Einzelne Prädikate
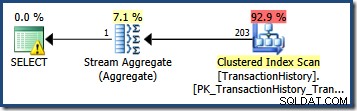
Das Schätzen der Anzahl der Zeilen, die durch ein einzelnes Abfrageprädikat qualifiziert werden, ist oft einfach. Wenn ein Prädikat einen einfachen Vergleich zwischen einer Spalte und einem Skalarwert durchführt, stehen die Chancen gut, dass der Kardinalitätsschätzer aus dem Statistikhistogramm eine gute Qualitätsschätzung ableiten können. Beispielsweise erzeugt die folgende AdventureWorks-Abfrage eine exakt korrekte Schätzung von 203 Zeilen (unter der Annahme, dass seit der Erstellung der Statistiken keine Änderungen an den Daten vorgenommen wurden):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
Betrachten Sie das Statistikhistogramm für das TransactionDate Spalte ist klar ersichtlich, woher diese Schätzung stammt:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
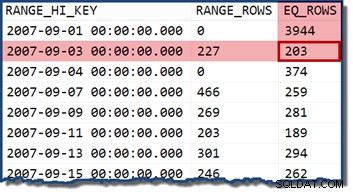
Wenn wir die Abfrage ändern, um ein Datum anzugeben, das in einen Histogramm-Bucket fällt, geht der Kardinalitätsschätzer davon aus, dass die Werte gleichmäßig verteilt sind. Unter Verwendung eines Datums von 2007-09-02 ergibt eine Schätzung von 227 Zeilen (aus RANGE_ROWS Eintrag). Als interessante Nebenbemerkung bleibt die Schätzung bei 227 Zeilen, unabhängig davon, ob wir einen Zeitabschnitt zum Datumswert hinzufügen (das TransactionDate). Spalte ist ein datetime Datentyp).
Wenn wir die Abfrage erneut mit dem Datum 2007-09-05 versuchen oder 2007-09-06 (beide fallen zwischen den 2007-09-04 und 2007-09-07 Histogrammschritte), nimmt der Kardinalitätsschätzer die 466 RANGE_ROWS an werden gleichmäßig auf die beiden Werte aufgeteilt, wobei in beiden Fällen 233 Zeilen geschätzt werden.
Es gibt viele andere Details zur Kardinalitätsschätzung für einfache Prädikate, aber das Vorstehende reicht als Auffrischung für unsere gegenwärtigen Zwecke.
Die Probleme multipler Prädikate
Wenn eine Abfrage mehr als ein Spaltenprädikat enthält, wird die Schätzung der Kardinalität schwieriger. Betrachten Sie die folgende Abfrage mit zwei einfachen Prädikaten (von denen jedes für sich leicht zu schätzen ist):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Die konkreten Wertebereiche in der Abfrage sind bewusst so gewählt, dass beide Prädikate genau dieselben Zeilen identifizieren. Wir könnten die Abfragewerte leicht ändern, um zu einer beliebigen Überlappung zu führen, einschließlich überhaupt keiner Überlappung. Stellen Sie sich nun vor, Sie wären der Kardinalitätsschätzer:Wie würden Sie eine Kardinalitätsschätzung für diese Abfrage ableiten?
Das Problem ist schwieriger, als es zunächst klingen mag. Standardmäßig erstellt SQL Server automatisch einspaltige Statistiken für beide Prädikatspalten. Wir können auch mehrspaltige Statistiken manuell erstellen. Gibt uns dies genügend Informationen, um eine gute Schätzung für diese spezifischen Werte zu erstellen? Was ist mit dem allgemeineren Fall, wo es alle geben könnte Grad der Überschneidung?
Unter Verwendung der beiden einspaltigen Statistikobjekte können wir leicht eine Schätzung für jedes Prädikat ableiten, indem wir die im vorherigen Abschnitt beschriebene Histogrammmethode verwenden. Für die spezifischen Werte in der obigen Abfrage zeigen die Histogramme, dass die TransactionID Der Bereich entspricht voraussichtlich 68412.4 Zeilen und das TransactionDate Der Bereich entspricht voraussichtlich 68.413 Reihen. (Wenn die Histogramme perfekt wären, wären diese beiden Zahlen genau gleich.)
Was die Histogramme nicht können Sagen Sie uns, wie viele dieser beiden Reihensätze die gleichen Reihen sein werden . Alles, was wir basierend auf den Histogramminformationen sagen können, ist, dass unsere Schätzung irgendwo zwischen null (für überhaupt keine Überlappung) und 68412,4 Zeilen (vollständige Überlappung) liegen sollte.
