Viel Produktions-T-SQL-Code wird mit der impliziten Annahme geschrieben, dass sich die zugrunde liegenden Daten während der Ausführung nicht ändern. Wie wir im vorherigen Artikel dieser Serie gesehen haben, ist dies eine unsichere Annahme, da sich Daten und Indexeinträge unter uns bewegen können, sogar während der Ausführung einer einzelnen Anweisung.
Wenn sich der T-SQL-Programmierer der Art von Korrektheits- und Datenintegritätsproblemen bewusst ist, die aufgrund gleichzeitiger Datenänderungen durch andere Prozesse auftreten können, besteht die am häufigsten angebotene Lösung darin, die anfälligen Anweisungen in eine Transaktion einzuschließen. Es ist nicht klar, wie die gleiche Art von Argumentation auf den Fall einer einzelnen Anweisung angewendet werden würde, der standardmäßig bereits in eine Auto-Commit-Transaktion eingeschlossen ist.
Abgesehen davon scheint die Idee, einen wichtigen Bereich des T-SQL-Codes mit einer Transaktion zu schützen, auf einem Missverständnis des Schutzes zu beruhen, den die ACID-Transaktionseigenschaften bieten. Das wichtige Element dieses Akronyms für die vorliegende Diskussion ist die Isolation Eigentum. Die Idee ist, dass die Verwendung einer Transaktion automatisch eine vollständige Isolierung von den Auswirkungen anderer gleichzeitiger Aktivitäten bietet.
Die Wahrheit ist, dass Transaktionen unter SERIALIZABLE nur einen Abschluss erbringen der Isolation, die von der aktuell wirksamen Transaktionsisolationsstufe abhängt. Um zu verstehen, was das alles für unseren Alltag bedeutet, T SQL-Codierungspraktiken werfen wir zunächst einen detaillierten Blick auf die serialisierbare Isolationsstufe.
Serialisierbare Isolierung
Serializable ist die isolierteste der standardmäßigen Transaktionsisolationsstufen. Es ist auch die Standardeinstellung vom SQL-Standard vorgegebene Isolationsstufe, obwohl SQL Server (wie die meisten kommerziellen Datenbanksysteme) in dieser Hinsicht vom Standard abweicht. Die Standard-Isolationsstufe in SQL Server ist Read Committed, eine niedrigere Isolationsstufe, die wir später in der Serie untersuchen werden.
Die Definition der serialisierbaren Isolationsstufe im SQL-92-Standard enthält den folgenden Text (Hervorhebung von mir):
Eine serialisierbare Ausführung ist definiert als eine Ausführung der Operationen gleichzeitig ausgeführter SQL-Transaktionen, die denselben Effekt wie eine serielle Ausführung erzeugt dieser gleichen SQL-Transaktionen. Bei einer seriellen Ausführung wird jede SQL-Transaktion vollständig ausgeführt, bevor die nächste SQL-Transaktion beginnt.
Hier muss eine wichtige Unterscheidung zwischen echten serialisierten getroffen werden Ausführung (wobei jede Transaktion tatsächlich ausschließlich bis zum Ende ausgeführt wird, bevor die nächste beginnt) und serialisierbar Isolation, bei der Transaktionen nur als ob dieselben Wirkungen haben müssen sie wurden seriell ausgeführt (in einer nicht spezifizierten Reihenfolge).
Anders ausgedrückt:Ein reales Datenbanksystem darf sich physikalisch überschneiden die zeitliche Ausführung serialisierbarer Transaktionen (wodurch die Parallelität erhöht wird), solange die Auswirkungen dieser Transaktionen noch einer möglichen Reihenfolge der seriellen Ausführung entsprechen. Mit anderen Worten, serialisierbare Transaktionen sind potenziell serialisierbar anstatt tatsächlich serialisiert zu werden .
Logisch serialisierbare Transaktionen
Lassen Sie alle physikalischen Überlegungen (wie das Sperren) für einen Moment beiseite und denken Sie nur an die logische Verarbeitung von zwei gleichzeitigen serialisierbaren Transaktionen.
Stellen Sie sich eine Tabelle vor, die eine große Anzahl von Zeilen enthält, von denen fünf zufällig ein interessantes Abfrageprädikat erfüllen. Eine serialisierbare Transaktion T1 beginnt mit dem Zählen der Zeilen in der Tabelle, die mit diesem Prädikat übereinstimmen. Einige Zeit nach T1 beginnt, aber bevor es festgeschrieben wird, eine zweite serialisierbare Transaktion T2 beginnt. Transaktion T2 fügt der Tabelle vier neue Zeilen hinzu, die auch das Abfrageprädikat erfüllen, und schreibt fest. Das folgende Diagramm zeigt die zeitliche Abfolge der Ereignisse:

Die Frage ist, wie viele Zeilen soll die Abfrage in der serialisierbaren Transaktion T1 durchführen zählen? Denken Sie daran, dass wir hier nur an die logischen Anforderungen denken, denken Sie also nicht darüber nach, welche Sperren verwendet werden könnten und so weiter.
