Von Zeit zu Zeit sehe ich jemand eine Anforderung ausdrückt eine Zufallszahl für einen Schlüssel zu erstellen. Normalerweise ist dies eine Art von Surrogat CustomerID oder Benutzer-ID zu erstellen, die eine eindeutige Nummer innerhalb eines gewissen Bereichs ist, ist aber nicht sequentiell ausgegeben, und daher weit weniger erratbar als ein IDENTITY Wert.
NEWID() löst das Erraten Problem, aber die Leistungseinbuße ist in der Regel ein Deal-Breaker, vor allem, wenn gruppierte:viel breitere Tasten als ganze Zahlen sind, und Seitenteilungen durch nicht aufeinanderfolgende Werte. NEWSEQUENTIALID() die Seitenteilung Problem löst, ist aber immer noch ein sehr großer Schlüssel, und wieder stellt das Problem, dass Sie den nächsten Wert erraten (oder vor kurzem ausgegebenen Werte) mit einem gewissen Grad an Genauigkeit.
Als Ergebnis sie wollen eine Technik, einen zufälligen zu erzeugen und eindeutige Ganzzahl. eine Zufallszahl auf eigene Erzeugung ist nicht schwierig, mit Methoden wie RAND() oder CHECKSUM(NEWID()) . Das Problem kommt, wenn Sie Kollisionen erkennen müssen. Werfen wir einen kurzen Blick auf einen typischen Ansatz, vorausgesetzt, wollen wir CustomerID Werte zwischen 1 und 1.000.000:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END Wie die Tabelle größer wird, nicht nur die Überprüfung auf Duplikate teurer, aber Ihre Chancen zu generieren als auch ein Duplikat nach oben. So dass dieser Ansatz in Ordnung zu arbeiten scheint, wenn die Tabelle klein ist, aber ich vermute, dass es mehr und mehr im Laufe der Zeit weh tun muss.
Ein anderer Ansatz
Ich bin ein großer Fan von Hilfstischen; Ich habe seit einem Jahrzehnt öffentlich über Kalender Tabellen und Tabellen von Zahlen zu schreiben und mit ihnen weit mehr für. Und dies ist ein Fall, wo ich denke, dass ein vorausgefüllte Tisch in Echt nützlich sein könnte. Warum sollten Sie sich darauf verlassen, zur Laufzeit Zufallszahlen zu generieren und mit potenziellen Duplikaten umzugehen, wenn Sie alle diese Werte im Voraus füllen können und – mit 100 %iger Sicherheit, wenn Sie Ihre Tabellen vor nicht autorisiertem DML schützen – wissen, dass der nächste Wert, den Sie auswählen, nie war verwendet vor?