Kameras, Drehtüren, Aufzüge, Temperatursensoren, Alarme – all diese Geräte erzeugen eine große Anzahl miteinander verbundener Signale, die sich auf Ereignisse um uns herum beziehen. Stellen Sie sich nun vor, Sie wären die Person, die Status verfolgen, Echtzeitberichte erstellen und auf der Grundlage all dieser Signaldaten Vorhersagen treffen muss. Dazu müssen Sie diese Daten zunächst speichern. Ein Datenmodell, das eine solche Signalverarbeitung unterstützt, ist das Thema des heutigen Artikels.
Der einfachste Weg, eingehende Signale zu speichern, wäre, einfach eine Textdarstellung davon in einer riesigen Liste zu speichern. Dieser Ansatz würde es uns ermöglichen, Einfügungen schnell durchzuführen, aber Aktualisierungen wären problematisch. Außerdem wäre ein solches Modell nicht normalisiert, und deshalb werden wir nicht in diese Richtung gehen.
Wir erstellen ein normalisiertes Datenmodell, das zum Speichern der von verschiedenen Geräten generierten Daten verwendet werden könnte, und definieren auch, wie die Geräte miteinander in Beziehung stehen. Ein solches Modell würde alles, was wir brauchen, effizient speichern und könnte auch für Analysen und Predictive Analytics verwendet werden.
Datenmodell
Das Datenmodell der Signalverarbeitung
Das Modell besteht aus drei Themenbereichen:
ComplexesInstallations & DevicesSignals & Events
Wir beschreiben jeden dieser Themenbereiche in der angegebenen Reihenfolge.
Komplexe
Bei der Erstellung dieses Datenmodells ging ich davon aus, dass wir es verwenden werden, um zu verfolgen, was in größeren Komplexen passiert. Komplexe variieren in der Größe von einem Einzelzimmer bis zu einem Einkaufszentrum. Es ist wichtig, dass jeder Komplex mindestens ein Gerät/einen Sensor hat, aber es werden wahrscheinlich noch viel mehr sein.
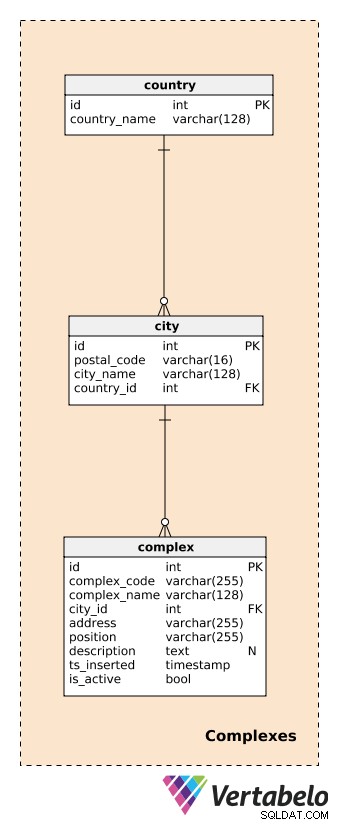
Bevor wir Komplexe beschreiben, müssen wir die Tabellen definieren, die Länder und Städte handhaben. Diese bieten eine ziemlich detaillierte Beschreibung der Lage jedes Komplexes.
Für jedes country , speichern wir seinen EINZIGARTIGEN country_name; für jede city speichern wir die EINZIGARTIGE Kombination von postal_code , city_name und country_id . Ich gehe hier nicht ins Detail und gehe davon aus, dass jede Stadt nur eine Postleitzahl hat. In Wirklichkeit haben die meisten Städte mehr als eine Postleitzahl; in diesem Fall können wir den Hauptcode für jede Stadt verwenden.