Die beiden Transaktionen überschneiden sich physisch zeitlich, was in Ordnung ist. Die serialisierbare Isolierung erfordert lediglich, dass die Ergebnisse dieser beiden Transaktionen einer möglichen seriellen Ausführung entsprechen. Es gibt offensichtlich zwei Möglichkeiten für einen logischen seriellen Zeitplan von Transaktionen T1 und T2 :
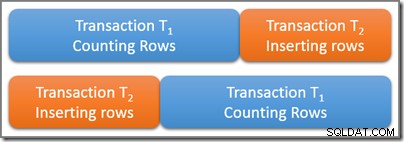
Unter Verwendung des ersten möglichen seriellen Zeitplans (T1 dann T2 ) die T1 Zählabfrage würde fünf Zeilen sehen , da die zweite Transaktion erst gestartet wird, wenn die erste abgeschlossen ist. Unter Verwendung des zweiten möglichen logischen Zeitplans, des T1 Abfrage würde neun Zeilen zählen , da die vierzeilige Einfügung logisch abgeschlossen wurde, bevor die Zähltransaktion begann.
Beide Antworten sind unter serialisierbarer Isolation logisch korrekt. Außerdem ist keine andere Antwort möglich (also Transaktion T1 konnte zum Beispiel nicht sieben Reihen zählen). Welches der beiden möglichen Ergebnisse tatsächlich beobachtet wird, hängt vom genauen Timing und einer Reihe von Implementierungsdetails ab, die für die verwendete Datenbank-Engine spezifisch sind.
Beachten Sie, dass wir nicht schlussfolgern, dass die Transaktionen tatsächlich irgendwie zeitlich neu geordnet werden. Die physische Ausführung kann sich, wie im ersten Diagramm gezeigt, frei überschneiden, solange die Datenbank-Engine sicherstellt, dass die Ergebnisse widerspiegeln, was passiert wäre, wenn sie in einer der beiden möglichen seriellen Sequenzen ausgeführt worden wären.
Serialisierbar und das Nebenläufigkeitsphänomen
Zusätzlich zur logischen Serialisierung erwähnt der SQL-Standard auch, dass eine Transaktion, die auf der serialisierbaren Isolationsebene ausgeführt wird, bestimmte Nebenläufigkeitsphänomene nicht erfahren darf. Es darf keine nicht festgeschriebenen Daten lesen (keine dirty reads ); und sobald Daten gelesen wurden, muss eine Wiederholung derselben Operation genau denselben Datensatz zurückgeben (wiederholbare Lesevorgänge ohne Phantome ).
Der Standard betont ausdrücklich, dass diese Nebenläufigkeitsphänomene auf der serialisierbaren Isolationsebene als direkte Folge ausgeschlossen sind zu verlangen, dass die Transaktion logisch serialisierbar ist. Mit anderen Worten, die Serialisierbarkeitsanforderung ist allein ausreichend um Dirty Read, Non-Repeatable Read und Phantom-Parallelitätsphänomene zu vermeiden. Dagegen reicht die Vermeidung der drei Nebenläufigkeitsphänomene allein nicht aus um die Serialisierbarkeit zu gewährleisten, wie wir in Kürze sehen werden.
Intuitiv vermeiden serialisierbare Transaktionen alle Parallelitätsphänomene, da sie sich so verhalten müssen, als ob sie vollständig isoliert ausgeführt worden wären. In diesem Sinne entspricht die Isolationsstufe für serialisierbare Transaktionen ziemlich genau den allgemeinen Erwartungen von T-SQL-Programmierern.
Serialisierbare Implementierungen
SQL Server verwendet zufällig eine Sperrimplementierung der serialisierbaren Isolationsstufe, bei der physische Sperren erworben und gehalten werden bis zum Ende der Transaktion (daher der veraltete Tabellenhinweis HOLDLOCK als Synonym für SERIALIZABLE ).
Diese Strategie reicht nicht aus, um eine technische Garantie für vollständige Serialisierbarkeit zu bieten, da neue oder geänderte Daten in einer Reihe von Zeilen erscheinen können, die zuvor von der Transaktion verarbeitet wurden. Dieses Nebenläufigkeitsphänomen wird als Phantom bezeichnet und kann zu Effekten führen, die in keinem Serienplan hätten auftreten können.
