Das Hinzufügen eines gefilterten Indexes kann überraschende Nebeneffekte auf vorhandene Abfragen haben, selbst wenn der neue gefilterte Index völlig unabhängig zu sein scheint. Dieser Beitrag befasst sich mit einem Beispiel, das sich auf DELETE-Anweisungen auswirkt, die zu einer schlechten Leistung und einem erhöhten Deadlock-Risiko führen.
Testumgebung
Die folgende Tabelle wird in diesem Beitrag verwendet:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Diese nächste Anweisung erstellt 499.999 Zeilen mit Beispieldaten:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Das verwendet eine Zahlentabelle als Quelle aufeinanderfolgender Ganzzahlen von 1 bis 499.999. Falls Sie keine davon in Ihrer Testumgebung haben, kann der folgende Code verwendet werden, um effizient eine zu erstellen, die ganze Zahlen von 1 bis 1.000.000 enthält:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Grundlage der späteren Tests wird das Löschen von Zeilen aus der Testtabelle für ein bestimmtes Startdatum sein. Um das Identifizieren von zu löschenden Zeilen effizienter zu gestalten, fügen Sie diesen nicht gruppierten Index hinzu:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Die Beispieldaten
Sobald diese Schritte abgeschlossen sind, sieht das Beispiel so aus:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
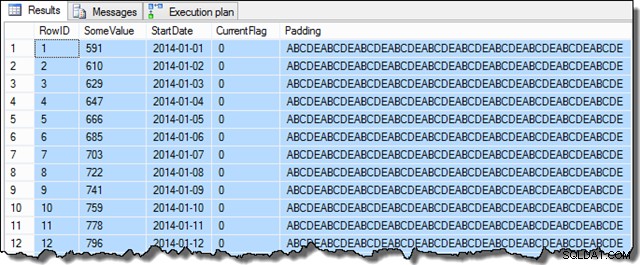
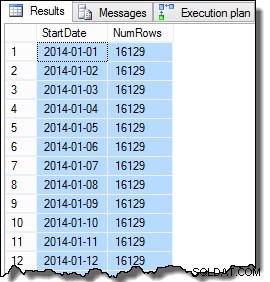
Die Daten der SomeValue-Spalte können aufgrund der pseudozufälligen Generierung geringfügig abweichen, aber dieser Unterschied ist nicht wichtig. Insgesamt enthalten die Beispieldaten 16.129 Zeilen für jedes der 31 StartDate-Daten im Januar 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
Der letzte Schritt, den wir ausführen müssen, um die Daten einigermaßen realistisch zu machen, besteht darin, die CurrentFlag-Spalte für die höchste RowID für jedes StartDate auf true zu setzen. Das folgende Skript erfüllt diese Aufgabe:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Der Ausführungsplan für dieses Update enthält eine Segment-Top-Kombination, um die höchste RowID pro Tag effizient zu finden:

Beachten Sie, dass der Ausführungsplan wenig Ähnlichkeit mit der schriftlichen Form der Abfrage hat. Dies ist ein großartiges Beispiel dafür, wie der Optimierer anhand der logischen SQL-Spezifikation arbeitet, anstatt die SQL direkt zu implementieren. Falls Sie sich fragen, ist die Eager Table Spool in diesem Plan für den Halloween-Schutz erforderlich.
Einen Tag voller Daten löschen
Ok, nach Abschluss der Vorbereitungen besteht die Aufgabe nun darin, Zeilen für ein bestimmtes Startdatum zu löschen. Dies ist die Art von Abfrage, die Sie routinemäßig zum frühesten Datum in einer Tabelle ausführen können, wenn die Daten das Ende ihrer Nutzungsdauer erreicht haben.
