Einführung
Dieses Tutorial enthält Informationen über SQL (DDL, DML), die ich während meines Berufslebens gesammelt habe. Dies ist das Minimum, das Sie wissen müssen, wenn Sie mit Datenbanken arbeiten. Wenn es notwendig ist, komplexe SQL-Konstruktionen zu verwenden, dann surfe ich normalerweise in der MSDN-Bibliothek, die leicht im Internet zu finden ist. Meiner Meinung nach ist es sehr schwierig, alles im Kopf zu behalten, und das ist übrigens auch nicht nötig. Ich empfehle, dass Sie alle Hauptkonstruktionen kennen sollten, die in den meisten relationalen Datenbanken wie Oracle, MySQL und Firebird verwendet werden. Dennoch können sie sich in den Datentypen unterscheiden. Um beispielsweise Objekte (Tabellen, Einschränkungen, Indizes usw.) zu erstellen, können Sie einfach die integrierte Entwicklungsumgebung (IDE) verwenden, um mit Datenbanken zu arbeiten, und es besteht keine Notwendigkeit, visuelle Tools für einen bestimmten Datenbanktyp (MS SQL, Oracle , MySQL, Firebird usw.). Dies ist praktisch, da Sie den gesamten Text sehen können und nicht durch zahlreiche Registerkarten blättern müssen, um beispielsweise einen Index oder eine Einschränkung zu erstellen. Wenn Sie ständig mit Datenbanken arbeiten, ist das Erstellen, Ändern und insbesondere der Neuaufbau eines Objekts mithilfe von Skripten viel schneller als im visuellen Modus. Außerdem ist es meiner Meinung nach im Skriptmodus (mit der gebotenen Genauigkeit) einfacher, Regeln für die Benennung von Objekten festzulegen und zu kontrollieren. Darüber hinaus ist es praktisch, Skripts zu verwenden, wenn Sie Datenbankänderungen von einer Testdatenbank in eine Produktionsdatenbank übertragen müssen.
SQL ist in mehrere Teile gegliedert. In meinem Artikel gehe ich auf die wichtigsten ein:
DDL – Datendefinitionssprache
DML – Data Manipulation Language, die die folgenden Konstruktionen umfasst:
- SELECT – Datenauswahl
- INSERT – Einfügen neuer Daten
- UPDATE – Datenaktualisierung
- DELETE – Datenlöschung
- MERGE – Datenzusammenführung
Ich werde alle Konstruktionen in Studienfällen erklären. Außerdem denke ich, dass eine Programmiersprache, insbesondere SQL, zum besseren Verständnis in der Praxis studiert werden sollte.
Dies ist ein Schritt-für-Schritt-Tutorial, in dem Sie beim Lesen Beispiele ausführen müssen. Wenn Sie den Befehl jedoch im Detail kennen müssen, dann surfen Sie im Internet, z. B. MSDN.
Beim Erstellen dieses Tutorials habe ich die MS SQL Server-Datenbank, Version 2014, und MS SQL Server Management Studio (SSMS) zum Ausführen von Skripten verwendet.
Kurz über MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) ist das Microsoft SQL Server-Dienstprogramm zum Konfigurieren, Verwalten und Verwalten von Datenbankkomponenten. Es enthält einen Skripteditor und ein Grafikprogramm, das mit Serverobjekten und -einstellungen arbeitet. Das Haupttool von SQL Server Management Studio ist der Objekt-Explorer, mit dem ein Benutzer Serverobjekte anzeigen, abrufen und verwalten kann. Dieser Text ist teilweise Wikipedia entnommen.
Um einen neuen Skript-Editor zu erstellen, verwenden Sie die Schaltfläche Neue Abfrage:
Um von der aktuellen Datenbank zu wechseln, können Sie das Dropdown-Menü verwenden:
Um einen bestimmten Befehl oder Befehlssatz auszuführen, markieren Sie ihn und drücken Sie die Schaltfläche „Ausführen“ oder F5. Wenn es nur einen Befehl im Editor gibt oder Sie alle Befehle ausführen müssen, markieren Sie nichts.
