Viele Leute verwenden Wartestatistiken als Teil ihrer Methodik zur Fehlerbehebung bei der Gesamtleistung, so wie ich es auch tue, also dreht sich die Frage, die ich in diesem Beitrag untersuchen wollte, um Wartetypen, die mit Beobachter-Overhead verbunden sind. Mit Beobachter-Overhead meine ich die Auswirkungen auf den Arbeitslastdurchsatz von SQL Server, die durch SQL Profiler, serverseitige Ablaufverfolgungen oder Sitzungen mit erweiterten Ereignissen verursacht werden. Weitere Informationen zum Thema Beobachter-Overhead finden Sie in den folgenden beiden Beiträgen meines Kollegen Jonathan Kehayias :
- Messung des „Beobachter-Overheads“ von SQL Trace im Vergleich zu erweiterten Ereignissen
- Auswirkung des erweiterten Ereignisses query_post_execution_showplan in SQL Server 2012
In diesem Beitrag möchte ich also einige Variationen des Beobachter-Overheads durchgehen und sehen, ob wir konsistente Wartetypen finden können, die mit der gemessenen Verschlechterung verbunden sind. Es gibt eine Vielzahl von Möglichkeiten, wie SQL Server-Benutzer die Ablaufverfolgung in ihren Produktionsumgebungen implementieren, daher können Ihre Ergebnisse variieren, aber ich wollte einige allgemeine Kategorien abdecken und über das berichten, was ich gefunden habe:
- Nutzung der SQL Profiler-Sitzung
- Serverseitige Trace-Nutzung
- Serverseitige Ablaufverfolgung, Schreiben in einen langsamen E/A-Pfad
- Verwendung von erweiterten Ereignissen mit einem Ringpufferziel
- Verwendung von erweiterten Ereignissen mit einem Dateiziel
- Verwendung von erweiterten Ereignissen mit einem Dateiziel auf einem langsamen E/A-Pfad
- Verwendung von erweiterten Ereignissen mit einem Dateiziel auf einem langsamen E/A-Pfad ohne Ereignisverlust
Sie können sich wahrscheinlich andere Variationen des Themas ausdenken, und ich lade Sie ein, alle interessanten Erkenntnisse in Bezug auf Beobachter-Overhead und Wartestatistiken als Kommentar in diesem Beitrag zu teilen.
Grundlage
Für den Test habe ich eine virtuelle VMware-Maschine mit vier vCPUs und 4 GB RAM verwendet. Mein virtueller Maschinengast war auf OCZ Vertex SSDs. Das Betriebssystem war Windows Server 2008 R2 Enterprise und die Version von SQL Server ist 2012, SP1 CU4.
Was die „Arbeitslast“ betrifft, verwende ich eine schreibgeschützte Abfrage in einer Schleife für die Beispieldatenbank von 2008 Credit, die 10.000.000 Mal auf GO gesetzt wurde.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Ich führe diese Abfrage auch über 16 gleichzeitige Sitzungen aus. Das Endergebnis auf meinem Testsystem ist eine CPU-Auslastung von 100 % über alle vCPUs auf dem virtuellen Gast und durchschnittlich 14.492 Batch-Anfragen pro Sekunde über einen Zeitraum von 2 Minuten.
In Bezug auf die Ereignisverfolgung habe ich in jedem Test das Showplan XML Statistics Profile verwendet für die SQL Profiler- und serverseitigen Ablaufverfolgungstests – und query_post_execution_showplan für erweiterte Event-Sessions. Ausführungsplan-Ereignisse sind sehr teuer, genau deshalb habe ich sie gewählt, damit ich sehen kann, ob ich unter extremen Umständen Wartetypen-Themes ableiten kann oder nicht.
Zum Testen der Akkumulation des Wartetyps über einen Testzeitraum habe ich die folgende Abfrage verwendet. Nichts Besonderes – einfach die Statistiken löschen, 2 Minuten warten und dann die 10 höchsten Wartezeiten für die SQL Server-Instanz während des Verschlechterungstestzeitraums sammeln:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Beachten Sie, dass ich nicht bin Herausfiltern von Wartetypen im Hintergrund, die normalerweise herausgefiltert werden, und das liegt daran, dass ich etwas nicht eliminieren wollte, das normalerweise harmlos ist – aber unter diesen Umständen weist es tatsächlich auf einen echten Bereich hin, der weiter untersucht werden muss.