Ein complex ist das tatsächliche Gebäude oder der Ort, an dem datenerzeugende Geräte installiert sind. Wie bereits erwähnt, können Komplexe von einem einzelnen Raum oder einer Messstation bis hin zu viel größeren Orten wie Parkplätzen, Einkaufszentren, Kinos usw. variieren. Sie sind Gegenstand unserer Analyse. Wir wollen in Echtzeit verfolgen können, was auf der komplexen Ebene passiert, und später Berichte und Analysen erstellen. Für jeden Komplex definieren wir ein:
complex_code– Eine EINDEUTIGE Kennung für jeden Komplex. Wir haben zwar ein separates Primärschlüsselattribut (id) für diese Tabelle können wir davon ausgehen, dass wir für jeden Komplex einen anderen Identifikationscode von einem anderen System erben werden.complex_name– Ein Name, der verwendet wird, um diesen Komplex zu beschreiben. Im Falle von Einkaufszentren und Kinos könnte dies der tatsächliche und bekannte Name sein; für eine Messstation könnten wir einen Gattungsnamen verwenden.city_id– Ein Hinweis auf die Stadt, in der sich der Komplex befindet.address– Die physische Adresse dieses Komplexes.position– Die Position des Komplexes (d. h. geografische Koordinaten) im Textformat definiert.description– Eine Textbeschreibung, die diesen Komplex näher beschreibt.ts_inserted– Ein Zeitstempel, wann dieser Datensatz eingefügt wurde.is_active– Ein boolescher Wert, der angibt, ob dieser Komplex noch aktiv ist oder nicht.
Installationen und Geräte
Jetzt nähern wir uns dem Kern unseres Modells. Wir werden wahrscheinlich eine Reihe von Geräten in jedem Komplex installiert haben. Wir werden diese Geräte mit ziemlicher Sicherheit auch nach ihrem Zweck gruppieren – z. Wir könnten Kameras, Türsensoren und einen Motor zum Öffnen und Schließen einer Tür in einer Gruppe zusammenstellen, weil sie zusammenarbeiten.
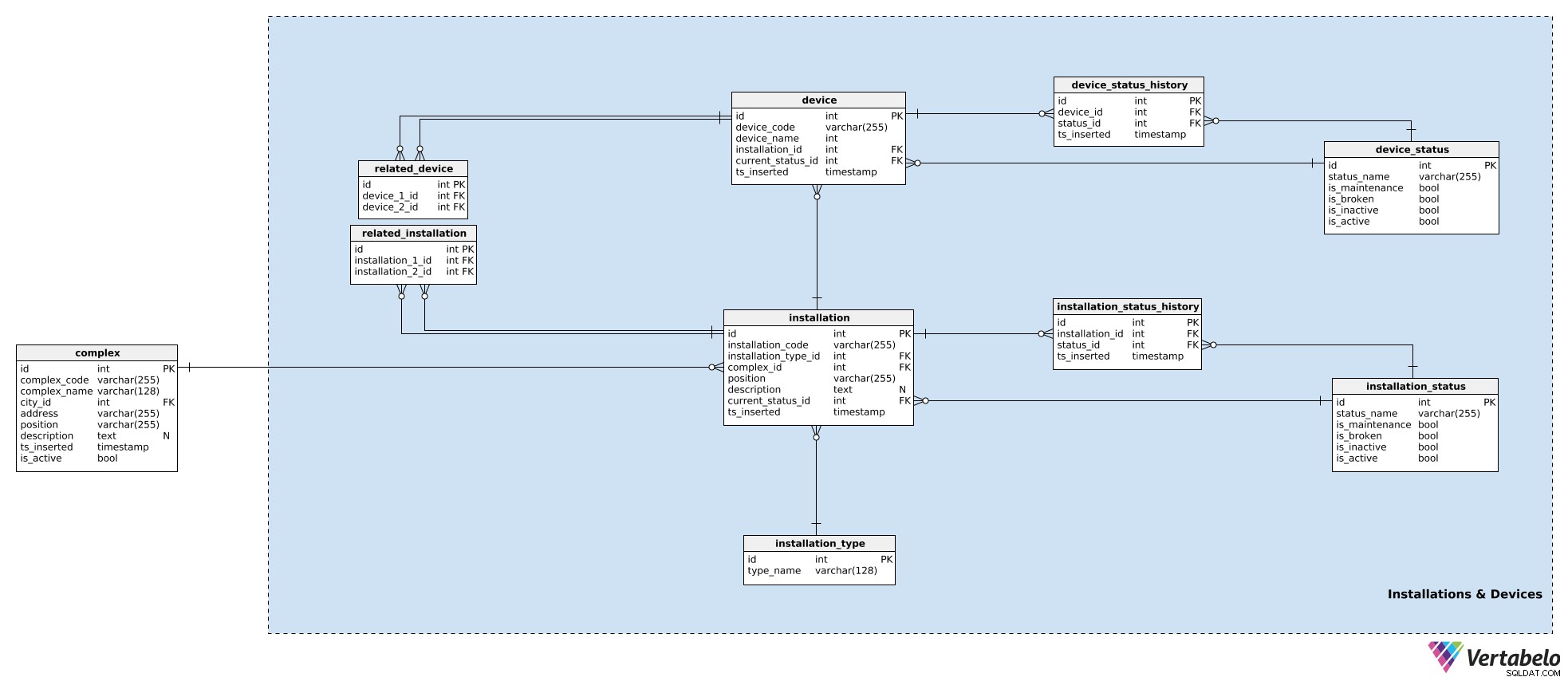
In unserem Modell werden Geräte, die in einem Komplex zusammenarbeiten, zu Installationen zusammengefasst. Dies können Haustüren, Rolltreppen, Temperatursensoren usw. sein. Für jede Installation speichern wir die folgenden Details im installation Tabelle:
