIGES Paar – diesmal question_id – ordinal_position – bildet den alternativen Schlüssel dieser Tabelle.
Ergebnis
In den beiden vorherigen Themenbereichen haben wir alles definiert, was wir brauchen, um die Umfrage zu erstellen und Fragen zu stellen. Jetzt müssen wir eine Datenstruktur definieren, um die tatsächlichen Antworten zu speichern.
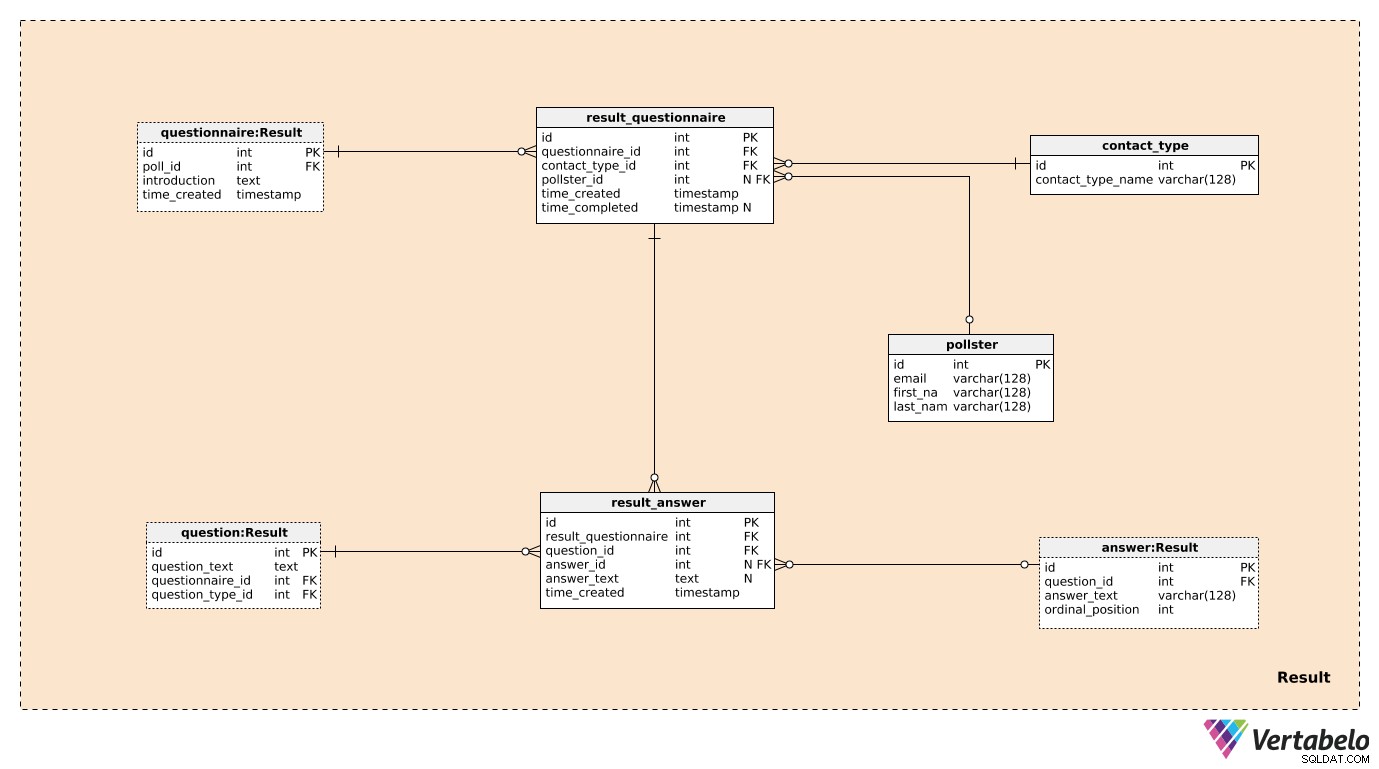
Drei der sieben Tabellen im Result Themenbereich wurden zuvor erwähnt und beschrieben. Dies sind questionnaire , question , und answer . Die verbleibenden vier Tabellen werden verwendet, um zu speichern, woran wir wirklich interessiert sind.