Nachdem Sie Skripts ausgeführt haben, die Objekte (Tabellen, Spalten, Indizes) erstellen, wählen Sie das entsprechende Objekt aus (z. B. Tabellen oder Spalten) und klicken Sie dann im Kontextmenü auf Aktualisieren, um die Änderungen anzuzeigen.
Eigentlich ist dies alles, was Sie wissen müssen, um die hier bereitgestellten Beispiele auszuführen.
Theorie
Eine relationale Datenbank ist eine Reihe von Tabellen, die miteinander verknüpft sind. Im Allgemeinen ist eine Datenbank eine Datei, die strukturierte Daten speichert.
Das Datenbankverwaltungssystem (DBMS) ist eine Reihe von Tools, um mit bestimmten Datenbanktypen (MS SQL, Oracle, MySQL, Firebird usw.) zu arbeiten.
Hinweis: Da wir in unserem täglichen Leben „Oracle DB“ oder einfach „Oracle“ sagen, was eigentlich „Oracle DBMS“ bedeutet, werde ich in diesem Tutorial den Begriff „Datenbank“ verwenden.
Eine Tabelle ist eine Reihe von Spalten. Sehr oft hört man die folgenden Definitionen dieser Begriffe:Felder, Zeilen und Datensätze, was dasselbe bedeutet.
Eine Tabelle ist das Hauptobjekt der relationalen Datenbank. Alle Daten werden zeilenweise in Tabellenspalten gespeichert.
Für jede Tabelle sowie für ihre Spalten müssen Sie einen Namen angeben, unter dem Sie ein gewünschtes Element finden können.
Der Name des Objekts, der Tabelle, der Spalte und des Indexes darf die Mindestlänge – 128 Zeichen haben.
Hinweis: In Oracle-Datenbanken darf ein Objektname mindestens 30 Zeichen lang sein. Daher ist es in einer bestimmten Datenbank erforderlich, benutzerdefinierte Regeln für Objektnamen zu erstellen.
SQL ist eine Sprache, die es ermöglicht, Abfragen in Datenbanken über DBMS auszuführen. In einem bestimmten DBMS kann eine SQL-Sprache ihren eigenen Dialekt haben.
DDL und DML – die SQL-Untersprache:
- Die Sprache DDL dient zum Erstellen und Ändern einer Datenbankstruktur (Löschen von Tabellen und Verknüpfungen);
- Die DML-Sprache erlaubt die Manipulation von Tabellendaten und deren Zeilen. Es dient auch dazu, Daten aus Tabellen auszuwählen, neue Daten hinzuzufügen sowie aktuelle Daten zu aktualisieren und zu löschen.
Es ist möglich, zwei Arten von Kommentaren in SQL zu verwenden (einzeilig und getrennt):
-- single-line comment
und
/* delimited comment */
Soweit die Theorie.
DDL – Datendefinitionssprache
Betrachten wir eine Beispieltabelle mit Daten über Mitarbeiter, die auf eine Weise dargestellt werden, die einer Person, die kein Programmierer ist, vertraut ist.
| Mitarbeiter-ID | Vollständiger Name | Geburtsdatum | Position | Abteilung | |
| 1000 | Johannes | 19.02.1955 | beispiel@sqldat.com | Geschäftsführer | Verwaltung |
| 1001 | Daniel | 03.12.1983 | beispiel@sqldat.com | Programmierer | IT |
| 1002 | Mike | 07.06.1976 | beispiel@sqldat.com | Buchhalter | Buchhaltung |
| 1003 | Jordanien | 17.04.1982 | beispiel@sqldat.com | Leitender Programmierer | IT |
In diesem Fall haben die Spalten die folgenden Titel:Mitarbeiter-ID, vollständiger Name, Geburtsdatum, E-Mail, Position und Abteilung.