installation_code– Ein EINZIGARTIGER Code, der verwendet wird, um diese Installation zu kennzeichnen.installation type_id– Ein Verweis auf deninstallation_typeWörterbuch. Dieses Wörterbuch speichert nur einen EINZIGARTIGENtype_nameAttribut, das den Typ beschreibt, z. Rolltreppe, Aufzug.complex_id– Ein Verweis auf dencomplexzu der die Installation gehört.position– Die Koordinaten dieser Installation innerhalb des Komplexes im Textformat.description– Eine Textbeschreibung dieser Installation.current_status_id– Ein Verweis auf den aktuellen Status (aus deminstallation_statusTabelle) dieser Installation.ts_inserted– Ein Zeitstempel, wann dieser Datensatz in unser System eingefügt wurde.
Wir haben bereits Installationsstatus erwähnt. Eine Liste aller möglichen Status ist im installation_status Wörterbuch. Jeder Status wird EINZIGARTIG durch seinen status_name definiert . Außerdem speichern wir Flags, die angeben, ob dieser Status bei Verwendung impliziert, dass die Installation is_broken ist , is_inactive , is_maintenance , oder is_active . Es sollte immer nur eines dieser Flags gesetzt werden.
Wir haben der Installation bereits einen aktuellen Stand zugeordnet. Wenn wir verfolgen wollen, was mit dem Gerät passiert, müssen wir auch seinen Verlauf speichern. Dazu verwenden wir eine weitere Tabelle, installation_status_history . Für jeden Datensatz hier speichern wir Verweise auf die zugehörige Installation und den aktuellen Status (ts_inserted ), als dieser Status zugewiesen wurde.
Installationen sind Teil unserer Komplexe. Obwohl jede Installation eine einzelne Einheit ist, kann sie dennoch mit anderen Installationen in Beziehung stehen. (Z. B. ist ein Videosystem am Vordereingang eines Einkaufszentrums offensichtlich mit den Eingangstüren des Einkaufszentrums verbunden – die Personen werden zuerst von der Kamera gesehen und dann öffnen sich die Türen.) Wenn wir diese Beziehungen im Auge behalten möchten, speichern wir sie in der related_installation Tisch. Bitte beachten Sie, dass diese Tabelle nur EINZIGARTIGE Paare von zwei Schlüsseln enthält, die beide auf die installation Tisch.
