Die serialisierbare Isolationsstufe bietet vollständigen Schutz vor Nebenläufigkeitseffekten, die die Datenintegrität gefährden und zu falschen Abfrageergebnissen führen können. Die Verwendung einer serialisierbaren Isolierung bedeutet, dass eine Transaktion, die nachweislich ohne gleichzeitige Aktivität korrekte Ergebnisse liefert, weiterhin korrekt ausgeführt wird, wenn sie mit einer beliebigen Kombination gleichzeitiger Transaktionen konkurriert.
Dies ist eine sehr starke Garantie , und eine, die wahrscheinlich den Erwartungen vieler T-SQL-Programmierer an die intuitive Transaktionsisolierung entspricht (obwohl in Wahrheit relativ wenige von ihnen routinemäßig eine serialisierbare Isolierung in der Produktion verwenden).
Der SQL-Standard definiert drei zusätzliche Isolationsstufen, die weitaus schwächere ACID bieten Isolationsgarantien als serialisierbar, im Gegenzug für potenziell höhere Parallelität und weniger potenzielle Nebenwirkungen wie Blockierung, Deadlocks und Abbrüche während der Festschreibung.
Anders als bei der serialisierbaren Isolation werden die anderen Isolationsstufen ausschließlich in Bezug auf bestimmte Nebenläufigkeitsphänomene definiert, die beobachtet werden können. Die zweitstärkste der Standard-Isolationsstufen nach serialisierbar heißt repeatable read . Der SQL-Standard legt fest, dass Transaktionen auf dieser Ebene ein einzelnes Nebenläufigkeitsphänomen zulassen, das als Phantom bekannt ist .
So wie wir zuvor wichtige Unterschiede zwischen der allgemeinen intuitiven Bedeutung von ACID-Transaktionseigenschaften und der Realität gesehen haben, umfasst das Phantomphänomen ein breiteres Spektrum an Verhaltensweisen, als oft angenommen wird.
Dieser Beitrag in der Serie befasst sich mit den tatsächlichen Garantien, die das wiederholbare Lesen bietet Isolationsstufe und zeigt einige der phantombezogenen Verhaltensweisen, die auftreten können. Um einige Punkte zu veranschaulichen, beziehen wir uns auf die folgende einfache Beispielabfrage, bei der die einfache Aufgabe darin besteht, die Gesamtzahl der Zeilen in einer Tabelle zu zählen:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Wiederholbarer Lesevorgang
Eine seltsame Sache an der Isolationsstufe für wiederholbare Lesevorgänge ist, dass dies nicht der Fall ist garantieren tatsächlich, dass Lesevorgänge wiederholbar sind , zumindest in einem allgemein verständlichen Sinn. Dies ist ein weiteres Beispiel, bei dem die intuitive Bedeutung allein irreführend sein kann. Das zweimalige Ausführen derselben Abfrage innerhalb derselben wiederholbaren Lesetransaktion kann tatsächlich unterschiedliche Ergebnisse zurückgeben.
Darüber hinaus bedeutet die SQL Server-Implementierung des wiederholbaren Lesens, dass ein einzelnes Lesen eines Datensatzes einige Zeilen verpassen kann das sollte logischerweise im Abfrageergebnis berücksichtigt werden. Obwohl dieses Verhalten zweifellos implementierungsspezifisch ist, entspricht es vollständig der Definition des wiederholbaren Lesens, die im SQL-Standard enthalten ist.
Das letzte, was ich schnell anmerken möchte, bevor ich in die Details eintauche, ist, dass wiederholbares Lesen in SQL Server nicht funktioniert bieten eine Point-in-Time-Ansicht der Daten.
Nicht wiederholbare Lesevorgänge
Die Isolationsstufe für wiederholbare Lesevorgänge bietet eine Garantie dafür, dass sich Daten nicht ändern für die Lebensdauer der Transaktion sobald sie gelesen wurde zum ersten Mal.
In dieser Definition sind einige Feinheiten enthalten. Erstens erlaubt es, dass sich Daten nach ändern die Transaktion beginnt, aber bevor die Daten erster sind zugegriffen. Zweitens gibt es keine Garantie dafür, dass die Transaktion tatsächlich auf alle Daten trifft, die logisch qualifiziert sind. Beispiele für beides werden wir in Kürze sehen.
Es gibt eine weitere Vorbereitung, die wir schnell aus dem Weg räumen müssen, die mit der Beispielabfrage zu tun hat, die wir verwenden werden. Fairerweise muss man sagen, dass die Semantik dieser Abfrage etwas verschwommen ist. Auf die Gefahr hin, leicht philosophisch zu klingen, was bedeutet das bedeuten um die Anzahl der Zeilen in der Tabelle zu zählen? Soll das Ergebnis den Stand der Tabelle zu einem bestimmten Zeitpunkt widerspiegeln? Soll dieser Zeitpunkt der Beginn oder das Ende der Transaktion sein oder etwas anderes?