Wir können jede Spalte dieser Tabelle durch ihren Datentyp beschreiben:
- Mitarbeiter-ID – Ganzzahl
- Vollständiger Name – Zeichenfolge
- Geburtsdatum – Datum
- E-Mail – Zeichenkette
- Position – Zeichenkette
- Abteilung – Zeichenkette
Ein Spaltentyp ist eine Eigenschaft, die angibt, welchen Datentyp jede Spalte speichern kann.
Zunächst müssen Sie sich die wichtigsten Datentypen merken, die in MS SQL verwendet werden:
| Definition | Bezeichnung in MS-SQL | Beschreibung |
| String variabler Länge | varchar(N) und nvarchar(N) | Mit der N-Zahl können wir die maximal mögliche Zeichenfolgenlänge für eine bestimmte Spalte angeben. Wenn wir zum Beispiel sagen wollen, dass der Wert der Spalte Vollständiger Name (höchstens) 30 Symbole enthalten kann, dann ist es notwendig, den Typ von nvarchar(30) anzugeben.
Der Unterschied zwischen varchar und nvarchar besteht darin, dass varchar das Speichern von Zeichenfolgen im ASCII-Format ermöglicht, während nvarchar Zeichenfolgen im Unicode-Format speichert, wobei jedes Symbol 2 Bytes benötigt. |
| String mit fester Länge | char(N) und nchar(N) | Dieser Typ unterscheidet sich von der Zeichenfolge mit variabler Länge in folgendem:Wenn die Zeichenfolgenlänge kleiner als N Symbole ist, werden immer Leerzeichen zu der Länge N rechts hinzugefügt. Somit werden in einer Datenbank genau N Symbole benötigt, wobei ein Symbol 1 Byte für char und 2 Bytes für nchar benötigt. In meiner Praxis wird dieser Typ nicht viel verwendet. Dennoch, wenn jemand es verwendet, dann hat dieser Typ normalerweise das char(1)-Format, d.h. wenn ein Feld durch 1 Symbol definiert wird. |
| Ganzzahl | int | Dieser Typ ermöglicht es uns, nur Ganzzahlen (sowohl positiv als auch negativ) in einer Spalte zu verwenden. Hinweis:Ein Nummernbereich für diesen Typ ist wie folgt:von 2 147 483 648 bis 2 147 483 647. Normalerweise ist dies der Haupttyp, der verwendet wird, um Identifikatoren zu erhalten. |
| Gleitkommazahl | schweben | Zahlen mit Dezimalpunkt. |
| Datum | Datum | Es wird verwendet, um nur ein Datum (Datum, Monat und Jahr) in einer Spalte zu speichern. Beispiel:15.02.2014. Dieser Typ kann für die folgenden Spalten verwendet werden:Eingangsdatum, Geburtsdatum usw., wenn Sie nur ein Datum angeben müssen oder wenn die Zeit für uns nicht wichtig ist und wir sie weglassen können. |
| Zeit | Zeit | Sie können diesen Typ verwenden, wenn Zeit gespeichert werden muss:Stunden, Minuten, Sekunden und Millisekunden. Beispiel:Sie haben 17:38:31.3231603 oder Sie müssen die Abflugzeit hinzufügen. |
| Datum und Uhrzeit | DatumUhrzeit | Dieser Typ ermöglicht Benutzern das Speichern von Datum und Uhrzeit. Beispiel:Sie haben das Ereignis am 15.02.2014 17:38:31.323. |
| Indikator | Bit | Sie können diesen Typ verwenden, um Werte wie „Ja“/„Nein“ zu speichern, wobei „Ja“ 1 und „Nein“ 0 ist. |
Darüber hinaus ist es nicht erforderlich, den Feldwert anzugeben, es sei denn, dies ist verboten. In diesem Fall können Sie NULL verwenden.