Das Erstellen von mehrspaltigen Statistiken bietet für diese Abfrage (oder für Bereichsabfragen im Allgemeinen) keine Hilfestellung. Mehrspaltige Statistiken erstellen immer noch nur ein Histogramm über der erstgenannten Spalte und duplizieren im Wesentlichen das Histogramm, das einer der automatisch erstellten Statistiken zugeordnet ist. Die zusätzliche Dichte Informationen, die von der mehrspaltigen Statistik bereitgestellt werden, können nützlich sein, um durchschnittliche Fallinformationen für Abfragen bereitzustellen, die mehrere Gleichheitsprädikate enthalten, aber sie helfen uns hier nicht weiter.
Um eine Schätzung mit einem hohen Maß an Zuverlässigkeit zu erstellen, benötigen wir SQL Server, um bessere Informationen über die Datenverteilung bereitzustellen – so etwas wie eine mehrdimensionale Statistik-Histogramm. Soweit ich weiß, bietet derzeit keine kommerzielle Datenbank-Engine eine solche Möglichkeit, obwohl mehrere technische Artikel zu diesem Thema veröffentlicht wurden (einschließlich eines von Microsoft Research, das eine interne Entwicklung von SQL Server 2000 verwendet).
Ohne etwas über Datenkorrelationen und -überschneidungen für bestimmte Wertebereiche zu wissen, ist nicht klar, wie wir vorgehen sollten, um eine gute Schätzung für unsere Abfrage zu erhalten. Also, was macht SQL Server hier?
SQL Server 7 – 2012
Der Kardinalitätsschätzer in diesen Versionen von SQL Server geht im Allgemeinen davon aus, dass Werte verschiedener Attribute in einer Tabelle völlig unabhängig voneinander verteilt werden. Diese Unabhängigkeitsannahme ist selten eine genaue Wiedergabe der realen Daten, aber es hat den Vorteil, dass es einfachere Berechnungen ermöglicht.
UND Selektivität
Unter Verwendung der Unabhängigkeitsannahme werden zwei Prädikate durch AND verbunden (bekannt als Konjunktion ) mit Selektivitäten S1 und S2 , ergeben eine kombinierte Selektivität von:
(S1 * S2)
Falls Ihnen der Begriff nicht geläufig ist, Selektivität ist eine Zahl zwischen 0 und 1, die den Anteil der Zeilen in der Tabelle darstellt, die das Prädikat passieren. Wenn beispielsweise ein Prädikat 12 Zeilen aus einer Tabelle mit 100 Zeilen auswählt, beträgt die Selektivität (12/100) =0,12.
In unserem Beispiel die TransactionHistory Tabelle enthält insgesamt 113.443 Zeilen. Das Prädikat für TransactionID wird (aus dem Histogramm) auf 68.412,4 Zeilen geschätzt, sodass die Selektivität (68.412,4 / 113.443) oder ungefähr 0,603055 beträgt . Das Prädikat für TransactionDate wird in ähnlicher Weise auf eine Selektivität von (68.413 / 113.443) =ungefähr 0,603061 geschätzt .
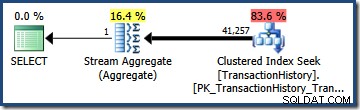
Die Multiplikation der beiden Selektivitäten (unter Verwendung der obigen Formel) ergibt eine kombinierte Selektivitätsschätzung von 0,363679 . Die Multiplikation dieser Selektivität mit der Kardinalität der Tabelle (113.443) ergibt die endgültige Schätzung von 41.256,8 Zeilen:
ODER-Selektivität
Zwei durch OR verbundene Prädikate (eine Disjunktion ) mit Selektivitäten S1 und S2 , ergibt eine kombinierte Selektivität von:
(S1 + S2) – (S1 * S2)
Die Intuition hinter der Formel besteht darin, die beiden Selektivitäten zu addieren und dann die Schätzung für ihre Verbindung (unter Verwendung der vorherigen Formel) zu subtrahieren. Natürlich könnten wir zwei Prädikate haben, jedes mit einer Selektivität von 0,8, aber ihre einfache Addition würde eine unmögliche kombinierte Selektivität von 1,6 ergeben. Trotz der Unabhängigkeitsannahme müssen wir erkennen, dass sich die beiden Prädikate möglicherweise überschneiden, daher wird die geschätzte Selektivität der Konjunktion abgezogen, um Doppelzählungen zu vermeiden.
Wir können unser laufendes Beispiel leicht ändern, um OR zu verwenden :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Einsetzen der Prädikatsselektivitäten in das OR Formel ergibt eine kombinierte Selektivität von:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Multipliziert mit der Anzahl der Zeilen in der Tabelle ergibt diese Selektivität die endgültige Kardinalitätsschätzung von 95.568,6 :
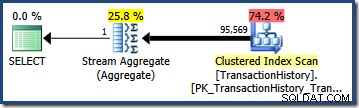
Keine Schätzung (41.257 für das AND Anfrage; 95.569 für das OR Abfrage) ist besonders gut, da beide auf einer Modellierungsannahme basieren, die nicht sehr gut mit der Datenverteilung übereinstimmt. Beide Abfragen geben tatsächlich 68.413 zurück Zeilen (weil die Prädikate genau dieselben Zeilen identifizieren).