Am Beispiel des 1. Januar 2014 ist die Testlöschabfrage einfach:
DELETE dbo.Data WHERE StartDate = '20140101';
Der Ausführungsplan ist ebenfalls ziemlich einfach, aber es lohnt sich, ihn ein wenig im Detail zu betrachten:

Plananalyse
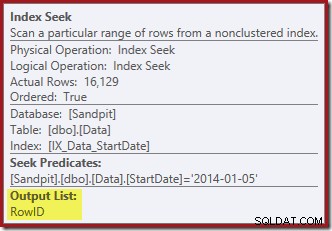
Die Indexsuche ganz rechts verwendet den nicht gruppierten Index, um Zeilen für den angegebenen StartDate-Wert zu finden. Es gibt nur die RowID-Werte zurück, die es findet, wie der Operator-Tooltip bestätigt:
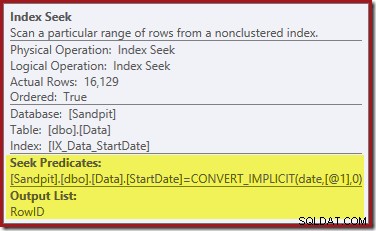
Wenn Sie sich fragen, wie der StartDate-Index es schafft, die RowID zurückzugeben, denken Sie daran, dass RowID der eindeutige Clustered-Index für die Tabelle ist, sodass er automatisch in den StartDate Nonclustered-Index aufgenommen wird.
Der nächste Operator im Plan ist Clustered Index Delete. Dies verwendet den von der Indexsuche gefundenen RowID-Wert, um zu entfernende Zeilen zu lokalisieren.
Der letzte Operator im Plan ist ein Index Delete. Dadurch werden Zeilen aus dem nicht gruppierten Index IX_Data_StartDate entfernt die sich auf die durch Clustered Index Delete entfernte RowID beziehen. Um diese Zeilen im Nonclustered-Index zu finden, benötigt der Abfrageprozessor das StartDate (den Schlüssel für den Nonclustered-Index).
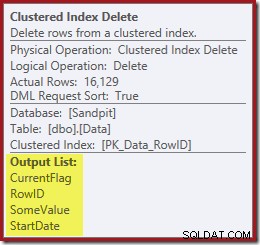
Denken Sie daran, dass die ursprüngliche Indexsuche nicht das Startdatum zurückgegeben hat, sondern nur die RowID. Wie erhält der Abfrageprozessor also das Startdatum für die Indexlöschung? In diesem speziellen Fall hat der Optimierer möglicherweise bemerkt, dass der StartDate-Wert eine Konstante ist, und ihn wegoptimiert, aber das ist nicht passiert. Die Antwort ist, dass der Clustered Index Delete-Operator liest den StartDate-Wert für die aktuelle Zeile und fügt ihn dem Stream hinzu. Vergleichen Sie die Ausgabeliste des unten gezeigten Clustered Index Delete mit der des Index Seek direkt darüber:
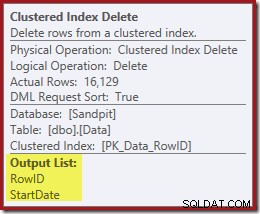
Es mag überraschend erscheinen, dass ein Delete-Operator Daten liest, aber so funktioniert es. Der Abfrageprozessor weiß, dass er die Zeile im Clustered-Index lokalisieren muss, um sie zu löschen, also könnte er das Lesen von Spalten, die zum Verwalten von Nonclustered-Indizes benötigt werden, genauso gut bis zu diesem Zeitpunkt aufschieben, wenn er kann.
Hinzufügen eines gefilterten Indexes
Stellen Sie sich nun vor, jemand hat eine entscheidende Abfrage für diese Tabelle, die schlecht abschneidet. Der hilfreiche DBA führt eine Analyse durch und fügt den folgenden gefilterten Index hinzu:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Der neue gefilterte Index hat die gewünschte Wirkung auf die problematische Abfrage, und alle sind zufrieden. Beachten Sie, dass der neue Index überhaupt nicht auf die StartDate-Spalte verweist, sodass wir nicht davon ausgehen, dass er sich überhaupt auf unsere Day-Delete-Abfrage auswirkt.
