Nebenläufigkeitsprobleme sind genauso schwierig wie die Multithread-Programmierung. Wenn keine serialisierbare Isolierung verwendet wird, kann es schwierig sein, T-SQL-Transaktionen zu codieren, die immer korrekt funktionieren, wenn andere Benutzer gleichzeitig Änderungen an der Datenbank vornehmen.
Die potenziellen Probleme können nicht trivial sein, selbst wenn die fragliche „Transaktion“ ein einfaches einzelnes SELECT ist Erklärung. Bei komplexen Transaktionen mit mehreren Anweisungen, die Daten lesen und schreiben, kann das Potenzial für unerwartete Ergebnisse und Fehler bei hoher Parallelität schnell überwältigend werden. Der Versuch, subtile und schwer reproduzierbare Parallelitätsprobleme zu lösen, indem zufällige Sperrhinweise oder andere Trial-and-Error-Methoden angewendet werden, kann eine äußerst frustrierende Erfahrung sein.
In vielerlei Hinsicht scheint die Snapshot-Isolationsstufe eine perfekte Lösung für diese Nebenläufigkeitsprobleme zu sein. Die Grundidee ist, dass sich jede Snapshot-Transaktion so verhält, als ob sie gegen ihre eigene private Kopie des festgeschriebenen Zustands der Datenbank ausgeführt würde, die zum Zeitpunkt des Transaktionsstarts erstellt wurde. Die Bereitstellung der gesamten Transaktion mit einer unveränderlichen Ansicht der festgeschriebenen Daten garantiert natürlich konsistente Ergebnisse für schreibgeschützte Operationen, aber was ist mit Transaktionen, die Daten ändern?
Die Snapshot-Isolation geht optimistisch mit Datenänderungen um und geht implizit davon aus, dass Konflikte zwischen gleichzeitigen Schreibern relativ selten sind. Wenn ein Schreibkonflikt auftritt, gewinnt der erste Committer und die Änderungen der verlierenden Transaktion werden rückgängig gemacht. Das ist natürlich unglücklich für die rückgängig gemachte Transaktion, aber wenn dies selten genug vorkommt, können die Vorteile der Snapshot-Isolation die Kosten eines gelegentlichen Fehlers und einer Wiederholung aufwiegen.
Die relativ einfache und saubere Semantik der Snapshot-Isolation (im Vergleich zu den Alternativen) kann ein erheblicher Vorteil sein, insbesondere für Personen, die nicht ausschließlich in der Datenbankwelt arbeiten und daher die verschiedenen Isolationsstufen nicht gut kennen. Selbst für erfahrene Datenbankprofis kann eine relativ „intuitiv bedienbare“ Isolationsstufe eine willkommene Erleichterung sein.
Natürlich sind die Dinge selten so einfach, wie sie auf den ersten Blick scheinen, und die Snapshot-Isolation ist da keine Ausnahme. Die offizielle Dokumentation beschreibt ziemlich gut die wichtigsten Vor- und Nachteile der Snapshot-Isolation, daher konzentriert sich der Großteil dieses Artikels darauf, einige der weniger bekannten und überraschenden Probleme zu untersuchen, auf die Sie stoßen können. Zunächst aber ein kurzer Blick auf die logischen Eigenschaften dieser Isolationsstufe:
ACID-Eigenschaften und Snapshot-Isolierung
Die Snapshot-Isolation gehört nicht zu den im SQL-Standard definierten Isolationsstufen, wird aber dennoch häufig mit den dort definierten „Parallelitätsphänomenen“ verglichen. Die folgende Vergleichstabelle ist beispielsweise aus dem technischen Artikel von SQL Server „SQL Server 2005 Row Versioning-Based Transaction Isolation“ von Kimberly L. Tripp und Neal Graves reproduziert:
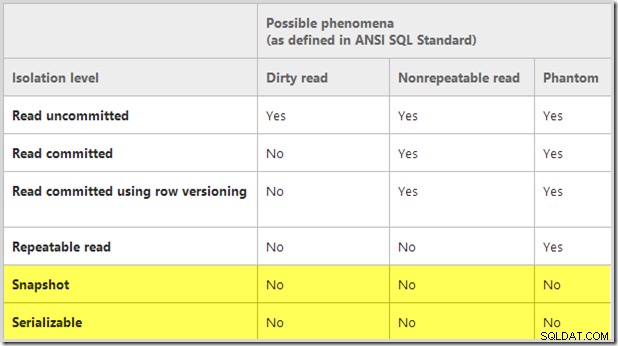
Durch Bereitstellen einer Point-in-Time-Ansicht von verpflichteten Daten , bietet die Snapshot-Isolation Schutz vor allen drei dort gezeigten Nebenläufigkeitsphänomenen. Dirty Reads werden verhindert, da nur festgeschriebene Daten sichtbar sind, und die statische Natur des Snapshots verhindert, dass sowohl nicht wiederholbare Lesevorgänge als auch Phantome auftreten.