SQL Profiler-Sitzung
Die folgende Tabelle zeigt die Vorher-Nachher-Stapelanforderungen pro Sekunde, wenn ein lokales SQL Profiler-Trace-Tracking Showplan XML Statistics Profile aktiviert wird (läuft auf derselben VM wie die SQL Server-Instanz):
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Sitzungs-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 1.416 |
Sie können sehen, dass der SQL Profiler-Trace einen erheblichen Durchsatzabfall verursacht.
Was die kumulierte Wartezeit über denselben Zeitraum anbelangt, waren die wichtigsten Wartetypen wie folgt (wie bei den restlichen Tests in diesem Artikel habe ich einige Testläufe durchgeführt und die Ausgabe war im Allgemeinen konsistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1.149.824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| DIRTY_PAGE_POLL | 1.198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
Der Wartetyp, der mir auffällt, ist TRACEWRITE – der von der Onlinedokumentation als ein Wartetyp definiert wird, der „auftritt, wenn der Rowset-Ablaufverfolgungsanbieter der SQL-Ablaufverfolgung entweder auf einen freien Puffer oder einen Puffer mit zu verarbeitenden Ereignissen wartet“. Die restlichen Wartetypen sehen aus wie standardmäßige Wartetypen im Hintergrund, die normalerweise aus Ihrer Ergebnismenge herausgefiltert werden. Darüber hinaus habe ich 2011 in einem Artikel mit dem Titel „Observer Overhead“ über ein ähnliches Problem mit übermäßiger Ablaufverfolgung gesprochen – die Gefahren einer zu langen Ablaufverfolgung –, sodass ich mit diesem Wartetyp manchmal vertraut war richtig auf Beobachter-Overhead-Probleme hindeutet. Nun, in diesem speziellen Fall, über den ich gebloggt habe, war es nicht SQL Profiler, sondern eine andere Anwendung, die den Rowset-Trace-Provider (ineffizient) verwendet.
Serverseitige Ablaufverfolgung
Das war für SQL Profiler, aber was ist mit dem serverseitigen Trace-Overhead? Die folgende Tabelle zeigt die Vorher-Nachher-Stapelanforderungen pro Sekunde, wenn ein lokaler serverseitiger Trace zum Schreiben in eine Datei aktiviert wird:
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 4.015 |
Die wichtigsten Wartetypen waren wie folgt (ich habe ein paar Testläufe durchgeführt und die Ausgabe war konsistent):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| WARTEN | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| DIRTY_PAGE_POLL | 1.193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Dieses Mal sehen wir TRACEWRITE nicht (wir verwenden jetzt einen Dateianbieter) und den anderen ablaufverfolgungsbezogenen Wartetyp, den undokumentierten SQLTRACE_INCREMENTAL_FLUSH_SLEEP gestiegen – hat aber im Vergleich zum ersten Test eine sehr ähnliche akkumulierte Wartezeit (120.046 vs. 120.006) – und meine Kollegin Erin Stellato (@erinstellato) hat in ihrem Beitrag „Finding Out When Wait Statistics were last cleared“ über diesen speziellen Wartetyp gesprochen . Wenn man sich also die anderen Wartetypen ansieht, springt keiner als zuverlässiges Warnsignal heraus.
Serverseitige Ablaufverfolgung schreibt in einen langsamen E/A-Pfad
Was passiert, wenn wir die serverseitige Ablaufverfolgungsdatei auf eine langsame Festplatte legen? Die folgende Tabelle zeigt die Vorher-Nachher-Batch-Anforderungen pro Sekunde, wenn eine lokale serverseitige Ablaufverfolgung aktiviert wird, die in eine Datei auf einem USB-Stick schreibt:
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 260 |
Wie wir sehen, hat sich die Leistung deutlich verschlechtert – sogar im Vergleich zum vorherigen Test.