Dieselbe Logik wird zum Speichern von Geräten verwendet. Geräte sind einzelne Hardwareteile, die die Signale erzeugen, an denen wir interessiert sind. Während Installationen zu Komplexen gehören, gehören Geräte zu Installationen. Für jedes device , speichern wir:
device_code– EINZIGARTIGE Art, jedes Gerät zu kennzeichnen.device_name– Ein Name für dieses Gerät.installation_id– Ein Verweis auf die Installation, zu der dieses Gerät gehört.current_status_id– Der aktuelle Status des Geräts.ts_inserted– Ein Zeitstempel, wann dieser Datensatz eingefügt wurde.
Status werden auf die gleiche Weise behandelt. Wir verwenden den device_status Tabelle zum Speichern einer Liste aller möglichen Gerätezustände. Diese Tabelle hat dieselbe Struktur wie installation_status und die Attribute werden auf die gleiche Weise verwendet. Der Grund für die beiden getrennten Statuswörterbücher ist, dass Geräte und ihre Installationen unterschiedliche Status haben können – zumindest dem Namen nach.
Der aktuelle Status wird in der device.current_status_id gespeichert -Attribut und der Statusverlauf wird in device_status_history Tisch. Für jeden Eintrag speichern wir hier die Zuordnung zum Gerät und Status sowie den Zeitpunkt, an dem dieser Eintrag eingefügt wurde.
Die letzte Tabelle in diesem Themenbereich ist related_device Tisch. Obwohl es ziemlich offensichtlich ist, dass alle Geräte innerhalb derselben Installation eng miteinander verwandt sind, möchte ich die Möglichkeit haben, zwei beliebige Geräte zu verknüpfen, die zu einer beliebigen Installation gehören. Dazu speichern wir ihre beiden Geräte-IDs in dieser Tabelle.
Signale und Ereignisse
Jetzt sind wir bereit für das Herzstück des gesamten Modells.
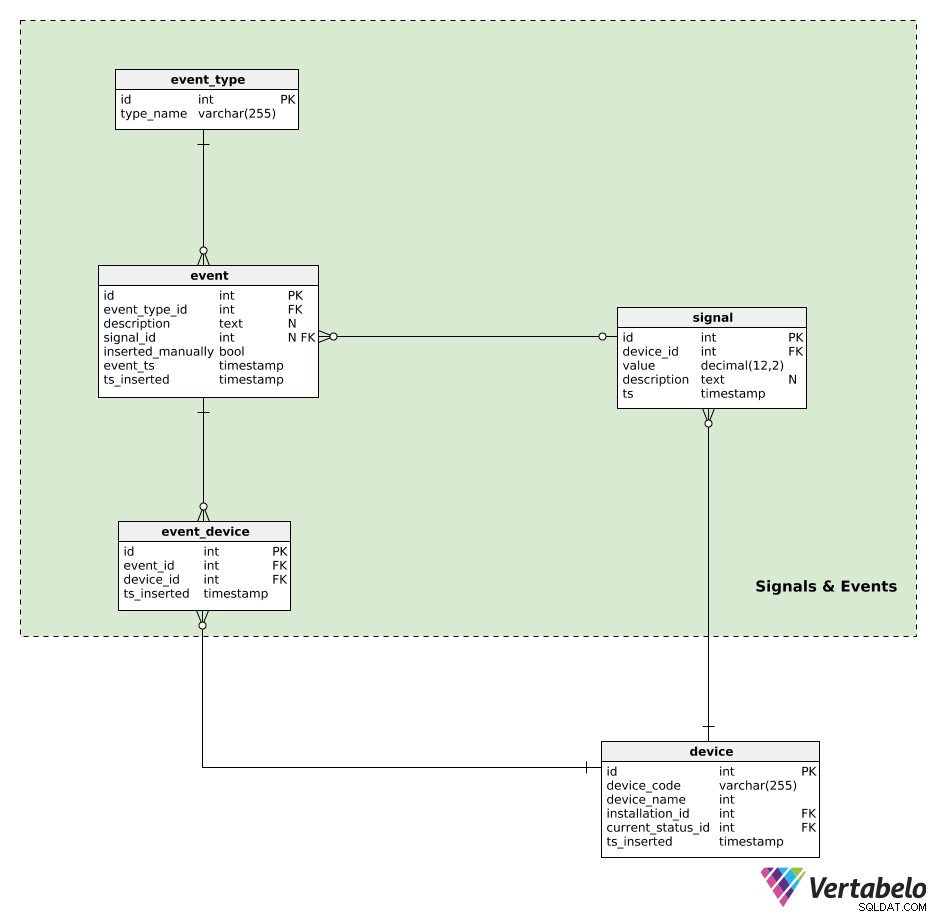
Geräte erzeugen Signale. Alle Signaldaten werden im signal Tisch. Für jedes Signal speichern wir Folgendes:
device_id– Ein Verweis auf das Gerät, das dieses Signal erzeugt hat.value– Der numerische Wert dieses Signals.description– Ein Textwert, der zusätzliche Parameter (z. B. Signaltyp, Werte, verwendete Maßeinheit) in Bezug auf dieses einzelne Signal enthalten kann. Diese Daten werden in einem JSON-ähnlichen Format gespeichert.ts– Ein Zeitstempel, wann dieses Signal in die Tabelle eingefügt wurde.