Löschen eines Tages mit dem gefilterten Index
Wir können diese Erwartung testen, indem wir Daten ein zweites Mal löschen:
DELETE dbo.Data WHERE StartDate = '20140102';
Plötzlich hat sich der Ausführungsplan in einen parallelen Clustered Index Scan geändert:

Beachten Sie, dass es für den neuen gefilterten Index keinen separaten Indexlöschoperator gibt. Der Optimierer hat sich dafür entschieden, diesen Index innerhalb des Clustered Index Delete-Operators beizubehalten. Dies wird im SQL Sentry Plan Explorer wie oben gezeigt hervorgehoben ("+1 nicht geclusterte Indizes") mit vollständigen Details im Tooltip:
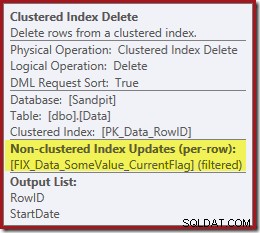
Wenn die Tabelle groß ist (denken Sie an Data Warehouse), kann diese Änderung zu einem parallelen Scan sehr wichtig sein. Was ist mit der netten Indexsuche am Startdatum passiert und warum hat ein völlig unabhängiger gefilterter Index die Dinge so dramatisch verändert?
Das Problem finden
Der erste Hinweis ergibt sich aus einem Blick auf die Eigenschaften des Clustered Index Scan:
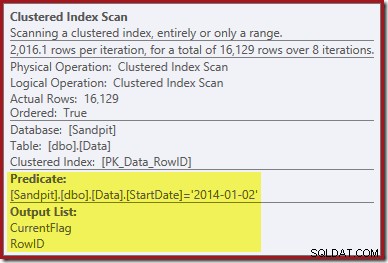
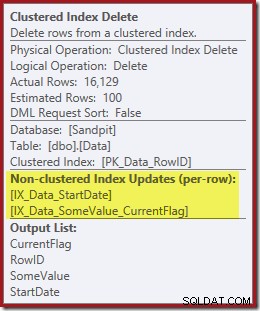
Dieser Operator findet nicht nur RowID-Werte für den Clustered Index Delete-Operator zum Löschen, sondern liest jetzt auch CurrentFlag-Werte. Die Notwendigkeit dieser Spalte ist unklar, aber sie erklärt zumindest ansatzweise die Entscheidung zum Scannen:Die CurrentFlag-Spalte ist nicht Teil unseres StartDate-Nonclustered-Index.
Wir können dies bestätigen, indem wir die Löschabfrage umschreiben, um die Verwendung des nicht gruppierten StartDate-Indexes zu erzwingen:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Der Ausführungsplan ist näher an seiner ursprünglichen Form, verfügt aber jetzt über eine Schlüsselsuche:
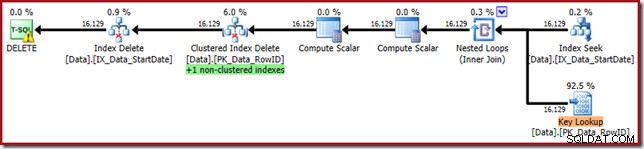
Die Key Lookup-Eigenschaften bestätigen, dass dieser Operator CurrentFlag-Werte abruft:
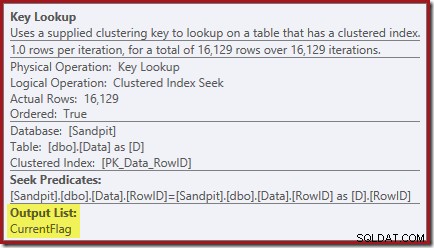
Vielleicht sind Ihnen auch die Warndreiecke in den letzten beiden Plänen aufgefallen. Dies sind fehlende Indexwarnungen:
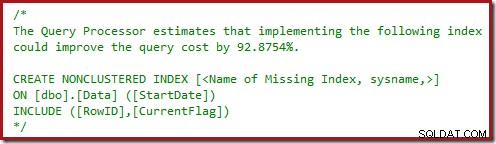
Dies ist eine weitere Bestätigung dafür, dass SQL Server die CurrentFlag-Spalte im Nonclustered-Index enthalten sehen möchte. Der Grund für den Wechsel zu einem parallelen Clustered Index Scan ist nun klar:Der Abfrageprozessor entscheidet, dass das Scannen der Tabelle billiger ist als das Ausführen der Schlüsselsuchen.
Ja, aber warum?