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; Diese Population nahm 9 Sekunden zu erstellen (in einer VM auf einem Laptop) und beschäftigt rund 17 MB auf der Festplatte. Die Daten in der Tabelle sieht wie folgt aus:
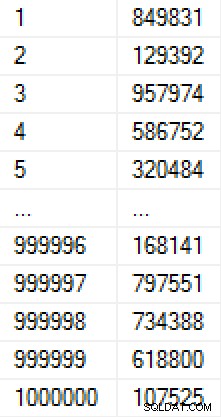
(Wenn wir über waren besorgt, wie die Zahlen wurden bevölkert zu werden, haben wir eine eindeutige Einschränkung auf die Spalte Wert hinzufügen könnte, die in der Tabelle 30 MB machen würde. Hätten wir Seite Komprimierung angewendet, wäre es 11 MB oder 25 MB gewesen sind. )
Ich habe eine weitere Kopie der Tabelle, und es mit den gleichen Werten aufgefüllt, so dass ich zwei verschiedene Verfahren zur Gewinnung von dem nächsten Wert testen konnte:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Nun, zu jeder Zeit wir eine neue Zufallszahl wollen, können wir nur einen Pop vom Stapel von vorhandenen Nummern, und es löschen. Dies verhindert, dass uns etwa Duplikate zu kümmern, und ermöglicht es uns, Zahlen zu ziehen - einen Clustered-Index mit -, die tatsächlich bereits in zufälliger Reihenfolge sind. (Streng genommen haben wir nicht zu Löschen die Zahlen, wie wir sie verwenden; wir könnten eine Spalte, um anzuzeigen, fügen Sie, ob ein Wert verwendet wurde, -. Dies würde es einfacher machen, wieder einzustellen und diesen Wert in dem Fall wiederverwenden, dass ein Kunde später gelöscht wird oder etwas schief geht außerhalb dieser Transaktion aber bevor sie vollständig erstellt werden)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