Dieser Vergleich (und insbesondere der hervorgehobene Abschnitt) zeigt jedoch nur, dass die Snapshot- und die serialisierbare Isolationsstufe dieselben drei spezifischen Phänomene verhindern. Das bedeutet nicht, dass sie in jeder Hinsicht gleichwertig sind. Wichtig ist, dass der SQL-92-Standard die serialisierbare Isolation nicht allein in Bezug auf die drei Phänomene definiert. Abschnitt 4.28 des Standards enthält die vollständige Definition:
Die Ausführung von nebenläufigen SQL-Transaktionen auf dem Isolationslevel SERIALIZABLE ist garantiert serialisierbar. Eine serialisierbare Ausführung ist als eine Ausführung der Operationen gleichzeitig ausgeführter SQL-Transaktionen definiert, die denselben Effekt erzeugt wie eine serielle Ausführung derselben SQL-Transaktionen. Bei einer seriellen Ausführung wird jede SQL-Transaktion vollständig ausgeführt, bevor die nächste SQL-Transaktion beginnt.
Der Umfang und die Bedeutung der stillschweigenden Garantien werden hier oft übersehen. Um es in einfacher Sprache zu sagen:
Jede serialisierbare Transaktion, die korrekt ausgeführt wird, wenn sie alleine ausgeführt wird, wird weiterhin korrekt mit einer beliebigen Kombination gleichzeitiger Transaktionen ausgeführt, oder sie wird mit einer Fehlermeldung zurückgesetzt (normalerweise ein Deadlock in der SQL Server-Implementierung).
Nicht serialisierbare Isolationsstufen, einschließlich Snapshot-Isolation, bieten nicht die gleichen starken Garantien für die Korrektheit.
Veraltete Daten
Die Snapshot-Isolation scheint fast verführerisch einfach. Lesevorgänge stammen immer von festgeschriebenen Daten ab einem bestimmten Zeitpunkt, und Schreibkonflikte werden automatisch erkannt und behandelt. Inwiefern ist dies keine perfekte Lösung für alle Parallelitätsprobleme?
Ein mögliches Problem besteht darin, dass Snapshot-Lesevorgänge nicht unbedingt den aktuellen festgeschriebenen Zustand der Datenbank widerspiegeln. Eine Snapshot-Transaktion ignoriert vollständig alle festgeschriebenen Änderungen, die von anderen gleichzeitigen Transaktionen vorgenommen werden, nachdem die Snapshot-Transaktion begonnen hat. Eine andere Möglichkeit, dies auszudrücken, ist zu sagen, dass eine Snapshot-Transaktion veraltete, veraltete Daten sieht. Während dieses Verhalten möglicherweise genau das ist, was zum Generieren eines genauen Point-in-Time-Berichts erforderlich ist, ist es unter anderen Umständen möglicherweise nicht so geeignet (z. B. wenn es zum Erzwingen einer Regel in einem Trigger verwendet wird).
Schief schreiben
Die Snapshot-Isolation ist auch anfällig für ein etwas verwandtes Phänomen, das als Schreibverzerrung bekannt ist. Das Lesen veralteter Daten spielt dabei eine Rolle, aber dieses Problem hilft auch zu klären, was die Snapshot-„Schreibkonflikterkennung“ tut und was nicht.
Schreibversatz tritt auf, wenn zwei gleichzeitige Transaktionen jeweils Daten lesen, die die andere Transaktion modifiziert. Es tritt kein Schreibkonflikt auf, da die beiden Transaktionen unterschiedliche Zeilen ändern. Keine Transaktion sieht die von der anderen vorgenommenen Änderungen, da beide von einem Zeitpunkt lesen, bevor diese Änderungen vorgenommen wurden.