Das ist alles sehr seltsam. Im ursprünglichen Ausführungsplan konnte SQL Server lesen Zusätzliche Spaltendaten, die zum Verwalten von Nonclustered-Indizes beim Clustered Index Delete-Operator benötigt werden. Der Wert der CurrentFlag-Spalte wird benötigt, um den gefilterten Index beizubehalten, also warum behandelt SQL Server ihn nicht genauso?
Die kurze Antwort lautet, dass dies möglich ist, aber nur, wenn der gefilterte Index in einem separaten Index Delete-Operator verwaltet wird. Wir können dies für die aktuelle Abfrage erzwingen, indem wir das undokumentierte Trace-Flag 8790 verwenden. Ohne dieses Flag entscheidet der Optimierer, ob jeder Index in einem separaten Operator oder als Teil der Basistabellenoperation verwaltet wird.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Der Ausführungsplan sucht wieder nach dem nicht gruppierten StartDate-Index:
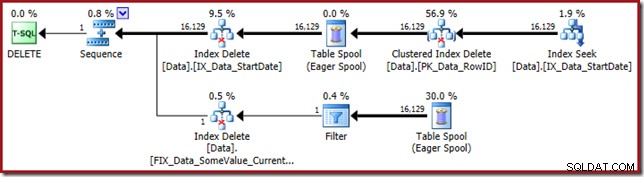
Die Indexsuche gibt nur RowID-Werte zurück (kein CurrentFlag):
Und der Clustered Index Delete liest die Spalten, die zum Verwalten der Nonclustered-Indizes benötigt werden, einschließlich CurrentFlag:
Diese Daten werden eifrig in eine Tabellenspule geschrieben, die für jeden Index, der gewartet werden muss, wiedergegeben wird. Beachten Sie auch den expliziten Filter-Operator vor dem Index Delete-Operator für den gefilterten Index.
Ein weiteres Muster, auf das Sie achten sollten
Dieses Problem führt nicht immer zu einem Tabellenscan anstelle einer Indexsuche. Um ein Beispiel dafür zu sehen, fügen Sie der Testtabelle einen weiteren Index hinzu:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Beachten Sie, dass dieser Index nicht ist gefiltert und betrifft nicht die StartDate-Spalte. Versuchen Sie jetzt erneut eine Abfrage zum Löschen von Tagen:
DELETE dbo.Data WHERE StartDate = '20140104';
Der Optimierer kommt jetzt mit diesem Monster:
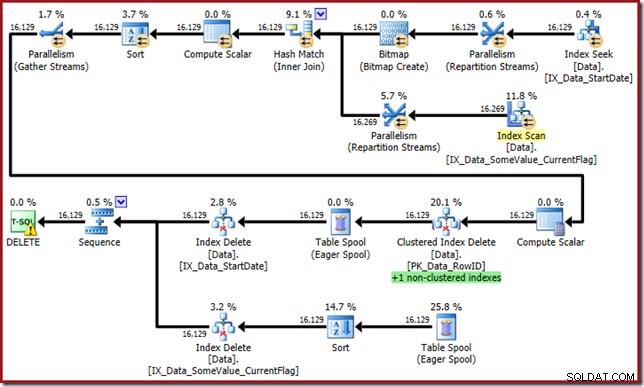
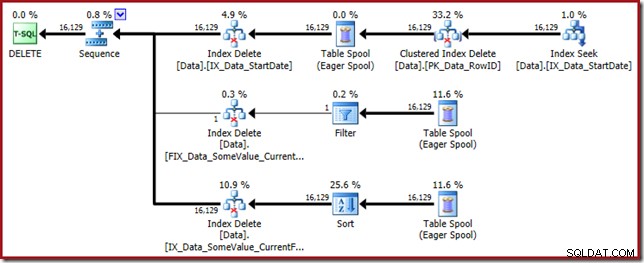
Dieser Abfrageplan hat einen hohen Überraschungsfaktor, aber die eigentliche Ursache ist die gleiche. Die CurrentFlag-Spalte wird immer noch benötigt, aber jetzt wählt der Optimierer eine Indexüberschneidungsstrategie, um sie anstelle eines Tabellenscans zu erhalten. Die Verwendung des Trace-Flags erzwingt einen Wartungsplan pro Index, und die Vernunft wird erneut wiederhergestellt (der einzige Unterschied ist eine zusätzliche Spool-Wiedergabe, um den neuen Index zu verwalten):
Nur gefilterte Indizes verursachen dies