Ich habe eine Tabelle Variable den Zwischenausgang zu halten, weil es verschiedene Einschränkungen mit zusammensetzbaren DML sind, dass es unmöglich einfügen in die Tabelle Kunden direkt aus dem DELETE (Beispielsweise das Vorhandensein von Fremdschlüssel). Noch anerkennen, dass es nicht immer möglich sein wird, habe ich auch diese Methode testen wollte:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Beachten Sie, dass keine dieser Lösungen wirklich zufälliger Reihenfolge zu gewährleisten, insbesondere dann, wenn die Zufallszahlen-Tabelle anderen Indizes (wie zum Beispiel einen eindeutigen Index auf die Spalte Wert) aufweist. Es gibt keine Möglichkeit, einen Auftrag für einen DELETE zu definieren, mit TOP; aus der Dokumentation:
Also, wenn Sie zufällige Reihenfolge garantieren wollen, könnten Sie so etwas wie dies stattdessen tun:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Eine weitere Überlegung dabei ist, dass für diese Tests, die Kunden Tabellen haben einen gruppierten Primärschlüssel auf der Spalte CustomerID; Dies wird sicherlich zu Seitenteilungen führen, wie Sie zufällige Werte einfügen. In der realen Welt, wenn Sie diese Anforderung hat, würden Sie wahrscheinlich auf einer andere Spalte am Ende Clustering.
Beachten Sie, dass ich auch habe weggelassen Transaktionen und Fehler hier Handhabung, aber auch diese sollte eine Überlegung für die Produktion Code.
Leistungstests
Um einige realistische Leistungsvergleiche zu ziehen, habe ich fünf gespeicherte Prozeduren erstellt, die die folgenden Szenarien darstellen (Testgeschwindigkeit, Verteilung und Kollisionshäufigkeit der verschiedenen Zufallsmethoden sowie die Geschwindigkeit der Verwendung einer vordefinierten Tabelle mit Zufallszahlen):
- Runtime Generation mit
CHECKSUM(NEWID()) - Runtime Generation mit
CRYPT_GEN_RANDOM() - Runtime Generation mit
RAND() - Vordefinierte Zahlen Tabelle mit Tabellenvariable
- Vordefinierte Zahlen Tisch mit Direkteinsatz
Sie verwenden eine Protokollierungstabelle Dauer und Anzahl der Kollisionen zu verfolgen:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