Die häufigsten Wartetypen waren wie folgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.273 | 299.995 |
| SLEEP_TASK | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| WARTEN | 1 | 120.515 |
| DIRTY_PAGE_POLL | 1.204 | 120.513 |
Ein Wartetyp, der für diesen Test herausspringt, ist der undokumentierte SQLTRACE_FILE_BUFFER . Nicht viel dokumentiert, aber basierend auf dem Namen können wir eine fundierte Vermutung anstellen (insbesondere angesichts der Konfiguration dieses speziellen Tests).
Erweiterte Ereignisse zum Ringpufferziel
Sehen wir uns als Nächstes die Ergebnisse für Sitzungsäquivalente für erweiterte Ereignisse an. Ich habe die folgende Sitzungsdefinition verwendet:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Die folgende Tabelle zeigt die Vorher-Nachher-Stapelanforderungen pro Sekunde, wenn eine XE-Sitzung mit einem Ringpufferziel aktiviert wird (Erfassen des query_post_execution_showplan Ereignis):
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 4.737 |
Die häufigsten Wartetypen waren wie folgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120.219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| DIRTY_PAGE_POLL | 1.198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| WARTEN | 1 | 120.001 |
Nichts sprang als XE-bezogen heraus, nur "Rauschen" der Hintergrundaufgabe.
Erweiterte Ereignisse zu einem Dateiziel
Was ist mit dem Ändern der Sitzung, um ein Dateiziel anstelle eines Ringpufferziels zu verwenden? Die folgende Tabelle zeigt die Vorher-Nachher-Stapelanforderungen pro Sekunde, wenn eine XE-Sitzung mit einem Dateiziel statt einem Ringpufferziel aktiviert wird:
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 4.299 |
Die häufigsten Wartetypen waren wie folgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| WARTEN | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Nichts, mit Ausnahme von XE_TIMER_EVENT , sprang als XE-bezogen heraus. Das Wait Type Repository von Bob Ward weist darauf hin, dass dieser Typ sicher ignoriert werden kann, es sei denn, es liegt ein möglicher Fehler vor – aber würden Sie diesen normalerweise harmlosen Wartetyp realistischerweise bemerken, wenn er während einer Leistungsminderung an 9. Stelle auf Ihrem System wäre? Und was ist, wenn Sie es aufgrund seiner normalerweise harmlosen Natur bereits herausfiltern?
Erweiterte Ereignisse zu einem langsamen E/A-Pfaddateiziel
Was passiert nun, wenn ich die Datei auf einen langsamen E/A-Pfad lege? Die folgende Tabelle zeigt die Vorher-Nachher-Stapelanforderungen pro Sekunde beim Aktivieren einer XE-Sitzung mit einem Dateiziel auf einem USB-Stick:
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 4.386 |
Die häufigsten Wartetypen waren wie folgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| WARTEN | 1 | 120.002 |
| DIRTY_PAGE_POLL | 1.197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Wieder springt nichts XE-bezogenes heraus, außer dem XE_TIMER_EVENT .
Erweiterte Ereignisse zu einem langsamen E/A-Pfaddateiziel, kein Ereignisverlust
Die folgende Tabelle zeigt die Vorher-Nachher-Batch-Anforderungen pro Sekunde beim Aktivieren einer XE-Sitzung mit einem Dateiziel auf einem USB-Stick, diesmal jedoch ohne Ereignisverlust (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – was nicht empfohlen wird, und Sie werden sehen in den Ergebnissen, warum das sein könnte:
| Baseline-Batch-Anforderungen pro Sekunde (2-Minuten-Durchschnitt) | SQL Profiler-Batch-Anfragen pro Sekunde (2-Minuten-Durchschnitt) |
|---|---|
| 14.492 | 539 |
Die häufigsten Wartetypen waren wie folgt:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8.773 | 1.707.845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| DIRTY_PAGE_POLL | 1.198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| WARTEN | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Bei der extremen Durchsatzreduzierung sehen wir XE_BUFFERMGR_FREEBUF_EVENT Springen Sie in unseren kumulierten Wartezeitergebnissen auf Platz eins. Dieser ist dokumentiert in Books Online, und Microsoft teilt uns mit, dass dieses Ereignis XE-Sitzungen zugeordnet ist, die für keinen Ereignisverlust konfiguriert sind und bei denen alle Puffer in der Sitzung voll sind.