Um Schutz vor dem Phantom-Parallelitätsphänomen zu gewährleisten, können Sperren, die von SQL Server auf der serialisierbaren Isolationsebene vorgenommen werden, auch Schlüsselbereichssperren enthalten um zu verhindern, dass neue oder geänderte Zeilen zwischen zuvor untersuchten Indexschlüsselwerten erscheinen. Bereichssperren sind nicht immer erworben unter der serialisierbaren Isolationsstufe; Alles, was wir allgemein sagen können, ist, dass SQL Server immer genügend Sperren erwirbt, um die logischen Anforderungen der serialisierbaren Isolationsstufe zu erfüllen. Tatsächlich erwerben Sperrimplementierungen oft mehr und strengere Sperren, als wirklich nötig sind, um die Serialisierbarkeit zu garantieren, aber ich schweife ab.
Das Sperren ist nur eine der möglichen physischen Implementierungen der serialisierbaren Isolationsstufe. Wir sollten darauf achten, das spezifische Verhalten der SQL Server-Sperrimplementierung gedanklich von der logischen Definition von serialisierbar zu trennen.
Als Beispiel für eine alternative physische Strategie siehe die PostgreSQL-Implementierung der serialisierbaren Snapshot-Isolation, obwohl dies nur eine Alternative ist. Jede unterschiedliche physikalische Implementierung hat natürlich ihre eigenen Stärken und Schwächen. Beachten Sie nebenbei, dass Oracle immer noch keine vollständig konforme Implementierung der serialisierbaren Isolationsstufe bereitstellt. Es hat eine Isolationsstufe benannt serialisierbar, aber es garantiert nicht wirklich, dass Transaktionen gemäß einem möglichen seriellen Zeitplan ausgeführt werden. Oracle bietet stattdessen Snapshot-Isolierung wenn serialisierbar angefordert wird, ähnlich wie PostgreSQL es vor der Isolation von serialisierbaren Snapshots tat (SSI ) wurde implementiert.
Die Snapshot-Isolation verhindert keine Nebenläufigkeitsanomalien wie Write Skew, was bei einer wirklich serialisierbaren Isolation nicht möglich ist. Wenn Sie interessiert sind, finden Sie unter dem obigen SSI-Link Beispiele für Schreibversatz und andere Parallelitätseffekte, die durch die Snapshot-Isolation zugelassen werden. Wir werden auch die SQL Server-Implementierung der Snapshot-Isolationsstufe später in der Serie besprechen.
Eine Point-in-Time-Ansicht?
Ein Grund, warum ich Zeit damit verbracht habe, über die Unterschiede zwischen logischer Serialisierbarkeit und physisch serialisierter Ausführung zu sprechen, ist, dass es ansonsten leicht ist, auf Garantien zu schließen, die möglicherweise gar nicht existieren. Zum Beispiel, wenn Sie an serialisierbare Transaktionen eigentlich denken Wenn Sie eine nach der anderen ausführen, könnten Sie schlussfolgern, dass eine serialisierbare Transaktion die Datenbank notwendigerweise so sieht, wie sie zu Beginn der Transaktion existierte, was eine Point-in-Time-Ansicht bietet.
Tatsächlich handelt es sich hierbei um ein implementierungsspezifisches Detail. Erinnern Sie sich an das vorherige Beispiel, in dem die serialisierbare Transaktion T1 könnte berechtigterweise fünf oder neun Zeilen zählen. Wenn eine Zählung von neun zurückgegeben wird, sieht die erste Transaktion eindeutig Zeilen, die zu dem Zeitpunkt, als die Transaktion gestartet wurde, nicht vorhanden waren. Dieses Ergebnis ist in SQL Server möglich, aber nicht in PostgreSQL SSI, obwohl beide Implementierungen den logischen Verhaltensweisen entsprechen, die für die serialisierbare Isolationsstufe angegeben sind.
In SQL Server sehen serialisierbare Transaktionen die Daten nicht unbedingt so, wie sie zu Beginn der Transaktion vorhanden waren. Vielmehr bedeuten die Details der SQL Server-Implementierung, dass eine serialisierbare Transaktion die zuletzt festgeschriebenen Daten ab dem Zeitpunkt sieht, an dem die Daten zum ersten Mal für den Zugriff gesperrt wurden. Außerdem wird garantiert, dass der Satz der letzten festgeschriebenen Daten, der zuletzt gelesen wird, seine Mitgliedschaft nicht ändert, bevor die Transaktion endet.
Nächstes Mal
Der nächste Teil dieser Serie untersucht die wiederholbare Leseisolationsebene, die schwächere Garantien für die Transaktionsisolation bietet als serialisierbar.
[Siehe den Index für die gesamte Serie]