Der Code für das Verfahren folgt (Klicken zum Anzeigen / Verbergen):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO Und um dies zu testen, würde ich jede gespeicherte Prozedur 1.000.000 mal laufen:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
Es überrascht nicht, die Verfahren die vordefinierte Tabelle von Zufallszahlen unter Verwendung nahm etwas länger * am Anfang des Tests *, da sie beide Lese auszuführen hatte und schreiben I / O jedes Mal. Wenn man bedenkt, dass diese Zahlen sind in Mikrosekunden hier sind die durchschnittlichen Laufzeiten für jedes Verfahren, in unterschiedlichen Abständen entlang dem Weges (gemittelt über die ersten 10.000 Hinrichtung, die Mitte 10.000 Hinrichtung, die letzten 10.000 Hinrichtung, und die letzten 1.000 Hinrichtung):
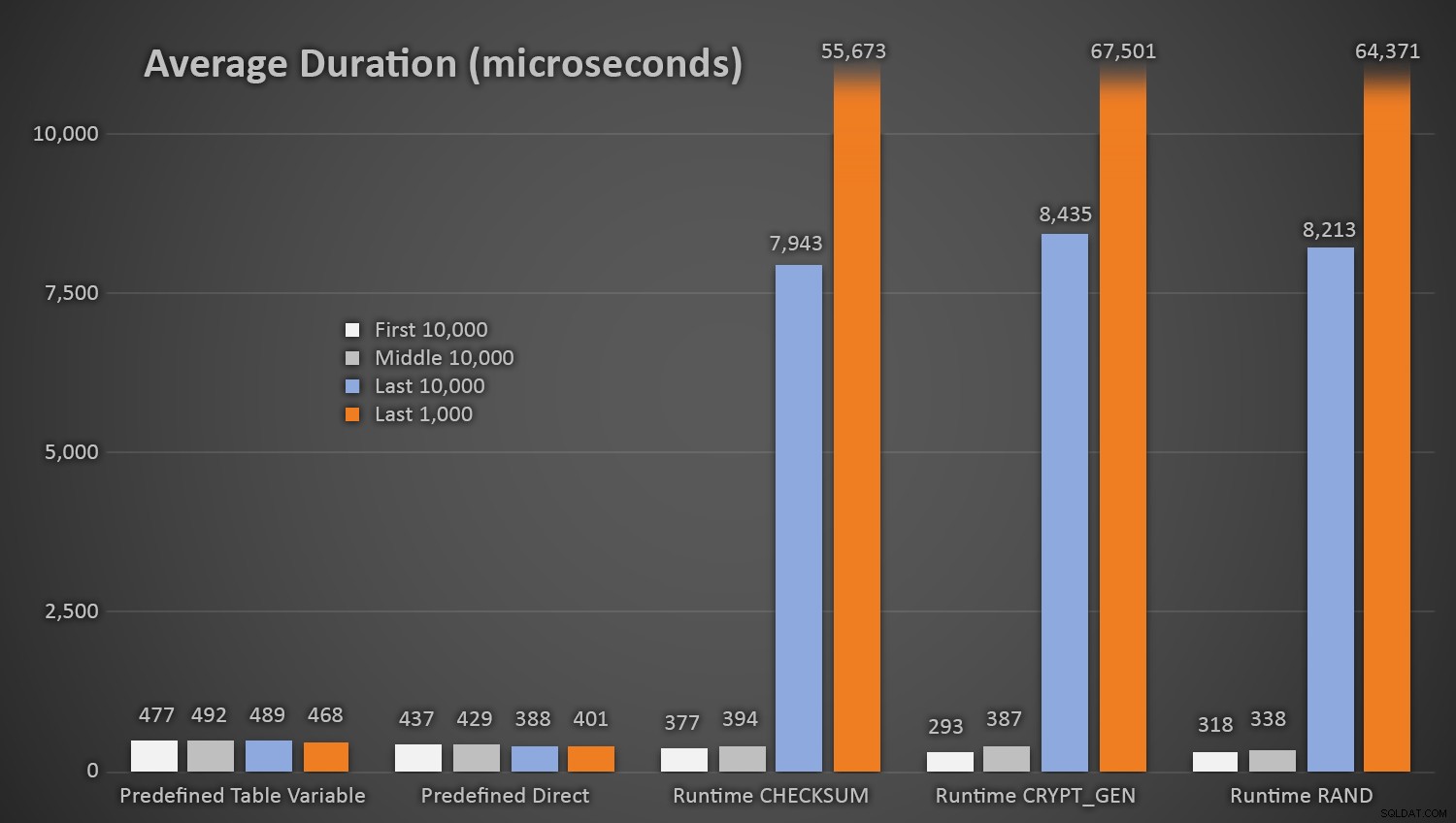
Durchschnittliche Dauer (in Mikrosekunden) von Zufallserzeugung unter Verwendung verschiedene Ansätze
Dies funktioniert gut für alle Methoden, wenn die Customers-Tabelle nur wenige Zeilen enthält, aber wenn die Tabelle immer größer wird, steigen die Kosten für die Überprüfung der neuen Zufallszahl gegen die vorhandenen Daten mithilfe der Laufzeitmethoden erheblich, sowohl wegen des erhöhten I / O und auch, weil die Anzahl der Kollisionen steigt (zwingt Sie, um zu versuchen, und versuchen Sie es erneut). Vergleichen Sie die durchschnittliche Dauer, wenn sie in den folgenden Bereichen Kollisionszahlen (und denken Sie daran, dass dieses Muster die Laufzeitverfahren betrifft nur):
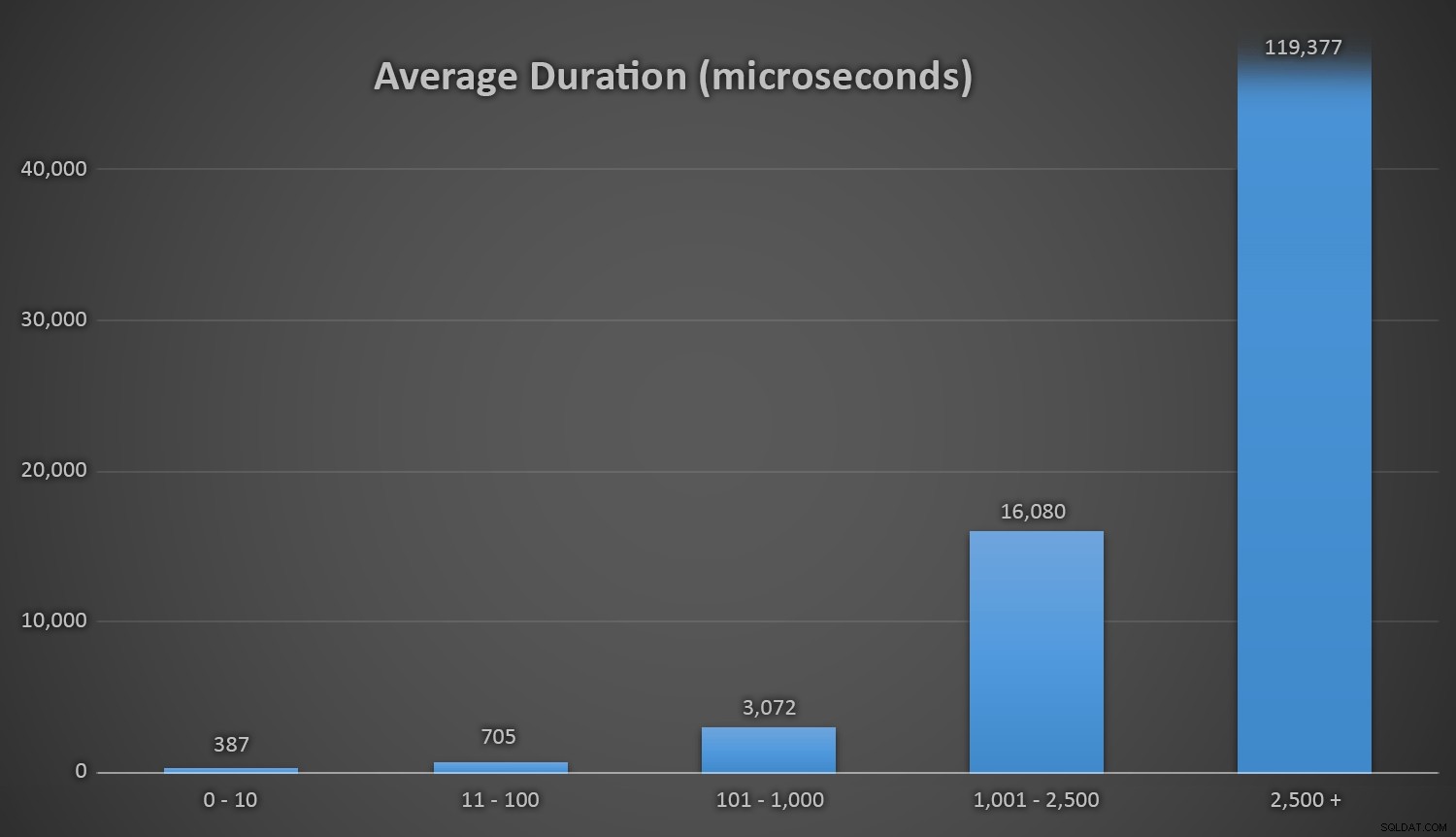
Durchschnittliche Dauer (in Mikrosekunden) während der verschiedenen Bereiche von Kollisionen
Ich wünsche es eine einfache Möglichkeit, die grafisch dargestellt Dauer gegen Kollision Zählungen waren. Ich werde Sie mit diesem Leckerbissen verlassen:auf den letzten drei Einsätzen, die folgenden Laufzeitverfahren so viele Versuche durchführen mussten, bevor sie schließlich auf die letzte eindeutige ID stolperte sie suchen, und das ist, wie lange es gedauert hat:
| Anzahl der Kollisionen | Dauer (Mikrosekunden) | ||
|---|---|---|---|