Ein klassisches Beispiel für Schreibversatz ist das Problem der weißen und schwarzen Murmel, aber ich möchte hier ein weiteres einfaches Beispiel zeigen:
-- Create two empty tables CREATE TABLE A (x integer NOT NULL); CREATE TABLE B (x integer NOT NULL); -- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT A (x) SELECT COUNT_BIG(*) FROM B; -- Connection 2 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; INSERT B (x) SELECT COUNT_BIG(*) FROM A; COMMIT TRANSACTION; -- Connection 1 COMMIT TRANSACTION;
Bei der Snapshot-Isolation enden beide Tabellen in diesem Skript mit einer einzelnen Zeile, die einen Nullwert enthält. Dies ist ein korrektes Ergebnis, aber kein serialisierbares:Es entspricht keiner möglichen seriellen Transaktionsausführungsreihenfolge. In jedem wirklich seriellen Zeitplan muss eine Transaktion abgeschlossen sein, bevor die andere beginnt, sodass die zweite Transaktion die von der ersten eingefügte Zeile zählen würde. Dies mag nach einer Formsache klingen, aber denken Sie daran, dass die leistungsstarken serialisierbaren Garantien nur gelten, wenn Transaktionen wirklich serialisierbar sind.
Eine subtile Konflikterkennung
Ein Snapshot-Schreibkonflikt tritt immer dann auf, wenn eine Snapshot-Transaktion versucht, eine Zeile zu ändern, die von einer anderen Transaktion geändert wurde, die nach Beginn der Snapshot-Transaktion festgeschrieben wurde. Hier gibt es zwei Feinheiten:
- Die Transaktionen müssen sich eigentlich nicht ändern beliebige Datenwerte; und
- Die Transaktionen müssen keine gemeinsamen Spalten ändern .
Das folgende Skript demonstriert beide Punkte:
-- Test table
CREATE TABLE dbo.Conflict
(
ID1 integer UNIQUE,
Value1 integer NOT NULL,
ID2 integer UNIQUE,
Value2 integer NOT NULL
);
-- Insert one row
INSERT dbo.Conflict
(ID1, ID2, Value1, Value2)
VALUES
(1, 1, 1, 1);
-- Connection 1
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value1 = 1
WHERE ID1 = 1;
-- Connection 2
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
UPDATE dbo.Conflict
SET Value2 = 1
WHERE ID2 = 1;
-- Connection 1
COMMIT TRANSACTION; Beachten Sie Folgendes:
- Jede Transaktion sucht dieselbe Zeile mit einem anderen Index
- Keine Aktualisierung führt zu einer Änderung der bereits gespeicherten Daten
- Die beiden Transaktionen „aktualisieren“ verschiedene Spalten in der Zeile.
Trotzdem endet die zweite Transaktion mit einem Update-Konfliktfehler, wenn die erste Transaktion festgeschrieben wird:
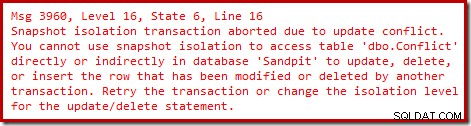
Fazit:Die Konflikterkennung arbeitet immer auf der Ebene einer ganzen Zeile, und ein „Update“ muss keine Daten tatsächlich ändern. (Falls Sie sich das fragen, zählen Änderungen an Off-Row-LOB- oder -SLOB-Daten auch als Änderung an der Zeile für Konflikterkennungszwecke).
Das Fremdschlüsselproblem
Die Konflikterkennung gilt auch für die übergeordnete Zeile in einer Fremdschlüsselbeziehung. Beim Ändern einer untergeordneten Zeile unter Snapshot-Isolation kann eine Änderung an der übergeordneten Zeile in einer anderen Transaktion einen Konflikt auslösen. Wie zuvor gilt diese Logik für die gesamte übergeordnete Zeile – die übergeordnete Aktualisierung muss sich nicht auf die Fremdschlüsselspalte selbst auswirken. Jede Operation in der untergeordneten Tabelle, die eine automatische Fremdschlüsselprüfung im Ausführungsplan erfordert, kann zu einem unerwarteten Konflikt führen.
