Ich bin seit langem ein Befürworter der Wahl des richtigen Datentyps. Ich habe in einem früheren Blogbeitrag zu „Bad Habits“ über einige Beispiele gesprochen, aber dieses Wochenende beim SQL Saturday #162 (Cambridge, UK), das Thema der Verwendung von DATETIME standardmäßig kam. In einem Gespräch nach meiner Präsentation T-SQL :Bad Habits and Best Practices gab ein Benutzer an, dass er nur DATETIME verwendet Selbst wenn sie nur eine minuten- oder tagesgenaue Granularität benötigen, haben die Datums-/Uhrzeitspalten im gesamten Unternehmen auf diese Weise immer den gleichen Datentyp. Ich habe angedeutet, dass dies verschwenderisch sein könnte und dass sich die Konsistenz möglicherweise nicht lohnt, aber heute habe ich beschlossen, meine Theorie zu beweisen.
TL;DR-Version
Meine Tests unten zeigen, dass es sicherlich Szenarien gibt, in denen Sie die Verwendung eines dünneren Datentyps in Erwägung ziehen sollten, anstatt bei DATETIME zu bleiben überall, überallhin, allerorts. Aber es ist wichtig zu sehen, wo meine Tests dafür in die andere Richtung wiesen, und es ist auch wichtig, diese Szenarien gegen Ihr Schema, in Ihrer Umgebung, mit Hardware und Daten zu testen, die so produktionsgetreu wie möglich sind. Ihre Ergebnisse können und werden mit ziemlicher Sicherheit variieren.
Die Zieltabellen
Betrachten wir den Fall, in dem die Granularität nur für den Tag wichtig ist (wir kümmern uns nicht um Stunden, Minuten, Sekunden). Dafür könnten wir DATETIME wählen (wie vom Benutzer vorgeschlagen) oder SMALLDATETIME , oder DATE auf SQL Server 2008+. Es gibt auch zwei verschiedene Arten von Daten, die ich berücksichtigen wollte:
- Daten, die ungefähr nacheinander in Echtzeit eingefügt würden (z. B. Ereignisse, die gerade stattfinden);
- Daten, die zufällig eingefügt würden (z. B. Geburtsdaten neuer Mitglieder).
Ich habe mit 2 Tabellen wie der folgenden begonnen und dann 4 weitere erstellt (2 für SMALLDATETIME, 2 für DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE TABLE dbo.EventsSequential_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt); CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Then repeat for DATE and SMALLDATETIME.
Und mein Ziel war es, die Batch-Insert-Performance auf diese beiden unterschiedlichen Arten zu testen, sowie die Auswirkungen auf die Gesamtspeichergröße und -fragmentierung und schließlich die Performance von Bereichsabfragen.
Beispieldaten
Um einige Beispieldaten zu generieren, habe ich eine meiner praktischen Techniken verwendet, um aus etwas, das keine Bedeutung hat, etwas Sinnvolles zu generieren:die Katalogansichten. Auf meinem System wurden in etwa 12 Sekunden 971 verschiedene Datums-/Uhrzeitwerte (insgesamt 1.000.000 Zeilen) zurückgegeben:
;WITH y AS
(
SELECT TOP (1000000) d = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x(x) ORDER BY NEWID()
)
SELECT DISTINCT d FROM y; Ich habe diese Millionen Zeilen in eine Tabelle eingefügt, damit ich sequentielle/zufällige Einfügungen mit verschiedenen Zugriffsmethoden für genau dieselben Daten aus drei verschiedenen Sitzungsfenstern simulieren konnte:
CREATE TABLE dbo.Staging
(
ID INT IDENTITY(1,1) PRIMARY KEY,
source_date DATETIME NOT NULL
);
;WITH Staging_Data AS
(
SELECT TOP (1000000) dt = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS sd(x) ORDER BY NEWID()
)
INSERT dbo.Staging(source_date)
SELECT dt
FROM y
ORDER BY dt; Dieser Vorgang dauerte etwas länger (20 Sekunden). Dann habe ich eine zweite Tabelle erstellt, um dieselben Daten zu speichern, aber zufällig verteilt (damit ich dieselbe Verteilung über alle Einfügungen hinweg wiederholen kann).