| CHECKSUM (NEWID ()) | 3. bis letzte Zeile | 63545 | 639.358 |
| 2. bis letzte Zeile | 164.807 | 1.605.695 | |
| Letzte Zeile | 30630 | 296.207 | |
| CRYPT_GEN_RANDOM () | 3. bis letzte Zeile | 219.766 | 2229166 |
| 2. bis letzte Zeile | 255.463 | 2681468 | |
| Letzte Zeile | 136.342 | 1434725 | |
| RAND() | Dritte bis letzte Reihe | 129.764 | 1.215.994 |
| 2. bis letzte Zeile | 220.195 | 2.088.992 | |
| Letzte Zeile | 440.765 | 4.161.925 | |
Übermäßige Dauer und Kollisionen in der Nähe des Endes der Zeile
Es ist interessant, dass die letzte Zeile ist nicht immer derjenige, der die höchste Zahl von Kollisionen ergibt, so dass diese beginnen können ein echtes Problem zu sein, lange bevor Sie 999,000+ Werte verbraucht haben.
Eine weitere Überlegung
Sie können die Einrichtung eine Art von Alarm oder eine Benachrichtigung zu prüfen, wenn die RandomNumbers Tabelle unten einem bestimmten Anzahl von Zeilen beginnt immer (an welchem Punkt können Sie die Tabelle mit einem neuen Satz von 1.000.001 neu bevölkern - 2.000.000, zum Beispiel). Sie müssten etwas ähnliches tun, wenn Sie auf die Schnelle Erzeugung von Zufallszahlen wurden - wenn Sie, dass innerhalb eines Bereichs von 1 halten - 1000000, dann würden Sie den Code ändern müssen, um Zahlen zu erzeugen, die von einem anderen Bereich, wenn Sie‘ Ich habe all diese Werte aufgebraucht.
Wenn Sie die Zufallszahl zur Laufzeit-Methode verwenden, dann können Sie diese Situation vermeiden, indem ständig die Poolgröße zu ändern, von dem Sie eine Zufallszahl ziehen (die auch stabilisieren sollte und drastisch die Zahl der Kollisionen reduzieren). Zum Beispiel statt:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Sie können den Pool auf der Anzahl der Zeilen in der Tabelle bereits stützen:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Jetzt ist Ihre einzige wirkliche Sorge ist, wenn Sie die obere Schranke für INT Ansatz …
. Hinweis:Ich schrieb vor kurzem auch einen Tipp über diesen bei MSSQLTips.com