Partitionierung ist eine SQL Server-Funktion, die häufig implementiert wird, um Herausforderungen im Zusammenhang mit Verwaltbarkeit, Wartungsaufgaben oder Sperren und Blockieren zu verringern. Die Verwaltung großer Tabellen kann durch Partitionierung einfacher werden und die Skalierbarkeit und Verfügbarkeit verbessern. Darüber hinaus kann ein Nebenprodukt der Partitionierung eine verbesserte Abfrageleistung sein. Es ist keine Garantie oder Selbstverständlichkeit und es ist nicht der Hauptgrund für die Implementierung der Partitionierung, aber es lohnt sich, es zu überprüfen, wenn Sie eine große Tabelle partitionieren.
Hintergrund
Kurz gesagt, die SQL Server-Partitionierungsfunktion ist nur in Enterprise und Developer Edition verfügbar. Die Partitionierung kann während des anfänglichen Datenbankentwurfs implementiert werden, oder sie kann eingerichtet werden, nachdem eine Tabelle bereits Daten enthält. Beachten Sie, dass das Ändern einer vorhandenen Tabelle mit Daten in eine partitionierte Tabelle nicht immer schnell und einfach ist, aber bei guter Planung durchaus machbar ist und die Vorteile schnell realisiert werden können.
Bei einer partitionierten Tabelle werden die Daten basierend auf dem Wert für eine bestimmte Spalte (als Partitionierungsspalte bezeichnet, die in der Partitionsfunktion definiert ist) in kleinere physische Strukturen aufgeteilt. Wenn Sie Daten nach Jahr trennen möchten, können Sie eine Spalte namens DateSold als Partitionierungsspalte verwenden, und alle Daten für 2013 würden sich in einer Struktur befinden, alle Daten für 2012 würden sich in einer anderen Struktur befinden usw. Diese separaten Datensätze Ermöglichen Sie eine konzentrierte Wartung (Sie können nur eine Partition eines Index statt des gesamten Index neu erstellen) und ermöglichen Sie das schnelle Hinzufügen und Entfernen von Daten, da sie vor dem tatsächlichen Hinzufügen oder Entfernen aus der Tabelle bereitgestellt werden können.
Die Einrichtung
Um die Unterschiede in der Abfrageleistung für eine partitionierte und eine nicht partitionierte Tabelle zu untersuchen, habe ich zwei Kopien der Sales.SalesOrderHeader-Tabelle aus der AdventureWorks2012-Datenbank erstellt. Die nicht partitionierte Tabelle wurde nur mit einem gruppierten Index auf SalesOrderID, dem herkömmlichen Primärschlüssel für die Tabelle, erstellt. Die zweite Tabelle wurde auf OrderDate partitioniert, mit OrderDate und SalesOrderID als Clusterschlüssel, und hatte keine zusätzlichen Indizes. Beachten Sie, dass bei der Entscheidung, welche Spalte für die Partitionierung verwendet werden soll, zahlreiche Faktoren zu berücksichtigen sind. Beim Partitionieren wird häufig, aber sicherlich nicht immer, ein Datumsfeld verwendet, um die Partitionsgrenzen zu definieren. Daher wurde OrderDate für dieses Beispiel ausgewählt und Beispielabfragen wurden verwendet, um typische Aktivitäten für die SalesOrderHeader-Tabelle zu simulieren. Die Anweisungen zum Erstellen und Füllen beider Tabellen können hier heruntergeladen werden.
Nach dem Erstellen der Tabellen und dem Hinzufügen von Daten wurden die vorhandenen Indizes überprüft und dann die Statistiken mit FULLSCAN aktualisiert:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Außerdem haben beide Tabellen die exakt gleiche Datenverteilung und minimale Fragmentierung.