CREATE TABLE dbo.Staging_Random ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL ); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Abfragen zum Füllen der Tabellen
Als Nächstes schrieb ich eine Reihe von Abfragen, um die anderen Tabellen mit diesen Daten zu füllen, wobei ich drei Abfragefenster verwendete, um zumindest ein wenig Parallelität zu simulieren:
WAITFOR TIME '13:53';
GO
DECLARE @d DATETIME2 = SYSDATETIME();
INSERT dbo.{table_name}(dt) -- depending on method / data type
SELECT source_date
FROM dbo.Staging[_Random] -- depending on destination
WHERE ID % 3 = <0,1,2> -- depending on query window
ORDER BY ID;
SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Wie in meinem letzten Beitrag habe ich die Datenbank vorerweitert, um zu verhindern, dass jegliche Art von Datendatei-Autowachstumsereignissen die Ergebnisse beeinträchtigen. Mir ist klar, dass es nicht ganz realistisch ist, Millionen-Zeilen-Einfügungen in einem Durchgang durchzuführen, da ich nicht verhindern kann, dass die Protokollaktivität für eine so große Transaktion stört, aber dies sollte bei jeder Methode konsistent erfolgen. Da sich die Hardware, mit der ich teste, völlig von der Hardware unterscheidet, die Sie verwenden, sollten die absoluten Ergebnisse keine wichtige Erkenntnis sein, sondern nur der relative Vergleich.
(In einem zukünftigen Test werde ich dies auch mit echten Stapeln versuchen, die aus Protokolldateien mit relativ gemischten Daten kommen, und Teile der Quelltabelle in Schleifen verwenden – ich denke, das wären auch interessante Experimente. Und natürlich Hinzufügen Kompression in den Mix.)
Die Ergebnisse:
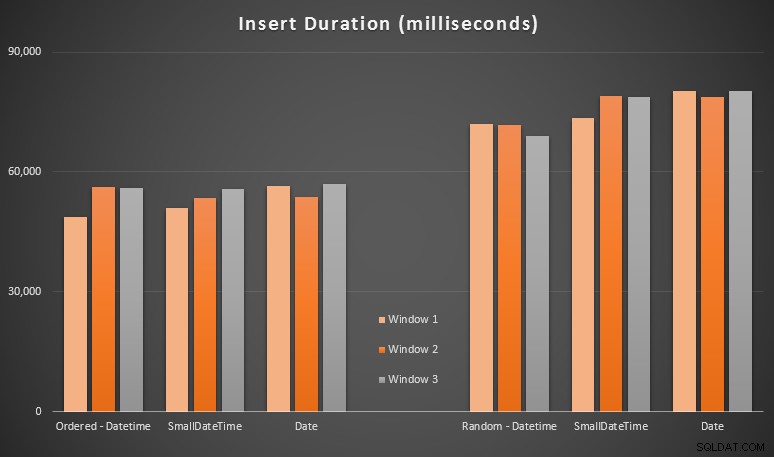
Diese Ergebnisse waren für mich nicht allzu überraschend – das Einfügen in zufälliger Reihenfolge führte zu längeren Laufzeiten als das sequenzielle Einfügen, etwas, das wir alle zu unseren Wurzeln des Verständnisses der Funktionsweise von Indizes in SQL Server zurückkehren können und wie mehr „schlechte“ Seitenteilungen auftreten können dieses Szenario (ich habe in dieser Übung nicht speziell auf Seitenteilungen geachtet, aber ich werde es in zukünftigen Tests berücksichtigen).