Trace-Flag 4137 – Minimale Selektivität
Für SQL Server 2008 (R1) bis einschließlich 2012 hat Microsoft einen Fix veröffentlicht, der die Art und Weise ändert, wie die Selektivität für AND berechnet wird nur Kasus (konjunktive Prädikate). Der Knowledge Base-Artikel in diesem Link enthält nicht viele Details, aber es stellt sich heraus, dass der Fix die verwendete Selektivitätsformel ändert. Anstatt die einzelnen Selektivitäten zu multiplizieren, verwendet die Kardinalitätsschätzung für konjunktive Prädikate jetzt nur die niedrigste Selektivität.
Um das geänderte Verhalten zu aktivieren, ist das unterstützte Ablaufverfolgungsflag 4137 erforderlich. Ein separater Knowledge Base-Artikel dokumentiert, dass dieses Trace-Flag auch für die Verwendung pro Abfrage über QUERYTRACEON unterstützt wird Hinweis:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Wenn dieses Flag aktiviert ist, verwendet die Kardinalitätsschätzung die minimale Selektivität der beiden Prädikate, was zu einer Schätzung von 68.412,4 führt Zeilen:
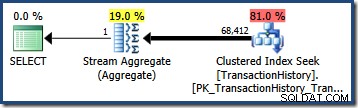
Dies ist geradezu perfekt für unsere Abfrage, da unsere Testprädikate genau korrelieren (und die aus den Basishistogrammen abgeleiteten Schätzungen auch sehr gut sind).
Es ist ziemlich selten, dass Prädikate so perfekt mit realen Daten korrelieren, aber das Trace-Flag kann in einigen Fällen dennoch hilfreich sein. Beachten Sie, dass das minimale Selektivitätsverhalten für alle Konjunktionen gilt (AND ) Prädikate in der Abfrage; Es gibt keine Möglichkeit, das Verhalten detaillierter zu spezifizieren.
Es gibt kein entsprechendes Trace-Flag, um disjunktiv zu schätzen (OR ) Prädikate mit minimaler Selektivität.
SQL-Server 2014
Die Selektivitätsberechnung in SQL Server 2014 verhält sich genauso wie frühere Versionen (und das Ablaufverfolgungsflag 4137 funktioniert wie zuvor), wenn der Datenbankkompatibilitätsgrad auf einen niedrigeren Wert als 120 festgelegt ist oder wenn das Ablaufverfolgungsflag 9481 ist ist aktiv. Das Festlegen des Datenbank-Kompatibilitätsgrads ist offiziell Möglichkeit, den Kardinalitätsschätzer vor 2014 in SQL Server 2014 zu verwenden. Das Ablaufverfolgungsflag 9481 bewirkt dasselbe wie zum Zeitpunkt des Schreibens und funktioniert auch mit QUERYTRACEON , obwohl dies nicht dokumentiert ist. Es gibt keine Möglichkeit zu wissen, wie das RTM-Verhalten dieses Flags sein wird.
Wenn der neue Kardinalitätsschätzer aktiv ist, verwendet SQL Server 2014 eine andere Standardformel zum Kombinieren von konjunktiven und disjunktiven Prädikaten. Obwohl undokumentiert, wurde die Selektivitätsformel für Konjunktionen jetzt mehrere Male entdeckt und dokumentiert. Der erste, an den ich mich erinnere, war in diesem portugiesischen Blogbeitrag und der zweite Teil, der ein paar Wochen später veröffentlicht wurde. Zusammenfassend lässt sich sagen, dass der Ansatz von 2014 für konjunktive Prädikate die Verwendung von exponentiellem Backoff: ist Gegeben sei eine Tabelle mit Kardinalität C und Prädikatenselektivitäten S1 , S2 , S3 … Sn , wobei S1 ist am selektivsten und Sn das mindeste:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
Die Schätzung wird aus dem selektivsten Prädikat multipliziert mit der Tabellenkardinalität, multipliziert mit der Quadratwurzel des nächstselektivsten Prädikats usw. berechnet, wobei jede neue Selektivität eine zusätzliche Quadratwurzel erhält.
Wenn man sich daran erinnert, dass Selektivität eine Zahl zwischen 0 und 1 ist, ist es klar, dass die Anwendung einer Quadratwurzel die Zahl näher an 1 verschiebt. Der Effekt besteht darin, alle Prädikate in der endgültigen Schätzung zu berücksichtigen, aber den Einfluss der weniger selektiven Prädikate zu verringern exponentiell. Diese Idee ist wohl logischer als unter der Unabhängigkeitsannahme , aber es ist immer noch eine feste Formel – sie ändert sich nicht basierend auf dem tatsächlichen Grad der Datenkorrelation.
