Ich habe zuvor über die Vorteile der Verwendung von NOEXPAND geschrieben Hinweise, auch in der Enterprise Edition. Die Details sind alle im verlinkten Artikel, aber kurz zusammengefasst:
- SQL Server wird nur automatisch erstellen Statistiken zu einer indizierten Ansicht, wenn ein
NOEXPANDTabellenhinweis wird verwendet. Das Weglassen dieses Hinweises kann zu Ausführungsplanwarnungen wegen fehlender Statistiken führen, die nicht durch manuelles Erstellen von Statistiken behoben werden können. - SQL Server wird nur verwenden automatisch oder manuell erstellte Ansichtsstatistiken in Kardinalitätsschätzungsberechnungen, wenn die Abfrage direkt auf die Ansicht verweist, und ein
NOEXPANDHinweis verwendet wird. Für alle außer den trivialsten Ansichtsdefinitionen bedeutet dies, dass die Qualität der Kardinalitätsschätzungen wahrscheinlich geringer ist, wenn dieser Hinweis nicht verwendet wird, was häufig zu weniger optimalen Ausführungsplänen führt. - Das Fehlen oder die Unfähigkeit, Ansichtsstatistiken zu verwenden, kann dazu führen, dass der Optimierer Kardinalitätsschätzungen annimmt, selbst wenn Basistabellenstatistiken verfügbar sind. Dies kann passieren, wenn ein Teil des Abfrageplans durch die automatische Ansichtszuordnungsfunktion durch eine indizierte Ansichtsreferenz ersetzt wird, aber keine Ansichtsstatistiken verfügbar sind, wie oben beschrieben.
Es gibt eine weitere Konsequenz, wenn NOEXPAND nicht verwendet wird Hinweis, den ich vor ein paar Jahren in meinem Artikel Optimizer Limitations with Filtered Indexes erwähnt habe:
Das NOEXPAND Hinweise werden sogar in der Enterprise Edition benötigt, um sicherzustellen, dass die Eindeutigkeitsgarantie, die von den Ansichtsindizes bereitgestellt wird, vom Optimierer verwendet wird.
Dieser Artikel untersucht diese Aussage und ihre Auswirkungen im Detail.
Demo-Setup
Das folgende Skript erstellt eine einfache Tabelle und eine indizierte Ansicht:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Dadurch wird eine Heap-Tabelle mit einer einzigen Spalte und eine uneingeschränkte Ansicht derselben Tabelle mit einem eindeutigen gruppierten Index erstellt. Dies ist nicht als realistischer Anwendungsfall für eine indizierte Ansicht gedacht; aber es wird helfen, die wichtigsten Punkte mit einem Minimum an Ablenkungen zu veranschaulichen. Der wichtige Punkt ist, dass die Basistabelle hier überhaupt keine Indizes hat (nicht einmal einen geclusterten Index), die Ansicht jedoch schon, und dieser Index ist eindeutig.
Die Beispielabfrage
Betrachten Sie die folgende einfache Abfrage für die Basistabelle:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Der für diese Abfrage angezeigte Ausführungsplan hängt von der verwendeten Edition von SQL Server ab. Wenn nicht Enterprise Edition (oder gleichwertig), sehen Sie einen Plan wie diesen:

Der SQL Server-Abfrageoptimierer hat sich dafür entschieden, die Basistabelle zu scannen und die angegebene Unterscheidbarkeit mithilfe eines Distinct Sort-Operators anzuwenden. Diese Planform wird vollständig erwartet, da der automatische Abgleich indizierter Ansichten außerhalb der Enterprise Edition nicht verfügbar ist. Ich werde ab jetzt aufhören, „Enterprise Edition oder gleichwertig“ zu sagen, aber bitte folgern Sie weiterhin, dass ich jede Edition meine, die den automatischen Ansichtsabgleich unterstützt, wenn ich von nun an „Enterprise Edition“ sage.
Der Hinweis ANSICHTEN ERWEITERN
Dies ist ein bisschen nebensächlich, aber um den gleichen Plan für die Enterprise Edition zu erhalten, müssen wir EXPAND VIEWS verwenden Abfragehinweis:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Es mag etwas seltsam erscheinen, diesen Hinweis zu verwenden, wenn es keine Ansichtsreferenzen gibt in der Abfrage, aber so funktioniert es. Die EXPAND VIEWS Hint gibt effektiv an, dass der Abgleich der indizierten Ansicht deaktiviert werden sollte, während die Abfrage kompiliert und optimiert wird. Um es klar zu sagen:Ohne diesen Hinweis kann die Enterprise Edition ansonsten (Teile davon) die Abfrage mit einer oder mehreren indizierten Ansichten abgleichen.
