TimescaleDB ist eine Open-Source-Datenbank, die erfunden wurde, um SQL für Zeitreihendaten skalierbar zu machen. Es ist ein relativ neues Datenbanksystem. TimescaleDB wurde vor zwei Jahren auf den Markt gebracht und erreichte im September 2018 die Version 1.0. Dennoch wurde es auf einem ausgereiften RDBMS-System entwickelt.
TimescaleDB ist als PostgreSQL-Erweiterung gepackt. Der gesamte Code ist unter der Apache-2-Open-Source-Lizenz lizenziert, mit Ausnahme einiger Quellcodes, die sich auf die unter der Timescale-Lizenz (TSL) lizenzierten Zeitreihen-Unternehmensfunktionen beziehen.
Als Zeitreihendatenbank bietet sie eine automatische Partitionierung über Datums- und Schlüsselwerte hinweg. Die native SQL-Unterstützung von TimescaleDB macht es zu einer guten Option für diejenigen, die Zeitreihendaten speichern möchten und bereits über solide SQL-Sprachkenntnisse verfügen.
Wenn Sie nach einer Zeitreihendatenbank suchen, die Rich SQL, HA, eine solide Sicherungslösung, Replikation und andere Unternehmensfunktionen verwenden kann, bringt Sie dieser Blog möglicherweise auf den richtigen Weg.
Wann TimescaleDB verwendet werden sollte
Bevor wir mit den Funktionen von TimescaleDB beginnen, sehen wir uns an, wo es passt. TimescaleDB wurde entwickelt, um das Beste aus relationalem und NoSQL zu bieten, mit dem Schwerpunkt auf Zeitreihen. Aber was sind Zeitreihendaten?
Zeitreihendaten bilden den Kern des Internets der Dinge, von Überwachungssystemen und vielen anderen Lösungen, die sich auf häufig ändernde Daten konzentrieren. Wie der Name „Zeitreihen“ schon sagt, handelt es sich um Daten, die sich mit der Zeit ändern. Die Möglichkeiten für diese Art von DBMS sind endlos. Sie können es in verschiedenen industriellen IoT-Anwendungsfällen in den Bereichen Fertigung, Bergbau, Öl und Gas, Einzelhandel, Gesundheitswesen, Entwicklungsüberwachung oder Finanzinformationen einsetzen. Es kann auch hervorragend in Pipelines für maschinelles Lernen oder als Quelle für Geschäftsabläufe und Informationen eingesetzt werden.
Es besteht kein Zweifel, dass die Nachfrage nach IoT und ähnlichen Lösungen wachsen wird. Vor diesem Hintergrund können wir auch erwarten, dass Daten auf viele verschiedene Arten analysiert und verarbeitet werden müssen. Zeitreihendaten werden normalerweise nur angehängt – es ist ziemlich unwahrscheinlich, dass Sie alte Daten aktualisieren. Normalerweise löschen Sie bestimmte Zeilen nicht, andererseits möchten Sie möglicherweise eine Art Aggregation der Daten im Laufe der Zeit. Wir wollen nicht nur speichern, wie sich unsere Daten mit der Zeit verändern, sondern auch analysieren und daraus lernen.
Das Problem bei neuartigen Datenbanksystemen ist, dass sie meist ihre eigene Abfragesprache verwenden. Benutzer brauchen Zeit, um eine neue Sprache zu lernen. Der größte Unterschied zwischen TimescaleDB und anderen gängigen Zeitreihendatenbanken ist die Unterstützung für SQL. TimescaleDB unterstützt die gesamte Bandbreite der SQL-Funktionalität, einschließlich zeitbasierter Aggregate, Joins, Unterabfragen, Fensterfunktionen und Sekundärindizes. Wenn Ihre Anwendung PostgreSQL bereits verwendet, sind darüber hinaus keine Änderungen am Client-Code erforderlich.
Architekturgrundlagen
TimescaleDB ist als Erweiterung von PostgreSQL implementiert, was bedeutet, dass eine Zeitskalendatenbank innerhalb einer gesamten PostgreSQL-Instanz ausgeführt wird. Das Erweiterungsmodell ermöglicht es der Datenbank, viele Attribute von PostgreSQL zu nutzen, wie z. B. Zuverlässigkeit, Sicherheit und Konnektivität zu einer Vielzahl von Tools von Drittanbietern. Gleichzeitig nutzt TimescaleDB den hohen Grad an Anpassungsmöglichkeiten, der Erweiterungen zur Verfügung steht, indem es Hooks tief in den Abfrageplaner, das Datenmodell und die Ausführungs-Engine von PostgreSQL einfügt.