Um Beispiele auszuführen, erstellen wir eine Testdatenbank mit dem Namen „Test“.
Um eine einfache Datenbank ohne zusätzliche Eigenschaften zu erstellen, führen Sie den folgenden Befehl aus:
CREATE DATABASE Test
Um eine Datenbank zu löschen, führen Sie diesen Befehl aus:
DROP DATABASE Test
Um zu unserer Datenbank zu wechseln, verwenden Sie den Befehl:
USE Test
Alternativ können Sie die Testdatenbank aus dem Dropdown-Menü im SSMS-Menübereich auswählen.
Jetzt können wir in unserer Datenbank eine Tabelle mit Beschreibungen, Leerzeichen und kyrillischen Symbolen erstellen:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
In diesem Fall müssen wir Namen in eckige Klammern setzen […].
Dennoch ist es besser, alle Objektnamen in lateinischer Sprache anzugeben und keine Leerzeichen in den Namen zu verwenden. In diesem Fall beginnt jedes Wort mit einem Großbuchstaben. Beispielsweise könnten wir für das Feld „EmployeeID“ den Namen „PersonnelNumber“ angeben. Sie können auch Zahlen im Namen verwenden, z. B. Telefonnummer1.
Hinweis: In einigen DBMSs ist es bequemer, das folgende Namensformat «PHONE_NUMBER» zu verwenden. Dieses Format können Sie beispielsweise in ORACLE-Datenbanken sehen. Außerdem sollte der Feldname nicht mit den in DBMS verwendeten Schlüsselwörtern übereinstimmen.
Aus diesem Grund können Sie die Syntax der eckigen Klammern vergessen und die Employees-Tabelle löschen:
DROP TABLE [Employees]
Beispielsweise können Sie die Tabelle mit Mitarbeitern „Mitarbeiter“ nennen und die folgenden Namen für ihre Felder festlegen:
- ID
- Name
- Geburtstag
- Position
- Abteilung
Sehr oft verwenden wir „ID“ für das Identifikatorfeld.
Lassen Sie uns nun eine Tabelle erstellen:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Um die obligatorischen Spalten festzulegen, können Sie die Option NOT NULL verwenden.
Für die aktuelle Tabelle können Sie die Felder mit den folgenden Befehlen neu definieren:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Hinweis: Das allgemeine Konzept der SQL-Sprache für die meisten DBMS ist dasselbe (aus eigener Erfahrung). Der Unterschied zwischen DDLs in verschiedenen DBMSs liegt hauptsächlich in den Datentypen (sie können sich nicht nur durch ihre Namen, sondern auch durch ihre spezifische Implementierung unterscheiden). Darüber hinaus sind die spezifischen SQL-Implementierungen (Befehle) gleich, es kann jedoch geringfügige Unterschiede im Dialekt geben. Wenn Sie die SQL-Grundlagen kennen, können Sie problemlos von einem DBMS zum anderen wechseln. In diesem Fall müssen Sie nur die Besonderheiten der Implementierung von Befehlen in einem neuen DBMS verstehen.
Vergleichen Sie die gleichen Befehle im ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE unterscheidet sich bei der Implementierung des Typs varchar2. Sein Format hängt von den DB-Einstellungen ab und Sie können einen Text beispielsweise in UTF-8 speichern. Außerdem können Sie die Feldlänge sowohl in Bytes als auch in Symbolen angeben. Dazu müssen Sie die BYTE- und CHAR-Werte gefolgt vom Längenfeld verwenden. Zum Beispiel:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
Der standardmäßig zu verwendende Wert (BYTE oder CHAR), wenn Sie in ORACLE lediglich varchar2(30) angeben, hängt von den DB-Einstellungen ab. Oft lässt man sich leicht verwirren. Daher empfehle ich, CHAR explizit anzugeben, wenn Sie den Typ varchar2 (z. B. mit UTF-8) in ORACLE verwenden (da es bequemer ist, die Zeichenfolgenlänge in Symbolen zu lesen).