Leistung für eine einfache Abfrage
Bevor zusätzliche Indizes hinzugefügt wurden, wurde eine grundlegende Abfrage für beide Tabellen ausgeführt, um die Gesamteinnahmen des Vertriebsmitarbeiters für im Dezember 2012 aufgegebene Bestellungen zu berechnen:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTIK-IO-AUSGABE
Tabelle 'Arbeitstisch'. Scan-Anzahl 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Big_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 2710440, physische Lesevorgänge 2226, Read-Ahead-Lesevorgänge 2658769, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Arbeitstisch'. Scan-Zähler 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Part_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 248128, physische Lesevorgänge 3, Read-Ahead-Lesevorgänge 245030, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.

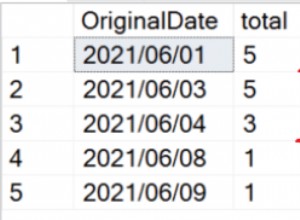
Gesamtsummen nach Verkäufer für Dezember – nicht partitionierte Tabelle
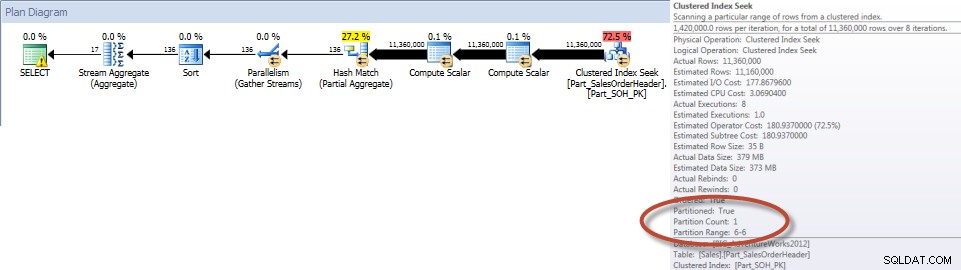
Gesamtsummen nach Verkäufer für Dezember – partitionierte Tabelle
Wie erwartet musste die Abfrage der nicht partitionierten Tabelle einen vollständigen Scan der Tabelle durchführen, da es keinen unterstützenden Index gab. Im Gegensatz dazu musste die Abfrage der partitionierten Tabelle nur auf eine Partition der Tabelle zugreifen.
Um fair zu sein:Wenn es sich um eine Abfrage handelt, die wiederholt mit unterschiedlichen Datumsbereichen ausgeführt wird, wäre der entsprechende nicht gruppierte Index vorhanden. Zum Beispiel:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Wenn dieser Index erstellt ist, werden die E/A-Statistiken bei erneuter Ausführung der Abfrage gelöscht und der Plan ändert sich, um den nicht gruppierten Index zu verwenden:
STATISTIK-IO-AUSGABE
Tabelle 'Arbeitstisch'. Scan-Anzahl 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Big_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 42901, physische Lesevorgänge 3, Read-Ahead-Lesevorgänge 42346, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.

Totals by Sales Person for December – NCI on Non-Partitioned Table
Mit einem unterstützenden Index erfordert die Abfrage für Sales.Big_SalesOrderHeader deutlich weniger Lesevorgänge als der Clustered-Index-Scan für Sales.Part_SalesOrderHeader, was nicht unerwartet ist, da der Clustered-Index viel breiter ist. Wenn wir einen vergleichbaren Nonclustered-Index für Sales.Part_SalesOrderHeader erstellen, sehen wir ähnliche I/O-Nummern:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIK-IO-AUSGABE
Tabelle 'Part_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 42894, physische Lesevorgänge 1, Read-Ahead-Lesevorgänge 42378, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
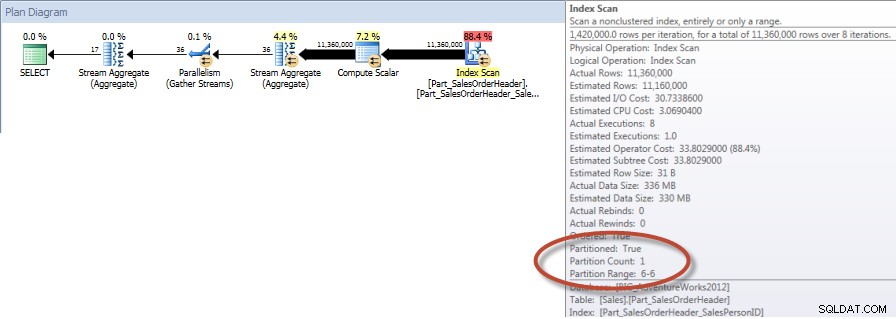
Gesamtsummen nach Verkäufer für Dezember – NCI auf partitionierter Tabelle mit Eliminierung
Und wenn wir uns die Eigenschaften des Nonclustered Index Scan ansehen, können wir verifizieren, dass die Engine nur auf eine Partition (6) zugegriffen hat.