Wir erstellen einen Datensatz im result_questionnaire Tabelle für jeden einzelnen Teilnehmer an der Umfrage. Die questionnaire_id Stellen Sie esus alle Informationen über die entsprechende Umfrage zur Verfügung. Die contact_type_id ist ein Verweis auf contact_type Wörterbuch. Die Werte in dieser Tabelle beschreiben die Art und Weise, wie wir mit dieser Person interagiert haben. Diese Werte werden EINZIGARTIG durch contact_type_name definiert Wert und könnte so etwas wie „Telefon“, „persönlich“, „E-Mail“, „Webformular“ usw. sein.
Die pollster_id -Attribut ist ein Verweis auf den pollster Tabelle, die Informationen darüber enthält, wer diese tatsächliche Umfrage durchgeführt hat. Für jeden pollster , speichern wir nur ihre EINZIGARTIGE E-Mail-Adresse und ihren first_name und last_name . Die time_created Das Attribut gibt die tatsächliche Zeit an, zu der dieser Datensatz erstellt wurde, während das time_completed wird in dem Moment festgelegt, in dem diese Umfrage abgeschlossen ist. (Bis dahin ist es NULL).
Die letzte Tabelle im Modell ist result_answer Tisch. Wie der Name schon sagt, speichern wir hier die tatsächlichen Antworten, die wir von Umfrageteilnehmern erhalten haben. Für jeden Datensatz in dieser Tabelle haben wir:
result_questionnaire_id– Verweis auf den entsprechenden Fragebogen.question_id– Eine Referenz, die die durch diese Antwort beantwortete Frage bezeichnet.answer_id– Ein Verweis auf die Antwort, die zur Beantwortung dieser Frage verwendet wurde. Dieses Attribut enthält einen NULL-Wert, wenn die Frage vom Typ „offen“ ist (weil es keine vordefinierten Antworten zur Auswahl gab).answer_text– Der Text, der zur Beantwortung dieser Frage eingefügt wurde. Dieses Attribut enthält einen Wert, wenn die Frage „offen“ war; in allen anderen Fällen ist es NULL.time_created– Der tatsächliche Zeitpunkt, zu dem diese Antwort in unser System eingefügt wurde.
Mögliche Verbesserungen
Bisher haben wir behandelt, wie wir Umfragedaten speichern können. Wir haben nicht darüber gesprochen, was wir mit den Daten tun würden, nachdem die Umfrage geschlossen wurde. Wir können davon ausgehen, dass wir die alten Daten in Zukunft nicht mehr benötigen, zumindest nicht in unserer operativen Datenbank. Daher könnten wir zwei Dinge tun:
- Speichern Sie eine Umfragezusammenfassung in einer separaten Tabelle in der Betriebsdatenbank. Dadurch würden uns solche Informationen zur Verfügung stehen, wenn wir sehen wollten, was bei einer ähnlichen Umfrage passiert ist.
- Speichern Sie alle Umfragedaten in einer Sicherungsdatenbank, die dieselbe Struktur wie die Betriebsdatenbank hatte. Dies würde es uns ermöglichen, auf die Details zuzugreifen, wenn wir sie brauchen.
Wir könnten auch ein Data Warehouse zum Speichern von Umfrageergebnissen erstellen, aber das wäre nicht notwendig, wenn wir die in den beiden Aufzählungspunkten beschriebenen Aufgaben bereits erledigt hätten.
Was halten Sie von unserem Datenmodell für Meinungsumfragen?
Wir würden gerne Ihre Meinung dazu hören, was wir ändern könnten, um das Datenmodell der Meinungsumfrage zu verbessern. Sie haben Branchenerfahrung? Glaubst du, wir haben etwas verpasst? Würdest du etwas hinzufügen oder entfernen? Ich freue mich darauf, Ihre Meinung zu hören.