Wenn in diesem Fall jedoch Daten in der Tabelle vorhanden sind, müssen zur erfolgreichen Ausführung von Befehlen die Felder ID und Name in allen Tabellenzeilen ausgefüllt werden.
Ich werde es an einem bestimmten Beispiel zeigen.
Lassen Sie uns mit dem folgenden Skript Daten in die Felder „ID“, „Position“ und „Abteilung“ einfügen:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
In diesem Fall gibt der INSERT-Befehl ebenfalls einen Fehler zurück. Dies geschieht, weil wir den Wert für das Pflichtfeld Name.
nicht angegeben habenWenn es einige Daten in der ursprünglichen Tabelle gäbe, dann würde der Befehl „ALTER TABLE Employees ALTER COLUMN ID int NOT NULL“ funktionieren, während der Befehl „ALTER TABLE Employees ALTER COLUMN Name int NOT NULL“ einen Fehler zurückgeben würde, den das Feld „Name“ hat NULL-Werte.
Lassen Sie uns Werte im Feld Name hinzufügen:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Außerdem können Sie NOT NULL verwenden, wenn Sie eine neue Tabelle mit der CREATE TABLE-Anweisung erstellen.
Lassen Sie uns zuerst eine Tabelle löschen:
DROP TABLE Employees
Jetzt erstellen wir eine Tabelle mit den Pflichtfeldern ID und Name:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Außerdem können Sie NULL nach einem Spaltennamen angeben, was bedeutet, dass NULL-Werte zulässig sind. Dies ist nicht zwingend erforderlich, da diese Option standardmäßig gesetzt ist.
Wenn Sie die aktuelle Spalte nicht obligatorisch machen müssen, verwenden Sie die folgende Syntax:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Alternativ können Sie diesen Befehl verwenden:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Darüber hinaus können wir mit diesem Befehl entweder den Feldtyp in einen anderen kompatiblen ändern oder seine Länge ändern. Erweitern wir beispielsweise das Namensfeld auf 50 Symbole:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Primärschlüssel
Beim Erstellen einer Tabelle müssen Sie für jede Zeile eine Spalte oder eine Gruppe von Spalten angeben, die eindeutig sind. Anhand dieses eindeutigen Werts können Sie einen Datensatz identifizieren. Dieser Wert wird Primärschlüssel genannt. Die ID-Spalte (die die „persönliche Nummer eines Mitarbeiters“ enthält – in unserem Fall ist dies der eindeutige Wert für jeden Mitarbeiter und kann nicht dupliziert werden) kann der Primärschlüssel für unsere Employees-Tabelle sein.
Sie können den folgenden Befehl verwenden, um einen Primärschlüssel für die Tabelle zu erstellen:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
„PK_Employees“ ist ein Einschränkungsname, der den Primärschlüssel definiert. Normalerweise besteht der Name eines Primärschlüssels aus dem Präfix „PK_“ und dem Tabellennamen.
Wenn der Primärschlüssel mehrere Felder enthält, müssen Sie diese Felder in Klammern durch ein Komma getrennt auflisten:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Beachten Sie, dass in MS SQL alle Felder des Primärschlüssels NICHT NULL sein sollten.
Außerdem können Sie beim Erstellen einer Tabelle einen Primärschlüssel definieren. Lassen Sie uns die Tabelle löschen:
DROP TABLE Employees
Erstellen Sie dann eine Tabelle mit der folgenden Syntax:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Daten zur Tabelle hinzufügen:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
Eigentlich müssen Sie den Constraint-Namen nicht angeben. In diesem Fall wird ein Systemname vergeben. Beispiel:«PK__Mitarbeiter__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
oder
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Ich persönlich würde empfehlen, den Constraint-Namen für permanente Tabellen explizit anzugeben, da es in Zukunft einfacher ist, mit einem explizit definierten und eindeutigen Wert zu arbeiten oder ihn zu löschen. Zum Beispiel:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Dennoch ist es bequemer, diese kurze Syntax ohne Einschränkungsnamen beim Erstellen von temporären Datenbanktabellen anzuwenden (der Name einer temporären Tabelle beginnt mit # oder ##.