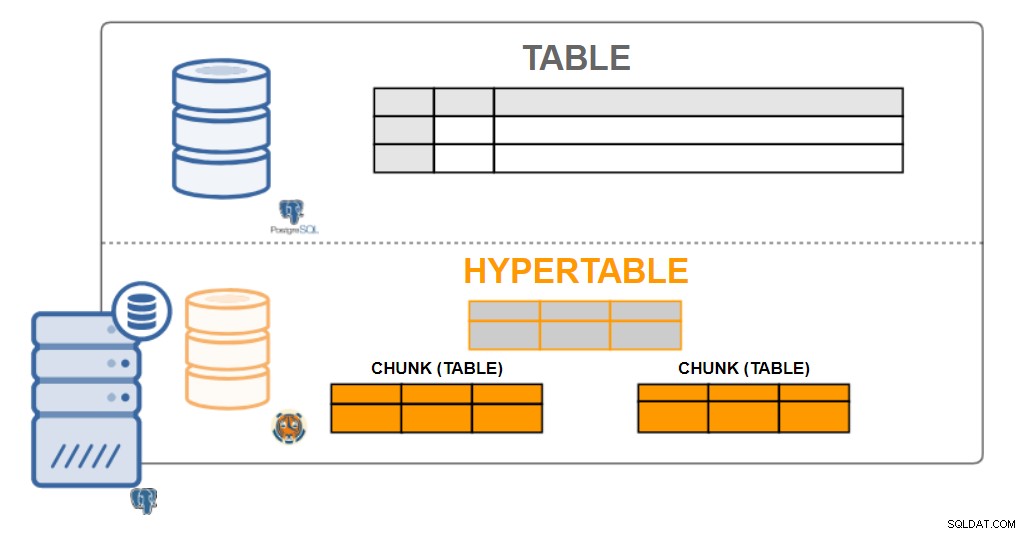 TimescaleDB-Architektur
TimescaleDB-Architektur Hypertabellen
Aus Benutzersicht sehen TimescaleDB-Daten wie einzelne Tabellen aus, die als Hypertabellen bezeichnet werden. Hypertabellen sind ein Konzept oder eine implizite Ansicht vieler einzelner Tabellen, die die als Chunks bezeichneten Daten enthalten. Die Daten der Hypertabelle können entweder ein- oder zweidimensional sein. Es kann durch ein Zeitintervall und durch einen (optionalen) "Partitionsschlüssel"-Wert aggregiert werden.
Praktisch alle Benutzerinteraktionen mit TimescaleDB erfolgen über Hypertabellen. Das Erstellen von Tabellen, Indizes, Ändern von Tabellen, Auswählen von Daten, Einfügen von Daten ... sollte alles auf der Hypertabelle ausgeführt werden.
TimescaleDB führt diese umfangreiche Partitionierung sowohl bei Einzelknoten-Bereitstellungen als auch bei Cluster-Bereitstellungen (in Entwicklung) durch. Während die Partitionierung traditionell nur für die horizontale Skalierung auf mehrere Computer verwendet wird, ermöglicht sie uns auch die Skalierung auf hohe Schreibraten (und verbesserte parallelisierte Abfragen) sogar auf einzelnen Computern.
Unterstützung relationaler Daten
Als relationale Datenbank bietet sie volle Unterstützung für SQL. TimescaleDB unterstützt flexible Datenmodelle, die für verschiedene Anwendungsfälle optimiert werden können. Dadurch unterscheidet sich Timescale etwas von den meisten anderen Zeitreihendatenbanken. Das DBMS ist für schnelle Aufnahme und komplexe Abfragen optimiert, basierend auf PostgreSQL, und bei Bedarf haben wir Zugriff auf eine robuste Zeitreihenverarbeitung.
Installation
TimescaleDB unterstützt ähnlich wie PostgreSQL viele verschiedene Installationsarten, einschließlich der Installation auf Ubuntu-, Debian-, RHEL/Centos-, Windows- oder Cloud-Plattformen.
Eine der bequemsten Möglichkeiten, mit TimescaleDB zu spielen, ist ein Docker-Image.
Der folgende Befehl ruft ein Docker-Image vom Docker-Hub ab, wenn es noch nicht installiert wurde, und führt es dann aus.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbErster Einsatz
Da unsere Instanz betriebsbereit ist, ist es an der Zeit, unsere erste timescaledb-Datenbank zu erstellen. Wie Sie unten sehen können, verbinden wir uns über die Standard-PostgreSQL-Konsole. Wenn Sie also PostgreSQL-Client-Tools (z. B. psql) lokal installiert haben, können Sie diese verwenden, um auf die TimescaleDB-Docker-Instanz zuzugreifen.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Tagesgeschäft
Sowohl aus der Sicht der Nutzung als auch der Verwaltung sieht und fühlt sich TimescaleDB einfach wie PostgreSQL an und kann als solches verwaltet und abgefragt werden.
Die wichtigsten Aufzählungspunkte für den täglichen Betrieb sind:
- Koexistiert mit anderen TimescaleDBs und PostgreSQL-Datenbanken auf einem PostgreSQL-Server.
- Verwendet SQL als Interface-Sprache.
- Verwendet gängige PostgreSQL-Konnektoren zu Tools von Drittanbietern für Backups, Konsole usw.
TimescaleDB-Einstellungen
Die Standardeinstellungen von PostgreSQL sind normalerweise zu konservativ für moderne Server und TimescaleDB. Sie sollten sicherstellen, dass Ihre postgresql.conf-Einstellungen optimiert sind, entweder durch die Verwendung von timescaledb-tune oder manuell.
$ timescaledb-tuneDas Skript fordert Sie auf, Änderungen zu bestätigen. Diese Änderungen werden dann in Ihre postgresql.conf geschrieben und treten beim Neustart in Kraft.
Werfen wir nun einen Blick auf einige grundlegende Operationen aus dem TimescaleDB-Tutorial, die Ihnen eine Vorstellung davon geben können, wie Sie mit dem neuen Datenbanksystem arbeiten.
Um eine Hypertabelle zu erstellen, beginnen Sie mit einer regulären SQL-Tabelle und wandeln sie dann über die Funktion create_hypertable.
in eine Hypertabelle um-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Das Konvertieren in eine Hypertabelle ist einfach wie folgt:
SELECT create_hypertable('conditions', 'time');Das Einfügen von Daten in die Hypertabelle erfolgt über normale SQL-Befehle:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Das Auswählen von Daten ist altes gutes SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Wie wir unten sehen können, können wir gruppieren nach, sortieren nach und Funktionen ausführen. Darüber hinaus enthält TimescaleDB Funktionen für die Zeitreihenanalyse, die in Vanilla PostgreSQL nicht vorhanden sind.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;