Mir ist aufgefallen, dass die impliziten Konvertierungen der eingehenden Daten auf der zufälligen Seite möglicherweise Auswirkungen auf die Zeitangaben hatten, da sie ein wenig höher schienen als die native DATETIME -> DATETIME Einsätze. Also beschloss ich, zwei neue Tabellen mit Quelldaten zu erstellen:eine mit DATE und eine mit SMALLDATETIME . Dies würde bis zu einem gewissen Grad die ordnungsgemäße Konvertierung Ihres Datentyps simulieren, bevor Sie ihn an die Insert-Anweisung übergeben, sodass während des Einfügens keine implizite Konvertierung erforderlich ist. Hier sind die neuen Tabellen und wie sie gefüllt wurden:
CREATE TABLE dbo.Staging_Random_SmallDatetime ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL ); CREATE TABLE dbo.Staging_Random_Date ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL ); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Dies hatte nicht den erhofften Effekt – die Timings waren in allen Fällen ähnlich. Das war also eine wilde Verfolgungsjagd.
Verwendeter Speicherplatz und Fragmentierung
Ich habe die folgende Abfrage ausgeführt, um festzustellen, wie viele Seiten für jede Tabelle reserviert wurden:
SELECT name = 'dbo.' + OBJECT_NAME([object_id]), pages = SUM(reserved_page_count) FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id]) ORDER BY pages;
Die Ergebnisse:
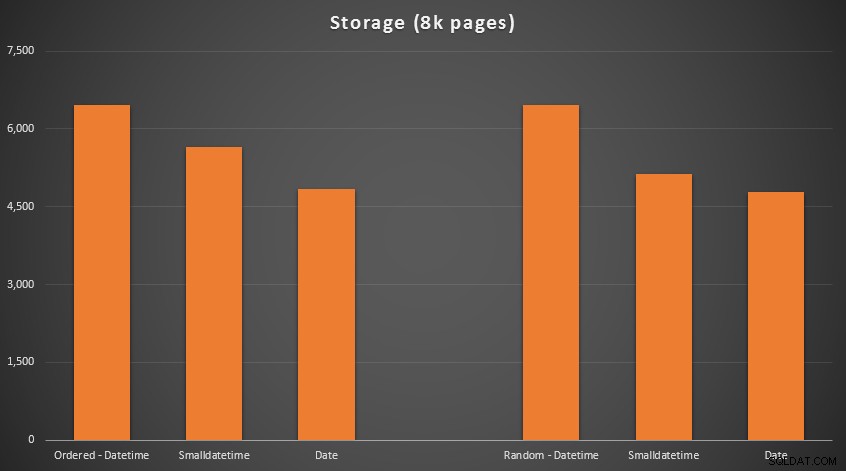
Keine Raketenwissenschaft hier; Verwenden Sie einen kleineren Datentyp, sollten Sie weniger Seiten verwenden. Umschalten von DATETIME bis zum DATE durchweg zu einer Reduzierung der Anzahl der verwendeten Seiten um 25 % führte, während SMALLDATETIME die Anforderung um 13–20 % reduziert.
Nun zur Fragmentierung und Seitendichte bei den nicht geclusterten Indizes (bei den geclusterten Indizes gab es nur sehr geringe Unterschiede):
SELECT '{table_name}',
index_id
avg_page_space_used_in_percent,
avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(), OBJECT_ID('{table_name}'),
NULL, NULL, 'DETAILED'
)
WHERE index_level = 0 AND index_id = 2; Ergebnisse:
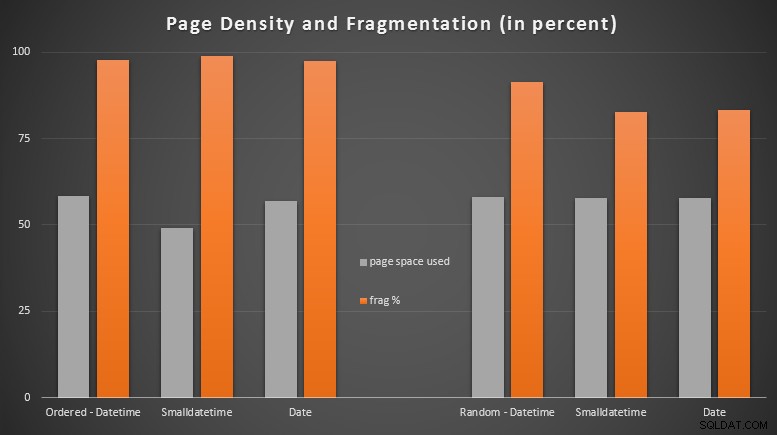
Ich war ziemlich überrascht zu sehen, dass die geordneten Daten fast vollständig fragmentiert wurden, während die zufällig eingefügten Daten tatsächlich zu einer etwas besseren Seitennutzung führten. Ich habe angemerkt, dass dies eine weitere Untersuchung außerhalb des Rahmens dieser spezifischen Tests rechtfertigt, aber es könnte etwas sein, das Sie überprüfen möchten, wenn Sie nicht gruppierte Indizes haben, die auf weitgehend sequenziellen Einfügungen beruhen.