Dies mag ein bisschen pingelig erscheinen, aber die Frage ist in jeder Datenbank berechtigt, die gleichzeitiges Lesen und Ändern von Daten unterstützt. Die Ausführung unserer Beispielabfrage könnte beliebig lange dauern (bei einer ausreichend großen Tabelle oder beispielsweise bei Ressourcenbeschränkungen), sodass gleichzeitige Änderungen nicht nur möglich, sondern unvermeidlich sind .
Das grundlegende Problem hier ist das Potenzial für das Nebenläufigkeitsphänomen, das als Phantom bezeichnet wird im SQL-Standard. Während wir Zeilen in der Tabelle zählen, könnte eine andere gleichzeitige Transaktion neue Zeilen einfügen an einem Ort, den wir bereits überprüft haben, oder ändern eine Zeile, die wir noch nicht überprüft haben, so, dass sie sich an eine Stelle bewegt, an der wir bereits gesucht haben. Die Leute denken oft an Phantome als Zeilen, die magisch erscheinen könnten, wenn sie zum zweiten Mal gelesen werden, in einer separaten Erklärung, aber die Auswirkungen können viel subtiler sein.
Beispiel für gleichzeitige Einfügung
Dieses erste Beispiel zeigt, wie gleichzeitige Einfügungen ein nicht wiederholbares Ergebnis erzeugen können lesen und/oder dazu führen, dass Zeilen übersprungen werden. Stellen Sie sich vor, unsere Testtabelle enthält anfänglich fünf Zeilen mit den unten gezeigten Werten:

Wir setzen jetzt die Isolationsstufe auf wiederholbares Lesen, starten eine Transaktion und führen unsere Zählabfrage aus. Wie zu erwarten ist das Ergebnis fünf . Bisher kein großes Rätsel.
Wird immer noch innerhalb derselben wiederholbaren Lese-Transaktion ausgeführt , führen wir die Zählabfrage erneut aus, diesmal jedoch während eine zweite gleichzeitige Transaktion neue Zeilen in dieselbe Tabelle einfügt. Das folgende Diagramm zeigt die Abfolge der Ereignisse, wobei die zweite Transaktion Zeilen mit den Werten 2 und 6 hinzufügt (vielleicht ist Ihnen aufgefallen, dass diese Werte direkt darüber nicht vorhanden waren):
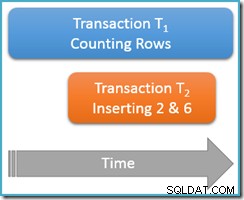
Wenn unsere Zählabfrage am serialisierbaren laufen würde Isolationsstufe, es würde garantiert entweder fünf zählen oder sieben Zeilen (siehe den vorherigen Artikel in dieser Serie, wenn Sie eine Auffrischung darüber benötigen, warum dies der Fall ist). Wie funktioniert Laufen am weniger isoliert wiederholbares Leseniveau Dinge beeinflussen?
Nun, wiederholbares Lesen Die Isolierung garantiert, dass beim zweiten Lauf der Zählabfrage alle zuvor gelesenen Zeilen angezeigt werden und sie sich in demselben Zustand wie zuvor befinden. Der Haken ist, dass die wiederholbare Leseisolation nichts aussagt darüber, wie die Transaktion die neuen Zeilen (die Phantome) behandeln soll.
Stellen Sie sich vor, dass unsere Zeilenzähltransaktion (T1 ) hat eine physische Ausführungsstrategie, bei der Zeilen in aufsteigender Indexreihenfolge durchsucht werden. Dies ist ein üblicher Fall, beispielsweise wenn ein vorwärts geordneter B-Tree-Index-Scan von der Ausführungsmaschine verwendet wird. Jetzt, gleich nach Transaktion T1 zählt die Zeilen 1 und 3 in aufsteigender Reihenfolge, Transaktion T2 könnte sich einschleichen, die neuen Zeilen 2 und 6 einfügen und dann seine Transaktion festschreiben.
Obwohl wir an dieser Stelle hauptsächlich an logische Verhaltensweisen denken, sollte ich erwähnen, dass es in der SQL Server-Sperrimplementierung von wiederholbarem Lesen nichts gibt, was verhindert wird Transaktion T2 davon ab, dies zu tun. Gemeinsam genutzte Sperren, die von Transaktion T1 übernommen wurden in zuvor gelesenen Zeilen verhindern, dass diese Zeilen geändert werden, aber sie verhindern nicht neue Zeilen nicht in den Wertebereich eingefügt werden, der von unserer Zählabfrage getestet wird (anders als die Schlüsselbereichssperren beim Sperren der serialisierbaren Isolation).