Wir können davon ausgehen, dass diese Tabelle mit einer großen Anzahl von Einfügungen pro Sekunde extrem stark beansprucht wird. Daher sollte sich die Datenbankwartung darauf konzentrieren, die Größe dieser Tabelle zu verfolgen.
Das Letzte, was ich tun möchte, ist, Ereignisse zu unserem Datenmodell hinzuzufügen. Ereignisse können automatisch durch ein Signal generiert oder manuell eingefügt werden. Ein automatisch generiertes Ereignis könnte „Tür für 5 Minuten offen“ sein, ein manuell eingefügtes Ereignis könnte sein „Wegen dieses Signals musste das Gerät ausgeschaltet werden“. Die ganze Idee besteht darin, Aktionen zu speichern, die als Ergebnis des Geräteverhaltens aufgetreten sind. Später könnten wir diese Ereignisse verwenden, während wir eine Analyse des Geräteverhaltens durchführen.
Ereignisse werden nach event_type . Jeder Typ wird EINZIGARTIG durch seinen type_name definiert .
Alle automatisch generierten oder manuell eingefügten Ereignisse werden im event Tisch. Für jeden Datensatz hier speichern wir:
event_type_id– Ein Verweis auf den zugehörigen Ereignistyp.description– Eine Textbeschreibung dieses Ereignisses.signal_id– Ein Verweis auf das Signal, falls vorhanden, das das Ereignis verursacht hat.inserted_manually– Ein Flag, das angibt, ob dieser Datensatz manuell eingefügt wurde oder nicht.event_tsundts_inserted–Zeitstempel, wann dieses Ereignis tatsächlich stattgefunden hat und wann ein Datensatz davon eingefügt wurde. Diese beiden können sich unterscheiden, insbesondere wenn Ereignisdatensätze manuell eingefügt werden.
Die letzte Tabelle in unserem Modell ist event_device Tisch. Diese Tabelle wird verwendet, um Ereignisse mit allen beteiligten Geräten in Beziehung zu setzen. Für jeden Datensatz speichern wir das EINZIGARTIGE Paar event_id – device_id und den Zeitstempel, wann der Datensatz eingefügt wurde.
Was halten Sie von unserem Signalverarbeitungs-Datenmodell?
Heute haben wir ein vereinfachtes Datenmodell analysiert, das wir verwenden könnten, um Signale von einer Reihe von Geräten zu verfolgen, die an verschiedenen Orten installiert sind. Das Modell selbst sollte ausreichen, um alles zu speichern, was wir zum Verfolgen von Status und Durchführen von Analysen benötigen. Dennoch sind viele Verbesserungen möglich. Was könnten wir hinzufügen? Bitte teilen Sie uns dies in den Kommentaren unten mit.