Zusammenfassung:
Folgende Befehle haben wir bereits analysiert:
- TABELLE ERSTELLEN table_name (Auflistung der Felder und ihrer Typen sowie Einschränkungen) – dient zum Erstellen einer neuen Tabelle in der aktuellen Datenbank;
- FALLTABELLE table_name – dient zum Löschen einer Tabelle aus der aktuellen Datenbank;
- TABELLE ÄNDERN Tabellenname ALTER COLUMN Spaltenname … – dient zum Aktualisieren des Spaltentyps oder zum Ändern seiner Einstellungen (z. B. wenn Sie NULL oder NOT NULL setzen müssen);
- TABELLE ÄNDERN Tabellenname BESCHRÄNKUNG HINZUFÜGEN Einschränkungsname PRIMÄRSCHLÜSSEL (field1, field2,…) – wird verwendet, um der aktuellen Tabelle einen Primärschlüssel hinzuzufügen;
- TABELLE ÄNDERN Tabellenname DROP CONSTRAINT Constraint_Name – wird verwendet, um einen Constraint aus der Tabelle zu löschen.
Temporäre Tabellen
Zusammenfassung von MSDN. Es gibt zwei Arten von temporären Tabellen in MS SQL Server:lokal (#) und global (##). Lokale temporäre Tabellen sind nur für ihre Ersteller sichtbar, bevor die Instanz von SQL Server getrennt wird. Sie werden automatisch gelöscht, nachdem der Benutzer von der Instanz von SQL Server getrennt wurde. Globale temporäre Tabellen sind nach dem Erstellen dieser Tabellen für alle Benutzer während aller Verbindungssitzungen sichtbar. Diese Tabellen werden gelöscht, sobald Benutzer von der Instanz von SQL Server getrennt werden.
Temporäre Tabellen werden in der tempdb-Systemdatenbank erstellt, was bedeutet, dass wir die Hauptdatenbank nicht überschwemmen. Außerdem können Sie sie mit dem Befehl DROP TABLE löschen. Sehr oft werden lokale (#) temporäre Tabellen verwendet.
Um eine temporäre Tabelle zu erstellen, können Sie den Befehl CREATE TABLE verwenden:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Sie können die temporäre Tabelle mit dem Befehl DROP TABLE löschen:
DROP TABLE #Temp
Darüber hinaus können Sie eine temporäre Tabelle erstellen und diese mithilfe der SELECT … INTO-Syntax mit den Daten füllen:
SELECT ID,Name INTO #Temp FROM Employees
Hinweis: In verschiedenen DBMS kann die Implementierung von temporären Datenbanken variieren. Beispielsweise sollte in den DBMS ORACLE und Firebird die Struktur temporärer Tabellen im Voraus durch den Befehl CREATE GLOBAL TEMPORARY TABLE definiert werden. Außerdem müssen Sie die Art der Datenspeicherung angeben. Danach sieht ein Benutzer es unter den üblichen Tabellen und arbeitet damit wie mit einer herkömmlichen Tabelle.
Datenbanknormalisierung:Aufteilung in Untertabellen (Referenztabellen) und Definition von Tabellenbeziehungen
Unsere aktuelle Mitarbeitertabelle hat einen Nachteil:Ein Benutzer kann beliebigen Text in die Felder Position und Abteilung eingeben, was zu Fehlern führen kann, da er für einen Mitarbeiter „IT“ als Abteilung angeben kann, während er für einen anderen Mitarbeiter „IT“ angeben kann Abteilung". Dadurch wird unklar, was der Benutzer gemeint hat, ob diese Mitarbeiter für die gleiche Abteilung arbeiten oder ob ein Schreibfehler vorliegt und es sich um 2 verschiedene Abteilungen handelt. Außerdem können wir in diesem Fall die Daten für einen Bericht nicht korrekt gruppieren, in dem wir die Anzahl der Mitarbeiter für jede Abteilung anzeigen müssen.