Wie auch immer, mit den zwei neuen Zeilen, die festgeschrieben sind, Transaktion T1 setzt seine Suche in aufsteigender Reihenfolge fort und trifft schließlich auf die Zeilen 4, 5, 6 und 7. Beachten Sie, dass T1 sieht in diesem Szenario die neue Zeile 6, aber nicht neue Zeile 2 (aufgrund der geordneten Suche und ihrer Position zum Zeitpunkt der Einfügung).
Das Ergebnis ist das wiederholbare Lesen Zählabfrage meldet, dass die Tabelle sechs Zeilen enthält (Werte 1, 3, 4, 5, 6 und 7). Dieses Ergebnis stimmt nicht mit dem vorherigen Ergebnis von fünf Zeilen überein innerhalb derselben Transaktion erhalten . Beim zweiten Lesen wurde Phantomreihe 6 gezählt, aber Phantomreihe 2 verfehlt. So viel zur intuitiven Bedeutung eines wiederholbaren Lesens!
Beispiel für gleichzeitige Aktualisierung
Eine ähnliche Situation kann bei einem gleichzeitigen Update auftreten statt einer Einlage. Stellen Sie sich vor, unsere Testtabelle wird zurückgesetzt und enthält dieselben fünf Zeilen wie zuvor:

Dieses Mal führen wir unsere Zählabfrage nur einmal aus beim wiederholbaren Lesen Isolationsstufe, während eine zweite gleichzeitige Transaktion die Zeile mit dem Wert 5 auf den Wert 2 aktualisiert:
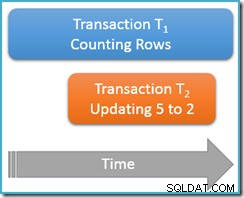
Transaktion T1 beginnt erneut mit dem Zählen der Zeilen (in aufsteigender Reihenfolge) und trifft zuerst auf die Zeilen 1 und 3. Jetzt schlüpft Transaktion T2 herein, ändert den Wert von Zeile 5 auf 2 und schreibt fest:

Ich habe die aktualisierte Zeile an derselben Position wie zuvor gezeigt, um die Änderung deutlich zu machen, aber der B-Tree-Index, den wir scannen, behält die Daten in logischer Reihenfolge bei, sodass das wirkliche Bild näher an diesem liegt:

Der Punkt ist diese Transaktion T1 scannt gleichzeitig dieselbe Struktur in Vorwärtsreihenfolge und befindet sich derzeit genau danach den Eintrag für den Wert 3. Die Zählabfrage fährt von diesem Punkt an mit dem Scannen fort und findet die Zeilen 4 und 7 (aber natürlich nicht die Zeile 5).
Zusammenfassend hat die Zählabfrage in diesem Szenario die Zeilen 1, 3, 4 und 7 gesehen. Es meldet eine Anzahl von vier Zeilen – was seltsam ist, denn die Tabelle scheint fünf Zeilen enthalten zu haben durchgehend!
Eine zweite Ausführung der Zählabfrage innerhalb derselben wiederholbaren Lesetransaktion würde fünf zurückgeben Zeilen, aus ähnlichen Gründen wie zuvor. Als letzte Anmerkung, falls Sie sich fragen, bieten gleichzeitige Löschungen keine Gelegenheit für eine phantombasierte Anomalie unter wiederholbarer Leseisolation.
Abschließende Gedanken
Die vorherigen Beispiele verwendeten beide Scans in aufsteigender Reihenfolge einer Indexstruktur, um einen einfachen Überblick über die Art von Effekten zu geben, die Phantome auf ein wiederholbares Lesen haben können Anfrage. Es ist wichtig zu verstehen, dass sich diese Darstellungen in keiner wichtigen Weise auf die Scanrichtung oder die Tatsache verlassen, dass ein B-Tree-Index verwendet wurde. Bitte nicht sind der Meinung, dass bestellte Scans irgendwie dafür verantwortlich und daher zu vermeiden sind!
Dieselben Nebenläufigkeitseffekte können bei einem Scan in absteigender Reihenfolge einer Indexstruktur oder in einer Vielzahl anderer Szenarien für den physischen Datenzugriff beobachtet werden. Der allgemeine Punkt ist, dass Phantomphänomene vom SQL-Standard für Transaktionen auf der Isolationsebene für wiederholbare Lesevorgänge ausdrücklich zugelassen (aber nicht erforderlich) sind.
Nicht alle Transaktionen erfordern die vollständige Isolationsgarantie, die eine serialisierbare Isolation bietet, und nicht viele Systeme könnten die Nebeneffekte tolerieren, wenn dies der Fall wäre. Dennoch lohnt es sich, genau zu verstehen, welche Garantien die verschiedenen Isolationsstufen bieten.
Nächstes Mal
Der nächste Teil dieser Reihe befasst sich mit den noch schwächeren Isolationsgarantien, die von der Standardisolationsstufe Read Committed von SQL Server geboten werden .
[Siehe den Index für die gesamte Serie]