Beobachtereinfluss
Abgesehen von Wartetypen war es interessant festzustellen, welche Auswirkungen jede Beobachtungsmethode auf die Fähigkeit unserer Workload hatte, Stapelanfragen zu verarbeiten:
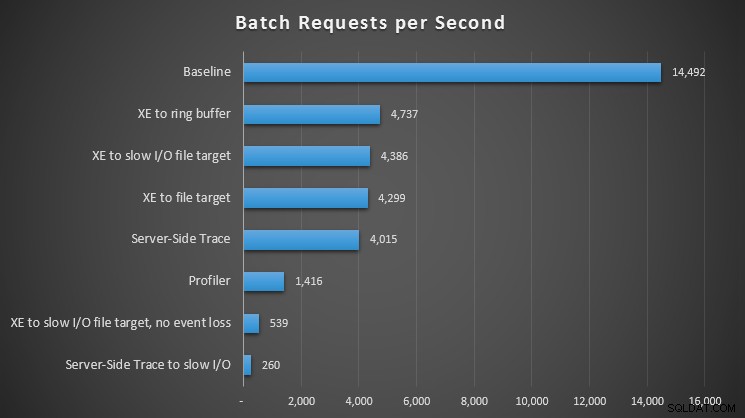
Auswirkung verschiedener Beobachtungsmethoden auf Batch-Anfragen pro Sekunde
Bei allen Ansätzen gab es einen signifikanten – aber nicht schockierenden – Treffer im Vergleich zu unserer Basislinie (keine Beobachtung); Die größten Probleme traten jedoch bei der Verwendung von Profiler auf, bei der Verwendung von serverseitigem Trace für einen langsamen E/A-Pfad oder erweiterten Ereignissen für ein Dateiziel auf einem langsamen E/A-Pfad – aber nur, wenn es für keinen Ereignisverlust konfiguriert war. Beim Ereignisverlust war dieses Setup tatsächlich auf Augenhöhe mit einem Dateiziel für einen schnellen E/A-Pfad, vermutlich weil es viel mehr Ereignisse verwerfen konnte.
Zusammenfassung
Ich habe nicht jedes mögliche Szenario getestet, und es gibt sicherlich andere interessante Kombinationen (ganz zu schweigen von unterschiedlichen Verhaltensweisen, die auf der SQL Server-Version basieren), aber die wichtigste Schlussfolgerung, die ich aus dieser Untersuchung ziehe, ist, dass Sie sich nicht immer auf eine offensichtliche Akkumulation des Wartetyps verlassen können Zeiger, wenn man einem Betrachter-Overhead-Szenario gegenübersteht. Basierend auf den Tests in diesem Beitrag zeigten nur drei von sieben Szenarien einen bestimmten Wartetyp, der Ihnen möglicherweise helfen könnte, in die richtige Richtung zu weisen. Schon damals – diese Tests fanden auf einem kontrollierten System statt – und häufig filtern die Leute die oben genannten Wartetypen als harmlose Hintergrundtypen heraus – sodass Sie sie möglicherweise überhaupt nicht sehen.
Was können Sie in Anbetracht dessen tun? Bei Leistungseinbußen ohne klare oder offensichtliche Symptome empfehle ich, den Bereich zu erweitern, um nach Ablaufverfolgungen und XE-Sitzungen zu fragen (nebenbei – ich empfehle auch, Ihren Bereich zu erweitern, wenn das System virtualisiert ist oder möglicherweise falsche Energieoptionen hat). Überprüfen Sie beispielsweise im Rahmen der Fehlerbehebung in einem System sys.[traces] und sys.[dm_xe_sessions] um zu sehen, ob etwas Unerwartetes auf dem System läuft. Es ist eine zusätzliche Ebene zu dem, worüber Sie sich Sorgen machen müssen, aber wenn Sie ein paar schnelle Überprüfungen durchführen, können Sie viel Zeit sparen.