Wie ursprünglich erwähnt, wird die Partitionierung normalerweise nicht implementiert, um die Leistung zu verbessern. Im oben gezeigten Beispiel schneidet die Abfrage der partitionierten Tabelle nicht wesentlich besser ab, solange der entsprechende Nonclustered-Index vorhanden ist.
Leistung für eine Ad-hoc-Abfrage
Eine Abfrage der partitionierten Tabelle kann dieselbe Abfrage gegenüber der nicht partitionierten Tabelle in einigen Fällen übertreffen, beispielsweise wenn die Abfrage den gruppierten Index verwenden muss. Während es ideal ist, dass die Mehrheit der Abfragen von Nonclustered-Indizes unterstützt wird, erlauben einige Systeme Ad-hoc-Abfragen von Benutzern, und andere haben Abfragen, die so selten ausgeführt werden, dass sie keine Unterstützung von Indizes rechtfertigen. Anhand der SalesOrderHeader-Tabelle kann ein Benutzer die folgende Abfrage ausführen, um Bestellungen aus Dezember 2012 zu finden, die bis Ende des Jahres versandt werden mussten, aber nicht versendet wurden, für eine bestimmte Gruppe von Kunden und mit einem TotalDue von mehr als 1000 USD:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTIK-IO-AUSGABE
Tabelle 'Big_SalesOrderHeader'. Scan-Anzahl 9, logische Lesevorgänge 2711220, physische Lesevorgänge 8386, Read-Ahead-Lesevorgänge 2662400, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Part_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 248128, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 243792, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
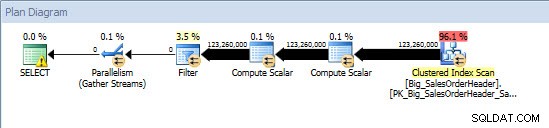
Ad-hoc-Abfrage – nicht partitionierte Tabelle
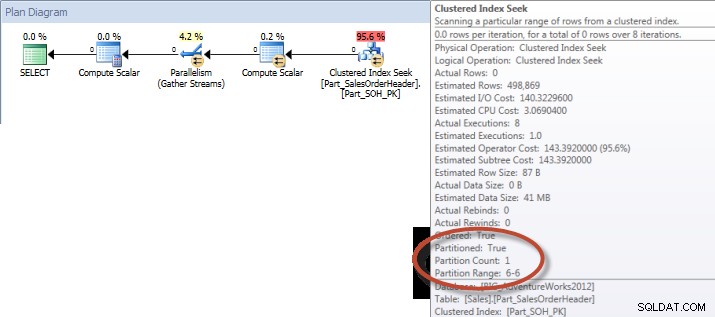
Ad-hoc-Abfrage – Partitionierte Tabelle
Für die nicht partitionierte Tabelle erforderte die Abfrage einen vollständigen Scan für den gruppierten Index, aber für die partitionierte Tabelle führte die Abfrage eine Indexsuche des gruppierten Index durch, da die Engine die Partitionsentfernung verwendete und nur die Daten las, die sie unbedingt benötigte. In diesem Beispiel ist dies ein erheblicher Unterschied in Bezug auf E/A und je nach Hardware möglicherweise ein dramatischer Unterschied in der Ausführungszeit. Die Abfrage könnte optimiert werden, indem der entsprechende Index hinzugefügt wird, aber es ist normalerweise nicht möglich, für alle zu indizieren einzeln Anfrage. Insbesondere bei Lösungen, die Ad-hoc-Abfragen zulassen, kann man durchaus sagen, dass man nie weiß, was die Benutzer tun werden. Eine Abfrage kann einmal ausgeführt und nie wieder ausgeführt werden, und das Erstellen eines Index im Nachhinein ist sinnlos. Daher ist es wichtig, beim Wechsel von einer nicht partitionierten Tabelle zu einer partitionierten Tabelle den gleichen Aufwand und Ansatz wie beim regulären Index-Tuning anzuwenden; Sie möchten sicherstellen, dass die entsprechenden Indizes vorhanden sind, um die meisten Abfragen zu unterstützen.