Mit aktiviertem automatischen Ansichtsabgleich
Ohne EXPAND VIEWS Hinweis:Das Kompilieren derselben Abfrage in der Developer Edition (z. B.) führt zu einem anderen Plan:
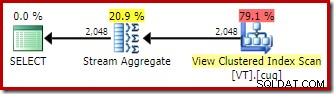
Die Anwendung des indizierten Ansichtsabgleichs bedeutet, dass der Ausführungsplan anstelle eines Basistabellen-Scans einen Scan des View-Clustered-Index enthält.
Derselbe Plan wird in diesem Fall erstellt, wenn die Abfrage direkt auf die Ansicht verweist (statt auf die Basistabelle):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; In allen Editionen wird die Ansichtsreferenz erweitert, bevor die Abfrageoptimierung beginnt. In Enterprise-äquivalenten Editionen kann das erweiterte Formular später wieder an die Ansicht angepasst werden. Dies ist ein Schlüsselkonzept, das Sie verstehen sollten, wenn Sie darüber nachdenken, wie der Abfragecompiler und -optimierer indizierte Ansichten in SQL Server verwenden.
Das Stream-Aggregat
Der interessanteste Unterschied zwischen den beiden Plänen, den wir bisher gesehen haben, ist das Stream Aggregate im View-Matched-Plan. Wenn Sie sich die geschätzten Kosten der Table Scan- und View Scan-Operatoren ansehen, werden Sie feststellen, dass sie genau gleich sind. Der Optimierer entschied sich nicht für die Verwendung der indizierten Ansicht, weil sie den Zugriff auf die Daten billiger machte. Stattdessen lässt das Scannen des Ansichtsindex den DISTINCT zu Anforderung, als Stream Aggregate implementiert zu werden, anstatt als Hash Aggregate oder Distinct Sort (wie im ersten Plan).
Ein Stream-Aggregat erfordert eine nach Gruppierungsspalte(n) geordnete Eingabe. In diesem Fall entspricht der Unterschied der Gruppierung nach der einzelnen Spalte, und der eindeutige gruppierte Index der Ansicht bietet die notwendige Ordnungsgarantie. Das Kostenmodell des Optimierers identifiziert das Stream-Aggregat als eine kostengünstigere Option als ein Distinct Sort- oder Hash-Aggregat für diese Abfrage. Dies ist die Grundlage dafür, dass der Optimierer entscheidet, auf die indizierte Ansicht zuzugreifen, wenn der automatische Ansichtsabgleich verfügbar ist.
Nach allem, was gesagt und verstanden wurde, ist Stream Aggregate immer noch unerwartet:Angesichts der Eindeutigkeitsgarantie, die der Ansichtsindex bietet, besteht überhaupt keine Notwendigkeit, diese Gruppierungsoperation durchzuführen. Das Einzigartige Der gruppierte Index stellt bereits sicher, dass die Spalte keine Duplikate enthält.
Das ist kurz gesagt das Problem. Wenn der automatische Ansichtsabgleich verwendet wird, erkennt der Optimierer die durch den Ansichtsindex bereitgestellte Ordnungsgarantie, aber nicht die Eindeutigkeitsgarantie.
Einen NOEXPAND-Hinweis verwenden
Um den idealen Ausführungsplan für diese Abfrage zu erhalten, müssen wir direkt auf die Ansicht verweisen und ein NOEXPAND verwenden Tabellenhinweis:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Dies gibt uns den Plan, den ein erfahrener Datenbankexperte erwarten würde; eine, die korrekt erkennt, dass die distinkte Operation redundant ist und entfernt werden kann:
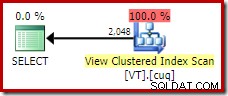
Ein zweites Beispiel
Wenn Sie die Eindeutigkeitsgarantie eines Ansichtsindex nicht nutzen, kann dies andere Auswirkungen auf den endgültigen Ausführungsplan haben. Betrachten Sie nun einen Self-Join der indizierten Ansicht (wieder nur zur Veranschaulichung eines Konzepts – dies soll keine realistische Abfrage sein):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Bei Verwendung der Developer Edition greift der ausgewählte Ausführungsplan überhaupt nicht auf die indizierte Ansicht zu und weist einen Hash-Join auf (manchmal ein Hinweis darauf, dass ein nützlicher Index fehlt):
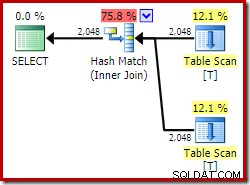
Lassen Sie uns nun genau die gleiche Abfrage versuchen, aber mit einem NOEXPAND Hinweis zu jeder View-Referenz:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Der Ausführungsplan verfügt jetzt über zwei Zugriffe auf indizierte Ansichten und einen Merge-Join:
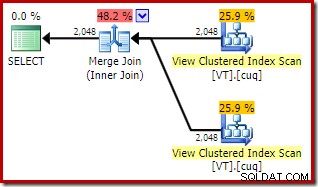
Dieser neue Plan hat viel niedrigere geschätzte Kosten als der Hash-Join-Plan, also warum hat der Optimierer diese Option nicht vorher gewählt? Wir können sehen, warum, indem wir der ursprünglichen Abfrage einen Merge-Join-Hinweis hinzufügen:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Dies ergibt ein ähnlich aussehendes Plan, der sich für den Zugriff auf die Ansicht entscheidet, obwohl NOEXPAND wurde nicht angegeben:
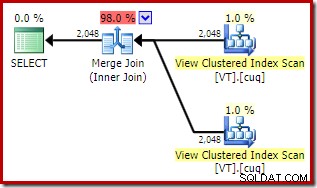
Die geschätzten Gesamtkosten dieses Plans sind höher als in den beiden vorherigen Beispielen. Der Merge Join in diesem Plan macht auch einen höheren Anteil der geschätzten Gesamtkosten aus als zuvor (98 % gegenüber 48,2 %).