Dieses Problem tritt nur auf, wenn der Optimierer einen gefilterten Index in einem Clustered Index Delete-Operator verwaltet. Nicht gefilterte Indizes sind nicht betroffen, wie das folgende Beispiel zeigt. Der erste Schritt besteht darin, den gefilterten Index zu löschen:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Jetzt müssen wir die Abfrage so schreiben, dass der Optimierer davon überzeugt wird, alle Indizes im Clustered Index Delete beizubehalten. Meine Wahl dafür ist, eine Variable und einen Hinweis zu verwenden, um die Erwartungen des Optimierers an die Zeilenanzahl zu senken:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Der Ausführungsplan ist:
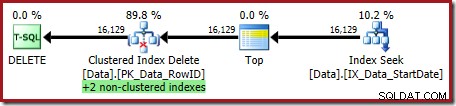
Beide Nonclustered-Indizes werden von Clustered Index Delete verwaltet:
Die Indexsuche gibt nur die RowID zurück:
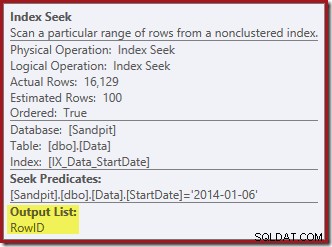
Die für die Indexpflege benötigten Spalten werden intern vom delete-Operator abgerufen; diese Details werden in der Ausgabe des Showplans nicht angezeigt (daher wäre die Ausgabeliste des delete-Operators leer). Ich habe einen OUTPUT hinzugefügt -Klausel in die Abfrage, um anzuzeigen, dass Clustered Index Delete erneut Daten zurückgibt, die es bei seiner Eingabe nicht erhalten hat:
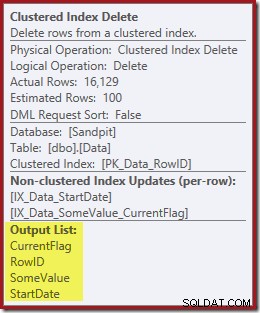
Abschließende Gedanken
Dies ist eine knifflige Einschränkung, die es zu umgehen gilt. Einerseits möchten wir generell keine undokumentierten Trace-Flags in Produktivsystemen verwenden.
Die natürliche „Lösung“ besteht darin, die für die Pflege des gefilterten Index erforderlichen Spalten zu all hinzuzufügen Nonclustered-Indizes, die verwendet werden können, um zu löschende Zeilen zu lokalisieren. Dies ist unter mehreren Gesichtspunkten kein sehr ansprechender Vorschlag. Eine andere Alternative ist es, überhaupt keine gefilterten Indizes zu verwenden, aber das ist auch nicht ideal.
Meiner Meinung nach sollte der Abfrageoptimierer automatisch eine Wartungsalternative pro Index für gefilterte Indizes in Betracht ziehen, aber seine Argumentation scheint in diesem Bereich derzeit unvollständig zu sein (und basiert eher auf einfachen Heuristiken als auf angemessenen Kosten pro Index/pro Zeile Alternativen).
Um diese Aussage mit einigen Zahlen zu untermauern:Der vom Optimierer gewählte parallele Clustered-Index-Scan-Plan lag bei 5,5 Einheiten in meinen Tests. Dieselbe Abfrage mit dem Trace-Flag schätzt die Kosten auf 1,4 Einheiten. Mit dem dritten Index hatte der vom Optimierer gewählte parallele Index-Schnittpunktplan geschätzte Kosten von 4,9 , während der Trace-Flag-Plan bei 2,7 eintraf Einheiten (alle Tests auf SQL Server 2014 RTM CU1 Build 12.0.2342 unter dem 120-Kardinalitätsschätzungsmodell und mit aktiviertem Ablaufverfolgungsflag 4199).
Ich betrachte dies als Verhalten, das verbessert werden sollte. Sie können abstimmen, ob Sie mir zu diesem Connect-Element zustimmen oder nicht zustimmen.