Performance- und Indexausrichtung
Ein weiterer zu berücksichtigender Faktor beim Erstellen von Indizes für eine partitionierte Tabelle ist, ob der Index ausgerichtet werden soll oder nicht. Indizes müssen mit der Tabelle ausgerichtet werden, wenn Sie planen, Daten in Partitionen hinein- und herauszuwechseln. Beim Erstellen eines Nonclustered-Index für eine partitionierte Tabelle wird standardmäßig ein ausgerichteter Index erstellt, wobei die Partitionierungsspalte als eingeschlossene Spalte zum Index hinzugefügt wird.
Ein nicht ausgerichteter Index wird erstellt, indem ein anderes Partitionsschema oder eine andere Dateigruppe angegeben wird. Die Partitionierungsspalte kann Teil des Indexes als Schlüsselspalte oder eingeschlossene Spalte sein, aber wenn das Partitionsschema der Tabelle nicht verwendet wird oder eine andere Dateigruppe verwendet wird, wird der Index nicht ausgerichtet.
Ein ausgerichteter Index wird genau wie die Tabelle partitioniert – die Daten werden in separaten Strukturen existieren – und daher kann eine Partitionseliminierung auftreten. Ein nicht ausgerichteter Index existiert als eine physische Struktur und bietet je nach Prädikat möglicherweise nicht den erwarteten Nutzen für eine Abfrage. Stellen Sie sich eine Abfrage vor, die Verkäufe nach Kontonummer zählt, gruppiert nach Monat:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Wenn Sie mit der Partitionierung nicht so vertraut sind, können Sie einen Index wie diesen erstellen, um die Abfrage zu unterstützen (beachten Sie, dass die PRIMARY-Dateigruppe angegeben ist):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Dieser Index ist nicht ausgerichtet, obwohl er OrderDate enthält, da es Teil des Primärschlüssels ist. Die Spalten sind auch enthalten, wenn wir einen ausgerichteten Index erstellen, aber beachten Sie den Unterschied in der Syntax:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Mit sp_helpindex:
von Kimberly Tripp können wir überprüfen, welche Spalten im Index vorhanden sindEXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex für Sales.Part_SalesOrderHeader