[Eine Online-Neuerstellung der nicht geclusterten Indizes auf allen 6 Tabellen lief in 7 Sekunden, wodurch die Seitendichte wieder auf den Bereich von 99,5 % gebracht und die Fragmentierung auf unter 1 % gesenkt wurde. Aber ich habe das nicht ausgeführt, bis ich die folgenden Abfragetests durchgeführt habe …]
Bereichsabfragetest
Schließlich wollte ich die Auswirkungen auf die Laufzeiten für einfache Datumsbereichsabfragen für die verschiedenen Indizes sehen, sowohl mit der inhärenten Fragmentierung, die durch Schreibaktivitäten vom OLTP-Typ verursacht wird, als auch auf einen sauberen Index, der neu erstellt wird. Die Abfrage selbst ist ziemlich einfach:
SELECT TOP (200000) dt
FROM dbo.{table_name}
WHERE dt >= '20110101'
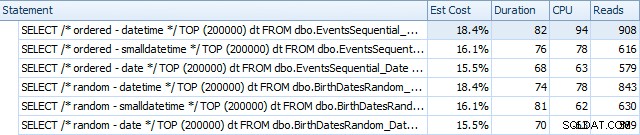
ORDER BY dt; Hier sind die Ergebnisse, bevor die Indizes mit SQL Sentry Plan Explorer neu erstellt wurden:
Und sie unterscheiden sich leicht nach den Rebuilds:
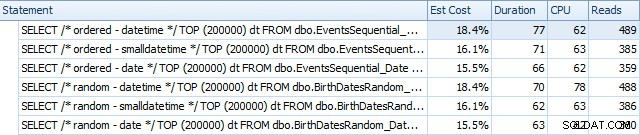
Im Wesentlichen sehen wir etwas höhere Dauer und Lesevorgänge für die DATETIME-Versionen, aber sehr wenig Unterschied in der CPU. Und die Unterschiede zwischen SMALLDATETIME und DATE sind im Vergleich vernachlässigbar. Alle Abfragen hatten vereinfachte Abfragepläne wie diese:

(Die Suche ist natürlich ein geordneter Bereichsscan.)
Schlussfolgerung
Obwohl diese Tests zugegebenermaßen ziemlich fabriziert sind und von mehr Permutationen hätten profitieren können, zeigen sie ungefähr das, was ich erwartet hatte:Die größten Auswirkungen auf diese spezifische Auswahl betreffen den Platz, der vom nicht gruppierten Index eingenommen wird (wobei die Auswahl eines dünneren Datentyps zutrifft sicherlich profitieren) und von der Zeit, die erforderlich ist, um Einfügungen in willkürlicher statt sequenzieller Reihenfolge durchzuführen (wobei DATETIME hat nur einen Rand).
Ich würde gerne Ihre Ideen hören, wie Sie Datentypauswahlen wie diese gründlicheren und strengeren Tests unterziehen können. Ich habe vor, in zukünftigen Beiträgen mehr ins Detail zu gehen.