Der Grund dafür ist aus den Eigenschaften des Merge-Joins ersichtlich. Im NOEXPAND Plan, war es ein Eins-zu-viele-Merge-Join. Im Plan direkt darüber handelt es sich um eine Viele-zu-Viele-Zusammenführungsverknüpfung. Das Kostenmodell des Optimierers weist n:n-Merge-Joins höhere Kosten zu, da eine tempdb-Arbeitstabelle benötigt wird, um alle Duplikate zu handhaben.
Schlussfolgerungen
Die Garantien eines eindeutigen Indexes können ein mächtiges Optimierungstool sein, daher ist es schade, dass der automatische Indexabgleich derzeit nicht davon profitieren kann. Die potenziellen Vorteile gehen über das Eliminieren unnötiger Aggregationen oder das Ermöglichen eines One-to-Many-Merge-Joins hinaus, wie in den vorherigen einfachen Beispielen gezeigt. Im Allgemeinen kann es schwierig sein, zu erkennen, dass ein Ausführungsplan suboptimal ist, weil der Optimierer es versäumt hat, eine Eindeutigkeitsgarantie zu nutzen.
Diese Einschränkung des Optimierers gilt nicht nur für den eindeutigen gruppierten Index, den eine Ansicht haben muss, um materialisiert zu werden. In komplexeren Szenarien können auch zusätzliche nicht gruppierte Indizes in der Ansicht vorhanden sein; möglicherweise um tabellenübergreifende Beziehungen widerzuspiegeln, die schwer durchzusetzen oder anderweitig darzustellen sind. Wenn diese Nonclustered-Indizes als eindeutig definiert sind, übersieht der Optimierer diese Garantien ebenfalls, wenn der automatische Indexabgleich verwendet wird.
Wenn man dies zu den Einschränkungen bei der Erstellung und Verwendung statistischer Informationen hinzufügt, scheint es, dass das Verlassen auf den automatischen Ansichtsabgleich zu minderwertigen Ausführungsplänen führen kann. Die sicherste Option ist wahrscheinlich, explizit auf indizierte Ansichten zu verweisen und ein NOEXPAND zu verwenden Hinweis jedes Mal – zumindest bis diese Probleme im Produkt behandelt werden.
Minderungsfaktoren
Ich möchte betonen, dass das in diesem Artikel beschriebene Problem nur für die Eindeutigkeitsgarantie gilt, die von einem eindeutigen Ansichtsindex bereitgestellt wird. Wenn der Optimierer die erforderlichen Eindeutigkeitsinformationen auf andere Weise erhalten kann , stehen die Chancen gut, dass Optimierungsprobleme vermieden werden.
Beispielsweise kann es einen geeigneten eindeutigen Index für eine Basistabelle geben, auf die von der Ansicht verwiesen wird. Oder im Fall einer Ansicht, die Aggregation enthält, kann der Optimierer bereits eine nützliche Eindeutigkeitsgarantie aus dem GROUP BY der Ansicht ableiten Klausel. Die übliche Praxis, den Gruppierungsschlüsseln einen View-Clustered-Index hinzuzufügen, fügt in diesem Fall keine zusätzlichen Eindeutigkeitsinformationen hinzu.
Dennoch gibt es Zeiten, in denen diese „Eindeutigkeitsüberprüfung“ bedeuten kann, dass Sie Ausführungspläne von besserer Qualität erhalten, indem Sie eine explizite Ansichtsreferenz und NOEXPAND verwenden Hinweise, sogar in der Enterprise Edition.