Wenn wir unsere Abfrage ausführen und sie dazu zwingen, den nicht ausgerichteten Index zu verwenden, wird der gesamte Index gescannt. Obwohl OrderDate Teil des Index ist, ist es nicht die führende Spalte, sodass die Engine den OrderDate-Wert für jede AccountNumber überprüfen muss, um festzustellen, ob er zwischen dem 1. Januar 2013 und dem 31. Juli 2013 liegt:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK-IO-AUSGABE
Tabelle 'Arbeitstisch'. Scan-Zähler 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Part_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 786861, physische Lesevorgänge 1, Read-Ahead-Lesevorgänge 770929, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
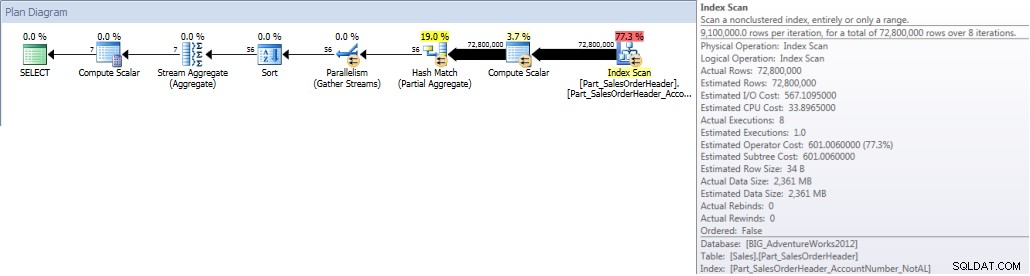
Kontosummen nach Monat (Januar – Juli 2013) mit Nicht- Ausgerichtetes NCI (erzwungen)
Wenn die Abfrage dagegen gezwungen ist, den ausgerichteten Index zu verwenden, kann die Partitionsentfernung verwendet werden, und es sind weniger I/Os erforderlich, obwohl OrderDate keine führende Spalte im Index ist.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK-IO-AUSGABE
Tabelle 'Arbeitstisch'. Scan-Zähler 0, logische Lesevorgänge 0, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.
Tabelle 'Part_SalesOrderHeader'. Anzahl der Scans 9, logische Lesevorgänge 456258, physische Lesevorgänge 16, Read-Ahead-Lesevorgänge 453241, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
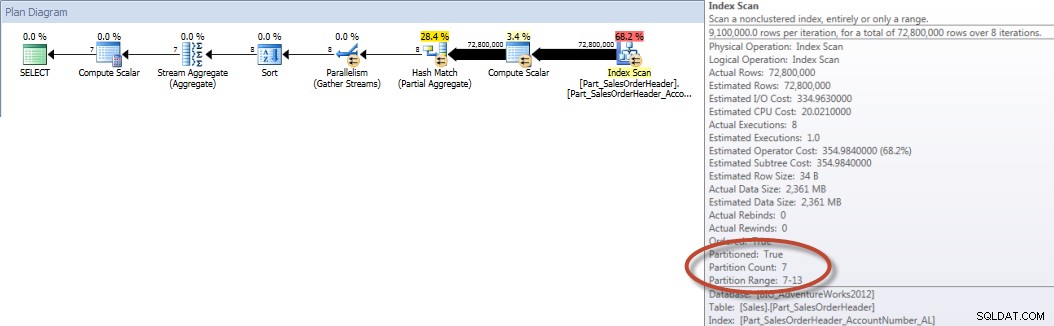
Kontosummen nach Monat (Januar – Juli 2013) unter Verwendung von Aligned NCI (erzwungen)
Zusammenfassung
Die Entscheidung, eine Partitionierung zu implementieren, erfordert sorgfältige Überlegungen und Planung. Einfache Verwaltung, verbesserte Skalierbarkeit und Verfügbarkeit sowie weniger Blockierung sind häufige Gründe für die Partitionierung von Tabellen. Die Verbesserung der Abfrageleistung ist kein Grund für die Partitionierung, obwohl dies in einigen Fällen ein vorteilhafter Nebeneffekt sein kann. In Bezug auf die Leistung ist es wichtig sicherzustellen, dass Ihr Implementierungsplan eine Überprüfung der Abfrageleistung enthält. Bestätigen Sie, dass Ihre Indizes Ihre Abfragen nachdem weiterhin angemessen unterstützen die Tabelle partitioniert ist, und vergewissern Sie sich, dass Abfragen, die Clustered- und Nonclustered-Indizes verwenden, gegebenenfalls von der Partitionsentfernung profitieren.