Um dies zu demonstrieren, erstellen Sie zunächst die folgenden Tabellen und Beispieldaten:
CREATE TABLE dbo.Dummy
(
x integer NULL
);
CREATE TABLE dbo.Parent
(
ParentID integer PRIMARY KEY,
ParentValue integer NOT NULL
);
CREATE TABLE dbo.Child
(
ChildID integer PRIMARY KEY,
ChildValue integer NOT NULL,
ParentID integer NULL FOREIGN KEY REFERENCES dbo.Parent
);
INSERT dbo.Parent
(ParentID, ParentValue)
VALUES (1, 1);
INSERT dbo.Child
(ChildID, ChildValue, ParentID)
VALUES (1, 1, 1); Führen Sie nun Folgendes von zwei separaten Verbindungen aus, wie in den Kommentaren angegeben:
-- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; SELECT COUNT_BIG(*) FROM dbo.Dummy; -- Connection 2 (any isolation level) UPDATE dbo.Parent SET ParentValue = 1 WHERE ParentID = 1; -- Connection 1 UPDATE dbo.Child SET ParentID = NULL WHERE ChildID = 1; UPDATE dbo.Child SET ParentID = 1 WHERE ChildID = 1;
Der Lesevorgang aus der Dummy-Tabelle dient dazu, sicherzustellen, dass die Snapshot-Transaktion offiziell gestartet wurde. Ausgabe von BEGIN TRANSACTION reicht dazu nicht aus; wir müssen eine Art Datenzugriff auf eine Benutzertabelle durchführen.
Die erste Aktualisierung der untergeordneten Tabelle verursacht keinen Konflikt, da die referenzierende Spalte auf NULL gesetzt wird erfordert keine Überprüfung der übergeordneten Tabelle im Ausführungsplan (es gibt nichts zu überprüfen). Der Abfrageprozessor berührt die übergeordnete Zeile im Ausführungsplan nicht, sodass kein Konflikt entsteht.
Die zweite Aktualisierung der untergeordneten Tabelle löst einen Konflikt aus, da automatisch eine Fremdschlüsselprüfung durchgeführt wird. Wenn der Abfrageprozessor auf die Parent-Zeile zugreift, wird sie auch auf einen Aktualisierungskonflikt geprüft. In diesem Fall wird ein Fehler ausgelöst, da die referenzierte übergeordnete Zeile nach dem Start der Snapshot-Transaktion eine festgeschriebene Änderung erfahren hat. Beachten Sie, dass die Änderung der übergeordneten Tabelle die Fremdschlüsselspalte selbst nicht beeinflusst hat.
Ein unerwarteter Konflikt kann auch auftreten, wenn eine Änderung an der untergeordneten Tabelle auf eine übergeordnete Zeile verweist, die erstellt wurde durch eine gleichzeitige Transaktion (und diese Transaktion wurde festgeschrieben, nachdem die Snapshot-Transaktion gestartet wurde).
Zusammenfassung:Ein Abfrageplan, der eine automatische Fremdschlüsselprüfung enthält, kann einen Konfliktfehler auslösen, wenn die referenzierte Zeile seit Beginn der Snapshot-Transaktion geändert (einschließlich erstellt!) wurde.
Das Problem der abgeschnittenen Tabelle
Eine Snapshot-Transaktion schlägt mit einem Fehler fehl, wenn eine Tabelle, auf die sie zugreift, seit Beginn der Transaktion abgeschnitten wurde. Dies gilt auch dann, wenn die abgeschnittene Tabelle anfangs keine Zeilen hatte, wie das folgende Skript zeigt:
CREATE TABLE dbo.AccessMe
(
x integer NULL
);
CREATE TABLE dbo.TruncateMe
(
x integer NULL
);
-- Connection 1
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION;
SELECT COUNT_BIG(*) FROM dbo.AccessMe;
-- Connection 2
TRUNCATE TABLE dbo.TruncateMe;
-- Connection 1
SELECT COUNT_BIG(*) FROM dbo.TruncateMe; Das abschließende SELECT schlägt mit dem folgenden Fehler fehl:

Dies ist ein weiterer subtiler Nebeneffekt, auf den Sie achten sollten, bevor Sie die Snapshot-Isolation für eine vorhandene Datenbank aktivieren.
Nächstes Mal
Der nächste (und letzte) Post in dieser Serie wird sich mit dem Read Uncommitted Isolation Level (liebevoll bekannt als "nolock") befassen.
[Siehe den Index für die gesamte Serie]