Ein weiterer Nachteil ist das Speichervolumen und seine Duplizierung, d. h. Sie müssen für jeden Mitarbeiter einen vollständigen Namen der Abteilung angeben, was Speicherplatz in Datenbanken erfordert, um jedes Symbol des Abteilungsnamens zu speichern.
Der dritte Nachteil ist die Komplexität der Aktualisierung von Felddaten, wenn Sie den Namen einer beliebigen Position ändern müssen – vom Programmierer zum Junior-Programmierer. In diesem Fall müssen Sie in jeder Tabellenzeile, in der die Position „Programmierer“ lautet, neue Daten hinzufügen.
Um solche Situationen zu vermeiden, wird empfohlen, die Datenbanknormalisierung zu verwenden – Aufteilung in Untertabellen – Referenztabellen.
Lassen Sie uns 2 Referenztabellen „Positionen“ und „Abteilungen“ erstellen:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Beachten Sie, dass wir hier eine neue Eigenschaft IDENTITY verwendet haben. Das bedeutet, dass die Daten in der ID-Spalte automatisch beginnend mit 1 aufgelistet werden. Somit werden beim Hinzufügen neuer Datensätze die Werte 1, 2, 3 usw. der Reihe nach zugewiesen. Normalerweise werden diese Felder als Autoincrement-Felder bezeichnet. In einer Tabelle kann nur ein Feld mit der IDENTITY-Eigenschaft als Primärschlüssel definiert werden. Normalerweise, aber nicht immer, ist ein solches Feld der Primärschlüssel der Tabelle.
Hinweis: In verschiedenen DBMSs kann die Implementierung von Feldern mit einem Inkrementierer unterschiedlich sein. In MySQL beispielsweise wird ein solches Feld durch die Eigenschaft AUTO_INCREMENT definiert. In ORACLE und Firebird könnten Sie diese Funktionalität durch Sequenzen (SEQUENCE) emulieren. Aber soweit ich weiß, wurde die Eigenschaft GENERATED AS IDENTITY in ORACLE hinzugefügt.
Lassen Sie uns diese Tabellen automatisch basierend auf den aktuellen Daten in den Feldern „Position“ und „Abteilung“ der Tabelle „Mitarbeiter“ ausfüllen:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Sie müssen die gleichen Schritte für die Abteilungstabelle ausführen:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Wenn wir nun die Tabellen Positionen und Abteilungen öffnen, sehen wir eine nummerierte Liste von Werten im ID-Feld:
SELECT * FROM Positions
| ID | Name |
| 1 | Buchhalter |
| 2 | Geschäftsführer |
| 3 | Programmierer |
| 4 | Leitender Programmierer |
SELECT * FROM Departments
| ID | Name |
| 1 | Verwaltung |
| 2 | Buchhaltung |
| 3 | IT |
Diese Tabellen dienen als Referenztabellen zur Definition von Positionen und Abteilungen. Nun beziehen wir uns auf Identifikatoren von Positionen und Abteilungen. Lassen Sie uns zunächst neue Felder in der Employees-Tabelle erstellen, um die Kennungen zu speichern:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Der Typ der Referenzfelder sollte derselbe sein wie in den Referenztabellen, in diesem Fall ist es int.