Der Kardinalitätsschätzer von 2014 verwendet eine exponentielle Backoff-Formel für beide Konjunktiv- und Disjunktivprädikate, obwohl die im Disjunktiv verwendete Formel (OR ) Fall wurde noch nicht dokumentiert (offiziell oder anderweitig).
SQL Server 2014-Selektivitätstrace-Flags
Ablaufverfolgungsflag 4137 (zur Verwendung der Mindestselektivität) nicht funktionieren in SQL Server 2014, wenn der neue Kardinalitätsschätzer beim Kompilieren einer Abfrage verwendet wird. Stattdessen gibt es ein neues Trace-Flag 9471 . Wenn dieses Flag aktiv ist, wird die minimale Selektivität verwendet, um mehrere konjunktive und disjunktive zu schätzen Prädikate. Dies ist eine Änderung gegenüber dem 4137-Verhalten, das nur konjunktive Prädikate betraf.
Ebenso Trace-Flag 9472 kann spezifiziert werden, um Unabhängigkeit anzunehmen für mehrere Prädikate, wie es frühere Versionen taten. Dieses Flag unterscheidet sich von 9481 (um den Kardinalitätsschätzer von vor 2014 zu verwenden), da unter 9472 weiterhin der neue Kardinalitätsschätzer verwendet wird, nur die Selektivitätsformel für mehrere Prädikate ist betroffen.
Weder 9471 noch 9472 sind zum Zeitpunkt des Schreibens dokumentiert (obwohl sie sich möglicherweise bei RTM befinden).
Eine praktische Methode, um zu sehen, welche Selektivitätsannahme in SQL Server 2014 (mit aktivem neuen Kardinalitätsschätzer) verwendet wird, besteht darin, die Debugausgabe der Selektivitätsberechnung zu untersuchen, die erzeugt wird, wenn die Ablaufverfolgungsflags 2363 anzeigen und 3604 aktiv sind. Der zu suchende Abschnitt bezieht sich auf den Selektivitätsrechner, der Filter kombiniert, wo Sie je nach verwendeter Annahme eines der folgenden sehen:
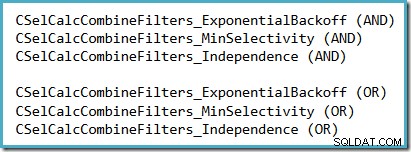
Es besteht keine realistische Aussicht, dass 2363 dokumentiert oder unterstützt wird.
Abschließende Gedanken
Es gibt nichts Magisches an exponentiellem Backoff, minimaler Selektivität oder Unabhängigkeit. Jeder Ansatz stellt eine (sehr) vereinfachende Annahme dar, die zu akzeptablen Schätzungen für eine bestimmte Abfrage oder Datenverteilung führen kann oder nicht.
In mancher Hinsicht exponentieller Backoff stellt einen Kompromiss zwischen den beiden Extremen der Unabhängigkeit dar und minimale Selektivität . Trotzdem ist es wichtig, keine unangemessenen Erwartungen daran zu haben. Bis ein genauerer Weg gefunden wird, um die Selektivität für mehrere Prädikate (mit angemessenen Leistungsmerkmalen) zu schätzen, bleibt es wichtig, sich der Modellbeschränkungen bewusst zu sein und entsprechend auf (potenzielle) Schätzfehler zu achten.
Die verschiedenen Trace-Flags bieten eine gewisse Kontrolle darüber, welche Annahme verwendet wird, aber die Situation ist alles andere als perfekt. Zum einen ist die feinste Granularität, bei der ein Flag angewendet werden kann, eine einzelne Abfrage – das Schätzverhalten kann nicht auf Prädikatebene angegeben werden. Wenn Sie eine Abfrage haben, bei der einige Prädikate korreliert und andere unabhängig sind, helfen Ihnen die Ablaufverfolgungsflags möglicherweise nicht viel, ohne die Abfrage auf die eine oder andere Weise umzugestalten. Ebenso kann eine problematische Abfrage Prädikatkorrelationen aufweisen, die von keiner der verfügbaren Optionen gut modelliert werden.
Die Ad-hoc-Nutzung der Ablaufverfolgungsflags erfordert dieselben Berechtigungen wie DBCC TRACEON – nämlich sysadmin . Für persönliche Tests ist das wahrscheinlich in Ordnung, aber für die Produktion verwenden Sie eine Plananleitung mit QUERYTRACEON Hinweis ist eine bessere Option. Bei einer Planhinweisliste sind keine zusätzlichen Berechtigungen zum Ausführen der Abfrage erforderlich (obwohl zum Erstellen der Planhinweisliste natürlich erhöhte Berechtigungen erforderlich sind).