Außerdem können Sie mehrere Felder mit einem Befehl hinzufügen, indem Sie die Felder durch Kommas getrennt auflisten:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Jetzt fügen wir diesen Feldern Referenzeinschränkungen (FOREIGN KEY) hinzu, sodass ein Benutzer keine Werte hinzufügen kann, die nicht die ID-Werte der Referenztabellen sind.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Die gleichen Schritte sollten für das zweite Feld durchgeführt werden:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Jetzt können Benutzer in diese Felder nur die ID-Werte aus der entsprechenden Referenztabelle einfügen. Um also eine neue Abteilung oder Position zu verwenden, muss ein Benutzer einen neuen Datensatz in der entsprechenden Referenztabelle hinzufügen. Da Positionen und Abteilungen in Referenztabellen in einer Kopie gespeichert sind, müssen Sie sie zum Ändern ihres Namens nur in der Referenztabelle ändern.
Der Name einer Referenzbeschränkung ist normalerweise zusammengesetzt. Es besteht aus dem Präfix «FK», gefolgt von einem Tabellennamen und einem Feldnamen, der auf die Kennung der Referenztabelle verweist.
Die Kennung (ID) ist normalerweise ein interner Wert, der nur für Links verwendet wird. Es spielt keine Rolle, welchen Wert es hat. Versuchen Sie daher nicht, Lücken in der Wertefolge zu beseitigen, die beim Arbeiten mit der Tabelle auftreten, beispielsweise wenn Sie Datensätze aus der Referenztabelle löschen.
In einigen Fällen ist es möglich, eine Referenz aus mehreren Feldern aufzubauen:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
In diesem Fall wird ein Primärschlüssel durch eine Menge von mehreren Feldern (field1, field2, …) in der Tabelle „reference_table“ repräsentiert.
Aktualisieren wir nun die Felder PositionID und DepartmentID mit den ID-Werten aus den Referenztabellen.
Dazu verwenden wir den UPDATE-Befehl:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Führen Sie die folgende Abfrage aus:
SELECT * FROM Employees
| ID | Name | Geburtstag | Position | Abteilung | Positions-ID | Abteilungs-ID | |
| 1000 | Johannes | NULL | NULL | Geschäftsführer | Verwaltung | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programmierer | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Buchhalter | Buchhaltung | 1 | 2 |
| 1003 | Jordanien | NULL | NULL | Leitender Programmierer | IT | 4 | 3 |
Wie Sie sehen können, stimmen die Felder PositionID und DepartmentID mit Positionen und Abteilungen überein. Daher können Sie die Felder „Position“ und „Abteilung“ in der Tabelle „Employees“ löschen, indem Sie den folgenden Befehl ausführen:
ALTER TABLE Employees DROP COLUMN Position,Department
Führen Sie nun diese Anweisung aus:
SELECT * FROM Employees
| ID | Name | Geburtstag | Positions-ID | Abteilungs-ID | |
| 1000 | Johannes | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordanien | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
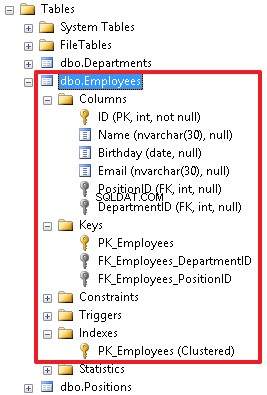
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
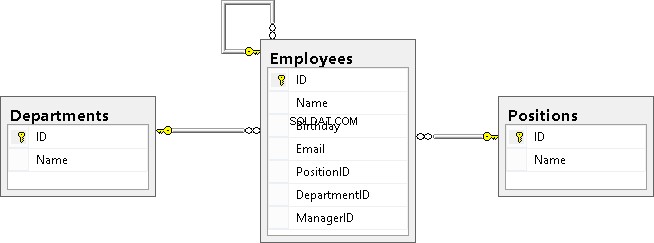
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
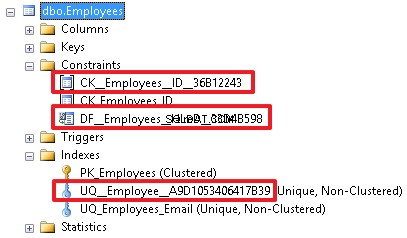
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.